









java实践7索引之Hash索引、位图索引、倒排索引原理
接上文B树、B+树持久化详解,下面来说说其他的索引
Hash索引
hash索引:简单地说哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似b树那样从根到叶子逐级查找,只需一次哈希算法即可立刻定位到相应的位置。与B树来对比的话,它操作起来则简单多了,也更容易理解。这里的简单是指他的思路简单哈,hash算法还是比较复杂的。
参考:java实践hashMap 中hash的例子。
例如: 我们要插入下面三条数据id和value三条数据
| id | value |
|---|---|
| o | 张三 |
| q | 李四 |
| s | 王二 |
那么针对上面的数据,如果每次都需要通过id取value,那么我们如何运用hash索引来优化它呢?
可以设计一个简单的hash算法,取id字母对应的asc码,然后和10取余。变成下面这样。
| id | value | asc码 | %10取余 |
|---|---|---|---|
| o | 张三 | 111 | 1 |
| q | 李四 | 113 | 3 |
| s | 王二 | 115 | 5 |
当数据插入时,我们可以新建一个数组(如果落盘的话可以创建一个文件)因为和10取余,所以数组的长度为10.
当数据插入时,我们先根据id%10取余后的得到下标,然后直接放到数组中。
| 下标 | 数据 |
|---|---|
| 0 | null |
| 1 | 张三 |
| 2 | null |
| 3 | 李四 |
| 4 | null |
| 5 | 王二 |
| … | … |
数据入库时,计算下标,使用的方法(先取asc码再和10取余),这个就叫hash算法。(当然还有其他的hash算法,为方便这里简化了)
通过例子我们就理解了hash算法的特点。
优缺点:
1)我们可以看到hash索引,在查找方面是非常快的, B树需要用二分查找来定位,他可以通过hash算法可以直接定位到结果。在等值查找方面hash索引几乎是没有对手的.
2)但是他的缺点也是显而易见的。上面有3条数据,但是数组定义的长度确是10,有7个冗余长度。相对于树,hash算法是非常耗费空间的。
3)数据冲突问题。假设我们再插入id ‘y’他的asc码是121和10取余也是1,和id’o’冲突了。
4)只能等值查询,其他如范围查询则无法使用,上面的例子可知hash算法必须通过确定的id来确定下标获取数据的,如果我们进行范围查询,没有确定的id,则无法利用hash索引查询。
通过上面我们明白了,hash算法的好坏,决定了我们查询的速度,和耗费的内存空间,每种hash算法,都有各自的优缺点。都避免不了数据冲突和耗费空间,只能减少。虽然他很快但是也有他的缺点。
位图索引:
考虑这样的场景。假设 数据有性别属性,业务侧经常使用性别,来查询数据,男500w条女500w条。那么我们如果利用索引来优化呢?由于是性别属性,选择性不高,使用B树,每次也要取一半的数据,完全没有必要。我们可以使用位图索引。
位图索引是一种使用位图的特殊数据索引。主要针对大量相同值的列而创建(例如:类别,性别,部门ID等)。
比如例子中,我们如何运用 位图索引来有花他呢?
首先:性别,我们可以使用bit 1和0来代表男女。
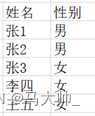
对性别创建,位图索引。左侧为创建的索引,右侧为数据。地址存放指向真实数据的偏移位置。如下图
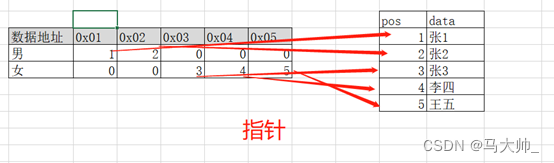
那么例子中1000w的数据,偏移量pos使用int的话,那么很少的空间即可存下,查询时先查询索引,由于索引比较小,极大的提高了查询速度。
优缺点:
通过上面的理解,我们可以知道,在选择性比较少的情况下,可以使用位图索引,或借鉴他的思路。 在选择性比较高的情况下,就不适用了,他不能像树一样使用二分查找来查找数据,他只能把索引分块load到内存,然后遍历它,查找符合条件的数据。
注意:位图索引,查询时,分块load到内存,他是要顺序遍历的,选择性小,那么用B树,不是也要遍历吗,这不是都一样吗?不是的,位图索引他遍历要比B树快。 B树需要存储索引数据、真实数据地址等,并且对数据进行排序,所以占用的空间比较大。而位图索引则不需要,只需要存储真实数据地址即可,其他都不需要存。位图索引比B树,占用空间很小,所以遍历起来会更快。
倒排索引:
考虑下面场景,假设下面文章数据:要对文章的内容进行搜索,搜索祖国 要查出内容包含”祖国”的文章。针对与这种场景,我们可以考虑使用倒排索引的来优化他。
 倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
首先我们先建立词库 {[祖国]、[繁荣]、[昌盛]、[java]、[编程]},当数据入库时我们要把内容字段的数据 根据词库来进行拆分。
 那么数据入库时我们可以对词和文章建立倒排索引,来提高查询速度。如下图
那么数据入库时我们可以对词和文章建立倒排索引,来提高查询速度。如下图
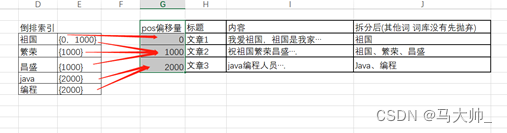 查询时我们只要查询倒排索引,就能直接定位,内容包含此分词的数据记录。这个就是倒排索引的实现思路。
查询时我们只要查询倒排索引,就能直接定位,内容包含此分词的数据记录。这个就是倒排索引的实现思路。
通过上面的图可以理解倒排索引的思路,但是还有问题,倒排索引如果能直接找到分词,的确可以直接定位到记录位置,但是词库很大怎么办?那么瓶颈就会出现在索引查找上。可以使用B树。
B树+倒排索引
倒排索引+词库 ,虽然解决了通过分词的索引位置 直接定位数据的查询问题,但是没有解决词库很大,搜索词库的效率问题。
如何解决呢?我们可以在倒赔索引的基础上再增加一层B树来解决此问题。
查询时先从B树中查找,然后利用B树定位倒排索引,再用倒排索引定位数据。这样针对词库数据过多,那么也能提高词库的搜索速度了。
图中树的排序方式是以 拼音形式根据asc码来排序的
 当然我们也可以进一步优化,比如在倒排索引中增加记录出现次数和出现位置。进行查询时就可实现高亮显示和按出现次数的权重进行排序显示。
当然我们也可以进一步优化,比如在倒排索引中增加记录出现次数和出现位置。进行查询时就可实现高亮显示和按出现次数的权重进行排序显示。

大家学废了吗?好了这篇分享完了,希望对大家会有帮助,文章中有哪些错误,或者理解的不对,欢迎大家多多和我交流、批评和指正。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









