









第一章 统计学习方法概论
简单介绍统计学习方法基本概念。
统计学习
定义
关于计算机基于数据构建概论统计模型并运用模型对数据进行预测与分析的一门学科。统计学习也称为统计机器学习。
研究对象
数据data(数字、文字、图像、视频、音频),同类数据具有一定的统计规律性
获取数据——提取特征——抽象模型——挖掘知识——分析预测
统计学习方法
基于数据构建统计模型从而对数据进行预测与分析,由监督学习、非监督学习、半监督学习、强化学习等组成。
步骤
1、得到一个优先的训练数据集合
2、确定包含所有可能的模型的假设空间,即学习模型的集合
3、确定模型选择的准则,即学习的策略
4、实现求解最优模型的算法,即学习的算法
5、通过学习方法选择最优模型
6、利用学习的最优模型对新数据进行预测或分析
监督学习
基本概念
输入空间:输入的所有可能取值的集合
输出空间:输出的所有可能取值的集合
特征空间:所有特征向量存在的空间,每一维对应于一个特征
映射关系:输入空间X——特征空间——输出空间Y
联合概率分布:监督学习假设输入与输出的随机变量X和Y遵循联合概率分布P(X,Y),P(X,Y)表示分布函数或分布密度函数。并假设训练数据与测试数据是依联合概率分布P(X,Y)独立同分布产生的。
假设空间:有输入空间到输出空间的映射的集合
应用
分类、标注、回归问题
分类问题:输出变量为有限个离散变量的预测问题
回归问题:输入变量与输出变量均为连续变量的预测问题
标注问题:输入变量与输出变量均为变量序列的预测问题
统计学习方法三要素
方法 = 模型+策略+算法
统计学习方法包括模型的假设空间、模型选择的准则以及模型学习的算法。
模型
统计学习首先考虑的问题是学习什么样的模型。假设空间中的模型一般有无穷多个。要学习的条件概率分布P(Y|X)或决策函数Y=f(X),由决策函数表示的模型为非概率模型,由条件概率表示的模型为概率模型。
策略
接着考虑按照什么样的准则学习或选择最优的模型。
损失函数/代价函数:度量模型一次预测的好坏,预测值f(X)和真实值Y的非负实值函数L(Y,f(X))。
常用损失函数:
概率模型使用对数损失,非概率模型使用0-1损失、平方损失、绝对损失。

风险函数/期望损失/期望风险:度量平均意义下模型预测的好坏 ,模型关于联合分布的期望损失

学习的目标:选择期望风险最小的模型
经验风险/经验损失:模型f(X)关于训练数据集的平均损失

根据大数定律,当样本容量N无穷大,经验风险趋于期望风险,可用其进行估计。当N有限或很小时,使用两个策略对经验风险进行一定的矫正,经验风险最小化、结构风险最小化。
经验风险最小化ERM:经验风险最小的模型是最优模型

当N足够大,ERM能保证很好的学习效果,现实中广泛采用。如极大似然估计,当模型是条件概率分布,损失函数是对数损失函数时,ERM等价于极大似然估计。
但当N很小时,ERM学习效果未必很好,容易产生过拟合。
结构风险最小化SRM:认为结构风险最小的模型是最优模型。防止过拟合提出来的策略,等价于正则化,结构风险小的模型往往对训练数据集以及未知测试数据都有较好预测。如贝叶斯估计中的最大后验概率估计MAP,当模型是条件概率分布、损失函数是对数损失函数、模型复杂度由模型的先验概率表示时,SRM等价于MAP。

总结:
如何选择最优模型呢?预测值与真实值损失越小,模型越好。
那如何选择合适的损失/风险函数?损失函数度量一次预测结果,风险函数度量平均意义的预测结果,度量所有训练样本故选择风险函数。但风险函数无法直接计算,根据大数定律将问题转换为计算所有训练集的平均损失——经验风险/经验损失,即每次损失函数的累加和平均值。
但直接使用经验风险结果往往不理想,需要矫正,方法两种:经验风险最小化、结构风险最小化。经验风险最小化适用于样本量N足够大,效果好;结构风险最小化适用于样本量小、复杂度高、对数损失函数,效果好,防止过拟合。
这样,监督学习问题就变成了经验风险或结果风险函数的最优化问题。经验或结构风险函数是最优化的目标函数。
算法
最后考虑用什么样的计算方法求解最优模型。算法指学习模型的具体计算方法。如何求解最优化问题(目标函数最优化),有显式解析解直接算,若没有的话,要用数值计算的方法求解,如何保证找到全局最优解,并使求解过程非常高效,成为一个重要问题。可以利用已有最优化算法,或者开发独自的最优化算法。
模型评估与选择
具体采用的损失函数未必是评估时使用的损失函数,当然,两者一致比较理想。
给定两种学习方法,测试误差小的方法具有更好的预测能力
泛化能力:学习方法对未知数据的预测能力
过拟合
学习时选择的模型所包含参数过多,对已知数据预测效果好,但对未知数据预测差
模型选择
旨在避免过拟合并提高模型预测能力
常用模型选择方法:正则化、交叉验证
模型复杂度越高,训练误差减小,但测试误差先减小后增大

举例
任务:给定一个训练集T={(x,y),...},求解其多项式表达式
解决:回归问题,多项式函数
模型:先确定模型复杂度,即多项式次数
策略:给定模型复杂度,使用经验风险最小化策略计算,损失函数采用平方损失
算法:求解最优参数,即多项式系数wj,对经验风险函数对系数求偏导并令其为0,求出系数wj
正则化
结构风险最小化/正则化 = 经验风险+正则化项/罚项
正则化项一般是模型复杂度的单调递增函数,可以是模型参数向量的范数,符合奥卡姆剃刀原理(效果好且简单,即为最优)
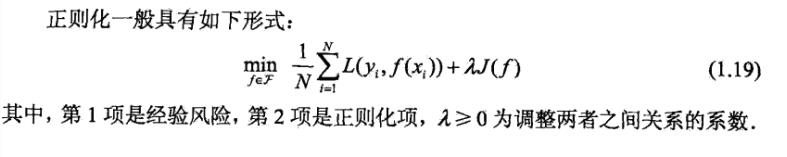

交叉验证
给定样本数据充足,随机划分训练集(训练模型)、验证集(模型选择)、测试集(最终对学习方法的评估),选择对验证集有最小预测误差的模型。
当数据不充足,采用交叉验证:重复的利用数据,切分给定数据集为不同的训练集与测试集,反复训练、测试、模型选择。
简单交叉验证:随机分两部分,70%训练集,30%测试集,训练集在不同条件下(不同参数个数、不同参数、……)训练不同模型,测试集评价个模型测试误差,选出测试误差最小的模型。
S折交叉验证:应用最多,随机切分S个互不相交的大小相同的子集,利用S-1个子集训练,剩余测试。不断重复该过程S次,选出评测中平均测试误差最小的模型。
留一交叉验证:S折交叉验证特殊情形S=N,往往在数据缺乏时使用。
泛化能力
学习到的模型对未知数据的预测能力,通过测试误差评价,当数据有限时结果不可靠。
泛化误差
用学习的模型对未知数据预测的误差,反映学习方法的泛化能力,即学习到的模型的期望风险。
泛化误差上界
研究概率上界大小评判优劣。当样本容量增加,泛化上界趋于0;假设空间容量越大,模型越难学,上界越大。
生成模型
生成方法由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型P(Y|X) = P(X,Y) / P(X)。
模型表示给定输入X产生输出Y的生成关系P(X,Y)。如朴素贝叶斯法、隐马尔科夫。
- 可以还原出联合概率分布P(X,Y),判别放法不能
- 学习收敛速度更快,当样本容量增加,模型更快地收敛于真是模型
- 存在隐变量时,可用生成方法学习,判别方法不能使用
判别模型
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。改定输入X,应该预测什么样的输出Y。如k近邻、感知机、决策树、逻辑回归、最大熵、支持向量机、提升方法、条件随机场。
- 直接学习的是条件概率P(Y|X)或决策函数f(X),直接面对预测,学习准确率更高
- 由于直接学习,可以对数据进行各种程度的抽、定义特征并使用特征,可以简化学习问题
分类问题
输出变量:有限个离散值
输出变量:可连续、可离散
评价指标
准确率accuracy:对给定测试数据集,分类器正确分类的样本数与总样本数之比,即损失函数0-1损失时测试数据集上的准确率
二分类问题常用指标:关注的类为正类,其他类为负类
TP:正类预测为正类
FN:正类预测为负类
FP:负类预测为正类
TN:负类预测为负类
精确率precision:预测为正类的结果中,正确样本所占比例,表示预测正类准不准
召回率recall:真实结果为正类的结果中,预测正确样本所占比例,表示正类被召回多少

常用方法
k近邻、感知机、朴素贝叶斯、决策树、决策列表、逻辑回归、支持向量机、提升方法、贝叶斯网络、神经网络、winnow等统计学习方法可用于分类。
应用
- 银行构建客户分类模型,按照贷款风险大小分类
- 网络安全领域,利用日志数据分类对非法入侵进行检测
- 图像处理,检测图像是否有人脸出现
- 手写识别,识别手写数字
- 互联网搜索,网页分类帮助网页的抓取、索引、排序
- 文本分类,新闻报道、翁源、电子邮件、学术论文等,分内容领域为政治、经济、体育,分情感为正面、负面,分应用为垃圾邮件、废垃圾邮件
标注问题
可认为是分类问题的推广,更复杂的结构预测问题的简单形式。
输入观测序列,输出标记序列或状态序列。学习一个模型,能对观测序列给出标记序列作为预测,标记个数是有限的,其组合成的标记序列的个数是依序列长度呈指数级增长。
标注问题分为学习和标注两个过程。
评价指标
与分类一样
常用方法
隐马尔科夫、条件随机场
应用
- 信息抽取,文章抽取基本名词短语,标记开始B、结束E、其他O,抽取名词,如LTP实体抽取
- 自然语言处理,词性标注,给定单词组成的句子,对句中每个单词标注词性,即对一个单词序列预测对应的词性标记序列
回归问题
回归问题等价于函数拟合。按输入变量的个数分为一元回归和多元回归,按输入输出关系类型分为线性回归和非线性回归。
常用损失函数是平方损失函数,此时回归问题由最小二乘法求解。
应用
- 商务领域,市场趋势预测、产品质量管理、客户满意度调查、投资风险分析工具
- 股价预测,已知某公司过去不同时间点股票价格(股票平均价格,作为因变量),以及各时间点前影响股价的信息(前一周营业额、利润,作为自变量特征),学习模型可基于当前信息预测下一个时间点的股票价格















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









