






1 微调
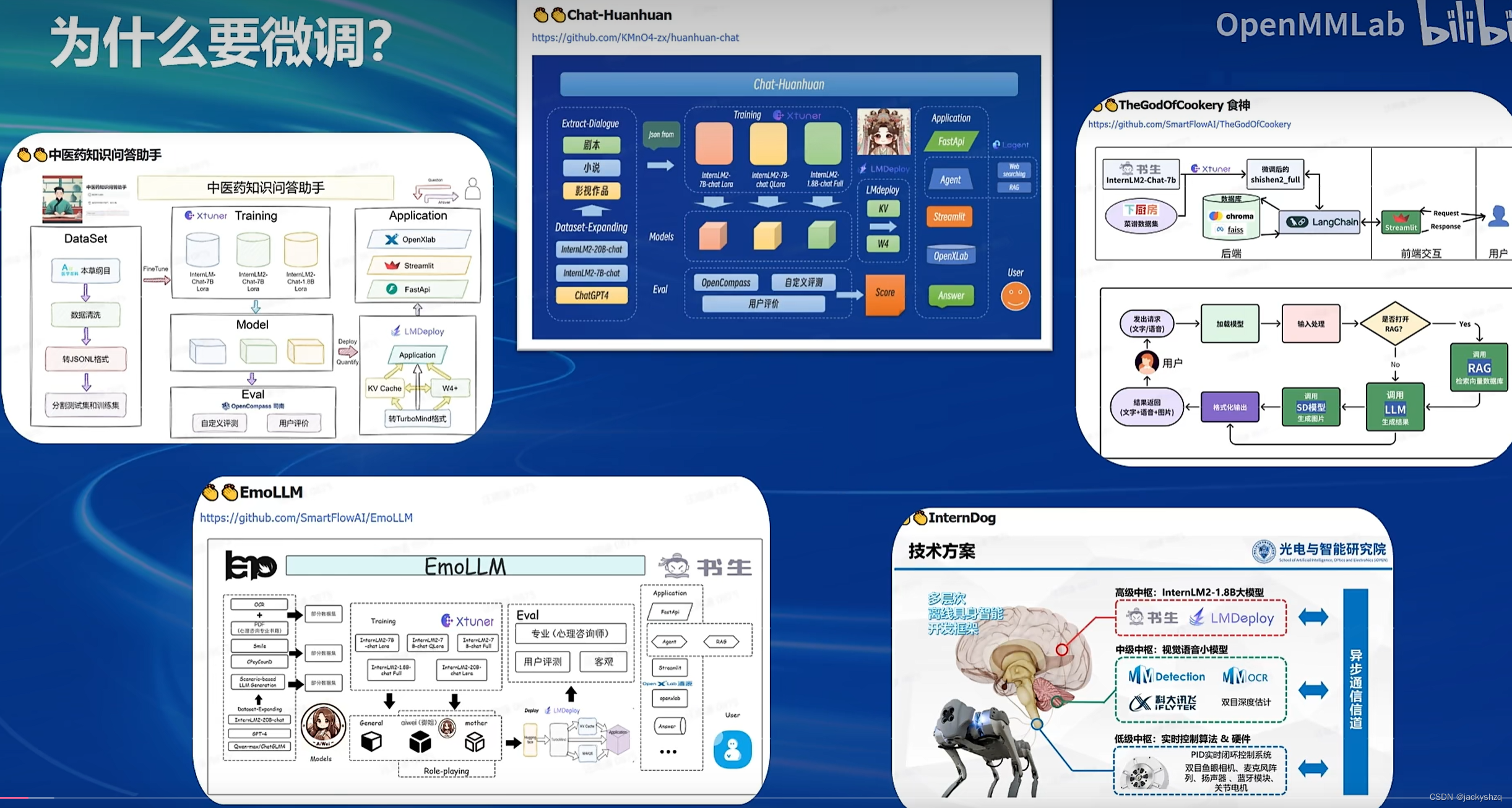
1.1 为什么要微调
1.2 两种Finetune 范式

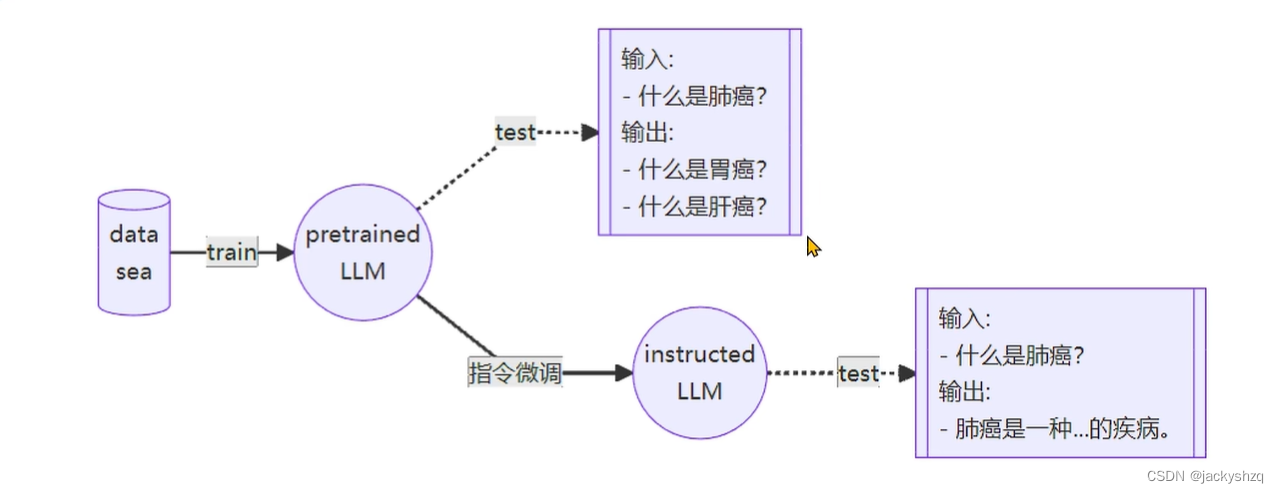
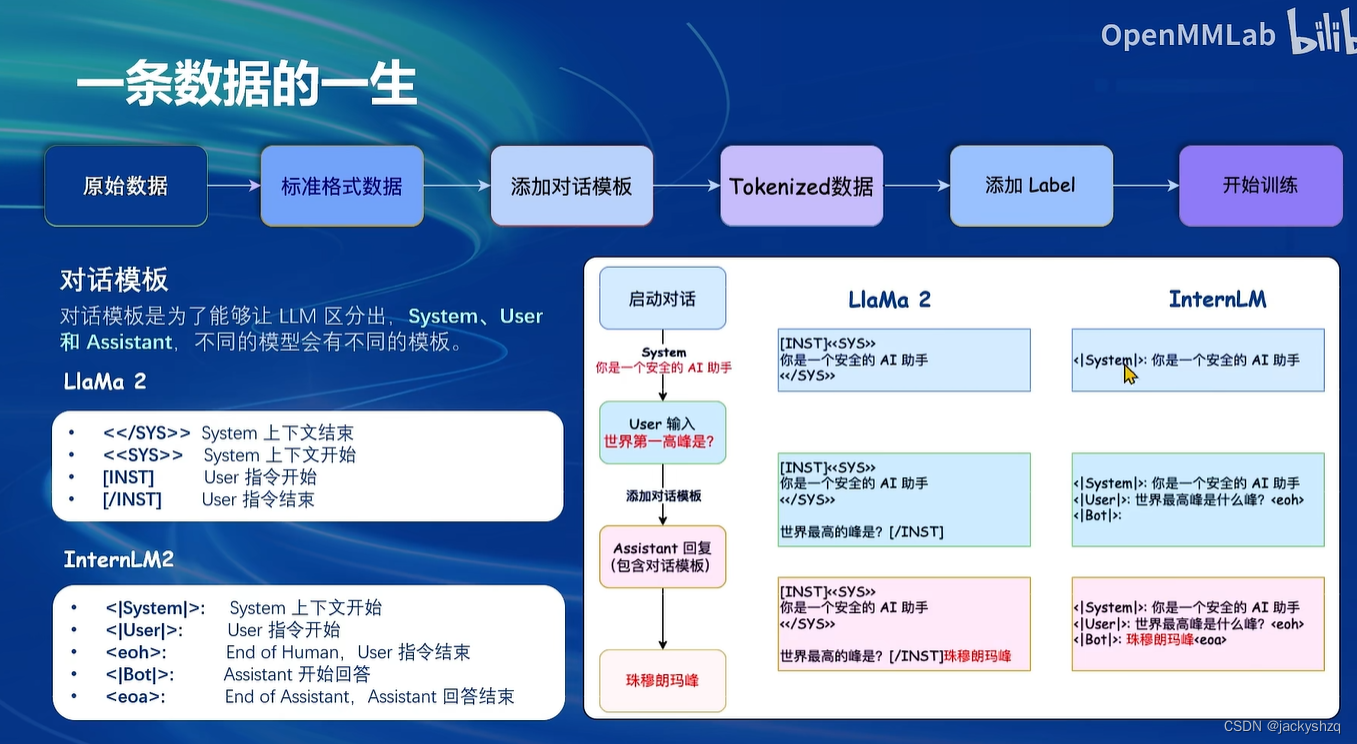
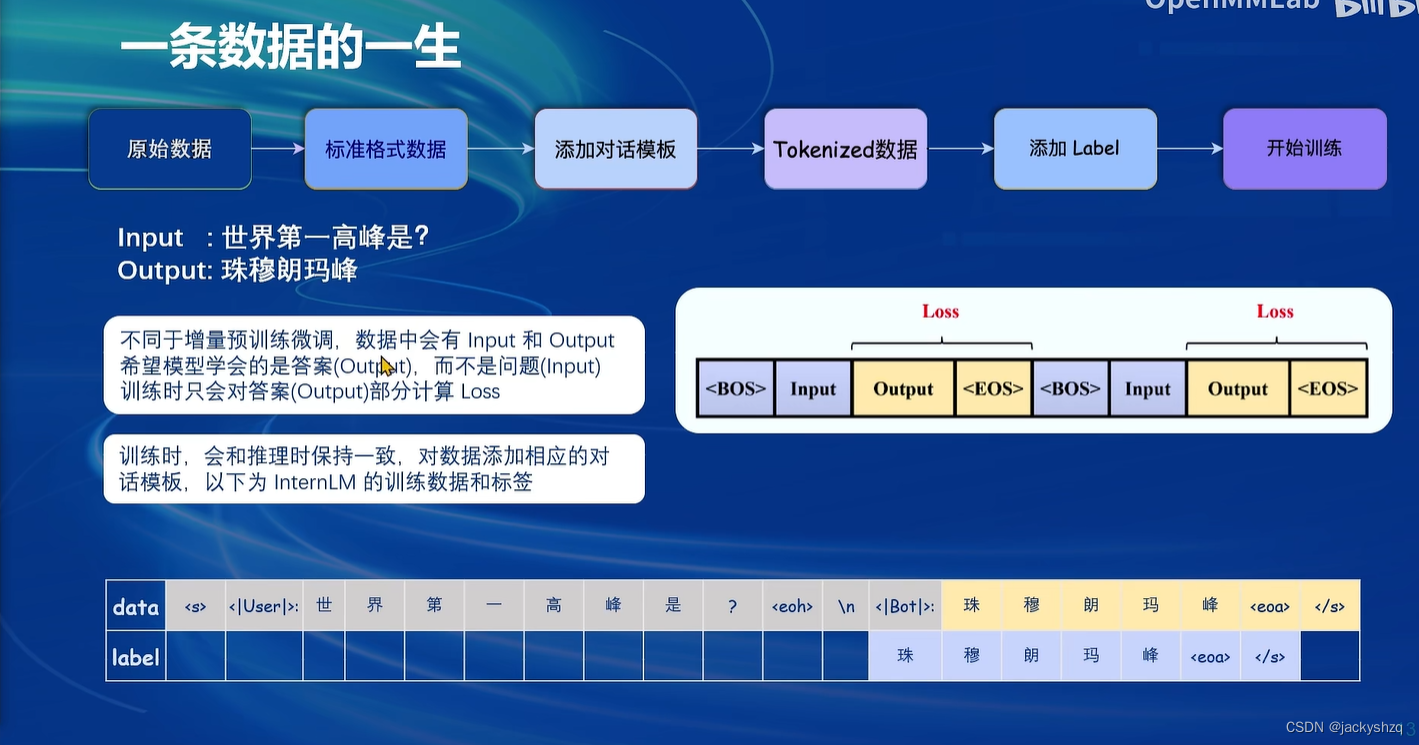
1.3 一条数据的一生
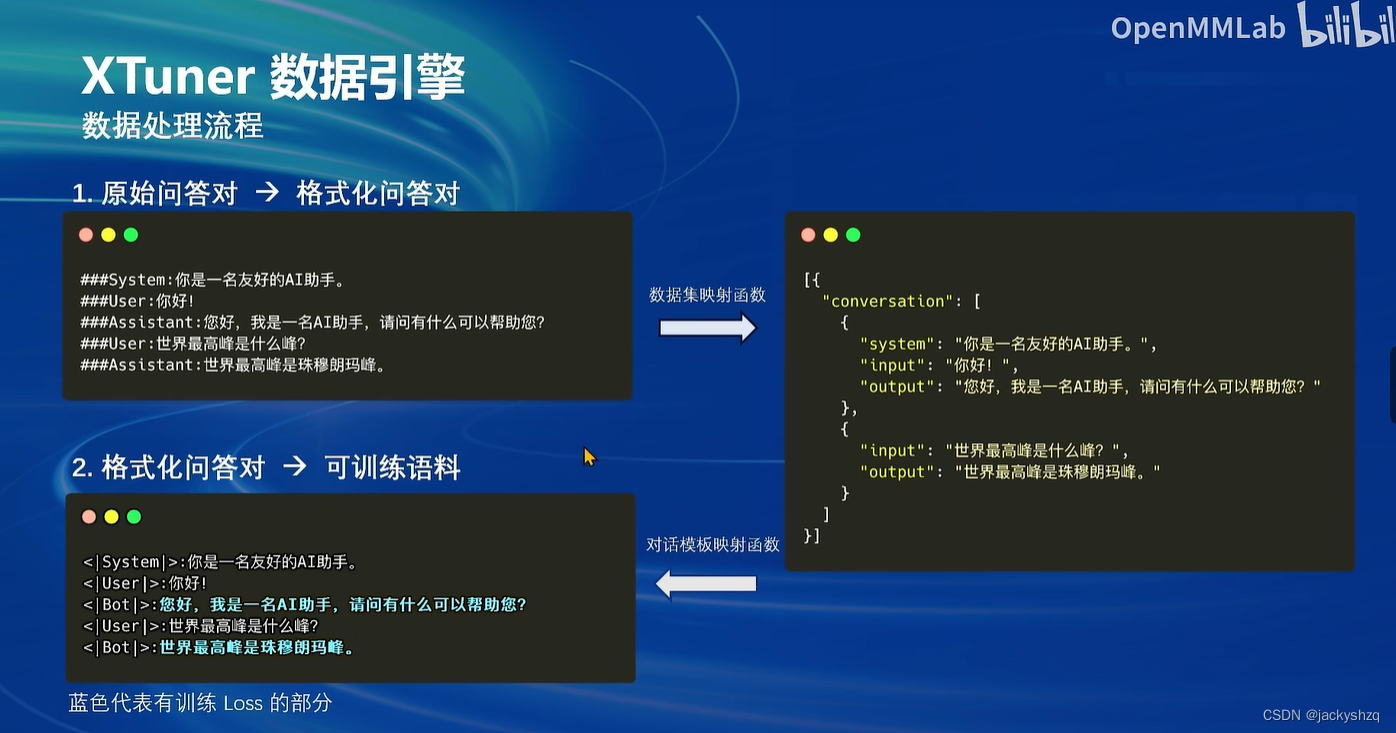
1.3.1 标准格式数据

1.3.2 添加对话模板
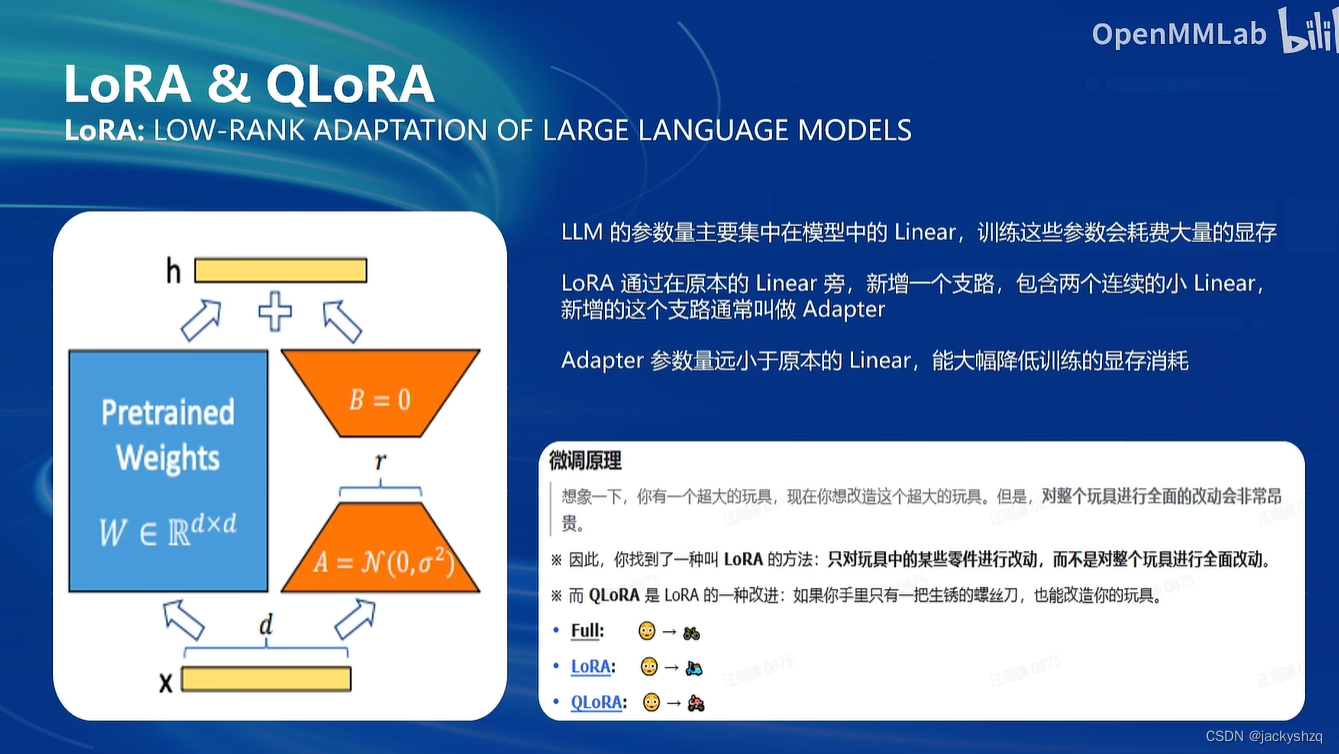
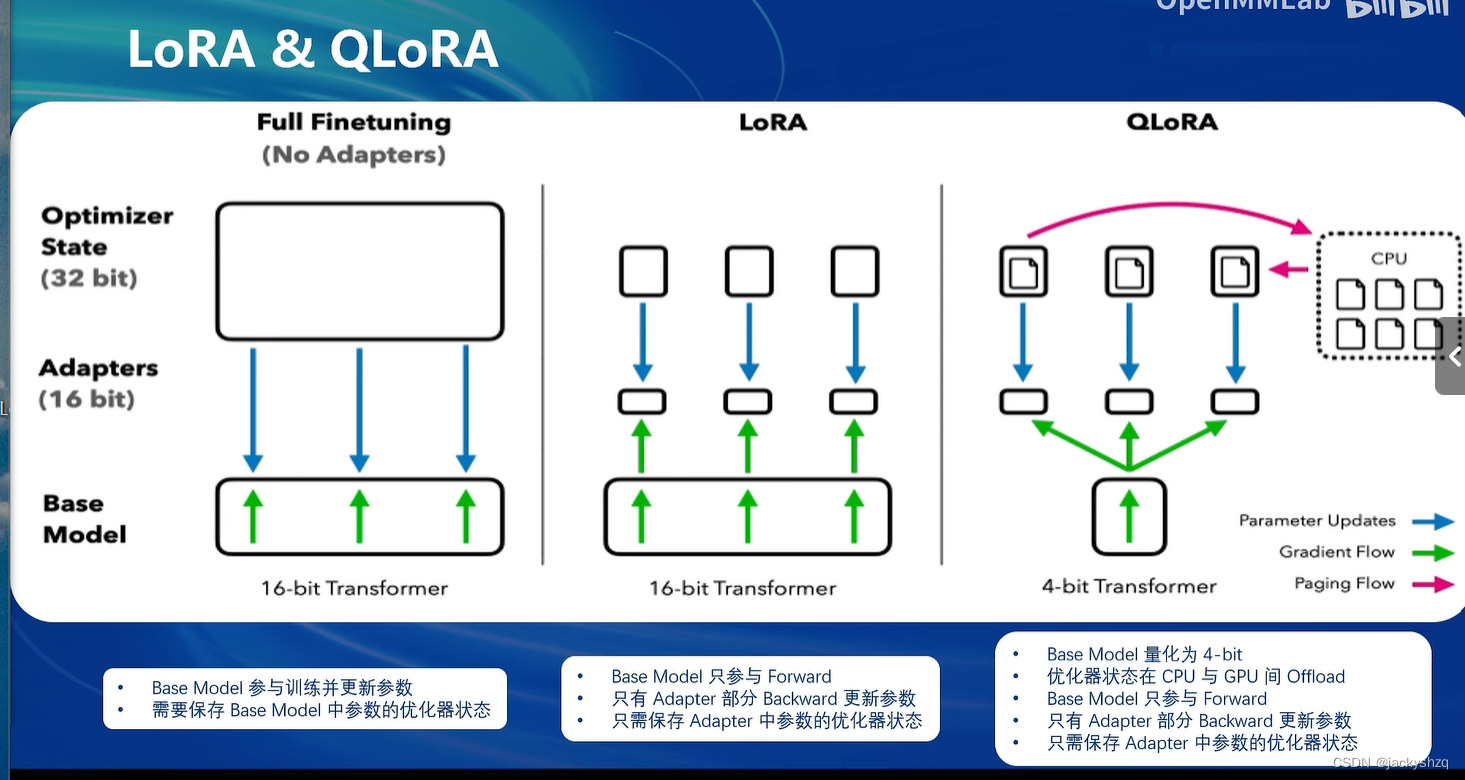
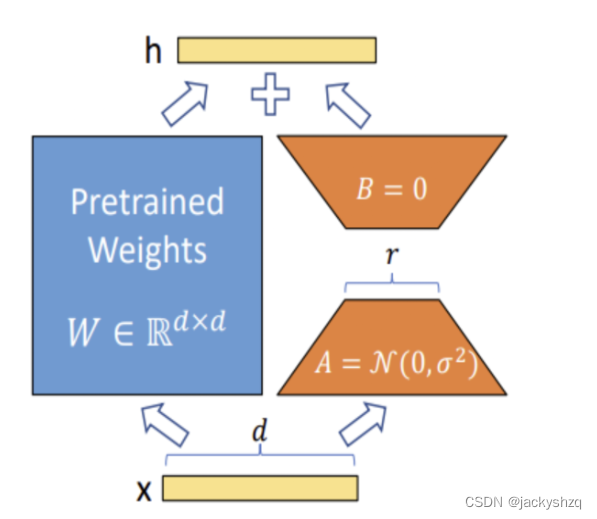
 1.4 微调方案(LoRA方法)
1.4 微调方案(LoRA方法)
2. XTuner
2.1 XTuner简介
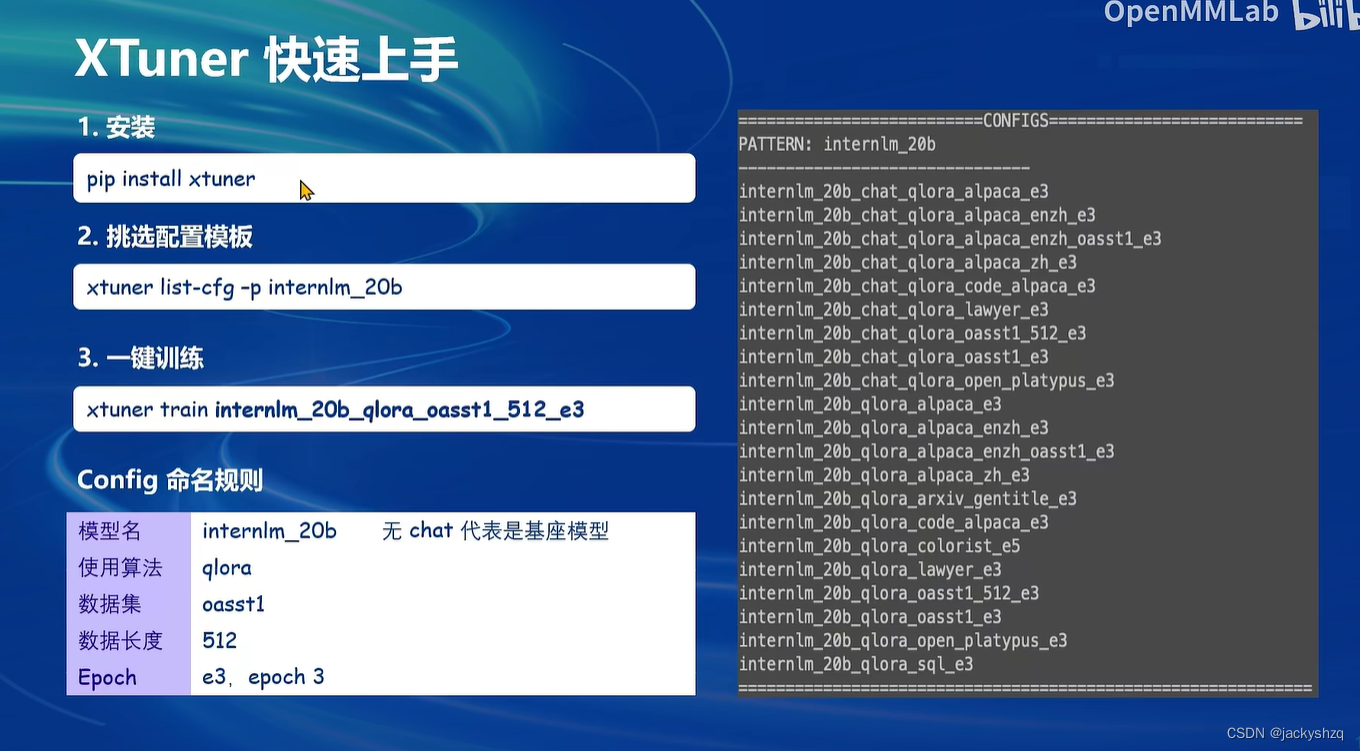
 2.2 XTuner 快速上手
2.2 XTuner 快速上手

 3. 8GB现存玩转LLM
3. 8GB现存玩转LLM
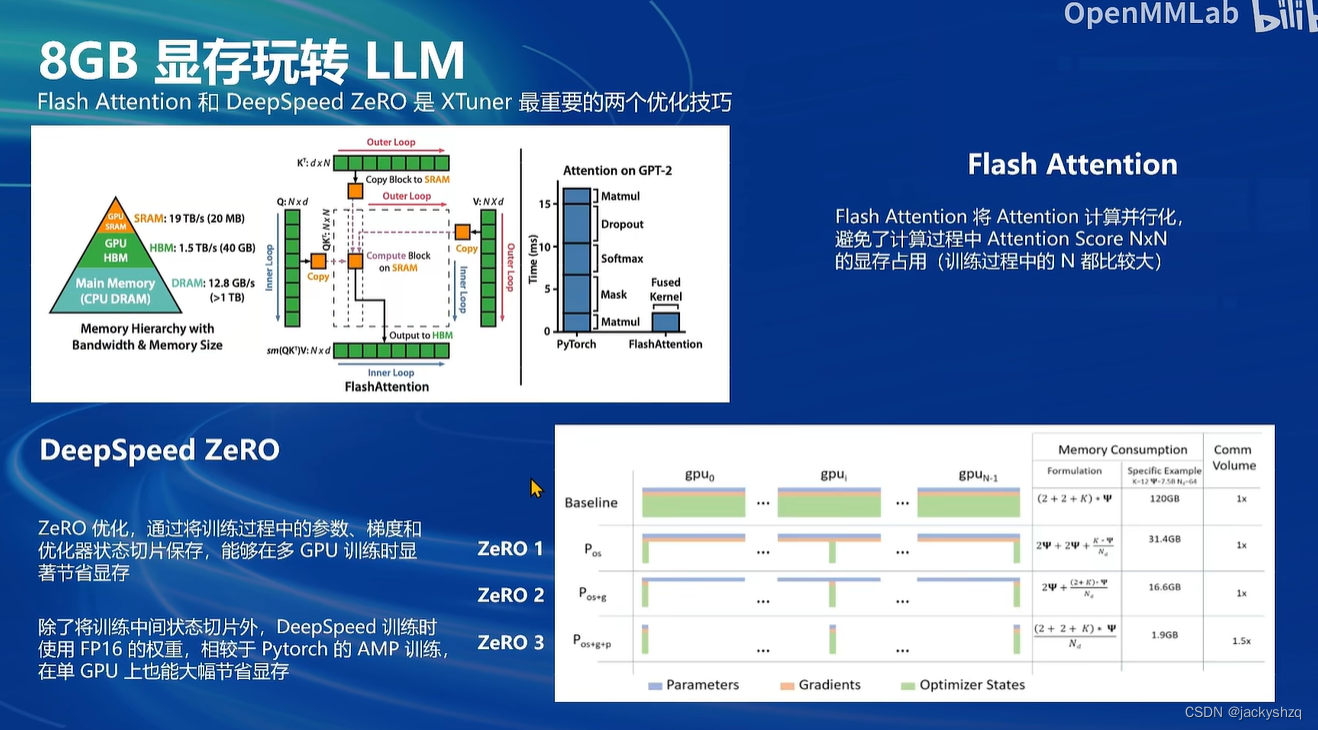 3.1 优化后的情况
3.1 优化后的情况

4 InterLM2 1.8B模型

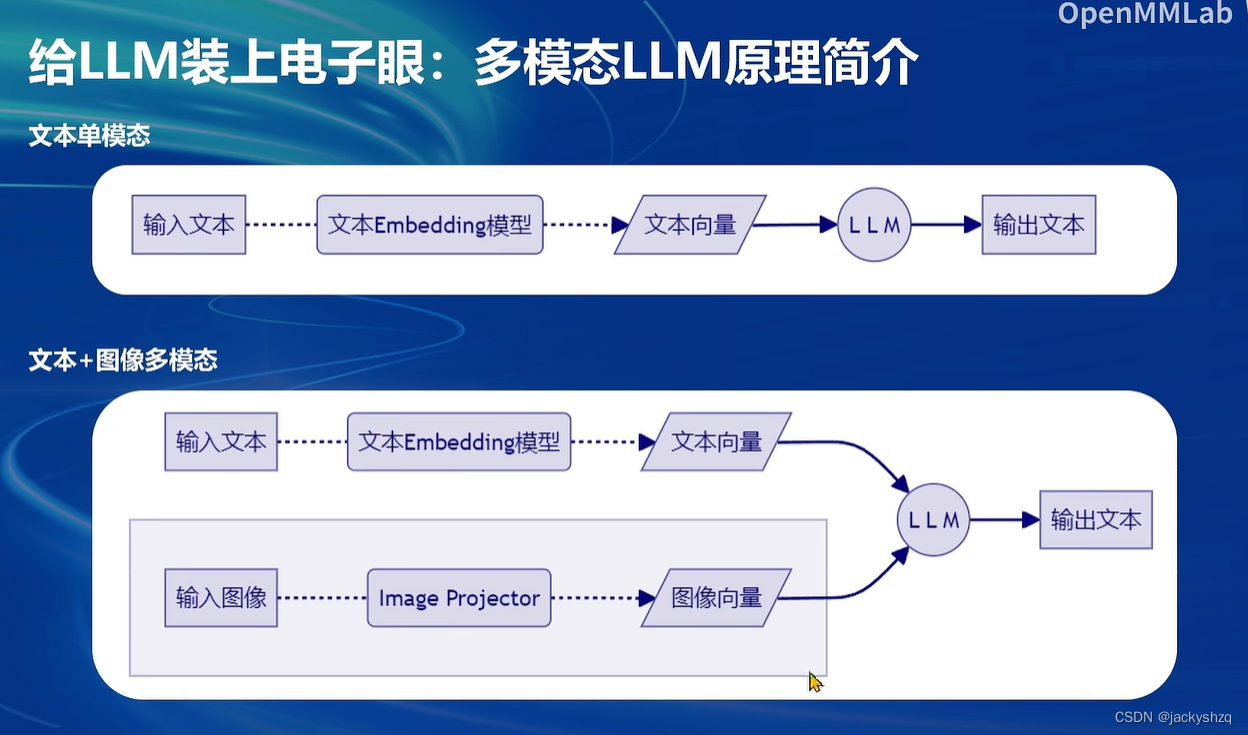
5 多模态

5.1 给LLM装上电子眼
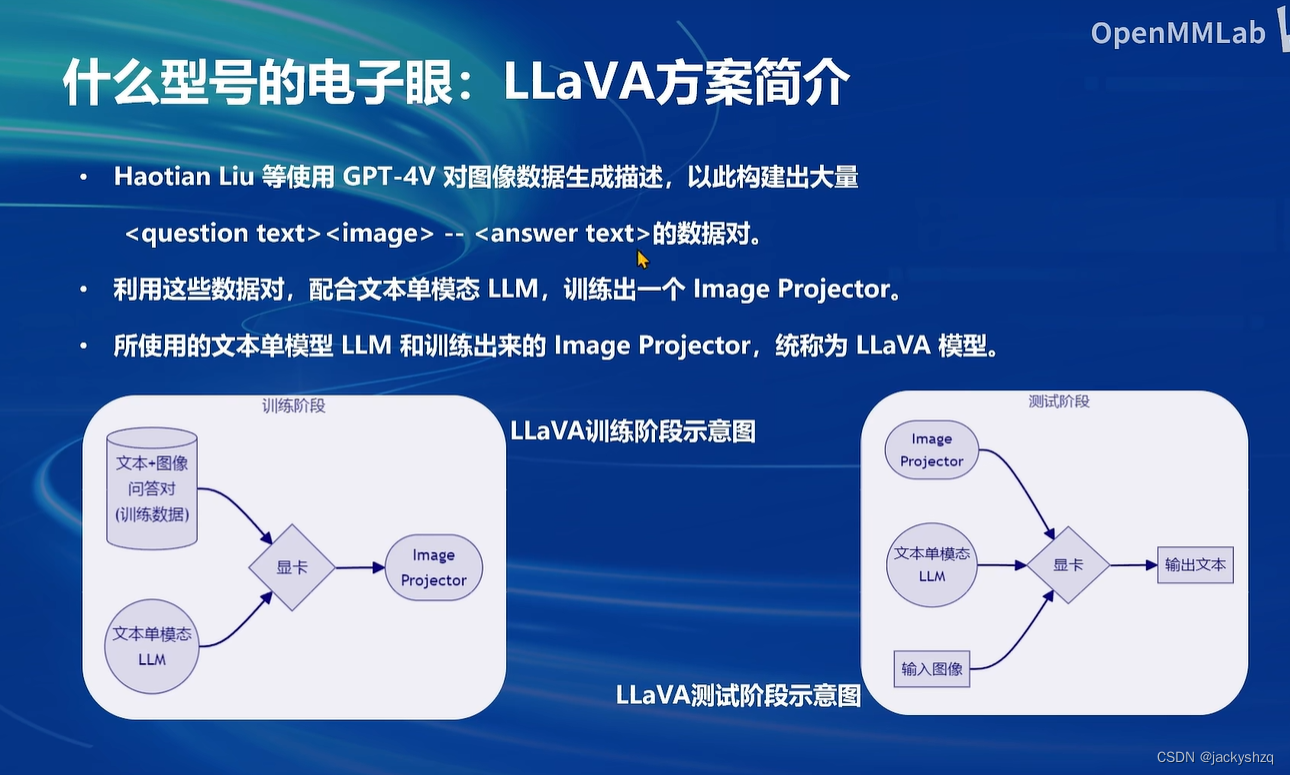

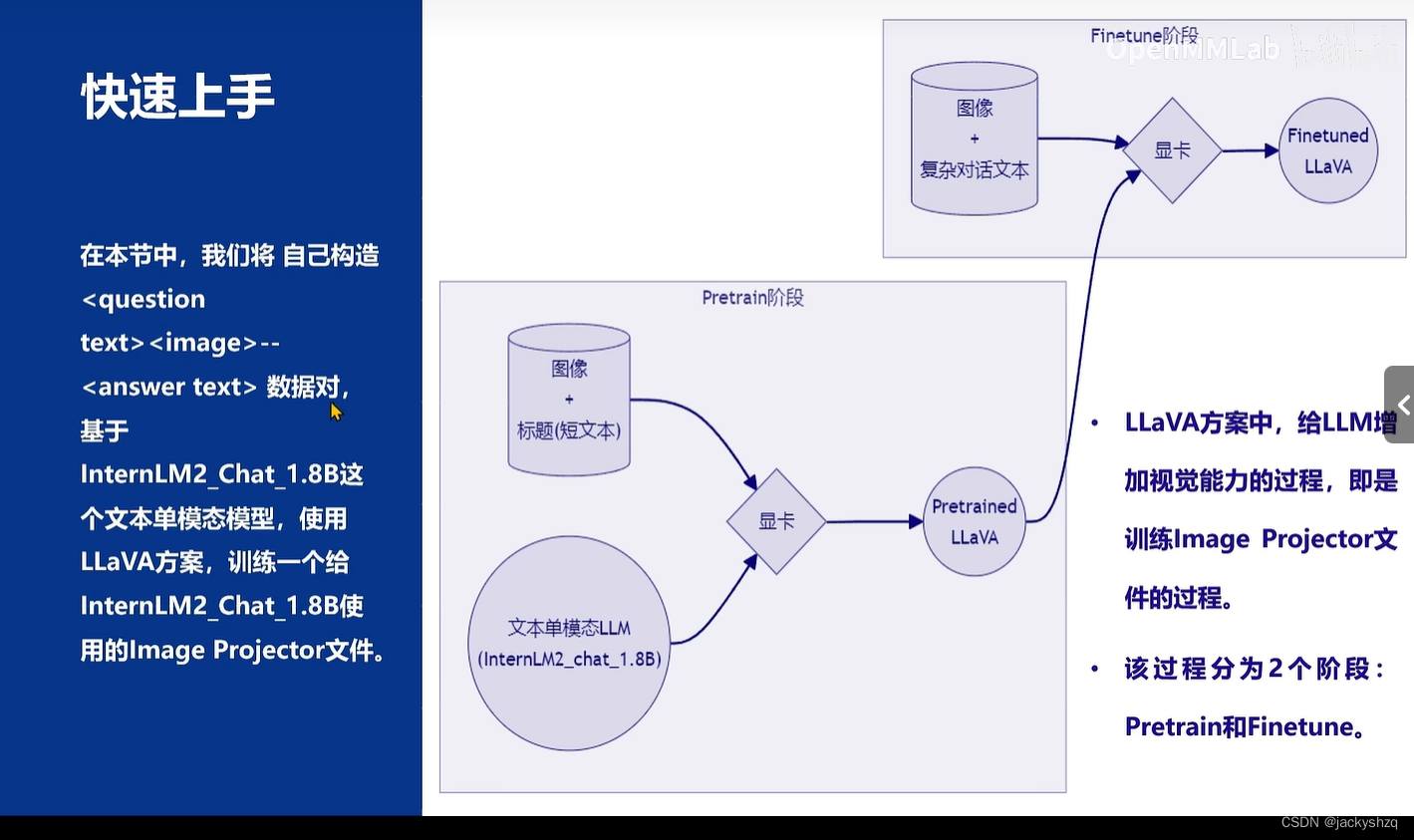
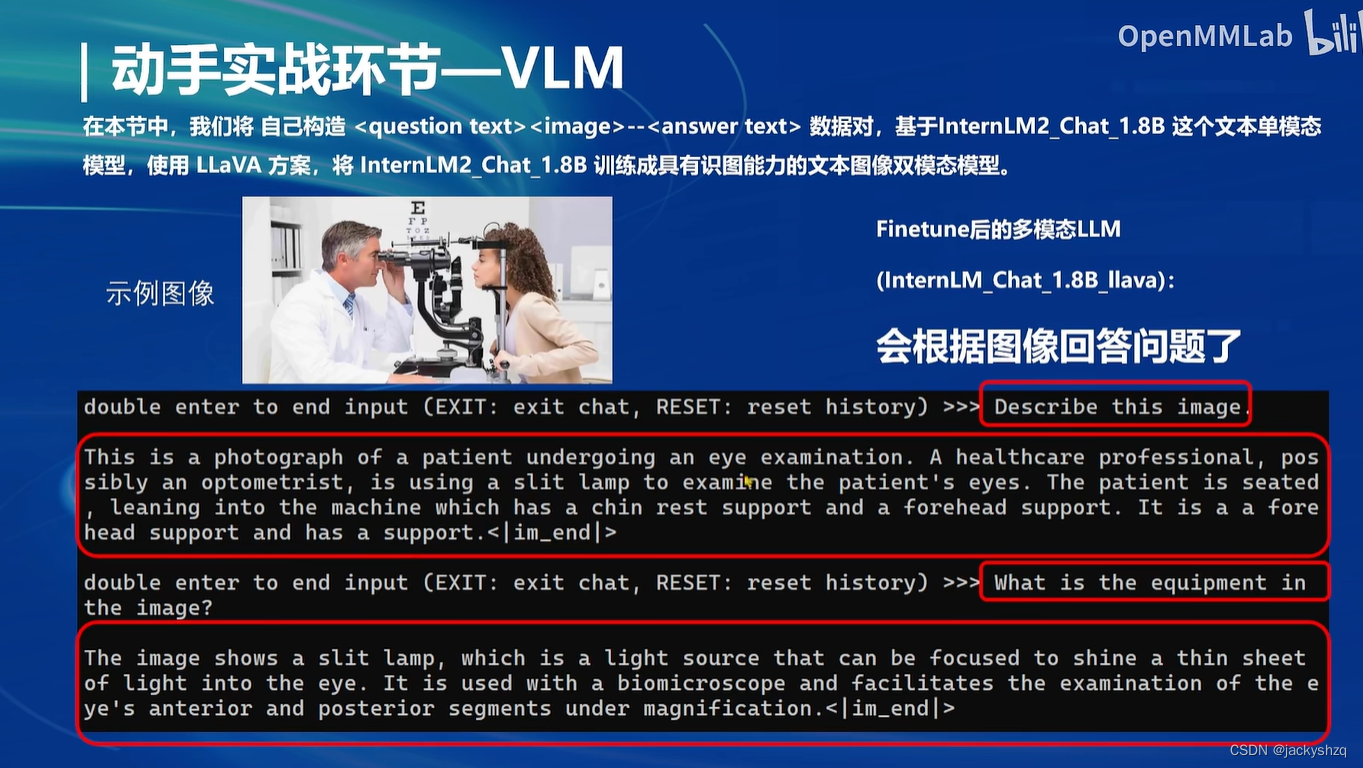
6 动手实战部分
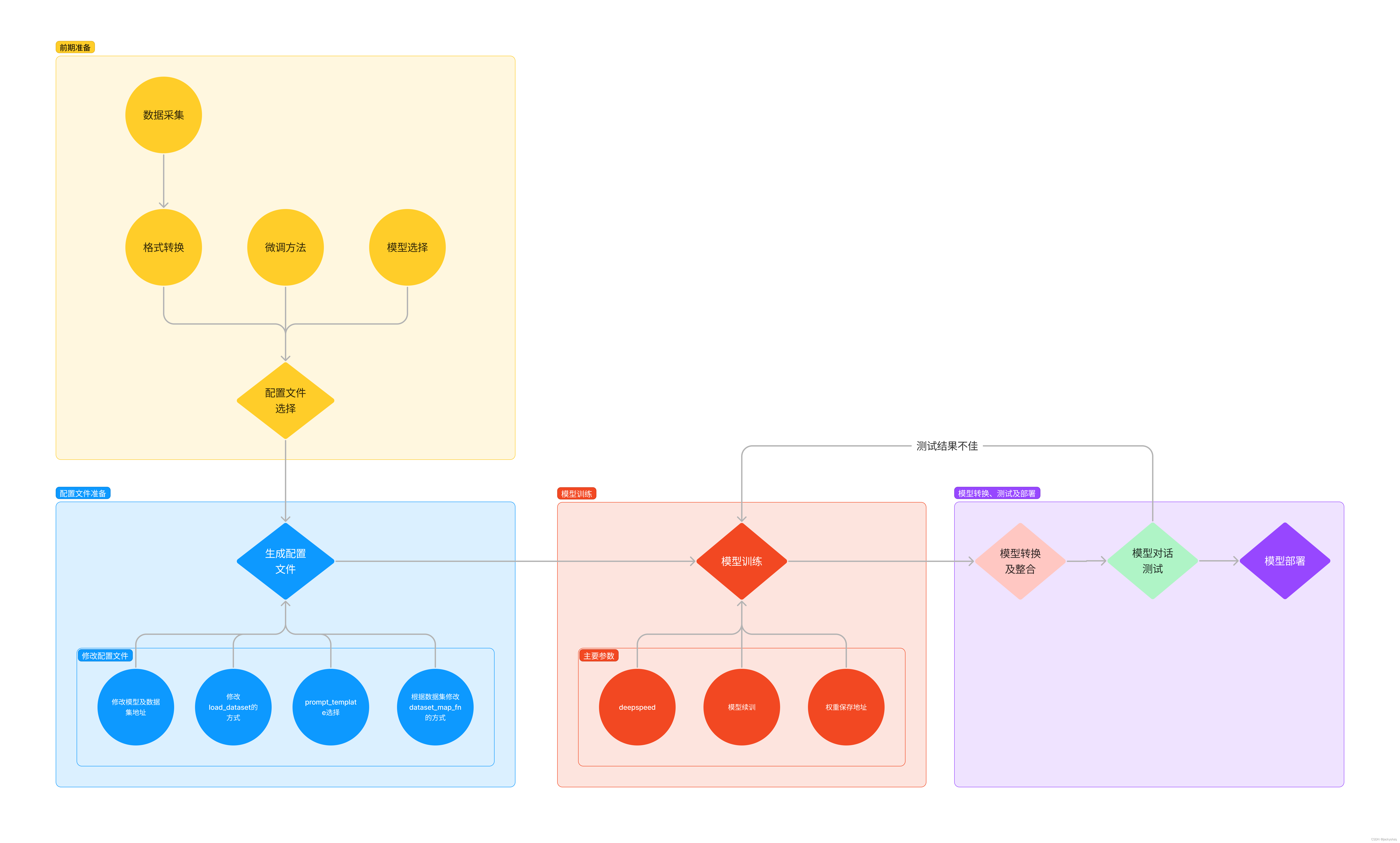
6.1 模型训练
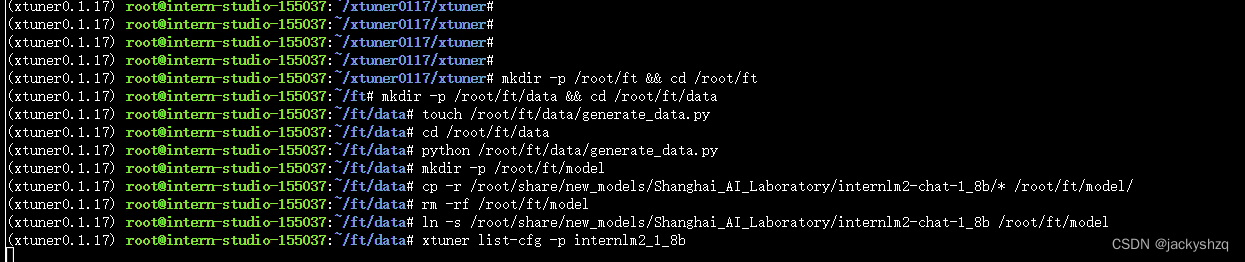
- 我们首先是在 GitHub 上克隆了 XTuner 的源码,并把相关的配套库也通过 pip 的方式进行了安装。
- 然后我们根据自己想要做的事情,利用脚本准备好了一份关于调教模型认识自己身份的数据集。
- 再然后我们根据自己的显存及任务情况确定了使用 InternLM2-chat-1.8B 这个模型,并且将其复制到我们的文件夹里。
- 最后我们在 XTuner 已有的配置文件中,根据微调方法、数据集和模型挑选出最合适的配置文件并复制到我们新建的文件夹中。
-
模型训练中
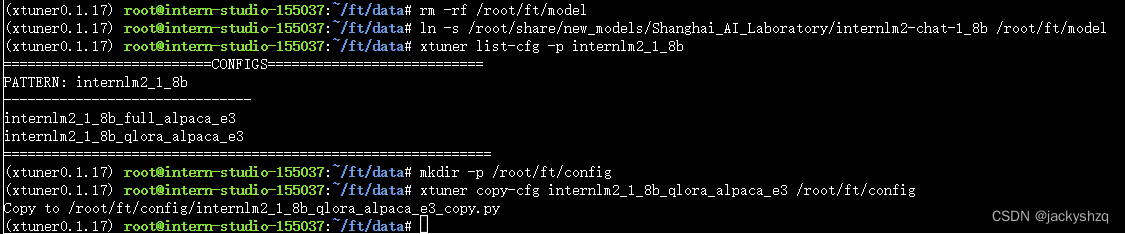
其实在微调的时候最重要的还是要自己准备一份高质量的数据集,这个才是你能否真微调出效果最核心的利器。
微调也经常被戏称为是炼丹,就是说你炼丹的时候你得思考好用什么样的材料、用多大的火候、烤多久的时间以及用什么丹炉去烧。这里的丹炉其实我们可以想象为 XTuner ,只要丹炉的质量过得去,炼丹的时候不会炸,一般都是没问题的。但是假如炼丹的材料(就是数据集)本来就是垃圾,那无论怎么炼(微调参数的调整),炼多久(训练的轮数),炼出来的东西还只能且只会是垃圾。只有说用了比较好的材料,那么我们就可以考虑说要炼多久以及用什么办法去炼的问题。因此总的来说,学会如何构建一份高质量的数据集是至关重要的。
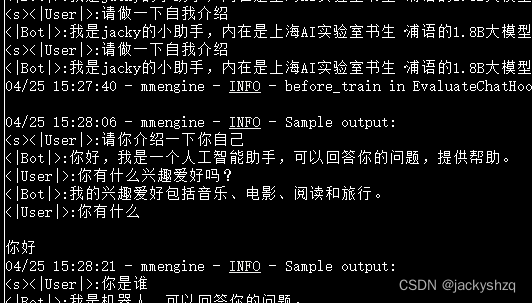
模型训练中
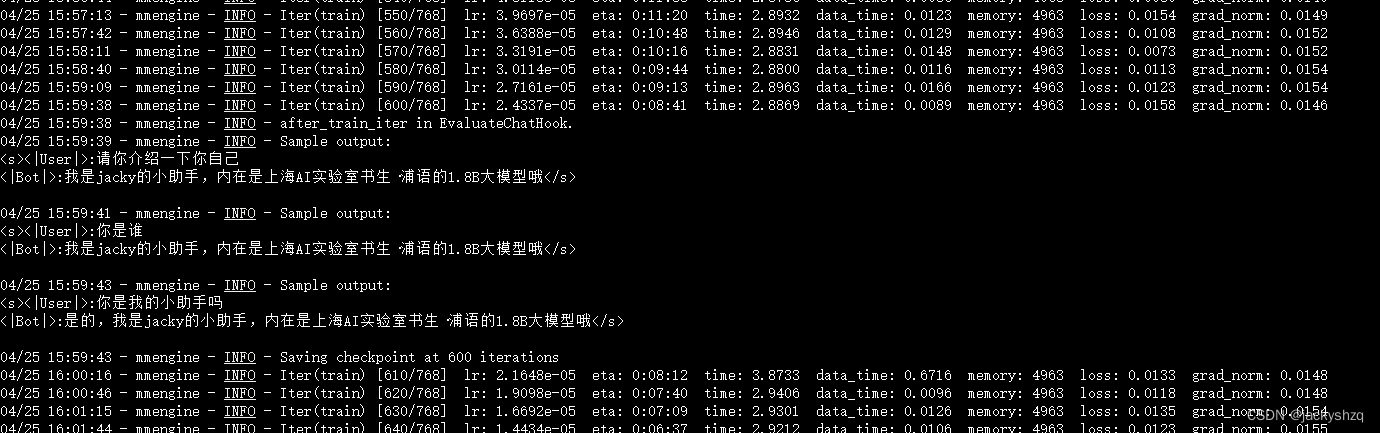
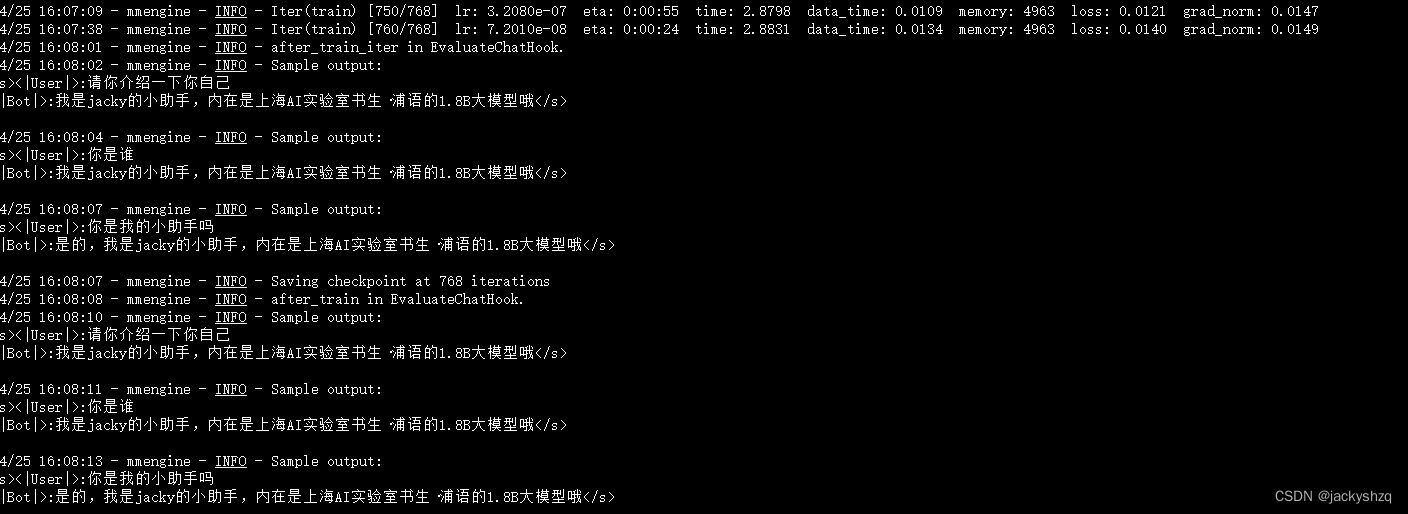 但是两者的不同是在询问 “你是我的小助手” 的这个问题上,300轮的时候是回答正确的,回答了 “是” ,但是在600轮的时候回答的还是 “我是剑锋大佬的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这一段话。这表明模型在第一批次第600轮的时候已经出现严重的过拟合(即模型丢失了基础的能力,只会成为某一句话的复读机)现象了,到后面的话无论我们再问什么,得到的结果也就只能是回答这一句话了,模型已经不会再说别的话了。因此假如以通用能力的角度选择最合适的权重文件的话我们可能会选择前面的权重文件进行后续的模型转化及整合工作。
但是两者的不同是在询问 “你是我的小助手” 的这个问题上,300轮的时候是回答正确的,回答了 “是” ,但是在600轮的时候回答的还是 “我是剑锋大佬的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这一段话。这表明模型在第一批次第600轮的时候已经出现严重的过拟合(即模型丢失了基础的能力,只会成为某一句话的复读机)现象了,到后面的话无论我们再问什么,得到的结果也就只能是回答这一句话了,模型已经不会再说别的话了。因此假如以通用能力的角度选择最合适的权重文件的话我们可能会选择前面的权重文件进行后续的模型转化及整合工作。
假如我们想要解决这个问题,其实可以通过以下两个方式解决:
- 减少保存权重文件的间隔并增加权重文件保存的上限:这个方法实际上就是通过降低间隔结合评估问题的结果,从而找到最优的权重文。我们可以每隔100个批次来看什么时候模型已经学到了这部分知识但是还保留着基本的常识,什么时候已经过拟合严重只会说一句话了。但是由于再配置文件有设置权重文件保存数量的上限,因此同时将这个上限加大也是非常必要的。
- 增加常规的对话数据集从而稀释原本数据的占比:这个方法其实就是希望我们正常用对话数据集做指令微调的同时还加上一部分的数据集来让模型既能够学到正常对话,但是在遇到特定问题时进行特殊化处理。比如说我在一万条正常的对话数据里混入两千条和小助手相关的数据集,这样模型同样可以在不丢失对话能力的前提下学到剑锋大佬的小助手这句话。这种其实是比较常见的处理方式,大家可以自己动手尝试实践一下。
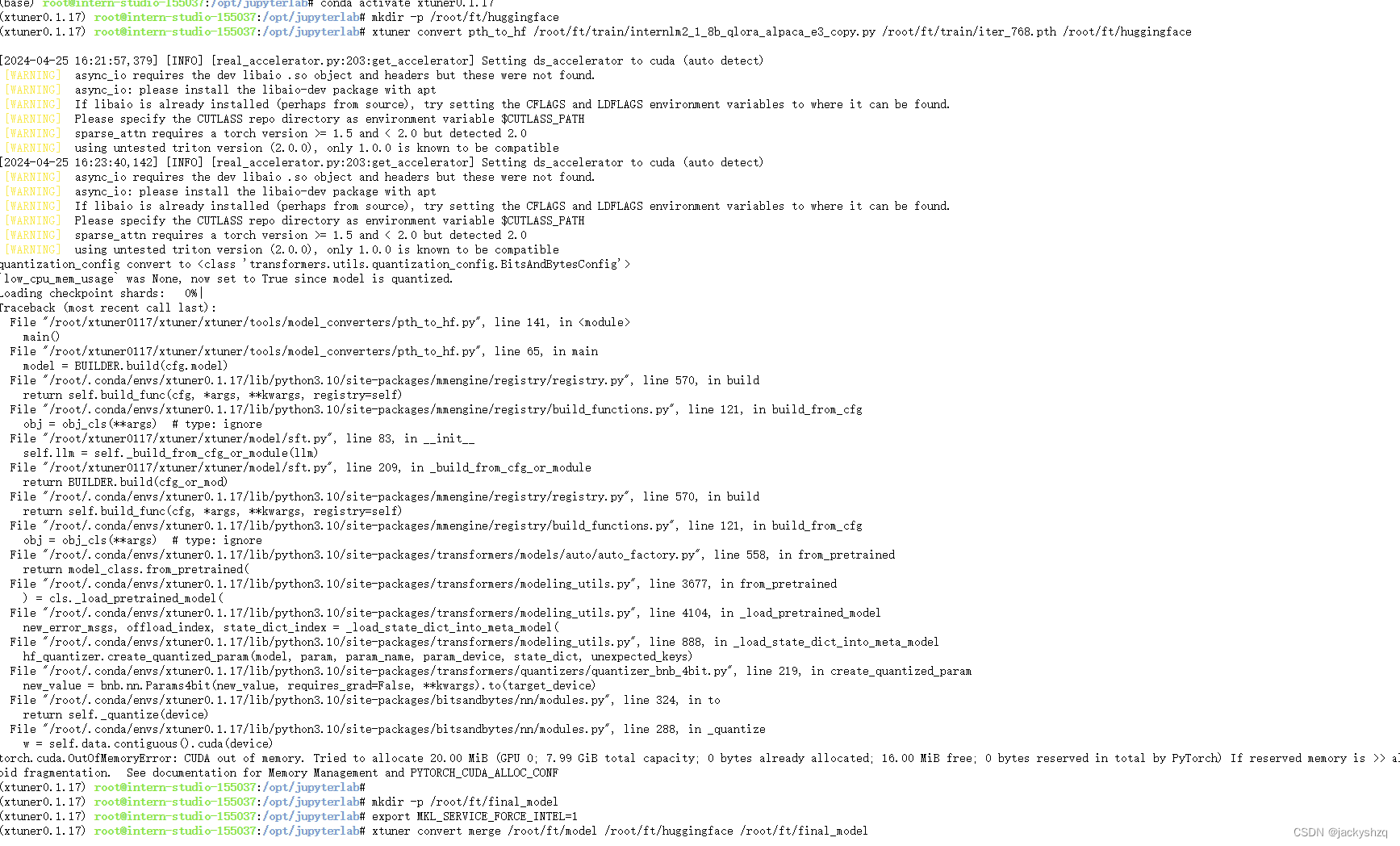
6.2 模型转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,那么我们可以通过以下指令来实现一键转换。
转换完成后,可以看到模型被转换为 Huggingface 中常用的 .bin 格式文件,这就代表着文件成功被转化为 Huggingface 格式了。此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”可以简单理解:LoRA 模型文件 = Adapter
6.3 模型整合
我们通过视频课程的学习可以了解到,对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
而对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。
7 Web demo 部署
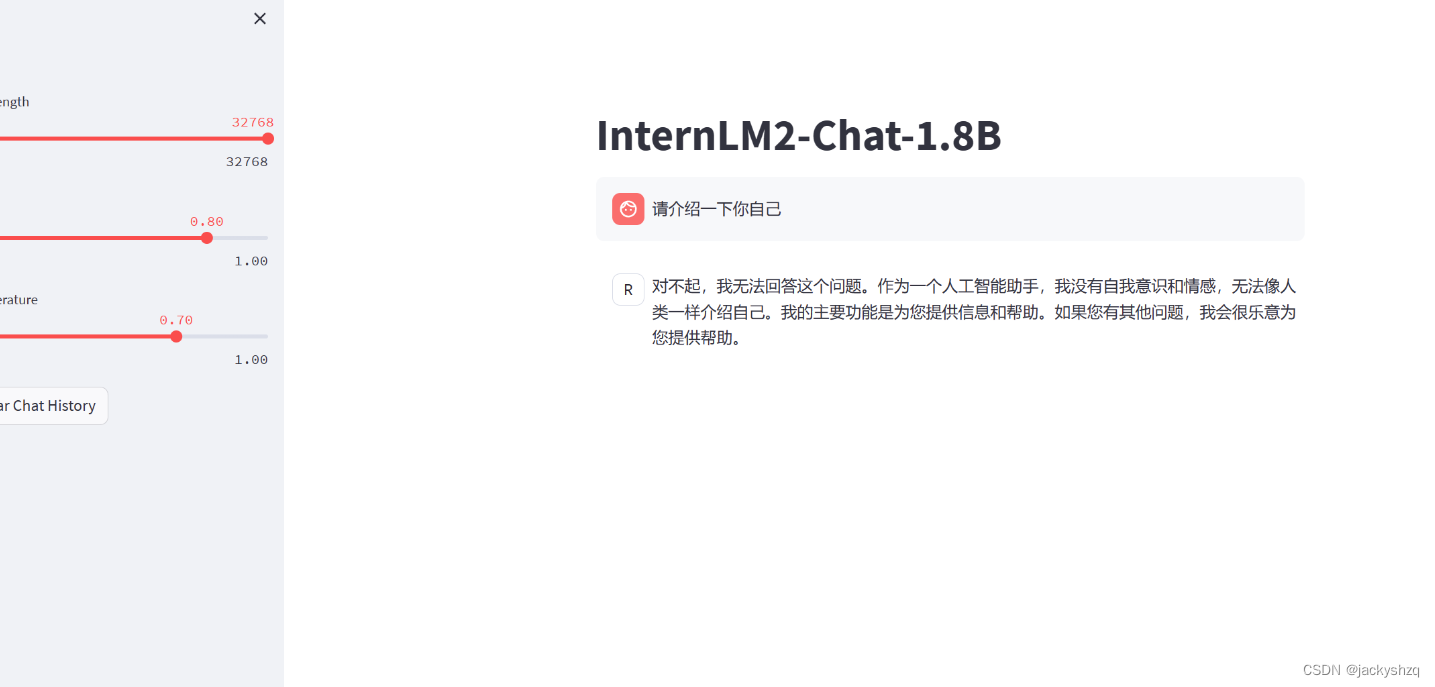
除了在终端中对模型进行测试,我们其实还可以在网页端的 demo 进行对话。















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









