







理论部分
为什么大模型需要评测,要评测哪些内容,怎么评测呢?
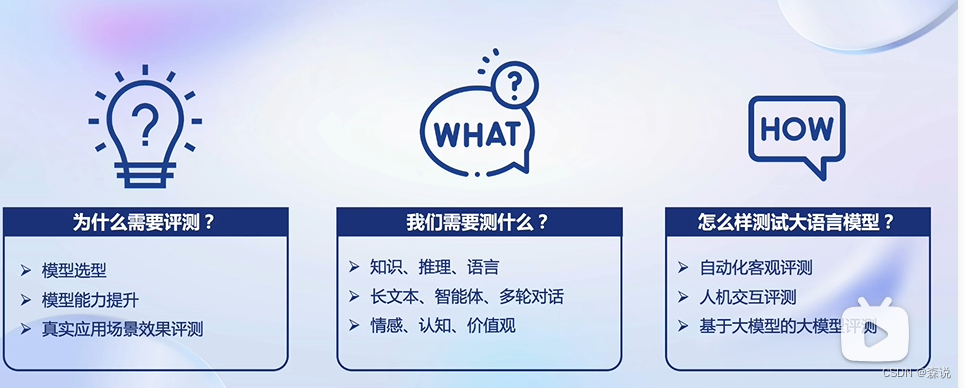
为什么需要评测
首先现在的大模型很多是多模态的,有文生文,文生图的,必须要建立一个统一的标准,这样才能让用户和产业界知道每个模型的差异,从而选择最合适的模型。对于开发者而言,只有经过评测之后,才会知道该模型有哪些不足,才能实现点对点的提升

要评测的内容
相对于传统的NLP任务,现在的大模型很显然要评测更多的内容,不单单是对语句的推理,情感的检测,而且还要做到对垂直领域的测试,比如说法法律,编码能力等。
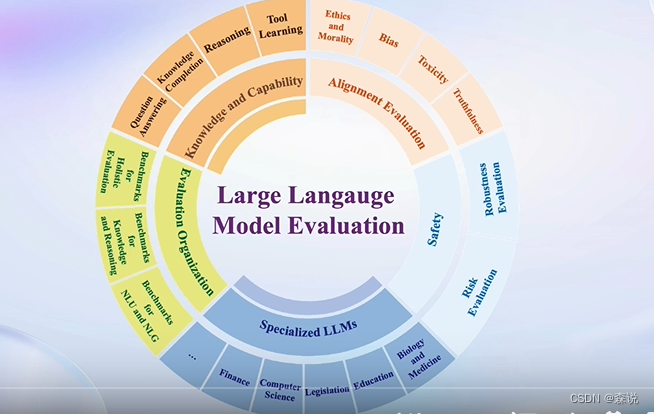
评测方法
客观评测
比如问大模型一个问题,模型回答中包含这个词语,就认为它回答成功。

主观评测
这类问题的话要人力辅助来判断是否回答得合理,当然也是可以借助大模型

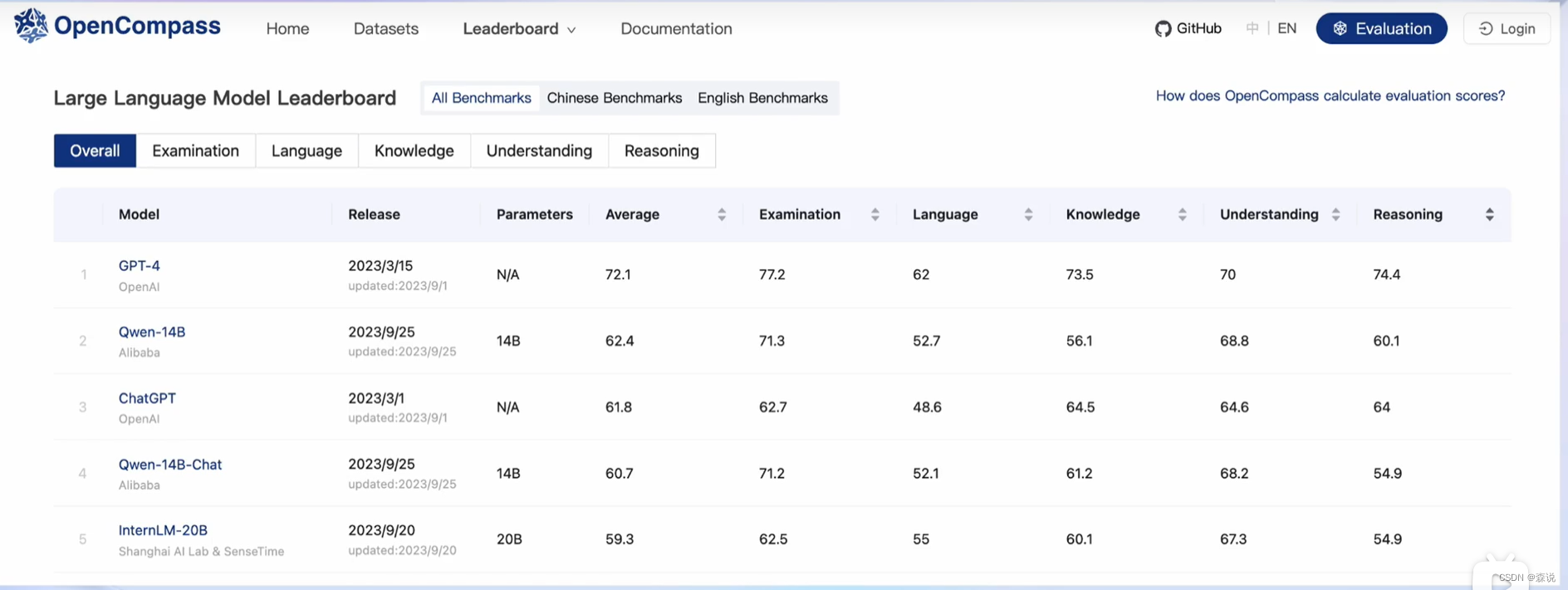
OpenCompass
下图是该框架得介绍

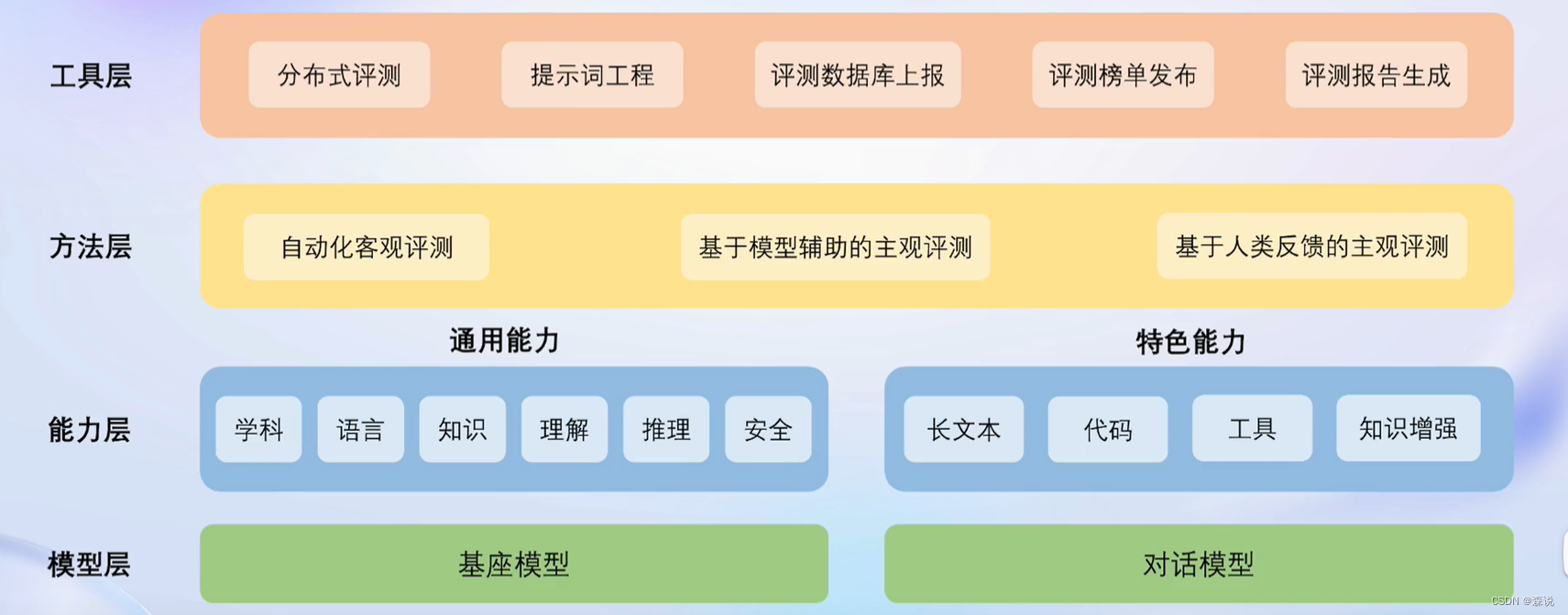
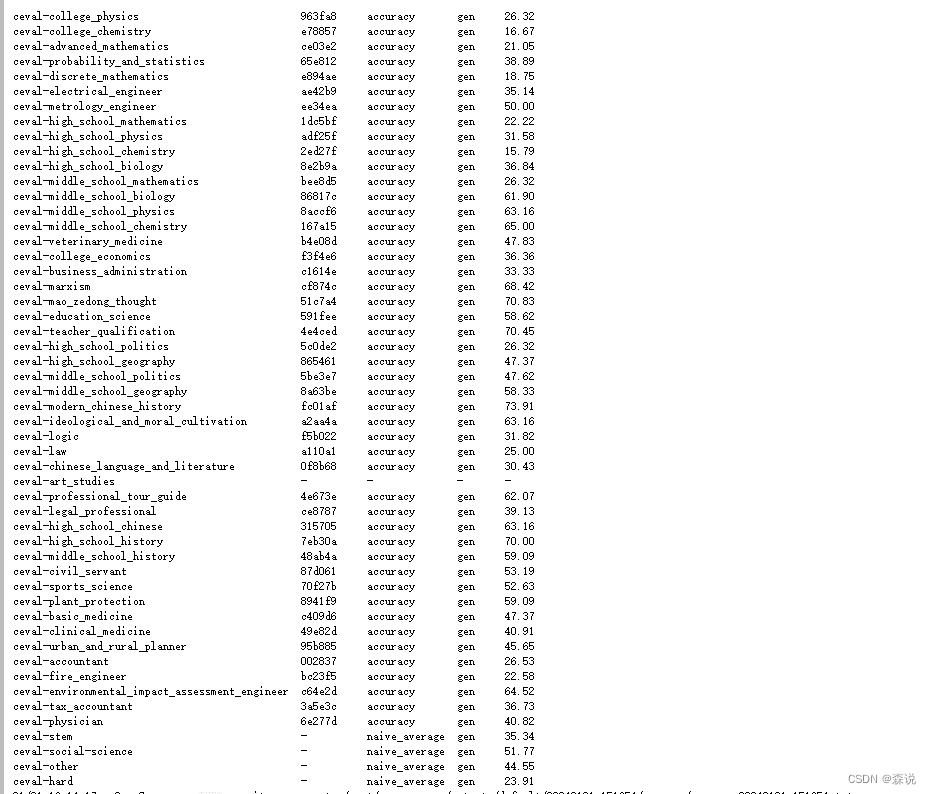
会在测试完输出榜单。
实践部分
环境配置
打开开发机
创建虚拟环境
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base
source activate opencompass

输入下面命令安装opencompass
git clone https://gitee.com/open-compass/opencompass
cd opencompass
pip install -e .
数据准备
# 解压评测数据集到 data/ 处
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
# 将会在opencompass下看到data文件夹
启动评测
还有就是这里主要实现客观评测,使用主观评测得话,还要借助其他得大模型。
python run.py \
--datasets ceval_gen \
--hf-path /share/model_repos/internlm2-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /share/model_repos/internlm2-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 100 \ # 生成的最大 token 数
--batch-size 8 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
–datasets ceval_gen \ # 数据集
–hf-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace 模型路径
–tokenizer-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
–tokenizer-kwargs padding_side=‘left’ truncation=‘left’ trust_remote_code=True \ # 构建 tokenizer 的参数
–model-kwargs device_map=‘auto’ trust_remote_code=True \ # 构建模型的参数
–max-seq-len 2048 \ # 模型可以接受的最大序列长度
–max-out-len 16 \ # 生成的最大 token 数,如果是客观评测要设置小一点
–batch-size 4 \ # 批量大小
–num-gpus 1 # 运行模型所需的 GPU 数量
–debug # 如果不开启,就会在logs中记录
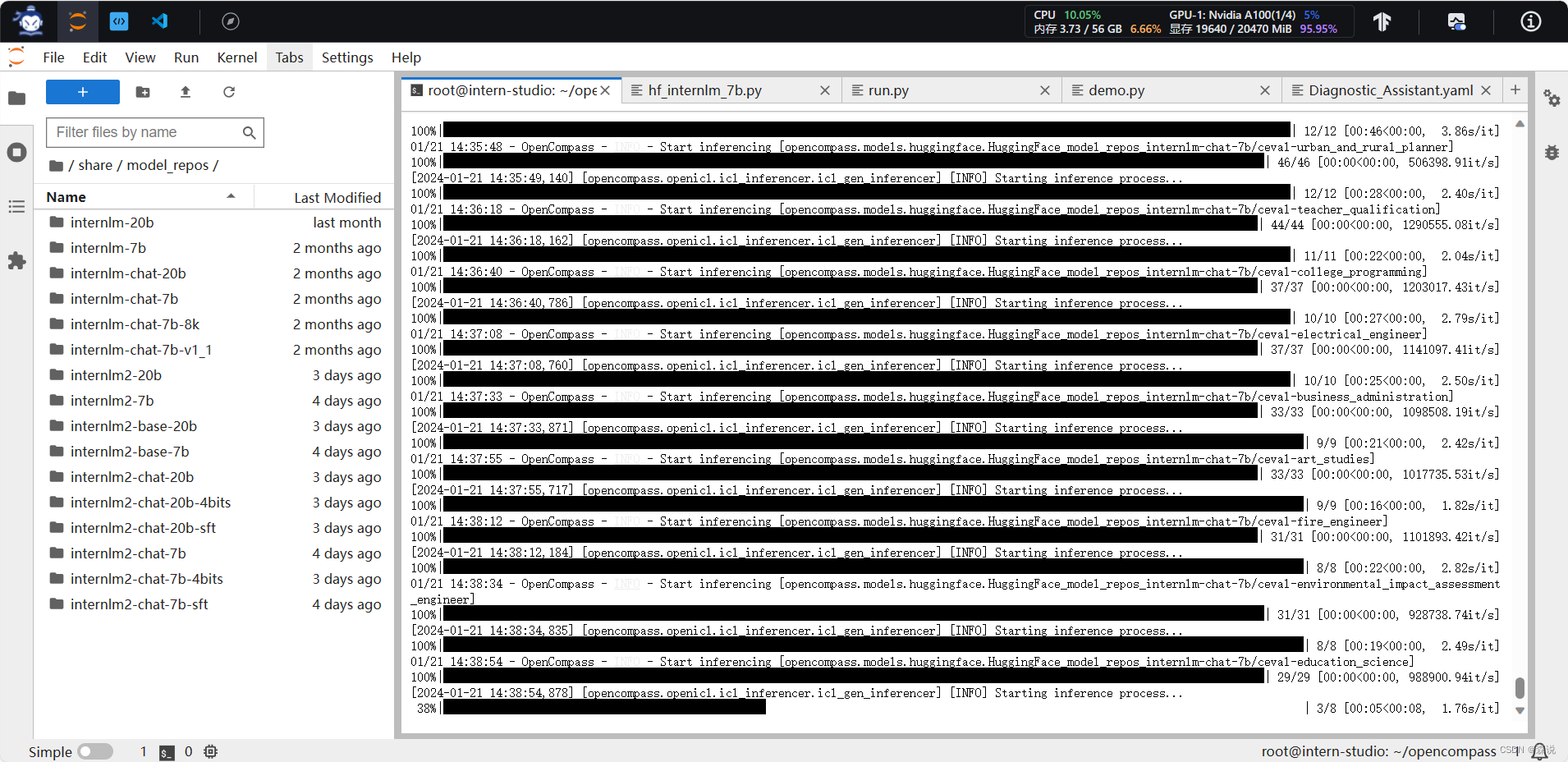
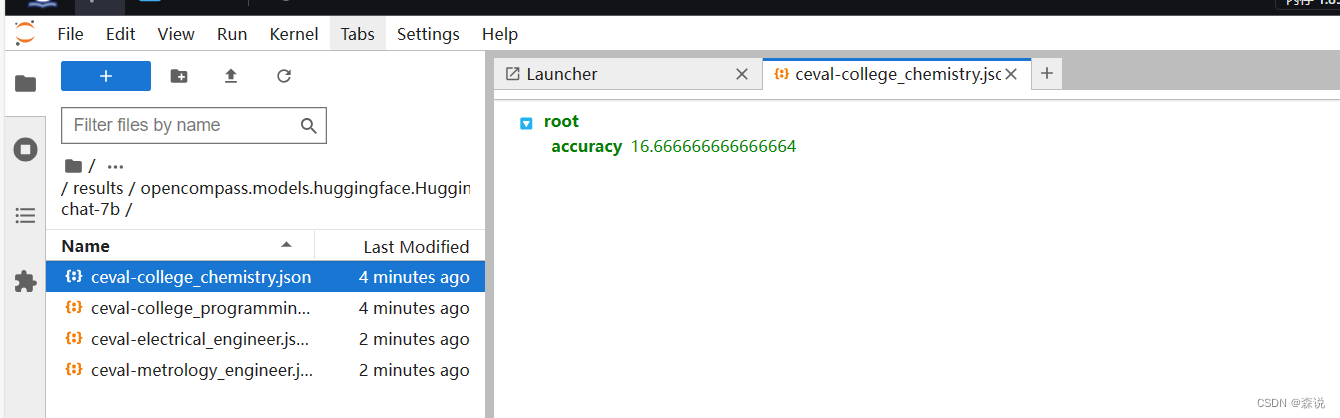
从这里可以看到过程和结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









