







import praw
import pymongo
from datetime import datetime
from pymongo import MongoClient
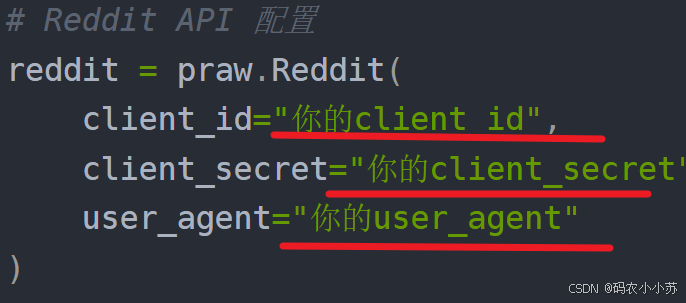
# Reddit API 配置
reddit = praw.Reddit(
client_id="你的client_id",
client_secret="你的client_secret",
user_agent="你的user_agent"
)
# MongoDB 连接配置
client = MongoClient('mongodb://localhost:27017/')
db = client['reddit_db']
collection = db['reddit_posts']
def scrape_reddit_data(subreddit_name, limit=10):
"""
抓取指定subreddit的帖子数据
Args:
subreddit_name (str): 要抓取的subreddit名称
limit (int): 要抓取的帖子数量
"""
subreddit = reddit.subreddit(subreddit_name)
for post in subreddit.hot(limit=limit):
post_data = {
'author': str(post.author),
'title': post.title,
'score': post.score,
'url': post.url,
'created_utc': datetime.fromtimestamp(post.created_utc),
'post_id': post.id,
'permalink': post.permalink,
'num_comments': post.num_comments,
'scraped_at': datetime.utcnow()
}
# 将数据存入MongoDB
try:
collection.update_one(
{'post_id': post.id}, # 查找条件
{'$set': post_data}, # 更新的数据
upsert=True # 如果不存在则插入
)
print(f"成功保存帖子: {post.title}")
except Exception as e:
print(f"保存帖子时出错: {str(e)}")
if __name__ == "__main__":
# 使用示例
subreddit_name = "python" # 你想抓取的subreddit
scrape_reddit_data(subreddit_name, limit=20)
使用这个代码之前,你需要先:
- 安装必要的包:
pip install praw pymongo
- 获取 Reddit API 凭证:
- 访问 https://www.reddit.com/prefs/apps
- 创建一个新的应用
- 获取 client_id 和 client_secret
- 确保本地运行了 MongoDB 服务
代码说明:
-
这个脚本会抓取以下数据:
- 作者名称
- 帖子标题
- 点赞数
- 帖子URL
- 创建时间
- 帖子ID
- 永久链接
- 评论数
- 抓取时间
-
数据会保存到本地 MongoDB 的
reddit_db数据库中的reddit_posts集合 -
使用
update_one配合upsert=True确保不会重复存储同一个帖子 -
可以通过修改
subreddit_name和limit参数来抓取不同版块的不同数量的帖子
这一块需要自己改


















 5404
5404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











