







目录
(2)使用长度为2的滚动数组优化空间,但时间复杂度并没有得到优化
五.动态规划
1.线性DP



(1)动态规划分析步骤

"""
dp[n]表示n个台阶方案数
dp[n]=dp[n-1]+dp[n-2]
dp[1]=1
dp[2]=2
"""
n=int(input())
dp=[0]*(n+1)#全是0的的列表,用于后续存储更新的方案数
dp[1]=1
dp[2]=2
for i in range(3,n+1):
dp[i]=(dp[i-1]+dp[i-2])%1000000007
print(dp[n])
"""
楼梯有 n 个台阶,每次可以一步上 1 阶、2 阶、…、k 阶。一共有多少种不同的上楼方法?
dp[n]表示n个台阶方案数
n>=k
dp[n]=dp[n-1]+dp[n-2]+...+dp[n-k]
n<k
dp[n]=dp[n-1]+dp[n-2]+...+dp[1]+1
"""(2)破损的楼梯3367
"""
破损的楼梯3367
https://www.lanqiao.cn/problems/3367/learning/?page=1&first_category_id=1&problem_id=3367
"""
import sys
sys.setrecursionlimit(100000)
n,m=map(int,input().split())
a=list(map(int,input().split()))
dp=[0]*(n+1)#dp 数组用于存储到达每一级台阶的方案数,dp[i] 表示到达第 i 级台阶的方案数
vis=[0]*(n+1)#vis 数组用于标记每一级台阶是否是坏的,vis[i] 为 1 表示第 i 级台阶是坏的,为 0 表示是好的
for x in a:
vis[x]=1
dp[0]=1#表示站在第 0 级台阶本身有一种方案,即不移动
dp[1]=1-vis[1]
#如果第 1 级台阶是好的(vis[1] = 0),则到达第 1 级台阶有一种方案(从第 0 级迈 1 级上来);
#如果第 1 级台阶是坏的(vis[1] = 1),则到达第 1 级台阶的方案数为 0
for i in range(2,n+1):
if vis[i]==1:
continue
dp[i]=(dp[i-1]+dp[i-2])%1000000007
print(dp[n])
"""
6 1
3
"""(3)安全序列3423
"""
安全序列3423
https://www.lanqiao.cn/problems/3423/learning/?page=1&first_category_id=1&problem_id=3423
"""
"""
dp[i]只需要考虑两种情况
不放置:从dp[i-1]转移#即第i个位置不放置油桶,则和前i-1个位置方案数一样
放置:从dp[i-k-1]转移#要在第 i 个空位放置油桶,且满足间隔条件,那么前一个油桶最远可以放在第 i - k - 1 个空位,所以此时的方案数就等于前 i - k - 1 个空位的放置方案数。
dp[i]=dp[i-1]+dp[i-k-1]
但需要考虑i-k-1<0时,如果要在第 i 个空位放置油桶,此时只有一种可能性,前面都是0,都不放1
"""
MOD=1000000007
n,k=map(int,input().split())
dp=[0]*(n+1)
#初始状态:没有空位不放置也是一种方案
dp[0]=1
#dp[i]表示前i个位置的方案数
for i in range(1,n+1):
if i-k-1>=0:
#i>=k+1:dp[i-1]:不放置;dp[i-k-1]:放置
dp[i]=(dp[i-1]+dp[i-k-1])%MOD
else:
#i<k+1:dp[i-1]:不放置;1:放置(要在第i个位置放,但前面的空位又不够,无法隔开,所以前面只能都不放,方案为1)
dp[i]=(dp[i-1]+1)%MOD
print(dp[n])
"""
4 2
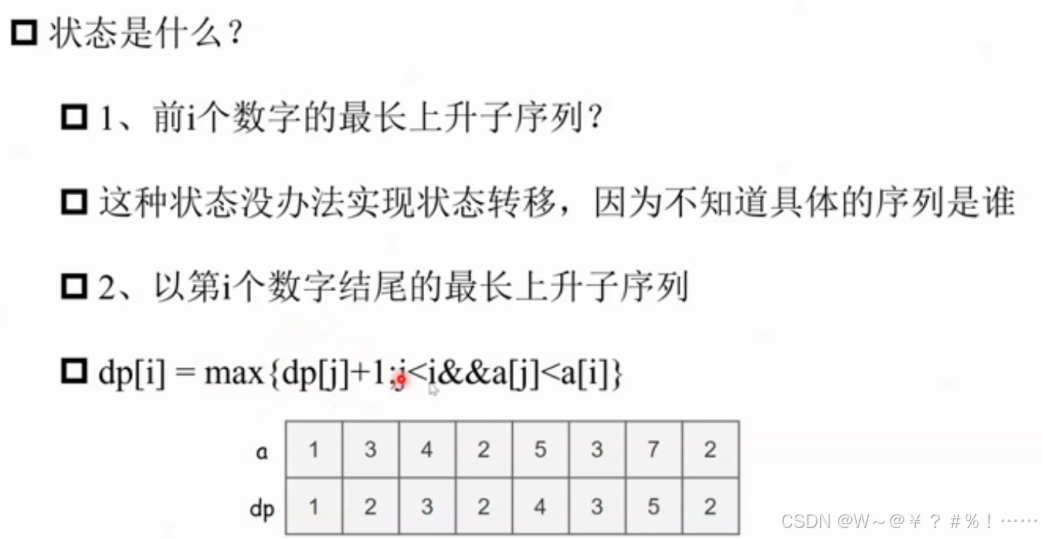
"""2.LIS-最长上升子序列

(1)蓝桥勇士2049
"""
https://www.lanqiao.cn/problems/2049/learning/?page=1&first_category_id=1&problem_id=2049
蓝桥勇士2049
"""
#dp[i]表示以第i个数字结尾的最长上升子序列长度
#dp[i]可以从dp[1]...dp[i-1]转移过来,前提是a[i]要比前一个大
#dp[i]=max(dp[i],dp[j]+1),j<i,a[j]<a[i]
n=int(input())
a=[0]+list(map(int,input().split()))
dp=[0]*(n+1)
for i in range(1,n+1):#dp[i]存储所有以第i个数字结尾的最长上升子序列长度
#更新dp[i]
dp[i]=1#至少包含自己
for j in range(1,i):#j<i,当i=1时不会执行内层
#在i的前面找到小于a[i]的数字a[j]
#用对应的dp值更新dp[i]
if a[j]<a[i]:
dp[i]=max(dp[i],dp[j]+1)#长度+1
#print(dp)
print(max(dp))
#如果 a[j] < a[i],说明可以将第 i 个数字添加到以第 j 个数字结尾的上升子序列后面,长度+1,此时更新 dp[i] 为 dp[i] 和 dp[j] + 1 中的较大值。
"""
6
1 4 3 2 5 6
"""(2)合唱队形742
"""
https://www.lanqiao.cn/problems/742/learning/?page=1&first_category_id=1&problem_id=742
合唱队形742
"""
n=int(input())
a=[0]+list(map(int,input().split()))
#dp1[i]表示以i结尾的最长上升子序列长度
#dp1[i]=max(dp1[i],dp1[j]+1),j<i,a[j]<a[i]
dp1=[0]+[1]*n
for i in range(1,n+1):
#更新dp[1]
for j in range(1,i):
if a[j]<a[i]:
dp1[i]=max(dp1[i],dp1[j]+1)
#dp2[i]表示从i出发的最长下降子序列长度
#dp2[i]=max(dp2[i],dp2[j]+1),j>i,a[j]<a[i]
dp2=[0]+[1]*n
for i in range(n,0,-1):# 外层循环从 n 到 1 倒序遍历
#更新dp2[i]
for j in range(i+1,n+1):
if a[j]<a[i]:
dp2[i]=max(dp2[i],dp2[j]+1)
#最终答案
ans=max([dp1[i]+dp2[i]-1 for i in range(1,n+1)])#i重复了,所以-1
print(n-ans)
#[dp1[i]+dp2[i]-1 for i in range(1,n+1)]=[3, 3, 2, 4, 3, 1, 3, 4]3.LCS-最长公共子序列

边界理解,只要有一个数组为空,它们的最长的公共子序列为0
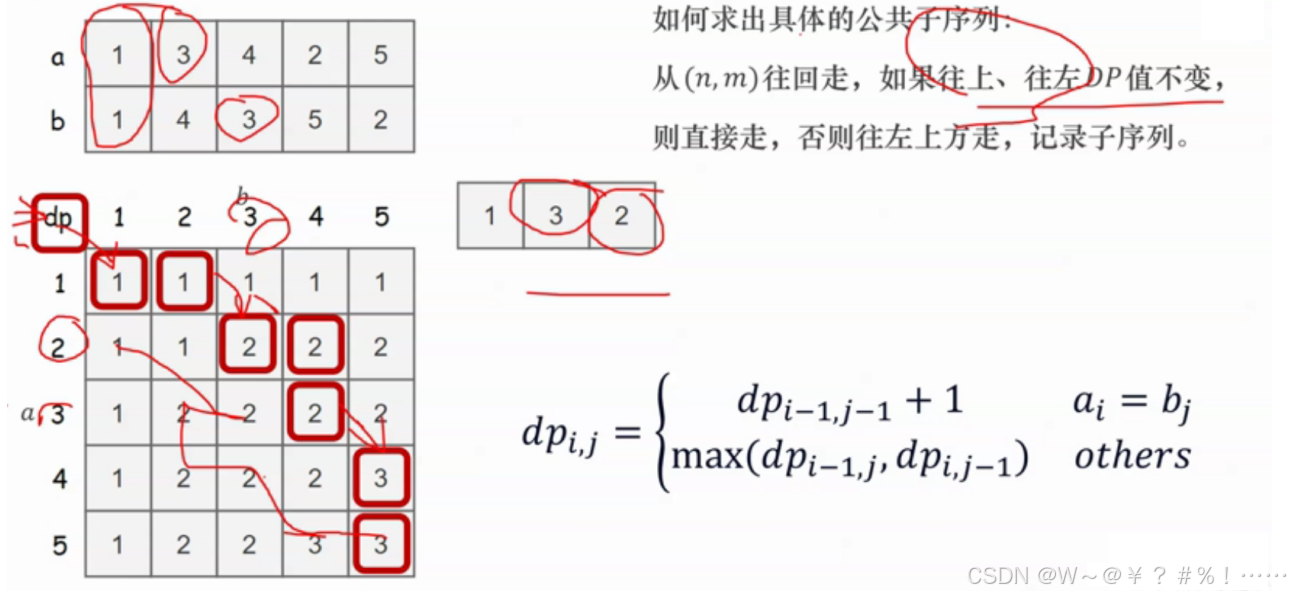
可以有多种走法,得到的最长公共子序列长度相同,比如132和145
(1)最长公共子序列1189
"""
https://www.lanqiao.cn/problems/1189/learning/?page=1&first_category_id=1&problem_id=1189
最长公共子序列1189
"""
#dp[i][j]表示a数组前i个,b数组前j个的最长公共子序列,
#公共子序列:数组a和b中均包含该子序列
n,m=map(int,input().split())
a=[0]+list(map(int,input().split()))
b=[0]+list(map(int,input().split()))
dp=[[0]*(m+1)for i in range(n+1)]#m+1列,n+1行,不是dp=[[0]*(n+1)for i in range(m+1)]
for i in range(1,n+1):#n行
for j in range(1,m+1):#m列
if a[i]==b[j]:
dp[i][j]=dp[i-1][j-1]+1
else:
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
#输出最长公共子序列的长度
print(dp[n][m])#不是max(dp)
"""
#ans表示最长公共子序列
ans=[]
x,y=n,m
while x!=0 and y!=0:
if dp[x][y]==dp[x-1][y]:#默认优先往上走
x-=1
elif dp[x][y]==dp[x][y-1]:
y-=1
else:
#此时a[x]==b[y]
ans.append(a[x])#因为a=[0]+list(map(int,input().split()))
x-=1
y-=1
#输出最长公共子序列
print(ans[::-1])#反序输出
"""
"""
5 6
1 2 3 4 5
2 3 2 1 4 5
"""4.二维DP

二维dp的有效下标都从1处理
(1)数字三角形1536


"""
https://www.lanqiao.cn/problems/1536/learning/?page=1&first_category_id=1&problem_id=1536
数字三角形1536
"""
#状态1写法
#下标统一从1开始
N=int(input())
a=[[0]*(N+1)]#或者a=[[0]]
dp=[[0]*(N+1)for i in range(N+1)]
for i in range(N):
a.append([0]+list(map(int,input().split())))
#dp[i][j]表示从(i,j)出发到底部的最大和
#最终答案=dp[1][1]
#(i,j)可以走到(i+1,j)或者(i+1,j+1)
#dp[i][j]=max(dp[i+1][j],dp[i+1][j+1])+a[i][j]
#更新时需要从下往上更新:从N到1
for i in range(N,0,-1):
#枚举第i行的每个位置,第i行有i个数字,下标从1到i
for j in range(1,i+1):
if i==N:#当 i == N 时,意味着当前处于数字三角形的最后一行。由于从最后一行的某个位置出发到底部的最大和就是该位置本身的值,所以此时直接将 dp[i][j] 赋值为 a[i][j]
dp[i][j]=a[i][j]
else:
dp[i][j]=max(dp[i+1][j],dp[i+1][j+1])+a[i][j]
print(dp[1][1])
"""
计算 dp[i][j] 需要知道 dp[i + 1][j] 和 dp[i + 1][j + 1] 的值。也就是说,我们需要先计算出下一行的状态,才能计算当前行的状态。
如果使用 for i in range(1, N + 1) 从上往下更新,那么在计算 dp[i][j] 时,dp[i + 1][j] 和 dp[i + 1][j + 1] 还没有被计算出来,无法得到正确的结果。
而使用 for i in range(N, 0, -1) 从下往上更新,我们先计算出最后一行的状态(最后一行每个位置到底部的最大和就是该位置本身的值),
然后逐步向上计算,这样在计算 dp[i][j] 时,dp[i + 1][j] 和 dp[i + 1][j + 1] 已经被计算出来了,可以直接使用状态转移方程进行更新。
"""
"""
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
""""""状态2写法"""
n=int(input())
a=[]
for i in range(n):
a.append(list(map(int,input().split())))
dp=[[0]*n for i in range(n)]
#dp[i][j]表示到达i,j的最大和
#i需要从上往下更新,枚举每一行
for i in range(n):
#枚举第j列
for j in range(i+1):
#边界
if j==0:
dp[i][j]=dp[i-1][j]+a[i][j]
elif j==i:
dp[i][j]=dp[i-1][j-1]+a[i][j]
else:
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1])+a[i][j]
print(max(dp[n-1]))#最大值在最后一行dp里0 - 1 背包问题:从大到小更新是为了控制物品的使用次数,每个物品只能选择一次,避免重复使用。
数字三角形问题:从下往上(从大到小)更新是为了满足状态转移的依赖关系,确保在计算当前状态时,所依赖的状态已经是最优解。
(2)摆花389

"""
https://www.lanqiao.cn/problems/389/learning/?page=1&first_category_id=1&problem_id=389
摆花389
"""
n,m=map(int,input().split())
a=[0]+list(map(int,input().split()))#下标从1开始
#dp[i][j]表示前i种花,选择出j盆的方案数
#最终答案dp[n][m]
dp=[[0]*(m+1)for _ in range(n+1)]
#状态之间如何转移
#如何利用先前的dp[0]...dp[i-1]来求dp[i][j]
#考虑当下第i种花的选择
#第i种花选择0盆:dp[i-1][j]#前i种花已经选择出j盆,所以第i种花只能选择0盆
#第i种花选择1盆:dp[i-1][j-1]
#第i种花选择2盆:dp[i-1][j-2]
#第i种花选择a[i]盆:dp[i-1][j-a[i]]
#最后累加
#边界:j=0,表示什么花都没选,它也是一种方案;i=0不需要考虑
for i in range(n+1):
dp[i][0]=1
for i in range(1,n+1):
for j in range(1,m+1):
#求解dp[i][j]
#枚举第i种花选择的盆数为k
for k in range(min(a[i],j)+1):#min(a[i],j)
dp[i][j]+=dp[i-1][j-k]
dp[i][j]%=1000007
print(dp[n][m])
"""
2 4
3 2
"""(3)选数异或3711
子序列:从初始序列中选出若干个数保持原有顺序的序列

"""
https://www.lanqiao.cn/problems/3711/learning/?page=1&first_category_id=1&problem_id=3711
选数异或3711
"""
"""
在 Python 以及大多数编程语言中,整数是以二进制形式存储的。当对两个或多个整数进行异或运算时,是对它们的二进制表示的每一位分别进行异或操作。
例如,有两个整数 a = 5(二进制表示为 0101)和 b = 3(二进制表示为 0011),它们进行异或运算 a ^ b 的过程如下:
plaintext
0101
^ 0011
------
0110
结果是 6(二进制 0110)。
"""
#子序列,原序列删掉某些后得到的序列,变成选与不选的dp问题
#原问题:给定n个正整数a,子序列异或为x,方案数
#子问题:前i个正整数,子序列异或为j,方案数
#dp[i][j]:前i个正整数,子序列异或为j,方案数
#基于dp[0]...dp[i-1],如何求dp[i][j]?
#选择第i个数字,dp[i][j]=dp[i-1][j^a[i]];因为dp[i-1][j^a[i]^a[i]]=dp[i][j]
#不选择第i个数字,dp[i][j]=dp[i-1][j]
n,x=map(int,input().split())
a=[0]+list(map(int,input().split()))
#dp[i][j]表示前i个数字异或得到j的方案数
dp=[[0]*64 for i in range(2)]
#0 异或一个数等于这个数本身
#边界:第一个数字不选:dp[1][0]=1;选dp[1][a[1]]=1。所以需要dp[0][0]=1就能更新确定dp[1]
#前 0 个数字异或得到 0 的方案数为 1
dp[0][0]=1
for i in range(1,n+1):
for j in range(64):#0<=x<=63,x不是异或范围!
dp[i%2][j]=(dp[(i-1)%2][j]+dp[(i-1)%2][j^a[i]])%998244353
print(dp[n%2][x])
"""
n,x=map(int,input().split())
a=[0]+list(map(int,input().split()))
#dp[i][j]表示前i个数字异或得到j的方案数
#这里 i 表示考虑前 i 个数字,范围是从 1 到 n;
#而 j 表示异或的结果,异或结果 j 的范围是 0 到 63,总共 64 种可能的取值。
dp=[[0]*64 for i in range(n+1)]
#边界:第一个数字不选:dp[1][0]=1;选dp[1][a[1]]=1。所以需要dp[0][0]=1就能更新确定dp[1]
dp[0][0]=1
for i in range(1,n+1):
for j in range(64):#0<=x<=63
dp[i][j]=(dp[i-1][j]+dp[i-1][j^a[i]])%998244353
print(dp[n][x])
"""像这样,dp[i]的更新只用到上一层dp[i-1],摆花也可以用滚动数组,减少空间复杂度
5.01背包



所谓的01,对应拿或者不拿
(1)小明的背包11174
"""
https://www.lanqiao.cn/problems/1174/learning/?page=1&first_category_id=1&problem_id=1174
小明的背包11174
"""
N,V=map(int,input().split())
dp=[[0]*(V+1) for i in range(N+1)]#因为i从1-N,j从0-V,初始化,包括边界
#dp[i][j]表示前i件物品,体积不超过j的最大价值
#i从1-N,j从0-V
for i in range(1,N+1):
wi,vi=map(int,input().split())
for j in range(0,V+1):
if j<wi:
dp[i][j]=dp[i-1][j]#在j没有达到wi前都是不拿:dp[1][0] = dp[0][0] = dp[0][1] = dp[0][2] ... dp[0][wi-1] = 0
#dp[2][0] = dp[1][0] = dp[1][1] = dp[1][2] ... dp[1][wi-1]
"""
当 i = 2 时
当考虑第二件物品时,读取其体积 w2 和价值 v2。
对于内层循环 for j in range(0, V + 1):
当 j < w2 时,当前背包容量装不下第二件物品,所以 dp[2][j] = dp[1][j]。
如果 j < w1,那么 dp[2][j] = dp[1][j] = dp[0][j] = 0。
如果 w1 <= j < w2,那么 dp[2][j] = dp[1][j] = v1。
这就是需要if j<wi:dp[i][j]=dp[i-1][j]更新的原因
"""
else:
dp[i][j]=max(dp[i-1][j],dp[i-1][j-wi]+vi)
#在j刚好达到wi才开始满足拿的条件,但你也可以选择不拿,所以在拿与不拿之间选择最大值,dp[1][wi] =max ( dp[0][wi] , dp[0][0]+vi )=vi
print(dp[N][V])"""错误写法,因为j<wi也要更新dp"""
N,V=map(int,input().split())
dp=[[0]*(V+1) for i in range(N+1)]
for i in range(1,N+1):
wi,vi=map(int,input().split())
for j in range(wi,V+1):
dp[i][j]=max(dp[i-1][j],dp[i-1][j-wi]+vi)
print(dp[N][V])(2)使用长度为2的滚动数组优化空间,但时间复杂度并没有得到优化
dp[i][j]的更新只用到上一层dp[i-1],就可以用滚动数组优化,可以减少空间
只需将第一个维度%2
只需要两行就可以存储dp
dp=[[0]*(V+1) for i in range(2)]
"""
第i件物品不拿
dp[(i-1)%2][j]
第i件物品拿
dp[(i-1)%2][j-wi]+vi
二者选最大,以及考虑临界j-wi的特殊情况
j<wi,只能从dp[(i-1)%2][j]转移过来,也是不拿
"""
N,V=map(int,input().split())
dp=[[0]*(V+1) for i in range(2)]
#dp[i][j]表示前i件物品,体积不超过j的最大价值
#i从1-N,j从0-V
for i in range(1,N+1):
wi,vi=map(int,input().split())
for j in range(0,V+1):
if j<wi:
dp[i%2][j]=dp[(i-1)%2][j]
else:
dp[i%2][j]=max(dp[(i-1)%2][j],dp[(i-1)%2][j-wi]+vi)
print(dp[N%2][V])(3)使用长度为1的滚动数组优化空间,时间复杂度也没有改变
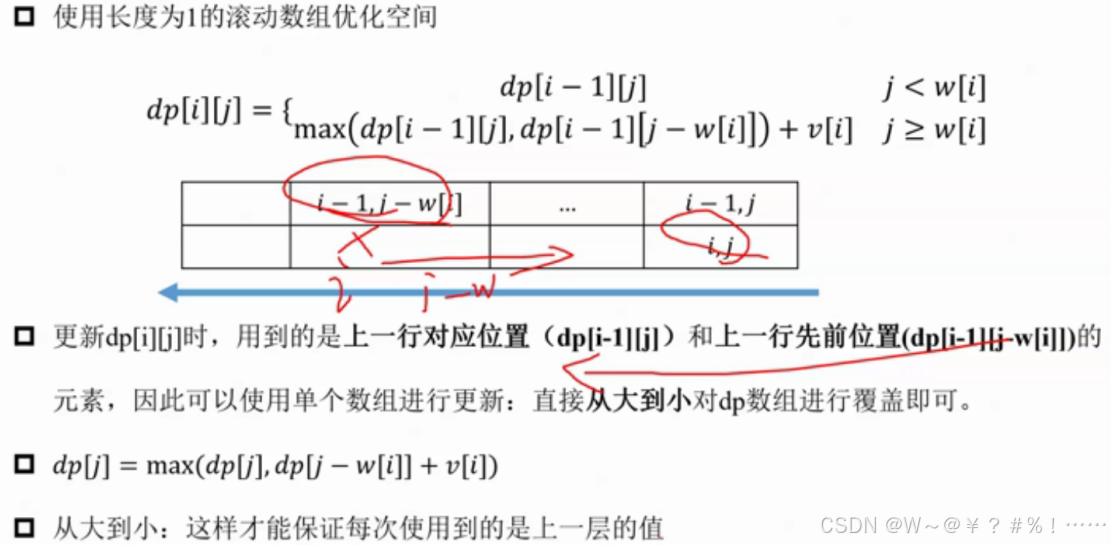
相当于把 i 维度消掉,因为我们只需考虑一定体积下最大价值,而不必考虑物品的件数
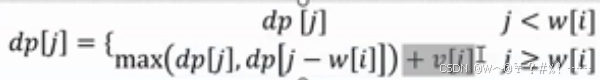
N,V=map(int,input().split())
dp=[0]*(V+1)
#dp[j] 表示背包容量为 j 时所能获得的最大价值
for i in range(N):
wi,vi=map(int,input().split())
#必须从大到小更新dp
for j in range(V,wi-1,-1):#wi<=j<=V
dp[j]=max(dp[j],dp[j-wi]+vi)
print(dp[V])
"""
dp[j] = max(dp[j], dp[j - wi] + vi) 表示对于当前容量为 j 的背包,有两种选择:
不选择当前物品 i,则背包的最大价值仍然是 dp[j]。
选择当前物品 i,即背包剩余容量为 j - wi(当你考虑把第 i 件物品放入容量为 j 的背包时,由于第 i 件物品的体积是 wi,那么放入这件物品之后,背包剩余的可使用容量就变为 j - wi。),
此时背包的最大价值为 dp[j - wi] + vi。
取这两种选择中的最大值作为 dp[j] 的新值。
"""
"""
要是从小到大更新 dp[j],当更新 dp[j] 时,dp[j - wi] 也许已经被更新过了,也就是 dp[j - wi] 也许已经包含了当前物品。
若继续使用这个 dp[j - wi] 来更新 dp[j],就相当于把当前物品多次放入了背包,这与 0 - 1 背包问题中每种物品仅有一个的条件不符。
而从大到小更新 dp[j],在更新 dp[j] 时,dp[j - wi] 还未被更新,它依旧是前 i - 1 个物品放入背包时的最大价值,这样就能保证每个物品仅被考虑一次。
"""6.多重背包


j-k*wi>0,所以k<j/wi,所以si要和j/wi取一个最小值
(1)小明的背包3 1176
"""
https://www.lanqiao.cn/problems/1176/learning/?page=1&first_category_id=1&problem_id=1176
小明的背包3 1176
"""
N,V=map(int,input().split())
dp=[[0]*(V+1) for i in range(N+1)]
for i in range(1,N+1):
#体积、价值、数量
wi,vi,si=map(int,input().split())
for j in range(0,V+1):
#dp[i][j],枚举k,k从0到si
#k表示第i件物品第k件
for k in range(0,min(si,j//wi)+1):
dp[i][j]=max(dp[i][j],dp[i-1][j-k*wi]+k*vi)#和自己比dp[i][j],不断更新最大值
print(dp[N][V])(2)新策略-二进制拆分si



(3)新一的宝藏搜寻加强版4059
"""
https://www.lanqiao.cn/problems/4059/learning/?page=1&first_category_id=1&problem_id=4059
新一的宝藏搜寻加强版4059
"""
N,V=map(int,input().split())
#N种物品,每种存在si件,拆成log件新物品
w_v=[]
for i in range(N):
wi,vi,si=map(int,input().split())#体积、价值和数量。
k=1
while si>=k:#si每种物品剩余数量
w_v.append((k*wi,k*vi))
si-=k
k*=2
if si!=0:
w_v.append((si*wi,si*vi))
dp=[0]*(V+1)
#print(w_v)
#[(20, 16), (40, 32), (20, 16), (2, 4), (4, 8), (8, 16), (16, 32), (2, 4), (10, 18), (20, 36), (30, 54), (18, 14), (36, 28), (72, 56), (126, 98), (18, 17), (36, 34), (36, 34)]
#w,v表示体积和价值;V表示背包的体积
#for i,(w,v) in enumerate(w_v):
for w, v in w_v:
for j in range(V,w-1,-1):
dp[j]=max(dp[j],dp[j-w]+v)
print(dp[V])
"""
enumerate(w_v) 会同时返回元素的索引 i 和元素本身 (w, v)
对于每个背包容量 j,有两种选择:
不放入当前物品,此时背包的最大价值仍然是 dp[j]。
放入当前物品,此时背包的最大价值是 dp[j - w] + v,其中 dp[j - w] 表示放入当前物品之前,背包容量为 j - w 时的最大价值,v 是当前物品的价值。
取这两种选择中的最大值作为 dp[j] 的新值,即更新背包容量为 j 时的最大价值。
"""wi,vi,si=map(int,input().split())#体积、价值和数量。注意对应
7.二维费用背包&分组背包
(1) 二维费用背包


把 i 维度删掉

"""
https://www.lanqiao.cn/problems/3937/learning/?page=1&first_category_id=1&problem_id=3937
小蓝的神秘行囊3937
"""
N,V,M=map(int,input().split())
#dp[V][M]
dp=[[0]*(M+1)for i in range(V+1)]
#前i件物品
for i in range(1,N+1):
#vi体积,mi重量,wi价值
vi,mi,wi=map(int,input().split())
#体积为j,从大到小,最小为vi
for j in range(V,vi-1,-1):
#重量为k,从大到小,最小为mi
for k in range(M,mi-1,-1):
#dp[i][j][k]=max(dp[i-1][j][k],dp[i-1][j-vi][k-mi]+wi)
dp[j][k] = max(dp[j][k], dp[j - vi][k - mi] + wi)
print(dp[V][M])(2)分组背包

"""
https://www.lanqiao.cn/problems/1178/learning/?page=1&first_category_id=1&problem_id=1178
小明的背包5 1178
"""
#N组物品,背包容积V
N,V=map(int,input().split())
#dp[i][j]前i组物品体积不超过j的最大价值
dp=[[0]*(V+1) for i in range(N+1)]
#最终答案是dp[N][V]
#枚举每组
for i in range(1,N+1):
s=int(input())#表示每组的物品个数
#枚举第i组的每件物品
for _ in range(s):
w,v=map(int,input().split())#表示物品的体积和价值
#对于每个体积j
for j in range(V+1):
#第i组的所有物品中取最大的一件物品,所以max有个dp[i][j],这是和01背包不同之处
if j<w:
dp[i][j]=max(dp[i][j],dp[i-1][j])
else:
dp[i][j]=max(dp[i][j],dp[i-1][j],dp[i-1][j-w]+v)
print(dp[N][V])
"""
#长度为2的滚动数组
N,V=map(int,input().split())
dp=[[0]*(V+1) for i in range(2)]
for i in range(1,N+1):
s=int(input())
for _ in range(s):
w,v=map(int,input().split())
for j in range(V+1):
if j<w:
dp[i%2][j]=max(dp[i%2][j],dp[(i-1)%2][j])
else:
dp[i%2][j]=max(dp[i%2][j],dp[(i-1)%2][j],dp[(i-1)%2][j-w]+v)
print(dp[N%2][V])
"""

j 从大到小不仅保证更新不出错,还恰好满足每组至多选择 1 个
#长度为1的滚动数组
N,V=map(int,input().split())
groups=[]
for _ in range(N):
s=int(input())
each_group=[list(map(int,input().split())) for i in range(s)]
groups.append(each_group)
#groups=[[[1, 4], [1, 6]], [[4, 9]], [[5, 5], [4, 5]]]
dp=[0]*(V+1)
#枚举每一组
for i in range(N):
#枚举每一种体积
for j in range(V,-1,-1):
#枚举第i组的每一件物品
for w,v in groups[i]:
if j>=w:
dp[j]=max(dp[j],dp[j-w]+v)
print(dp[V])
"""
groups=[]
for _ in range(N):
s=int(input())
each_group=[]
for _ in range(s):
each_group.append(list(map(int,input().split())))
groups.append(each_group)
""""""错误代码"""
N,V=map(int,input().split())
dp=[0]*(V+1)
for i in range(N):
s=int(input())
for _ in range(s):
w,v=map(int,input().split())
for j in range(V,w-1,-1):
dp[j]=max(dp[j],dp[j-w]+v)
print(dp[V])
#在分组背包问题中,需要对每组物品单独进行状态转移,保证每组物品只选一个或者不选。
#然而当前代码是对所有物品一起进行状态转移,这会导致可能从同一组中选择多个物品。8.树形DP
树上进行动态规划:
1、需要使用 DFS 遍历树结构
2、定义好状态和状态转移方程
经典问题:最大独立集
(1)蓝桥舞会1319


先遍历所有子节点,然后回溯就可以更新父节点的dp,这就是dfs
"""
https://www.lanqiao.cn/problems/1319/learning/?page=1&first_category_id=1&problem_id=1319
蓝桥舞会1319
"""
n=int(input())
a=[0]+list(map(int,input().split()))#编号从1开始,员工的快乐指数
G=[[]for i in range(n+1)]
#构建一个邻接表 G 来表示员工之间的关系,其中 G[i] 存储与员工 i 相邻的员工编号。
for i in range(n-1):#根节点只有一个,所以n-1
u,v=list(map(int,input().split()))
G[u].append(v)
G[v].append(u)
#邻接表G=[[], [2, 3], [1], [1]]
dp=[[0,0]for i in range(n+1)]#[[0, 0], [0, 0], [0, 0], [0, 0]]
#d[u][0]以u为根节点的子树下,不选择u的最大值
#d[u][1]以u为根节点的子树下,选择u的最大值
#fa-u-v
def dfs(u,fa):#u当前节点;fa先前的父节点,v子节点
dp[u][1]=a[u]#若选择节点 u,则初始的快乐指数为节点 u 的快乐指数。
dp[u][0]=0#若不选择节点 u,则初始的快乐指数为 0
#遍历所有u的儿子
for v in G[u]:
if v==fa:continue#若 v 是 u 的父节点,则跳过,避免重复遍历
dfs(v,u)#递归调用 dfs 函数,处理以 v 为根,以u为先前父节点的子树
"""
先递归,算出dp[v]的最大值,然后回溯返回时,才能更新dp[u]的最大值
"""
dp[u][1]+=dp[v][0]#选择u则所有子树v不可以选择其对应的根节点
dp[u][0]+=max(dp[v][0],dp[v][1])#不选择u,每个子树v可以自由决定选不选,哪个更大选哪个
dfs(1,0)#从节点 1 开始进行深度优先搜索,将其父节点设为 0
print(max(dp[1][0],dp[1][1]))print([0]*3)
print([[0]for _ in range(3)])
print([[0][0]for _ in range(3)])
print([[0,0]for _ in range(3)])
print([]*3)
print([[]for _ in range(3)])
print([[0]*3 for i in range(3)])
"""
[0, 0, 0]
[[0], [0], [0]]
[0, 0, 0]
[[0, 0], [0, 0], [0, 0]]
[]
[[], [], []]
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
"""(2)树的路径权值和

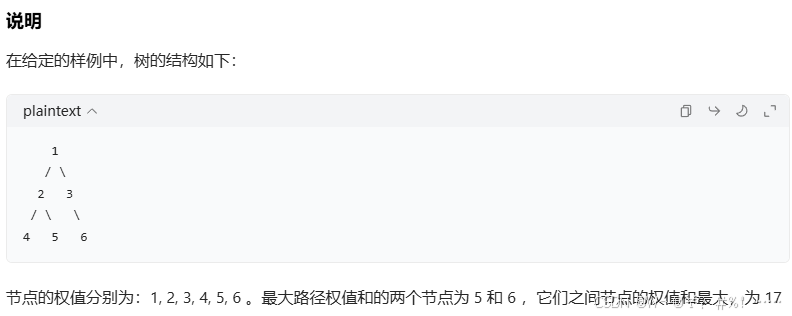

n=int(input())
G=[[]for i in range(n+1)]
for i in range(n-1):
u,v=list(map(int,input().split()))
G[u].append(v)
G[v].append(u)
a=[0]
for i in range(n):
a.append(int(input()))
#a=[0, 1, 2, 3, 4, 5, 6]存储对应节点的权值
dp=[[0,0]for i in range(n+1)]
#dp[u][0] 表示以节点 u 为根节点,从节点 u 出发的最长路径长度
#dp[u][1] 表示以节点 u 为根节点,从节点 u 出发的次长路径长度
#这里的路径长度是指路径上所有节点的权值之和,也就是在计算路径长度时会把路径上每个节点的权值累加起来
def dfs(u,fa):
"""
flag1:用于记录当前节点 u 的所有子节点中,从子节点出发的最长路径长度。初始值设为 0。
flag2:用于记录当前节点 u 的所有子节点中,从子节点出发的次长路径长度。初始值设为 0。
"""
flag1,flag2=0,0
#遍历所有儿子
for v in G[u]:
if v==fa:continue
dfs(v,u)
if dp[v][0]>flag1:#dp[v][0]子节点 v 的最长路径长度
flag2=flag1
flag1=dp[v][0]
elif dp[v][0]>flag2:#这里必须是elif,保证了逻辑的互斥性。当 dp[v][0] > flag1 条件成立时,更新 flag1 和 flag2,并且不会再去判断 dp[v][0] 是否大于 flag2,因为此时已经确定了新的最大和次大值。
"""
不能 if dv[v][0]<=flag1 and dv[v][0]>flag2:
假设当前 flag1 = 10,flag2 = 5,dp[v][0] = 15。
当执行 if dp[v][0] > flag1 时,条件成立,此时 flag2 被更新为原来的 flag1 即 10,flag1 被更新为 dp[v][0] 即 15。
接着执行 if dp[v][0] <= flag1 and dp[v][0] > flag2,此时 dp[v][0] = 15,flag1 = 15,flag2 = 10,
dp[v][0] <= flag1 成立,dp[v][0] > flag2 也成立,所以这个if语句也会执行。
本来是等价的,但是赋值操作改变大小关系
"""
flag2=dp[v][0]
#先递归,算出子节点 v 的最长路径长度dp[v][0],然后回溯返回,利用dp[v][0]更新flag1和flag2,进而更新dp[u]的最大值
dp[u][0]=a[u]+flag1#最大权值路径=所有儿子的最大值flag1加上当前的value
dp[u][1]=a[u]+flag2#次大权值路径=所有儿子的次大值flag2加上当前的value
dfs(1,0)
ans=0
#dp[u]表示以节点 u 为根节点,从节点 u 出发的最长和次长路径长度
#在树的最大路径权值和问题中,最大路径不一定经过根节点,所以需要遍历所有节点,通过比较不同节点处的最长路径和次长路径的组合情况来确定整棵树的最大路径权值和。
for i in range(1,n+1):
ans=max(ans,dp[i][0]+dp[i][1]-a[i],dp[i][0])
#dp[i][0] + dp[i][1]途径i节点的最大值和次大值加起来,a[i]是重复的值
#dp[i][0]只有一条边,没有次大值
print(ans)
"""
样例输入
6
1 2
1 3
2 4
2 5
3 6
1
2
3
4
5
6
样例输出
17
"""9.区间DP


(1)石子合并1233

"""
https://www.lanqiao.cn/problems/1233/learning/?page=1&first_category_id=1&problem_id=1233
石子合并1233
"""
n=int(input())
a=[0]+list(map(int,input().split()))#这种用到前缀和的,有效下标都从1开始
#Pre_sum 数组用于存储前缀和,Pre_sum[i] 表示前 i 堆石子的重量之和
Pre_sum=[0]*(n+1)
for i in range(1,n+1):
Pre_sum[i]=Pre_sum[i-1]+a[i]
#INF 是一个很大的数,用于初始化 dp 数组,表示初始时最小花费未知,设为一个较大值
INF=1e9+7
#dp[left][right]表示合并[left,right]中间的石子的最小花费
dp=[[INF]*(n+1)for i in range(n+1)]
#初始化:长度为1,只有一堆石子,无需合并,花费为 0,所以 dp[i][i] = 0
for i in range(1,n+1):
dp[i][i]=0
#dp[left][right]=Min(dp[left][mid]+dp[mid+1][right])+a[left]+...+a[right]
#变为前缀和
#dp[left][right]=Min(dp[left][mid]+dp[mid+1][right])+Pre_sum[right]-Pre_sum[left-1]
#枚举长度
for len in range(2,n+1):
#枚举左端点
for left in range(1,n+1):
#计算右端点
right=left+len-1
if right>n:break#break终止内层循环,继续下一次外层循环,continue跳过此次内层循环,继续下一次内层循环
#更新dp[left][right]
for mid in range(left,right):#mid<right,因为dp[mid+1][right]
dp[left][right]=min(dp[left][right],dp[left][mid]+dp[mid+1][right]+Pre_sum[right]-Pre_sum[left-1])
"""
枚举分割点 mid:将区间 [left, right] 分割成 [left, mid] 和 [mid + 1, right] 两部分,
合并这两部分的最小花费为 dp[left][mid] + dp[mid + 1][right],
再加上合并这两部分的额外花费 Pre_sum[right] - Pre_sum[left - 1],取最小值更新 dp[left][right]
"""
#表示合并区间 [1, n] 内的石子的最小花费
print(dp[1][n])
"""
4
4 5 9 4
"""
"""
在石子合并问题中,我们要把区间 [left, right] 内的石子合并成一堆,为了得到最小的合并花费,
会尝试把这个区间在不同的位置 mid 处进行分割,将其分成 [left, mid] 和 [mid + 1, right] 这两个子区间。
若 mid 等于 left,那么分割后的两个子区间就是 [left, left] 和 [left + 1, right]。
这种分割是有意义的,因为它代表着把区间 [left, right] 从最左边开始分割,即把第一堆石子单独分开,其余的石子作为另一部分。
若 mid 等于 right,分割后的两个子区间就是 [left, right] 和 [right + 1, right]。
然而,[right + 1, right] 这个区间是不合法的,因为左端点 right + 1 大于右端点 right,不存在这样的区间,所以在逻辑上没有意义。
"""(2)涂色926

"""
https://www.lanqiao.cn/problems/926/learning/?page=1&first_category_id=1&problem_id=926
涂色926
"""
S=input()
n=len(S)
#dp[left][right] 表示给字符串中从索引 left 到 right 的子串涂色所需的最少颜色数。
#初始时,将 dp 数组所有元素设为 100(一个较大的值,用于后续取最小值),1<=n<=50,即dp最大为50
dp=[[100]*n for i in range(n)]
#边界情况:长度为1,只有一个字母,需要涂一次
for i in range(n):
dp[i][i]=1
#枚举长度
for len in range(2,n+1):#尽管有效下标是从0开始,但长度可以达到n,保证right=left+len-1的最大值达到n-1
#枚举左端点
for left in range(n):
#计算右端点
right=left+len-1
if right>=n:
break
#更新dp[left][right]
if S[left]==S[right]:
#RGBGR=RGBG,GBGR
dp[left][right]=min(dp[left][right-1],dp[left+1][right])
else:
for mid in range(left,right):
dp[left][right]=min(dp[left][right],dp[left][mid]+dp[mid+1][right])
#表示给字符串[0,n-1]的子串涂色所需的最少颜色数
print(dp[0][n-1])
"""
RGBGR
"""

















 4049
4049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









