









文章目录
java实践3之大话线程、手写线程池、理解核心参数
一、创建线程和使用
在java中,创建一个线程,可以继承Thread,也可以实现 Runnable 接口。然后重写run方法,或者实现Callable接口实现call方法。(使用demo,大家自行查找)
在使用中一般需要知道下面的几个知识点。
1、启动调用
注意start()方法和run()方法。start才是开启线程,run方法只是普通的方法,是没有多线程效果的。当调用start()启动线程后,并不是马上就可以运行,必须得等CPU来处理,当线程被调度并获得CPU资源时,才会运行。(这个在培训的时候早就说过了,还用你来说?大家别着急先记一下这俩方法,后面线程池会说道,线程池执行的run,而不是start)
实现Callable接口的话。执行Callable任务后,可以获取一个Future的对象,调用它的get方法可以获取返回值,注意get方法是阻塞的,任务不完成,get会一直阻塞,不会继续向下执行。它是如何获取返回值呢?面试事为什么有时候会说,实现线程就Thread和Runnable2种呢?下面线程池原理会提到,相信大家就会有答案了。
2、volatile关键字
volatile关键子,这个就比较重要的了,它的主要作用是保证变量的可见性。在多线程编程时经常会用到,尤其是在多个线程访问静态变量时,如果不理解volatile,则特别容易出错。
执行下面代码:a线程访问变量flag,b线程也访问变量flag。
public static boolean flag = false;
public static void main(String[] args) throws Exception {
new Thread(new Runnable() {
@Override
public void run() {
// 监控下面的线程是否执行完毕,否则一直监控,
// 下面线程执行完后,则停止
while (!flag) {}
}}).start();
Thread.sleep(10);
new Thread(new Runnable() {
@Override
public void run() {flag = true;}
}).start();
}
我们可以运行一下,看到程序陷入了死循环,为什么会死循环呢,b线程明明已经更改了flag,a线程得到最新数据,判断后应该停止啊? 先看一下java内存模型抽象图
java内存模型抽象图:
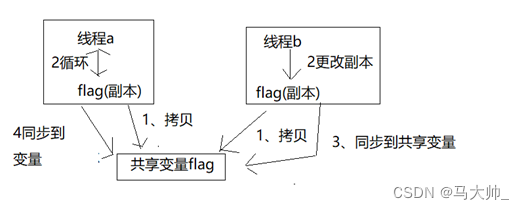
线程a启动时会从主内存中拷贝flag到此线程的内存中做副本。线程b启动时也是从主内存中拷贝flag,到此线程的内存中做副本。 当线程b修改flag时,先修改的是本地的flag副本,然后再同步到共享变量。
为何线程要做副本呢?这么做的好处是什么,我理解为,我们一般做优化时,例如:一些不太重要的数据计算,其实也是从远端,同步一份最新数据,放到本机做副本,然后实时计算,定时再向上推送一批数据的。减少本地和外部交互次数,能解决IO、连接等资源。
刚好jvm中的优化器也是这么想的,JNI会对我们的程序进行优化,由于每个线程都有自己的工作内存,为了加快cpu运行速度,不用每次都去主内存中去查询修改,它会把flag拷贝到本线程中做副本。所以最终会造成程序“错误”。
这里怕误导大家,最终造成程序 “错误”,我写的是“错误”,不是死循环,单纯的运行demo会死循环,有的文章中说demo中线程1运行一定次数后,JNI会判定为热点代码,while (!flag) {}相当于while(true){}。这个我不太赞同,因为没看过底层源码不敢瞎说,如果在循环体中增加一些语句,则程序就会退出循环,但何时退出,所以我认为不使用volatile会总成程序则不可控。
所以我认为多线程访问共享变量,不是死循环问题,而是要注意不加volatile可能会造成程序运行错误,并且程序不可控等问题。
volatile可见性:使用volatile修饰flag后,无论线程a或b访问本地副本时,都会先去同步主内存中的flag,然后再进行操作,操作完成后也会马上同步到主内存。这就是volatile的保证变量的可见性。注意:a线程->flag副本->主内存共享flag ,其中副本到住内存是原子性的、没有并发问题,但是a线程到flag副本不是原子性的,所以volatile只是保证可见性,并不保证并发问题。
volatile防止指令重排: 定义 int a=1;int b=1;编译器有可能会优化成int b=1;int a=1;有依赖的话,如果改变顺序程序会出错,所以它不会去优化。这点我觉着不重要。实际应用中我没碰到过因代码重排而出现的问题,也没听说过谁在生产系统中因为指令重排导致了问题。
另外:除了volatile外,也可以为flag属性增加update方法,用synchronized修饰此方法。更改时通过update方法来修改flag的值。由于使用了synchronized,也可以保证变量的可见性,由于synchronized比较重所以建议优先尝试volatile。
3、yeild()和join()
yield:表示这个线程不着急,它自己可以先等等,让其他的线程先运行,当前线程可能会暂停,也可能不会。
join:内部调用了wait(等待)方法,wait(等待)多久可以设置,调用此方法会阻塞,一直等到这个线程完成,再向下运行。例子:
Thread t=new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println("子线程开始执行");
Thread.sleep(1000);
System.out.println("子线程执行完毕");
} catch (Exception e) {
e.printStackTrace();
}
}});
t.start();
t.join();//内部调用了wait,进行阻塞,执行完t线程后才会向下执行,如果不调用join,则不阻塞,继续执行下面的语句
System.out.println("主线程执行完毕");
一般能用到的场景为:假如2个线程A和B,必须等到A执行完,B才可以执行,可以尝试jion方法。如果有这种依赖的场景的话,我会把A、B合并,串行处理。如果有多个线程依赖的话,我会用futrue的get方式。
4、其他
其他还有一些我们可能会用到的方法,比如:
1、setName(设置线程名称)
2、setPriority(更改线程优先级)
3、sleep(让此线程休眠),
4、wait(当前线程进入等待,等待nofity唤醒,需要和notify和nofityall连用,或者设置等待时间)
5、notify(唤醒正在等待此对象监视器的单个线程)
6、notifyAll(唤醒正在等待此对象监视器的所有线程)
知道一下即可,用的不是很多。
二、线程池
1、为什么使用线程池
开发中,在使用多线程处理业务时,我们常常会用到多线程技术。线程每次的创建、销毁、线程之间的切换都是需要耗费资源的。当线程过多时,而对应的CPU和CPU核心数没有增加的话,就会造成资源浪费、系统死机、程序缓慢等一系列问题。
比如我是餐厅的老板(服务器),如果每来一桌客人(每一次请求),都雇佣个服务员来处理 (创建线程),这样是需要花大量的金钱的(耗费资源),在厨师(CPU)就一位的情况下,服务员越多耗费的工资就得多开(小号资源多),厨师也得来回处理看每个服务员的菜单 根据菜的快慢决定出菜顺序,太慢的放后 (线程切换),也不会提升效率,并且当客人减少时,我们要辞掉服务员 是要赔偿N+1的(耗费资源)。
这时我们就要使用线程池技术,来管理优化多个线程,避免线程多次创建、销毁和减少线程之间的切换,造成的一些问题。
2、创建线程池5种类型
CachedThreadPool 可缓存线程池:特点是无限大,同时提交1w个任务就创建1w个线程,提交多少就创建多少个线程执行,只要服务器资源够。个人认为哈这个没用,完全没解决问题,放弃。
FixedThreadPool 定长线程池:这个是比较常用的,不会像CachedThreadPool一样,同时来多少就创建多少,它是根据初始化的入参,去创建固定大小的线程,去执行任务的。入参设置5的话,那么他同时跑的线程就5个,同时提交超过5个的话,多余的任务都缓存在队列中。
SingleThreadExecutor 单线程池:同时只有1个线程运行,不知道这个什么用,使用Executors.FixedThreadPool(1)就可以了。
ScheduledThreadPool 任务调度线程池: 可设置任务运行时间间隔的线程池。
newWorkStealingPool 工作窃取线程池: 这个没用过不了解。
注意:使用FixedThreadPool时,队列可容纳的任务为int的最大值,任务比较多也会造成内存溢出,可以直接使用ThreadPoolExecutor。
3、线程池核心参数和原理
线程池的核心参数是什么?线程池是怎么保证线程不用频繁创建、销毁线程的,我们提交任务到线程池的时候,他内部不也要start启动线程吗?我们使用Fixed线程池时,放到队列中,它是先启动几个任务线程任务,等运行完了,销毁刚才的线程任务,再启动几个吗?如果是的话,那他这个只是限流了啊,没有减少线程创建销毁啊?只是进行了限流,该干的一点没少啊。
这些问题面试多线程时经常会被问到,怎么办?赶紧背吧,什么核心参数啊,什么源码啊,赶紧背一遍,然而第二天又忘了,内容实在是太多了。其实理解了他们之后,就很容易了,不需要背。
3.1、线程池是如何保证线程频繁创建和销毁的?
1)首先向线程池提交任务。调用execute方法。(这不是重点)
2)execute这里调用了addworker 传入我们新建的任务。(这也不是重点)
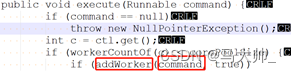
3)然后addWorker内部,创建了worker对象。这里要注意它启动的是woker的thread线程,而不是把我们提交的任务start。(这个是重点,它启动的是他自己创建的线程,不是我们提交的,我们提交的叫任务不叫线程)

4)在来看一下worker对象,在3)中启动的是woker的线程,然后调用runWorker方法。

5)最后看一下runworker,可以看到它执行了我们提交的task任务,注意上面说的线程启动调用。这里他调用了任务的run方法,根本就没启动。(这个也很重要)
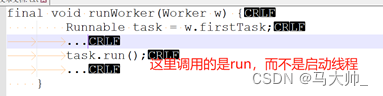
通过上面就理解了:首先我们提交到线程池的叫做任务,而不是线程,当时开发人员估计是为了方便所以直接沿用了Runable。线程池它自己会创建线程,然后start启动他自己创建的线程,来执行我们提交的任务run方法,执行完run后继续从队列Queue中取任务来执行。没任务则阻塞 或者结束线程。
举个例子,假设 有10个任务提交到线程池,线程池设置为2. 那么线程池,内部会创建2个线程启动,他们分别会从队列中取出来任务(一个一个取,取一个执行一个,完毕再取下一个),来执行run方法(不是start启动),。
理解了线程池的原理,也就理解了Callable获得的返回值,如何实现了吧。它就是套了一个Thread,然后start开启这个thread,在这个thread的run方法中执行我们的call方法,get的时候会判断线程是否执行完毕,未完毕继续等,完了的话就返回call的结果。
3.2、核心参数
这个核心参数的话,我是这样理解的。知道了线程池的原理,假如自己实现线程池,需要关注哪些。推理一下大概就知道了。
- 线程池可接收任务的总大小 得关注,不能来几亿个任务都放队列里吧,应该设置大小,超过,就不应该接收了。否则会内存溢出。
- 还有执行的任务线程数 得关注吧,不能同时执行开启几千几万个线程吧, cpu就那么几个核数。也就是一共就几个人,弄几万个项目同时干,来回切换项目也很麻烦(线程切换),这也不现实。
我认为这2个参数就是核心了。其他就是一些就看具体业务了,我认为不是很重要,比如woker一直没有任务,要不要回收,是否允许增加一些冗余线程(比如zf机构不也有一些临时工嘛,正式员工比较少,一般会配备几个临时工,完事直接回收),线程运行时间要不要做控制,要不要做超时处理等等。
3.3、CountDownLatch使用
在实际场景中CountDownLatch也经常会使用,它就是一个线程安全的计数器,例如:有a、b、c 3个线程,c线程需要等a和b完成后,才能执行。那么就需要这个计数器了。
例子:
ExecutorService es = Executors.newFixedThreadPool(3);
//初始化一个计数器初始值为3
final CountDownLatch latch = new CountDownLatch(3);
for (int x = 0; x < 3; x++) {
es.submit(new Runnable() {
public void run() {
latch.countDown();// 做完了计数器-1
}});
}
// 等待计数器归0,所有都执行完成后继续向下执行
latch.await();
// 注意调用shutdown后,不在接收新的任务,内部任务完成后,
// 会关闭池子里的那些线程并停止。
// 否则池子里的那些worker线程会一直阻塞,等待新的任务提交。
es.shutdown();
System.out.println("完成");
这个的原理也很简单,我们自己弄个变量也可以。
1)、初始化值为线程数,
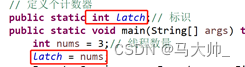
2)、定义自减方法

3)使用cas的方式(也可以使用其他方式),去监控latch的值,当latch=0时,说明所有线程运行完了,则退出循环。
完整demo:
public final class Test {
// 定义个计数器
public static int latch;// 标识
public static void main(String[] args) throws Exception {
int nums = 3;// 线程数量
latch = nums;
ExecutorService es = Executors.newFixedThreadPool(nums);
for (int x = 0; x < nums; x++) {
es.submit(new Runnable() {
public void run() {
try {
// 做一些事情
Thread.sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
countDown();// 做完了计数器-1
}});}
// 等待计数器归0,所有都执行完成后继续向下执行
await();
// 注意调用shutdown后,不在接收新的任务,内部任务完成后,
// 会关闭池子里的那些线程并停止。
// 否则池子里的那些worker线程会一直阻塞,等待新的任务提交。
es.shutdown();
System.out.println("完成;latch="+latch);
}
public static synchronized void countDown() {
latch--;
}
public static void await() throws Exception {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
long offer = unsafe.staticFieldOffset(Test.class.getDeclaredField("latch"));
int result = -1;
boolean flag = false;
while (!flag) {
flag = unsafe.compareAndSwapInt(Test.class, offer, 0, result);
}
}
}
4、实现自己的线程池
那么现在我们来实现以下自己的线程池
1、定义个接口,让其他任务实现这个接口,helloword中执行 要执行的方法。
public interface TaskInterface { public void helloword(String treadname); }
2、定义核心线程,数组和队列,队列存放要执行的任务,数组存放执行任务的线程
Thread[] hexinthread = new Thread[workerNums];//工作线程数
BlockingQueue bufqueue = new ArrayBlockingQueue(maxTaskLen);;//执行任务的队列
3、开启我们的线程
4、 对外提供add接口,让上游可以添加任务
public void addTask(TaskInterface tic) {
bufqueue.offer(tic);
}
大家先想一下思路自己实现一下。
完整demo
接口
public interface TaskInterface {
public void helloword(String treadname);
}
实现类
public class TaskInterfaceImp implements TaskInterface {
public void helloword(String treadname) {
System.out.println(treadname + "执行" );
}
}
自定义线程池
public class SelfThreadChi {
Thread[] hexinthread = null;
BlockingQueue<TaskInterface> bufqueue = null;
int workerNums;
int maxTaskLen;
//任务计数器
AtomicInteger jishuqi = new AtomicInteger(0);
// 让用户初始化时 填入工作线程数 和 可接收的任务数 多了就拒绝
public SelfThreadChi(int workerNums, int maxTaskLen) {
this.workerNums = workerNums;//
this.maxTaskLen = maxTaskLen;
hexinthread = new Thread[workerNums];// 初始化
bufqueue = new ArrayBlockingQueue<TaskInterface>(maxTaskLen);// 初始化
for (int i = 0; i < workerNums; i++) {
String name = "线程" + i;
// 新建new一个我们自己的thread 从队列中取任务,然后执行helloword方法
hexinthread[i] = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
// 从队列中取 ,没有就阻塞,有就执行下面(可以使用其他方式 这里只是简单举个例子)
TaskInterface ti = bufqueue.take();
// 取完了就开始执行
ti.helloword(name);
// 队列中的任务计数器 -1
jishuqi.decrementAndGet();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
});
// 启动我们自己的线程
hexinthread[i].start();
}
}
// 接收外部传过来 要执行的任务
public void addTask(TaskInterface tic) {
// 队列没超过边界则添加到执行队列中,等待执行
if (jishuqi.get() < maxTaskLen) {
// 计数器+1
jishuqi.incrementAndGet();
bufqueue.offer(tic);
} else {
System.out.println("没添加成功,任务队列满了");
}
}
}
main函数
public static void main(String[] args) {
SelfThreadChi stc = new SelfThreadChi(5, 20);
for (int i = 0; i < 50; i++) {
stc.addTask(new TaskInterfaceImp());
}
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("刚才满了,有一些没添加成功,等一下执行完毕,就可以再次添加了");
for (int i = 0; i < 10; i++) {
stc.addTask(new TaskInterfaceImp());
}
}
总结
线程我觉着要知道并理解有几点:
1、线程的创建、启动。继承Thread 实现Runable或Callable带返回值。
2、volatile保证变量的可见性。
3、线程池FixedThreadPool的使用时,不断提交任务会有内存溢出的风险, ThreadPoolExecutor如何使用。
4、理解线程池原理,通过自己创建少量的线程,执行外部提交任务的方式,来保证线程不会频繁创建、销毁、上下文切换的。还有一些例如:shutdown、isShutdown、awaitTermination等等线程池的方法,有个印象,用的时候查一下API即可。
5、还有一些锁这个还没整理,以后有机会继续分享
好了这篇分享完了,希望对大家会有帮助,文章中有哪些错误,或者理解的不对,欢迎大家多多和我交流、批评和指正。















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









