







本文在创作过程中借助 AI 工具辅助资料整理与内容优化。图片来源网络。

文章目录
引言
大家好,我是沛哥儿。
“工欲善其事,必先利其器”,在如今这个互联网飞速发展的时代,分布式系统越来越多地应用于各个领域。Celery 作为一款强大的异步任务队列工具,在分布式系统的任务调度和执行中发挥着举足轻重的作用。但分布式系统难免会受到网络、硬件等因素影响而出现故障,所以构建高可用的 Celery 集群并制定有效的故障恢复策略就显得尤为重要啦。今天咱就来深入探讨一下 Celery 高可用集群构建与故障恢复那些事儿。
一、Celery 初探
1.1 Celery 是个啥
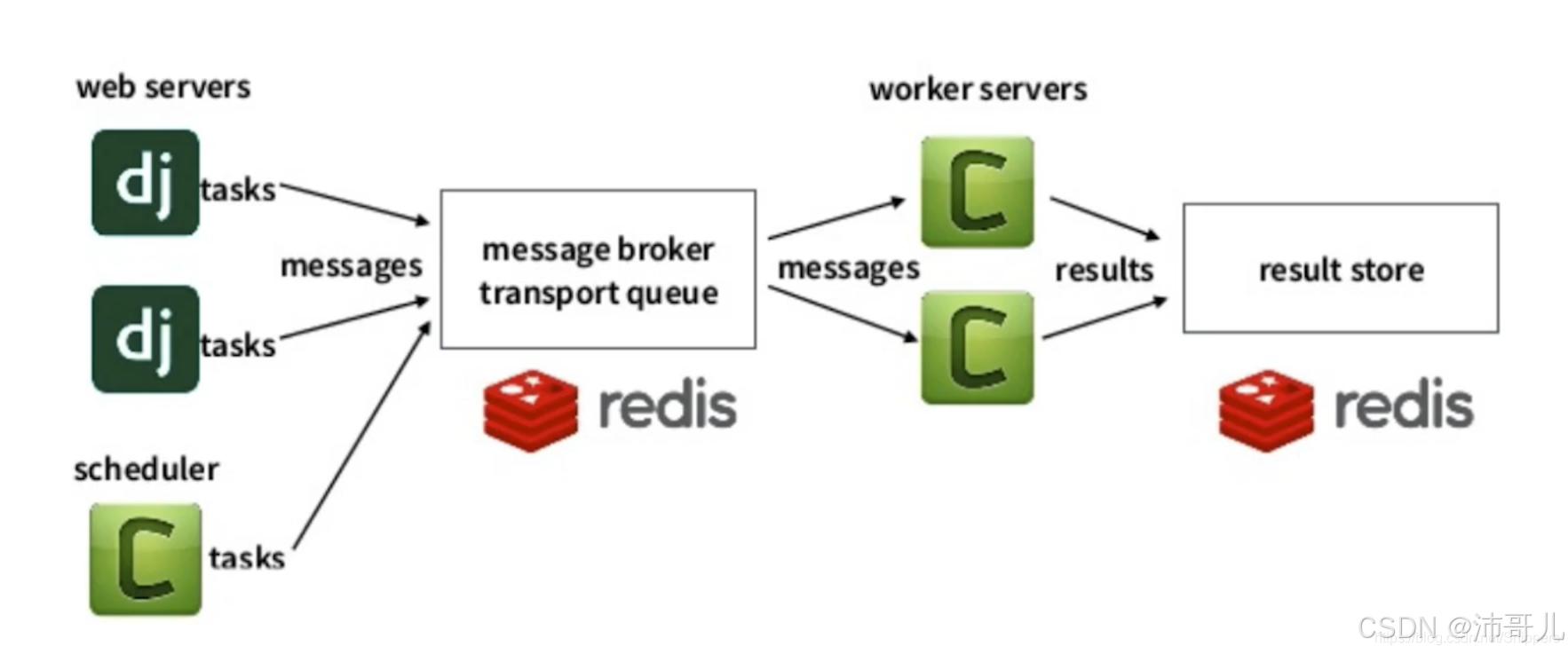
Celery 是一款基于分布式消息传递的开源异步任务队列工具,就好比一个勤劳的小秘书,能帮开发者把耗时的任务异步执行,让系统的响应速度和吞吐量都蹭蹭往上涨。它支持多种消息中间件,像 RabbitMQ、Redis 等,这些消息中间件就像是一个个“快递驿站”,负责消息的传递和存储。
1.2 Celery 的特点
Celery 这小家伙优点可多啦。
- 高性能:基于消息传递机制,能实现任务的异步执行,就像给系统装了个涡轮增压,让系统的吞吐量大大提高。
- 可扩展性:支持分布式部署,这就好比搭积木,你可以根据需求随意扩展集群规模。
- 可靠性:支持任务的重试和失败处理,就算任务在执行过程中遇到点小挫折,也能重新再来,确保任务的可靠性。
- 易用性:提供了丰富的 API 和工具,方便开发者进行任务调度和监控,就像给开发者配了个智能小助手。

1.3 Celery 的应用场景
Celery 在分布式系统中的应用那是相当广泛,下面我给大家举几个例子。
-
异步处理耗时的任务:比如在电商平台中,用户下单后需要进行库存更新、订单处理等操作,这些操作耗时较长,使用 Celery 异步处理这些任务,就可以让用户更快地得到响应,提高用户体验。
-
定时任务调度:在互联网公司中,需要定时清理日志、更新数据等操作,使用 Celery 的定时任务调度功能,就可以实现这些操作的自动化,省心又省力。
-
分布式任务调度:在数据挖掘项目中,需要对大量数据进行处理,使用 Celery 的分布式任务调度功能,就可以实现数据的分布式处理,大大提高处理效率。
二、Celery 高可用集群构建
2.1 集群架构设计
要构建高可用的 Celery 集群,我们需要好好设计一下它的架构。Celery 集群通常由消息中间件、任务队列、任务消费者和任务执行器几个部分组成。
为了确保集群的高可用性,我们需要从以下几个方面进行设计。
- 消息中间件高可用:选择支持高可用的消息中间件,比如 RabbitMQ 的集群模式,就像给“快递驿站”搞了个连锁,一个“驿站”出问题了,还有其他“驿站”可以顶上。
- 任务队列高可用:使用分布式存储系统,如 Redis 集群,确保任务队列的可靠性,就像给任务找了个安全的“仓库”。
- 任务消费者高可用:采用多实例部署,实现负载均衡和故障转移,就像给任务安排了多个“搬运工”,一个“搬运工”累了或出问题了,还有其他“搬运工”接着干。
- 任务执行器高可用:同样采用多实例部署,实现负载均衡和故障转移,确保任务能够及时执行。
2.2 集群部署
下面我以 RabbitMQ 和 Redis 为例,给大家讲讲集群部署的具体方法。
- RabbitMQ 集群部署:采用 RabbitMQ 的镜像队列模式,实现消息的高可用。下面是一个简单的 Python 代码示例,用于连接 RabbitMQ 集群。
import pika
# 配置 RabbitMQ 集群节点信息
credentials = pika.PlainCredentials('guest', 'guest')
parameters = [
pika.ConnectionParameters(host='node1.example.com', port=5672, credentials=credentials),
pika.ConnectionParameters(host='node2.example.com', port=5672, credentials=credentials),
pika.ConnectionParameters(host='node3.example.com', port=5672, credentials=credentials)
]
# 尝试连接 RabbitMQ 集群
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
# 声明一个队列
channel.queue_declare(queue='hello')
# 发送消息
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print(" [x] Sent 'Hello World!'")
# 关闭连接
connection.close()
这段代码通过配置多个 RabbitMQ 节点信息,实现了对 RabbitMQ 集群的连接和消息发送。
- Redis 集群部署:采用 Redis 集群模式,实现任务队列的高可用。以下是一个简单的 Python 代码示例,用于连接 Redis 集群。
from rediscluster import RedisCluster
# 配置 Redis 集群节点信息
startup_nodes = [
{"host": "127.0.0.1", "port": "7000"},
{"host": "127.0.0.1", "port": "7001"},
{"host": "127.0.0.1", "port": "7002"}
]
# 连接 Redis 集群
redis_cluster = RedisCluster(startup_nodes=startup_nodes, decode_responses=True)
# 设置键值对
redis_cluster.set('key', 'value')
# 获取键值对
value = redis_cluster.get('key')
print(f"Value: {value}")
这段代码通过配置多个 Redis 节点信息,实现了对 Redis 集群的连接和数据操作。
- 任务消费者和执行器部署:采用多实例部署,实现负载均衡和故障转移。可以使用 Docker 等容器技术来进行部署,方便快捷。

三、故障恢复策略
3.1 故障检测
在分布式系统中,及时发现故障是非常重要的。我们可以采用以下几种方式进行故障检测。
- 心跳检测:定期发送心跳信号,检测集群中各个节点的状态。就像给每个节点都装了个“脉搏监测仪”,一旦发现“脉搏”不正常,就说明节点可能出问题了。
- 任务监控:监控任务的执行状态,及时发现失败任务。可以通过日志记录和监控系统来实现。
- 系统监控:监控系统的资源使用情况,如 CPU、内存、磁盘等。当资源使用超过一定阈值时,就可能意味着系统出现了问题。
3.2 故障处理
当检测到系统故障时,我们需要采取相应的措施进行处理。
- 消息中间件故障处理:根据故障类型,采取重启、切换主节点等措施。比如,如果 RabbitMQ 节点出现故障,可以尝试重启该节点,如果还是不行,就切换到其他节点。
- 任务队列故障处理:根据故障类型,采取数据恢复、切换主节点等措施。
3.3 任务消费者和执行器故障处理
当任务消费者或者执行器出现故障时,可以采用自动重启机制,就像给这些“老伙计”按了个“复活按钮”。同时,利用负载均衡器将任务重新分配给其他正常的实例。
以下是一个简单的 Python 代码示例,模拟任务消费者故障时的自动重启机制:
import time
import subprocess
while True:
try:
# 模拟任务消费者运行
subprocess.run(['python', 'consumer.py'], check=True)
except subprocess.CalledProcessError as e:
print(f"任务消费者出现故障: {e}. 正在重启...")
time.sleep(5) # 等待 5 秒后重启
3.4 故障恢复演练
为了确保故障恢复策略的有效性,我们需要定期进行故障恢复演练。这就好比军队定期进行军事演习一样,做到有备无患。可以模拟各种故障场景,检验系统在故障发生时的响应和恢复能力。
四、Celery 高可用集群的监控与优化
4.1 监控指标
为了保证 Celery 高可用集群的稳定运行,我们需要监控一些关键指标,比如任务队列长度、任务执行时间、节点资源使用情况等。这些指标就像是系统的“体检报告”,能让我们及时发现系统的健康状况。
4.2 优化策略
根据监控指标的分析结果,我们可以采取相应的优化策略。比如,如果任务队列长度过长,我们可以增加任务消费者的数量;如果任务执行时间过长,我们可以优化任务代码或者增加任务执行器的资源。
以下是一个简单的 Python 代码示例,根据任务队列长度动态调整任务消费者的数量:
import redis
redis_cluster = redis.RedisCluster(startup_nodes=[
{"host": "127.0.0.1", "port": "7000"},
{"host": "127.0.0.1", "port": "7001"},
{"host": "127.0.0.1", "port": "7002"}
])
queue_length = redis_cluster.llen('task_queue')
if queue_length > 100:
# 增加任务消费者数量
subprocess.run(['docker', 'run', '-d', 'task_consumer_image'])
五、总结与展望

构建 Celery 高可用集群并制定有效的故障恢复策略是一个长期的、不断优化的过程。通过合理的架构设计、有效的故障检测与处理机制以及定期的监控和优化,我们可以确保分布式系统的稳定运行。
未来,随着技术的不断发展,Celery 也可能会有更多的功能和特性。我们需要不断学习和探索,跟上技术的步伐,为分布式系统的发展贡献自己的力量。


















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











