






1.LMDeploy简介

1.1 面临的挑战
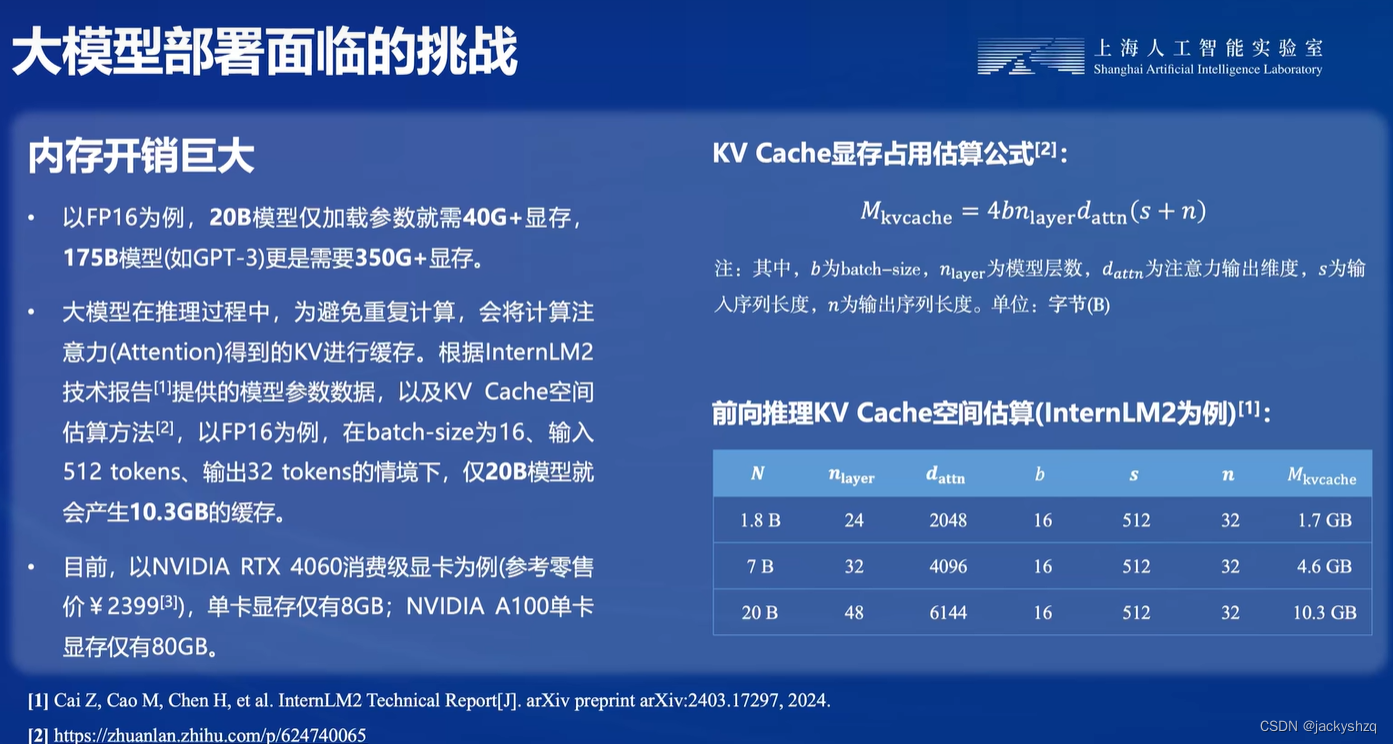
1.1.1 内存开销巨大
大模型训练的成本构成中,硬件投资包括算力、运力、存力,其中算力相关硬件投资占比80%。根据第一性原理,大模型训练时算力利用率低的诱因是海量的小文件,传统存储系统无法高效地处理这些数据,导致加载速度缓慢。大模型训练的效率要达到极致,减少不必要的浪费,必须在数据上下功夫,准确地说,必须要在数据存储性能上进行创新。
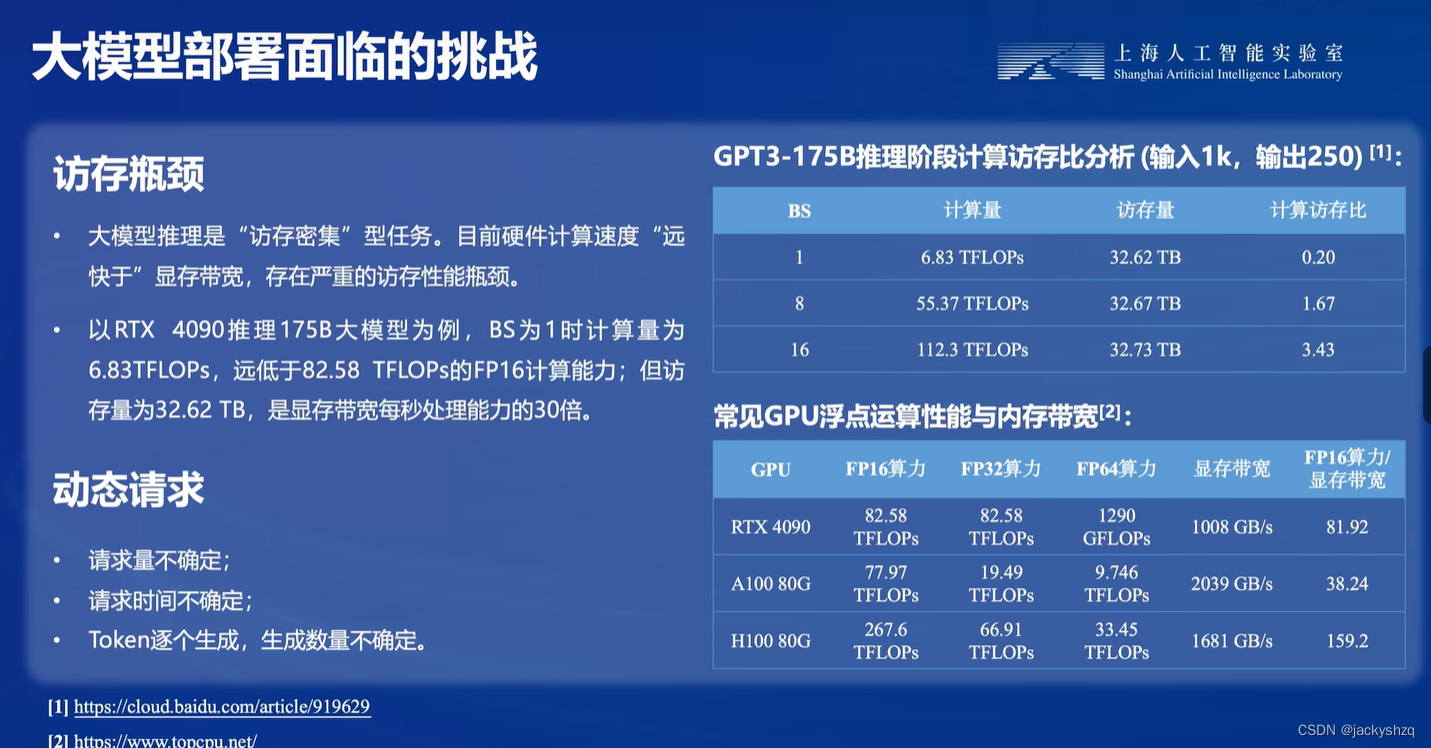
1.1.2 访问瓶颈
深度学习计算遇到的较大瓶颈其实是带宽问题,而非计算本身。由于深度学习里的特征表示本身就是稀疏的,因此我们做一个直接的剪枝压缩来减少带宽的使用。
1.1.3 动态请求
对于时间和算力的估计存在不确定性,可能会导致请求不具备可靠性。
1.2 解决方法
1.2.1 模型剪枝
一次性剪枝 VS 迭代性剪枝: 与一次性修剪网络相比,迭代修剪的中奖彩票在较小的网络规模下收敛更快,达到更高的精度
参数的初始化 VS 结构的重排:结构比初始化更重要,中奖彩票是初始化和结构的结合;无论是初始化还是结构本身都不能单独形成更好的性能

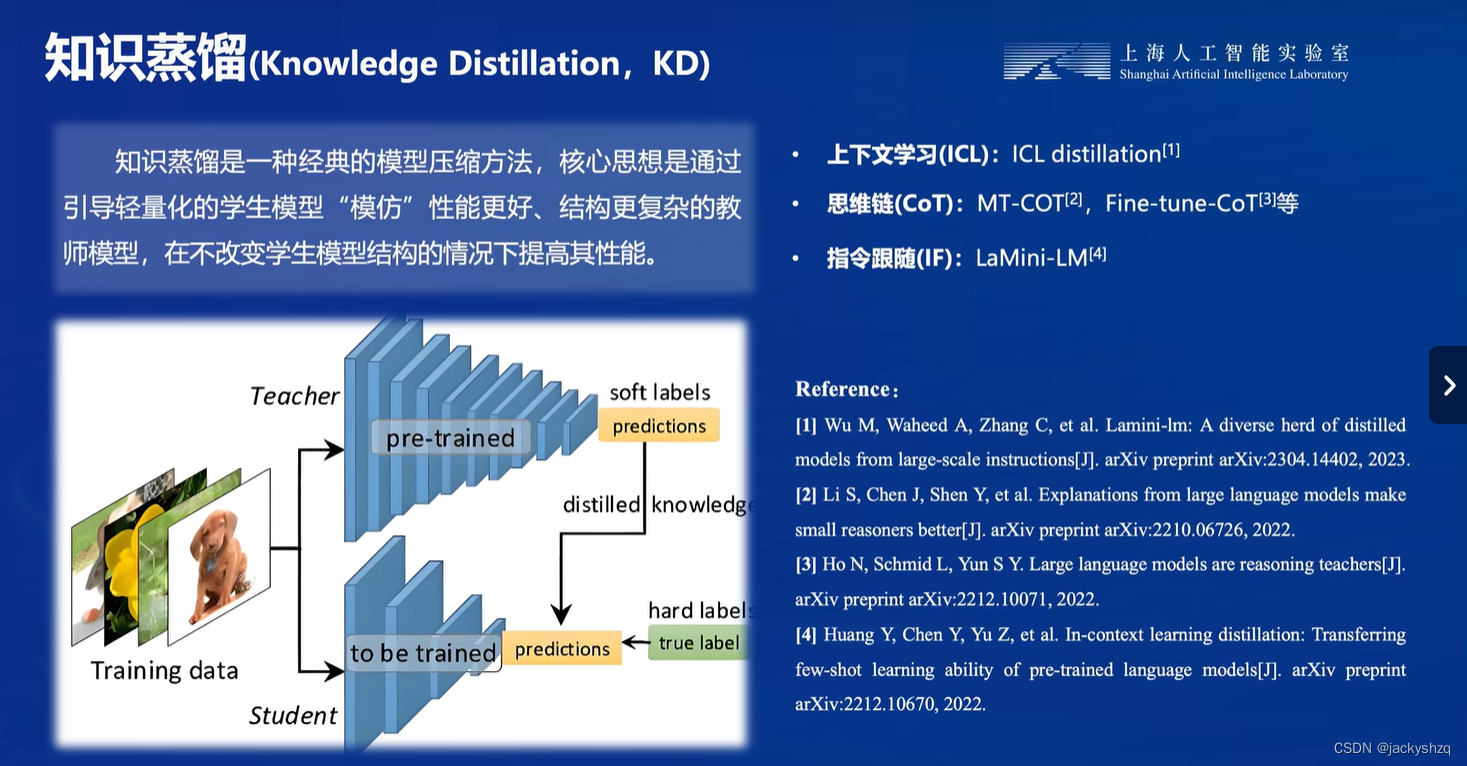
1.2.2 知识蒸馏
知识蒸馏的概念由Hinton在Distilling the Knowledge in a Neural Network中提出,目的是把 一个大模型或者多个模型集成 学到的知识迁移到另一个轻量级模型上。
1.2.3 量化
为了节省总用时,模型量化更通常的思路是:
- 按照平时训练模型的流程,设计好 Float 模型并进行训练(等同于得到一个预训练模型);
- 插入 Observer 和 FakeQuantize 算子,得到 Quantized-Float 模型(简称 QFloat 模型),量化感知训练;
- 进行训练后量化,得到真正的 Quantized 模型(简称 Q 模型),即最终被用作推理的低比特模型。(此时的量化感知训练 QAT 可被看作是在预训练好的 QFloat 模型上微调(Fine-tune),同时做了校准)
 1.3 LMDelopy核心功能
1.3 LMDelopy核心功能
LMDelopy的核心功能有模型高效推理、模型量化压缩、服务化部署。
 2 实战
2 实战
2.1 使用Transformer库运行模型

 2.2 使用LMDeploy与模型对话
2.2 使用LMDeploy与模型对话















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









