







1、数据清洗
重复值、缺失值、格式调整
异常值处理(比如存在销售额为0)
data = pd.read_csv('data_wuliu.csv',encoding='gbk')#导入数据
print(data.info())输出结果:
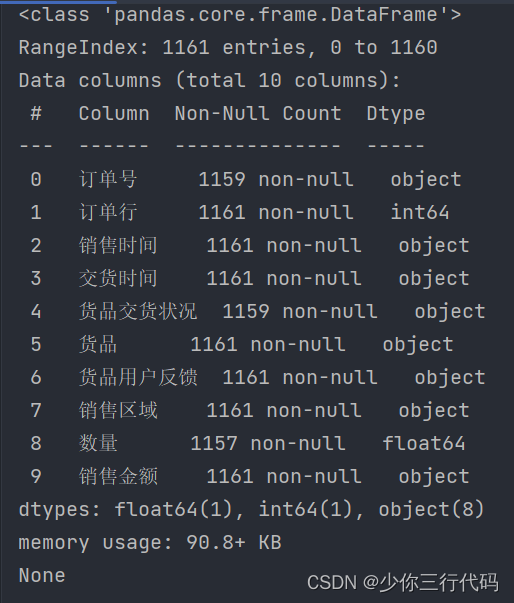
由运行结果可以看出,存在缺失值,订单号和货品交货状况以及数量都小于1161,所以应该进行数据清理,在此将缺失值删除。
通过info()可以看出,包括10列数据,名字,数据量,格式等,可以得出: 1、订单号,货品交货情况,数量:存在缺失值,但是缺失量不大,可以删除 2、订单行,对分析无关要求,可以考虑删除 3、销售金额格式不对(万元|元,逗号问题),数据类型需要转换成int|float
data.drop_duplicates(keep='first',inplace=True) #保留第一次出现的重复值
data.dropna(axis=0,how='any',inplace=True) #any:默认值,如果存在NaN值,就删除该行或该列。//有一个就删除行或列
data.drop(columns='订单行',axis=1,inplace=True)
# 更新索引(drop=true:把原来的索引index列删除,重置index)
data.reset_index(drop=True,inplace=True)#注意此处不能够用=来赋值,返回的就是空值。
print(data.info())
输出结果:
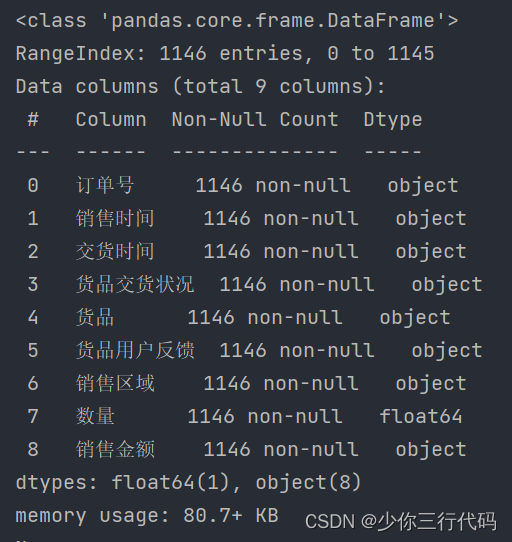
运行结果表明确实把缺失值的行都给删除了。
取出销售金额,对每个数据进行清理
编写自定义过滤函数,删除逗号,转成float类型,如果是万元,乘以10000,删除万元或者元
def data_deal(x):
if x.find('万元')!=-1:#找到带有万元的,取出数字,去掉逗号,转成float,乘以10000
x_new = float(x[:x.find('万元')].replace(',',''))*10000
else:#找到带有元的,删除元,删除逗号,转成float
x_new = float(x.replace('元','').replace(',',''))
return x_new
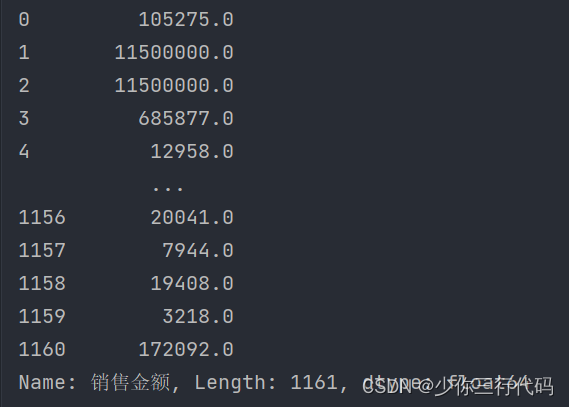
print(data['销售金额'].map(data_deal))输出结果可以表明,效果很好 。
数据规整(建立一个新的列 月份 month)
data['销售时间'] = pd.to_datetime(data['销售时间'])
data['month'] = data['销售时间'].map(lambda x:x.month)
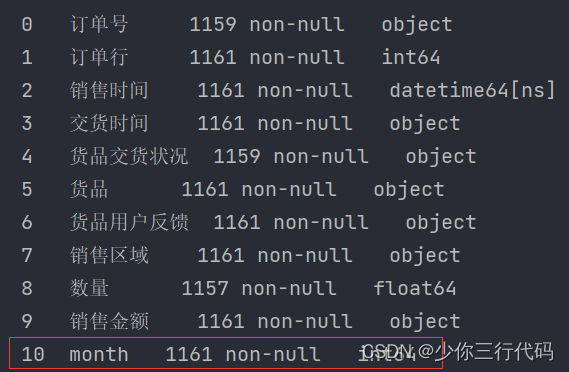
print(data.info())如图,month新列已经建立完成。
















 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











