







学号:sa**199 姓名:*浩
环境:ubuntu12.04 gcc4.7.3
1进程管理
进程创建:
fork()
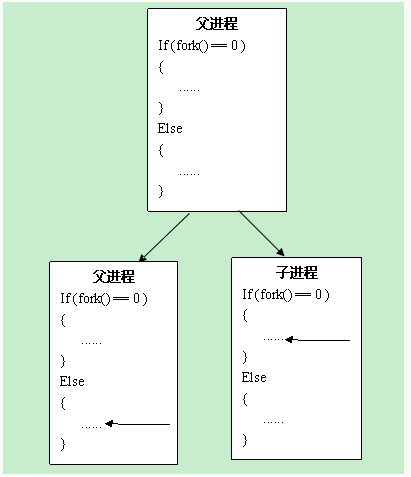
为什么fork会返回两次?
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
int glob = 1;
char buf[] = "hehehehehe\n";
int main()
{
int var;
pid_t pid;
var = 2;
fprintf(stderr, "%s", buf);
printf("before fork\n");
if(( pid = fork() ) < 0 )
{
fprintf(stderr, "fork error\n");
}
else if(pid == 0)
{
glob++;
var++;
printf("child process\n");
buf[3] = '\0';
printf( "%s\n", buf );
printf("pid = %d, father pid = %d, glob = %d, var = %d\n", getpid(), getppid(), glob, var);
exit(0);
}
else
{
sleep(2);
printf("father process\n");
printf( "%s", buf );
printf("pid = %d, father pid = %d, glob = %d, var = %d\n", getpid(), getppid(), glob, var);
}
return 0;
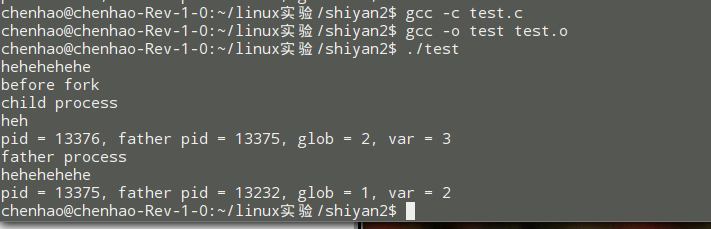
}我们在子进程中修改了一些参数的值,来打印输出下结果:
例子分析
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。fork之后,子进程和父进程都会继续执行fork调用之后的指令。子进程是父进程的副本。它将获得父进程的数据空间,堆和栈的副本,这些都是副本,父子进程并不共享这部分的内存。也就是说,子进程对父进程中的同名变量进行修改并不会影响其在父进程中的值。但是父子进程又共享一些东西,简单说来就是程序的正文段。正文段存放着由cpu执行的机器指令,通常是read-only的。
这样看来,fork是一个开销十分大的系统调用,这些开销并不是所有的情况下都是必须的,比如某进程fork出一个子进程后,其子进程仅仅是为了调用exec执行另一个可执行文件,那么在fork过程中对于虚存空间的复制将是一个多余的过程。但由于现在Linux中是采取了copy-on-write(COW写时复制)技术,为了降低开销,fork最初并不会真的产生两个不同的拷贝,因为在那个时候,大量的数据其实完全是一样的。写时复制是在推迟真正的数据拷贝。若后来确实发生了写入,那意味着parent和child的数据不一致了,于是产生复制动作,每个进程拿到属于自己的那一份,这样就可以降低系统调用的开销。
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
了解了简单的fork()函数,我们来看一下几个经典题目来加深下对fork()的认识:下面的题目均转载自他人,我会将地址放到这。
fork 进阶题目:
1) 第一个题目:地址:http://www.cnblogs.com/leoo2sk/archive/2009/12/11/talk-about-fork-in-linux.html
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t pid1;
pid_t pid2;
pid1 = fork( );
pid2 = fork( );sleep(1);
printf( " pid1 = %d, pid2 = %d\n", pid1, pid2 );
}要求如下:
已知从这个程序执行到这个程序的所有进程结束这个时间段内,没有其它新进程执行。
1、请说出执行这个程序后,将一共运行几个进程。
2、如果其中一个进程的输出结果是“pid1:1001, pid2:1002”,写出其他进程的输出结果(不考虑进程执行顺序)。
预备知识
这里先列出一些必要的预备知识,对linux下进程机制比较熟悉的朋友可以略过。
1、进程可以看做程序的一次执行过程。在linux下,每个进程有唯一的PID标识进程。PID是一个从1到32768的正整数,其中1一般是特殊进程init,其它进程从2开始依次编号。当用完32768后,从2重新开始。
2、linux中有一个叫进程表的结构用来存储当前正在运行的进程。可以使用“ps aux”命令查看所有正在运行的进程。
3、进程在linux中呈树状结构,init为根节点,其它进程均有父进程,某进程的父进程就是启动这个进程的进程,这个进程叫做父进程的子进程。
4、fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
解题的关键
有了上面的预备知识,我们再来看看解题的关键。我认为,解题的关键就是要认识到fork将程序切成两段。看下图:

上图表示一个含有fork的程序,而fork语句可以看成将程序切为A、B两个部分。然后整个程序会如下运行:
step1、设由shell直接执行程序,生成了进程P。P执行完Part. A的所有代码。
step2、当执行到pid = fork();时,P启动一个进程Q,Q是P的子进程,和P是同一个程序的进程。Q继承P的所有变量、环境变量、程序计数器的当前值。
step3、在P进程中,fork()将Q的PID返回给变量pid,并继续执行Part. B的代码。
step4、在进程Q中,将0赋给pid,并继续执行Part. B的代码。
这里有三个点非常关键:
1、P执行了所有程序,而Q只执行了Part. B,即fork()后面的程序。(这是因为Q继承了P的PC-程序计数器)
2、Q继承了fork()语句执行时当前的环境,而不是程序的初始环境。
3、P中fork()语句启动子进程Q,并将Q的PID返回,而Q中的fork()语句不启动新进程,仅将0返回。
解题
下面利用上文阐述的知识进行解题。这里我把两个问题放在一起进行分析。
1、从shell中执行此程序,启动了一个进程,我们设这个进程为P0,设其PID为XXX(解题过程不需知道其PID)。
2、当执行到pid1 = fork();时,P0启动一个子进程P1,由题目知P1的PID为1001。我们暂且不管P1。
3、P0中的fork返回1001给pid1,继续执行到pid2 = fork();,此时启动另一个新进程,设为P2,由题目知P2的PID为1002。同样暂且不管P2。
4、P0中的第二个fork返回1002给pid2,继续执行完后续程序,结束。所以,P0的结果为“pid1:1001, pid2:1002”。
5、再看P2,P2生成时,P0中pid1=1001,所以P2中pid1继承P0的1001,而作为子进程pid2=0。P2从第二个fork后开始执行,结束后输出“pid1:1001, pid2:0”。
6、接着看P1,P1中第一条fork返回0给pid1,然后接着执行后面的语句。而后面接着的语句是pid2 = fork();执行到这里,P1又产生了一个新进程,设为P3。先不管P3。
7、P1中第二条fork将P3的PID返回给pid2,由预备知识知P3的PID为1003,所以P1的pid2=1003。P1继续执行后续程序,结束,输出“pid1:0, pid2:1003”。
8、P3作为P1的子进程,继承P1中pid1=0,并且第二条fork将0返回给pid2,所以P3最后输出“pid1:0, pid2:0”。
9、至此,整个执行过程完毕。
所得答案:
1、一共执行了四个进程。(P0, P1, P2, P3)
2、另外几个进程的输出分别为:
pid1:1001, pid2:0
pid1:0, pid2:1003
pid1:0, pid2:0
进一步可以给出一个以P0为根的进程树:

验证
这个在我的电脑下跑出来的结果是:

fork 函数进阶2:代码和分析全部来自:http://coolshell.cn/articles/7965.html (大牛的博客)可以收获很多。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
int i;
for(i=0; i<2; i++){
pid = fork();
printf( " ppid = %d ,pid = %d ,i = %d \n", getppid(),getpid(),i );
}
sleep(10); //查看下进程树
return 0;
}问题是:会打印几行,总共有几个进程在运行。
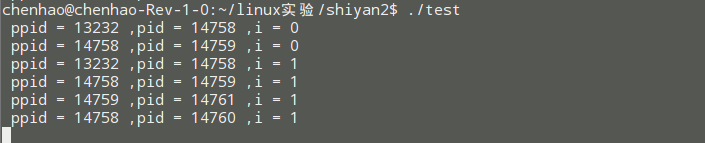
于是,上面这段程序会输出下面的结果,(注:编译出的可执行的程序名为fork)
|
1
2
3
4
5
6
7
8
9
10
|
ppid=8858, pid=8518, i=0
ppid=8858, pid=8518, i=1
ppid=8518, pid=8519, i=0
ppid=8518, pid=8519, i=1
ppid=8518, pid=8520, i=1
ppid=8519, pid=8521, i=1
$ pstree -p | grepfork
|-bash(8858)-+-fork(8518)-+-fork(8519)---fork(8521)
| | `-fork(8520)
|
面对这样的图你可能还是看不懂,没事,我好事做到底,画个图给你看看:

注意:上图中的我用了几个色彩,相同颜色的是同一个进程。于是,我们的pstree的图示就可以成为下面这个样子:(下图中的颜色与上图对应)

#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
int i;
for(i=0; i<2; i++){
fork();
printf("-");
//fflush(stdout);
}
return 0;
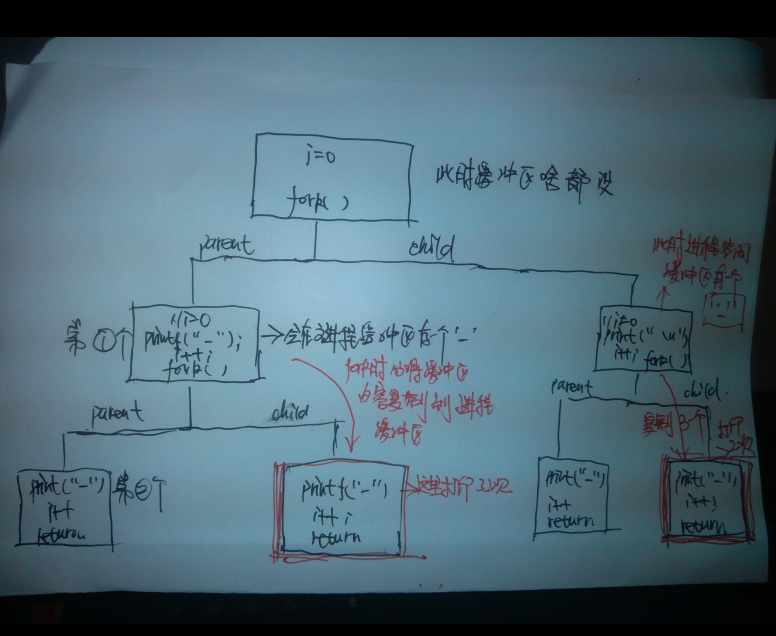
}问题是会打印几个 - ,经过刚才的分析我们知道 会打印 6次,所以应该是打印 6个 - ,答案是错误的,会打印8个。。。 问题原因在哪里,看下面的分析。
我们首先需要知道fork()系统调用的特性,
- fork()系统调用是Unix下以自身进程创建子进程的系统调用,一次调用,两次返回,如果返回是0,则是子进程,如果返回值>0,则是父进程(返回值是子进程的pid),这是众为周知的。
- 还有一个很重要的东西是,在fork()的调用处,整个父进程空间会原模原样地复制到子进程中,包括指令,变量值,程序调用栈,环境变量,缓冲区,等等。
所以,上面的那个程序为什么会输入8个“-”,这是因为printf(“-”);语句有buffer,所以,对于上述程序,printf(“-”);把“-”放到了缓存中,并没有真正的输出(参看《C语言的迷题》中的第一题),在fork的时候,缓存被复制到了子进程空间,所以,就多了两个,就成了8个,而不是6个。
另外,多说一下,我们知道,Unix下的设备有“块设备”和“字符设备”的概念,所谓块设备,就是以一块一块的数据存取的设备,字符设备是一次存取一个字符的设备。磁盘、内存都是块设备,字符设备如键盘和串口。块设备一般都有缓存,而字符设备一般都没有缓存。
对于上面的问题,我们如果修改一下上面的printf的那条语句为:
|
1
|
printf("-\n");
|
或是
|
1
2
|
printf("-");
fflush(stdout);
|
就没有问题了(就是6个“-”了),因为程序遇到“\n”,或是EOF,或是缓中区满,或是文件描述符关闭,或是主动flush,或是程序退出,就会把数据刷出缓冲区。需要注意的是,标准输出是行缓冲,所以遇到“\n”的时候会刷出缓冲区,但对于磁盘这个块设备来说,“\n”并不会引起缓冲区刷出的动作,那是全缓冲,你可以使用setvbuf来设置缓冲区大小,或是用fflush刷缓存。则 打印的过程如下如所示: (在linux底下还不会用画图工具) 先自己手画了一个 凑合着看)
Linux下进程的结构
Linux下一个进程在内存里有三部分的数据,就是"代码段"、"堆栈段"和"数据段"。其实学过汇编语言的人一定知道,一般的CPU都有上述三种段寄存器,以方便操作系统的运行。这三个部分也是构成一个完整的执行序列的必要的部分。
"代码段",顾名思义,就是存放了程序代码的数据,假如机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。"堆栈段"存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据段。(代码段是可以共享的)
Linux进程描述符
在Linux中每一个进程都由task_struct 数据结构来定义.task_struct就是我们通常所说的PCB.它是对进程控制的唯一手段也是最有效的手段. 当我们调用fork() 时,系统会为我们产生一个task_struct结构。然后从父进程,那里继承一些数据, 并把新的进程插入到进程树中,以待进行进程管理。
以下是进程描述符的源码:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#endif
int on_rq;
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
/*
* fpu_counter contains the number of consecutive context switches
* that the FPU is used. If this is over a threshold, the lazy fpu
* saving becomes unlazy to save the trap. This is an unsigned char
* so that after 256 times the counter wraps and the behavior turns
* lazy again; this to deal with bursty apps that only use FPU for
* a short time
*/
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
cpumask_t cpus_allowed;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
struct mm_struct *mm, *active_mm;
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned int jobctl; /* JOBCTL_*, siglock protected */
/* ??? */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/*
* ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
cputime_t prev_utime, prev_stime;
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time; /* monotonic time */
struct timespec real_start_time; /* boot based time */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
/* process credentials */
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
/* file system info */
int link_count, total_link_count;
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count;
#endif
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespaces */
struct nsproxy *nsproxy;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
seccomp_t seccomp;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
* mempolicy */
spinlock_t alloc_lock;
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
主要结构分析:
volatile long state; 说明了该进程是否可以执行,还是可中断等信息
unsigned long flags; Flage 是进程号,在调用fork()时给出
int sigpending; 进程上是否有待处理的信号
mm_segment_taddr_limit; 进程地址空间,区分内核进程与普通进程在内存存放的位置不同(0-0xBFFFFFFF foruser-thead 0-0xFFFFFFFF forkernel-thread)
volatile long need_resched;调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度
struct mm_struct *mm; 进程内存管理信息
pid_tpid; 进程标识符,用来代表一个进程
pid_tpgrp; 进程组标识,表示进程所属的进程组
task_struct的数据成员mm指向关于存储管理的struct mm_struct结构。它包含着进程内存管理的很多重要数据,如进程代码段、数据段、未未初始化数据段、调用参数区和进程。
Wait和waipid函数
1当一个进程正常或异常终止的时候,内核就像其父进程发送SIGCHLD信号,因为子进程是个异步事件,所以这种信号也是内核系那个父进程发的异步通知。父进程可以选择忽略该信号,或者提供一个该信号发生时即被调用执行的函数。对于这种信号的系统默认动作是忽略它。
现在要知道调用wait或waitpid的进程可能会发生什么情况:
- 如果其所有子进程都在运行,则阻塞。
- 如果一个子进程已经终止,正在得带的父进程获取到终止状态,则取得该子进程的终止状态立即返回。
- 如果他没有任何子进程,则立即出错返回。
如果进程由于接收到SIGCHLD信号而调用wait,则可期望wait会立即返回。但是如果在任意时刻调用wait则进程可能会阻塞。
2.wait()和waitpid()的功能:
1>wait()函数使父进程暫停执行,直到它的一个子进程结束为止,该函数的返回值是终止运行的子进程的PID. 参数status所指向的变量存放子进程的退出码,即从子进程的main函数返回的值或子进程中exit()函数的参数。如果status不是一个空指针,状态信息将被写入它指向的变
量。
2> 头文件sys/wait.h中定义了进程退出状态的宏。
WIFEXITED(status) 若子进程是正常结束时则返回一个非零值。即调用exit(3),_exit(3) 或从main()函数返回的值。
WEXITSTATUS(status) 如果宏WIFEXIED返回值为非零值时,它返回子进程中exit或_exit参数中的低8位。
WIFSIGNALED(status) 若子进程异常终止则返回一个非零值。
WTERMSIG(status) 如果宏WIFSIGNALED的返回值非零,则返回使子进程异常终止的信号编号。
WIFSTOPPED(status) 若子进程由于异常暫停,则返回一个非零值。当调用WUN‐TRACED或子进程被跟踪时这才时可能的。
WSTOPSIG(status) 如果宏WIFSTOPPED返回值非零,则返回使子进程暫停的信号编号。
WIFCONTINUED(status) (从2.6版本后)如果孩子进程通过SIGCONT恢复则返回一个非零
值。
3>waitpid() 函数
(1)我们先来看一个waitpid()的经典例子:当我们下载了A软件的安装程序后,在安装快结束时它又启动了另外一个流氓软件安装程序B,当B也安装结束后,才告诉你所有安装都完成了。A和B分别在不同的进程中,A如何启动B并知道B安装完成了呢?可以很简单地在A中用fork启动B,然后用waitpid()来等待B的结束。
(2)waitpid()也用来等待子进程的结束,但它用于等待某个特定进程结束。参数pid指明要等待的子进程的PID,参数status的含义与wait()函数中的status相同。options参数可以用来改变waitpid的行为,若将该参数赋值为WNOHANG,则使父进程不被挂起而立即返回执行其后的代
(3)waitpid()函数中参数pid的取值码。
pid的值可以为下己中情况:
< -1 等待其组ID等于pid绝对值的任一子进程。
=-1 等待任一子进程
=0 等待其组ID等于调用进程的组ID的任一进程
> 0 等待其进程ID等于pid的子进程退出
(4)waitpid()函数的一个应用:
如果想让父进程周期性地检查某个特定的子进程是否已经退出,可以用下面的方法:
waitpid(child_pid,(int *) 0,WNOHANG);
如果子进程尚未退出,它将返回0;如果子进程已经结束,则返回child_pid。调用失败时返回-1。失败的原因包括没有该子进程,参数不合法等。
3.wait()和waitpid() 函数的区别
(1). 在一个子进程终止前,wait()使其调用者阻塞,而waitpid()有一个选项,可使调用者不阻塞。
(2). waitpid()并不等待在其调用之后的第一个终止子进程,它有若干个选项,可以控制它所等待的进程。
(3). 对于wait(),其唯一的出错是调用进程没有子进程;对于waitpid(),若指定的进程或进程组不存在,或者参数pid指定的进程不是调用进程的子进程都可能出错。
(4). waitpid()提供了wait()没有的三个功能:一是waitpid()可等待一个特定的进程;二是waitpid()提供了一个wait()的非阻塞版本(有时希望取的一个子进程的状态,但不想使父进程阻塞,waitpid() 提供了一个这样的选择:WNOHANG,它可以使调用者不阻塞);三是waitpid()支持作业控制。
(5) wait(&status) 的功能就等于waitpid(-1, &status, 0);
两个函数原型
#include <sys/wait.h>
pid_t wait(int *status);
pit_t wait(pid_t pid,int *status,int options);
函数若成功,返回进程ID,若出错则返回-1;
若子进程先于父进程结束时,父进程调用wait()函数和不调用wait()函数会产生两种不同的结果:
--如果父进程没有调用wait()和waitpid()函数,子进程就会进入僵死状态。变成僵尸京城。
--如果父进程调用了wait()和waitpid()函数,就不会使子进程变为僵尸进程。
代码:
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main( )
{
pid_t pid;
int status, k, i;
if( ( pid = fork() ) == 0 )
{
printf( "This is the child process. pid = %d \n", getpid() );
for( k = 0; k < 5 ; k ++ )
{
printf("this child process %d print \n ", k );
sleep( 1 );
}
}
else
{
printf( "This is the parent process ,wait for child ..\n" );
//pid = wait( &status );
i = WEXITSTATUS(status);
printf( "child's pid = %d. exit status = %d \n ", pid, i );
}
return 0;
}
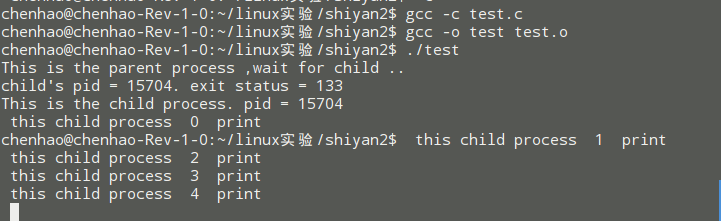
可以观察到,主进程直接执行结束了,没有等待子进程的打印结束,我们这个时候将 主进程中 使用wait 函数,看下结果:
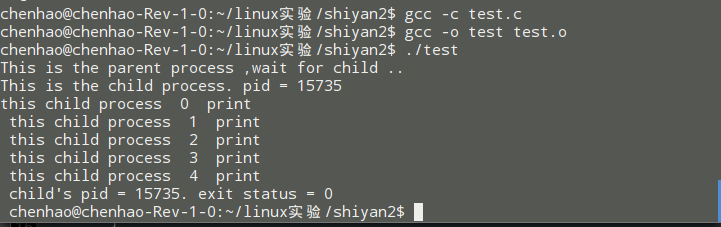
这个时候就可以看到,主进程一直在等待子进程的打印输出,一直等待子进程结束,自己才会结束。等待的过程堵塞。
waitpid
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pc, pr;
pc=fork();
if(pc<0)
{
/*如果fork出错 */
printf("Erroroccured on forking.\n");
}
else if(pc==0)
{
/*如果是子进程 */
sleep(10);
/*睡眠10秒 */
exit(0);
}
/*如果是父进程 */
do{
pr=waitpid(pc,NULL, WNOHANG);
/*使用了WNOHANG参数,waitpid不会在这里等待 */
if(pr==0){
/*如果没有收集到子进程 */
printf("Nochild exited\n");
sleep(1);
}
} while(pr==0);
/*没有收集到子进程,就回去继续尝试 */
if(pr==pc)
printf("successfullyget child %d\n", pr);
else
printf("someerror occured\n");
}打印结果:
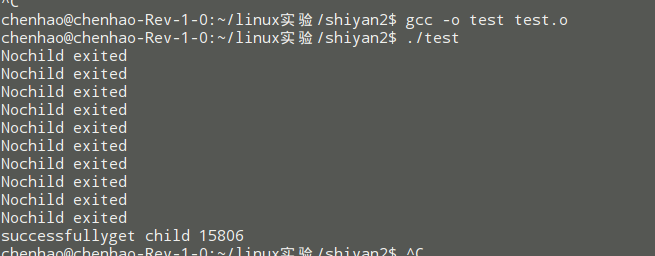

会一直等待。
OK,我们接着看下面的函数。
execve:
参数2:命令的集合
参数3:传递给执行文件的环境变量集
在Linux中要使用exec函数族来在 一个进程中启动另一个程序。系统调用execve()对当前进程进行替换,替换者为一个指定的程序.一个进程一旦调用exec类函数,它本身就"死亡"了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。(不过exec类函数中有的还允许继承环境变量之类的信息。)
#include <stdio.h>
#include <unistd.h>
int main(int arg,char **args)
{
//char *name="/usr/bin/ls";
char * argv[ ]={"ls","-al","/etc/passwd",(char *)0};//传递给执行文件的参数数组,这里包含执行文件的参数
char *envp[]={0,NULL};//传递给执行文件新的环境变量数组
execve("/bin/ls",argv,envp);
} 执行结果:

argv[]是argc个参数,其中第0个参数是程序的全名,以后的参数命令行后面跟的用户输入的参数,比如: 还是看下代码把:
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
int i;
for (i = 0; i<argc; i++)
cout<<argv[i]<<endl;
// cin>>i;
cout << argc << endl;
return 0;
}
可以大概看出,char *argv[]是一个字符数组,其大小是int argc,主要用于命令行参数 argv[] 参数,数组里每个元素代表一个参数;
比如你输入
./ test aaa bbb ccc ddd
则
argc = 5
argv[0] = " ./ test "
argv[1] = "aaa"
argv[2] = "bbb"
argv[3] = "ccc"
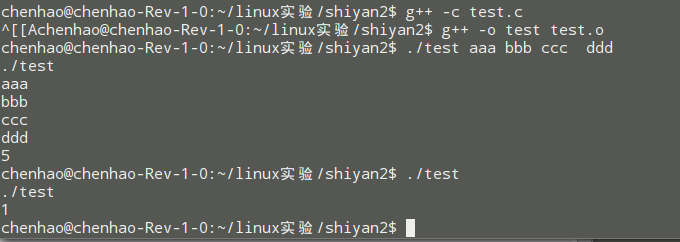
argv[3] = "ddd"
argc记录了用户在运行程序的命令行中输入的参数的个数。
arg[]指向的数组中至少有一个字符指针,即arg[0].他通常指向程序中的可执行文件的文件名。在有些版本的编译器中还包括程序文件所在的路径。
那么程序中如何能得到这些输入参数呢?这个工作是编译器帮我们完成的,编译器将输入参数的信息放入main函数的参数列表中。
main函数的参数列表保存了输入参数的信息,第一个参数argc记录了输入参数的个数,第二个参数是字符串数组的,字符串数组的每个单元是char*类型的,指向一个c风格字符串。argv数组中的第一个单元指向的字符串总是可执行程序的名字,以后的单元指向的字符串依次是程序调用时的参数。 这个赋值过程是编译器完成的,我们只需要读出数据就可以了。
看下 char *envp[] ,了解了 argv[]的作用 那么 这个数组是干什么用的呢。它是用来取得系统的环境变量的。
在DOS下,有一个PATH变量。当你在DOS提示符下输入一个命令(当然,这个命令不是dir一类的内部命令)的时候,DOS会首先在当前目录下找这个命令的执行文件。如果找不到,则到PATH定义的路径下去找,找到则执行,找不到返回Bad command or file name
在DOS命令提示符下键入set可查看系统的环境变量
同样,在UNIX或者LINUX下,也有系统环境变量,而且用得比DOS要多。如常用的$PATH,$USER,$HOME等等。
envp保存所有的环境变量。其格式为(UNIX下)
PATH=/usr/bin;/local/bin;
HOME=/home/shuui
即:
环境变量名=值
看下测试代码:
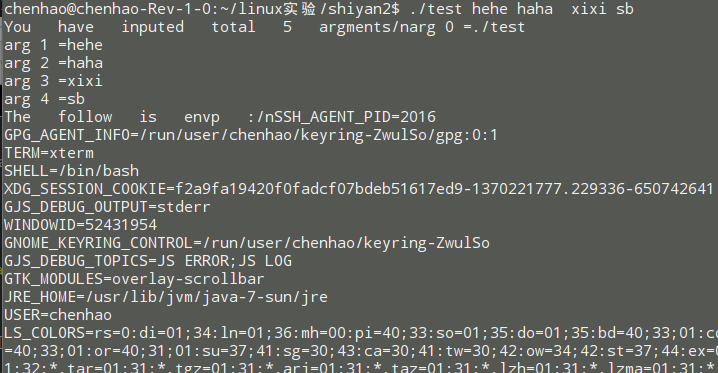
#include<stdio.h>
int main( int argc , char *argv[] , char *envp[] )
{
int k, i;
printf( "You have inputed total %d argments/n" , argc );
for( i=0 ; i<argc ; i++)
{
printf( "arg %d =%s\n" , i , argv[i] );
}
printf( "The follow is envp :/n" );
for(k =0;*envp[k]!='\0' ; k++ )
{
printf( "%s\n" , envp[k] );
}
return 0;
}
打印输出结果:
OK,大致 了解了这两个数组。回头我们在看 execve函数的两个参数,就感觉好理解一些了。
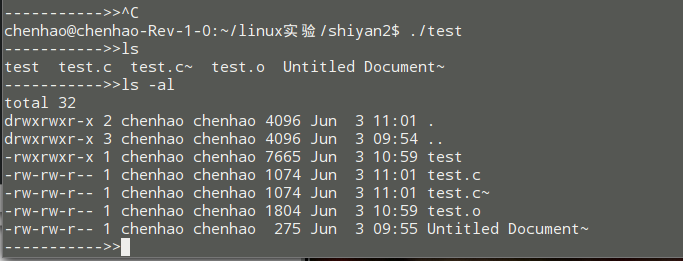
简单的shell
#include<stdio.h>
#include<unistd.h>
#define MAXSIZE 1024
char command[MAXSIZE];
char *argv[MAXSIZE];
int argc;
int analyse();
void runcommand();
int main()
{
printf("----------->>");
while( gets(command) )
{
argc = analyse();
argv[argc] = NULL;
runcommand();
printf("----------->>");
}
return 0;
}
int analyse()
{
int i = 0;
char *ptr = command;
//将参数一个一个分开,保存在argv数组中
while( *ptr != '\0' )
{
if( *ptr != ' ' && *ptr != '\t' )
{
argv[i++] = ptr++;
while( *ptr != ' ' && *ptr != '\t' )
{
if( *ptr =='\0' )
return i;
else ptr++;
}
*ptr = '\0';
}
ptr++;
}
return i;
}
void runcommand()
{
pid_t pid;
pid = fork();
if( pid == 0 )
{
execvp(argv[0], argv);
printf("command not found\n");
}
else if( pid > 0 )
{
wait(NULL);
}
else
{
printf("fork error\n");
}
}
执行过程:















 2054
2054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









