






https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
前言:同上一篇
Grok is a great way to parse unstructured log data into something structured and queryable.
This tool is perfect for syslog logs, apache and other webserver logs, mysql logs, and in general, any log format that is generally written for humans and not computer consumption.
Logstash ships with about 120 patterns by default. You can find them here: https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns. You can add your own trivially. (See the patterns_dir setting)
If you need help building patterns to match your logs, you will find the http://grokdebug.herokuapp.com and http://grokconstructor.appspot.com/ applications quite useful!
Grok Basics
Grok works by combining text patterns into something that matches your logs.
Grok的工作原理是将文本模式组合成与日志匹配的内容。
The syntax for a grok pattern is %{SYNTAX:SEMANTIC}
grok模式的语法是BSYNTAX:SEMANTIC}
The SYNTAX is the name of the pattern that will match your text. For example, 3.44 will be matched by the NUMBER pattern and 55.3.244.1 will be matched by the IP pattern. The syntax is how you match.
SYNTAX :我的理解是类似于logstash定义的数据类型,比如ip、number,logstash还支持TIMESTAMP_ISO8601、NUMBER、JAVAFILE、NUMBER、LOGLEVEL(网上查的)
The SEMANTIC is the identifier you give to the piece of text being matched. For example, 3.44 could be the duration of an event, so you could call it simply duration. Further, a string 55.3.244.1 might identify the client making a request.
SEMANTIC :字段名称,自定义,kibana搜索的时候用的是这个字段
For the above example, your grok filter would look something like this:
%{NUMBER:duration} %{IP:client}Optionally you can add a data type conversion to your grok pattern. By default all semantics are saved as strings. If you wish to convert a semantic’s data type, for example change a string to an integer then suffix it with the target data type. For example %{NUMBER:num:int} which converts the num semantic from a string to an integer. Currently the only supported conversions are int and float.
您还可以添加一个数据类型转换到您的grok模式。默认情况下,所有的语义都被保存为字符串。如果您希望转换一个语义的数据类型,例如将一个字符串更改为一个整数,然后用目标数据类型替换它。例如,BNUMBER:num:int,它将num语义从字符串转换为整数。目前唯一支持的转换是int和float。
Examples: With that idea of a syntax and semantic, we can pull out useful fields from a sample log like this fictional http request log:
通过语法和语义的概念,我们可以从一个示例日志中提取有用的字段,比如这个虚构的http请求日志:
55.3.244.1 GET /index.html 15824 0.043The pattern for this could be:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}A more realistic example, let’s read these logs from a file:
一个更实际的例子,让我们从文件中读取这些日志:
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}After the grok filter, the event will have a few extra fields in it:
扩展字段如下:
- client: 55.3.244.1
- method: GET
- request: /index.html
- bytes: 15824
- duration: 0.043
Regular Expression 正则表达式
Grok sits on top of regular expressions, so any regular expressions are valid in grok as well. The regular expression library is Oniguruma, and you can see the full supported regexp syntax on the Oniguruma site.
正则表达式适用于Grok
Custom Patterns自定义格式
Sometimes logstash doesn’t have a pattern you need. For this, you have a few options.
上面的正在不够用,可以自定义
First, you can use the Oniguruma syntax for named capture which will let you match a piece of text and save it as a field:
(?<field_name>the pattern here)field_name:名字,搜索的依据;the pattern here:制定的规则(正则)
For example, postfix logs have a queue id that is an 10 or 11-character hexadecimal value. I can capture that easily like this:
(?<queue_id>[0-9A-F]{10,11})Alternately, you can create a custom patterns file.
- Create a directory called patterns with a file in it called extra (the file name doesn’t matter, but name it meaningfully for yourself)
- In that file, write the pattern you need as the pattern name, a space, then the regexp for that pattern.
For example, doing the postfix queue id example as above:
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}Then use the patterns_dir setting in this plugin to tell logstash where your custom patterns directory is. Here’s a full example with a sample log:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
指定文件路径,过滤文件内容syslogbase
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}The above will match and result in the following fields:
timestamp: Jan 1 06:25:43
logsource: mailserver14
program: postfix/cleanup
pid: 21403
queue_id: BEF25A72965
syslog_message: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
The timestamp, logsource, program, and pid fields come from the SYSLOGBASE pattern which itself is defined by other patterns.Another option is to define patterns inline in the filter using pattern_definitions. This is mostly for convenience and allows user to define a pattern which can be used just in that filter. This newly defined patterns in pattern_definitions will not be available outside of that particular grok filter.
另一种方法是使用pattern_definition在筛选器中内联定义模式。……这种模式在该特定的grok过滤器之外是不可用的。
Grok Filter Configuration Options
This plugin supports the following configuration options plus the Common Options described later.
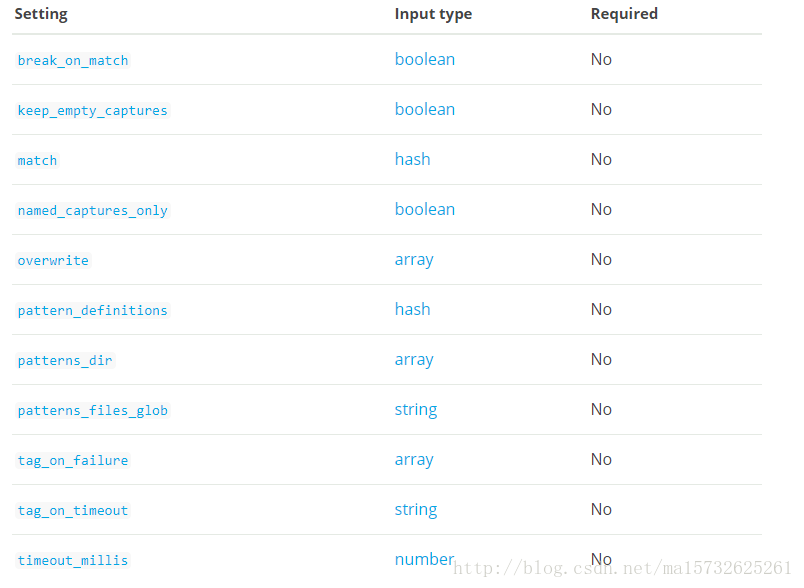
break_on_match
- Value type is boolean
- Default value is true
Break on first match. The first successful match by grok will result in the filter being finished. If you want grok to try all patterns (maybe you are parsing different things), then set this to false.
在第一次匹配中如果成功匹配后将不再进行匹配。如果您希望grok尝试所有模式(也许您正在解析不同的东西),那么将其设置为false。
keep_empty_captures
- Value type is boolean
- Default value is false
If true, keep empty captures as event fields.
如果为true,捕获失败的字段奖设置为空值
match
- Value type is hash
- Default value is {}
A hash of matches of field ⇒ value
filter {
grok { match => { "message" => "Duration: %{NUMBER:duration}" } }
}If you need to match multiple patterns against a single field, the value can be an array of patterns
单个字段上匹配多个模式,那么该值可以是一个模式数组。
filter {
grok { match => { "message" => [ "Duration: %{NUMBER:duration}", "Speed: %{NUMBER:speed}" ] } }
}
named_captures_only
- Value type is boolean
- Default value is true
If true, only store named captures from grok.???
设置为true,只存储grok中命名的字段 ?
overwrite
- Value type is array
- Default value is []
The fields to overwrite.重写
This allows you to overwrite a value in a field that already exists.
For example, if you have a syslog line in the message field, you can overwrite the message field with part of the match like so:
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite => [ "message" ]
}
}In this case, a line like May 29 16:37:11 sadness logger: hello world will be parsed and hello world will overwrite the original message.
覆盖message内容
pattern_definitions
- Value type is hash
- Default value is {}
A hash of pattern-name and pattern tuples defining custom patterns to be used by the current filter. Patterns matching existing names will override the pre-existing definition. Think of this as inline patterns available just for this definition of grok
一个模式名称和元组的hash,定义了当前过滤器所使用的自定义模式。匹配现有名称的模式将覆盖原有的定义。可以将其看作是仅用于grok定义的内联模式。
patterns_diredit
-Value type is array
- Default value is []
Logstash ships by default with a bunch of patterns, so you don’t necessarily need to define this yourself unless you are adding additional patterns. You can point to multiple pattern directories using this setting. Note that Grok will read all files in the directory matching the patterns_files_glob and assume it’s a pattern file (including any tilde backup files).
指定自定义的pattern文件存放目录,Logstash在启动时会读取文件夹内patterns_files_glob 匹配的所有文件内容
patterns_dir => ["/opt/logstash/patterns", "/opt/logstash/extra_patterns"]Pattern files are plain text with format:
NAME PATTERN
For example: NUMBER \d+
The patterns are loaded when the pipeline is created.
patterns_files_glob
Value type is string
Default value is "*"
Glob pattern, used to select the pattern files in the directories specified by patterns_dir
Glob模式,用于在patterns_dir指定的目录中选择模式文件。
tag_on_failure
Value type is array
Default value is ["_grokparsefailure"]
Append values to the tags field when there has been no successful match
当没有成功匹配时,将值附加到标记字段。
tag_on_timeout
Value type is string
Default value is "_groktimeout"
Tag to apply if a grok regexp times out.
如果一个grok regexp超时可以应用标签;
timeout_millis
Value type is number
Default value is 30000
Attempt to terminate regexps after this amount of time. This applies per pattern if multiple patterns are applied This will never timeout early, but may take a little longer to timeout. Actual timeout is approximate based on a 250ms quantization. Set to 0 to disable timeouts
尝试在设定时间后终止regexp。如果应用了多个模式,那么将适用于每个模式,因为这将不会提前超时,但是可能需要更长的时间来超时。实际的超时大约是基于250ms的量子化。设置为0以禁用超时。Common Options
The following configuration options are supported by all filter plugins:以下配置选项由所有过滤器插件支持:

add_field用于向Event中添加字段
- Value type is hash
- Default value is {}
If this filter is successful, add any arbitrary fields to this event. Field names can be dynamic and include parts of the event using the %{field}.
如果此筛选器成功,则在此事件中添加任意字段。字段名可以是动态的,并且使用Bfield}包含事件的部分。
filter {
grok {
add_field => { "foo_%{somefield}" => "Hello world, from %{host}" }
}
}# You can also add multiple fields at once:
filter {
grok {
add_field => {
"foo_%{somefield}" => "Hello world, from %{host}"
"new_field" => "new_static_value"
}
}
}If the event has field “somefield” == “hello” this filter, on success, would add field foo_hello if it is present, with the value above and the %{host} piece replaced with that value from the event. The second example would also add a hardcoded field.
如果事件有字段“somefield”==“hello”,在成功时则会添加字段foo_hello,上面的值和{Bhost}替换为事件的值。第二个示例还将添加一个硬编码字段
add_tage
- Value type is array
- Default value is []
If this filter is successful, add arbitrary tags to the event. Tags can be dynamic and include parts of the event using the %{field} syntax.
filter {
grok {
add_tag => [ "foo_%{somefield}" ]
}
}
# You can also add multiple tags at once:
filter {
grok {
add_tag => [ "foo_%{somefield}", "taggedy_tag"]
}
}If the event has field “somefield” == “hello” this filter, on success, would add a tag foo_hello (and the second example would of course add a taggedy_tag tag).
enable_metric
- Value type is boolean
- Default value is true
Disable or enable metric logging for this specific plugin instance by default we record all the metrics we can, but you can disable metrics collection for a specific plugin.
id
- Value type is string
- There is no default value for this setting.
Add a unique ID to the plugin configuration. If no ID is specified, Logstash will generate one. It is strongly recommended to set this ID in your configuration. This is particularly useful when you have two or more plugins of the same type, for example, if you have 2 grok filters. Adding a named ID in this case will help in monitoring Logstash when using the monitoring APIs.
在插件配置中添加唯一的ID。如果没有指定ID,则Logstash将生成一个。强烈建议在配置中设置此ID。当您有两个或多个相同类型的插件时,这是特别有用的,例如,如果您有两个grok过滤器。在本例中添加一个名为ID的ID将有助于在使用监视api时监视日志存储。
periodic_flush定期刷新
- Value type is boolean
- Default value is false
Call the filter flush method at regular interval. Optional.
remove_field
Value type is array
Default value is []
If this filter is successful, remove arbitrary fields from this event. Example:
filter {
grok {
remove_field => [ "foo_%{somefield}" ]
}
}
# You can also remove multiple fields at once:
filter {
grok {
remove_field => [ "foo_%{somefield}", "my_extraneous_field" ]
}
}If the event has field “somefield” == “hello” this filter, on success, would remove the field with name foo_hello if it is present. The second example would remove an additional, non-dynamic field.
remove_tag
Value type is array
Default value is []
If this filter is successful, remove arbitrary tags from the event. Tags can be dynamic and include parts of the event using the %{field} syntax.
Example:
filter {
grok {
remove_tag => [ "foo_%{somefield}" ]
}
}
# You can also remove multiple tags at once:
filter {
grok {
remove_tag => [ "foo_%{somefield}", "sad_unwanted_tag"]
}
}If the event has field “somefield” == “hello” this filter, on success, would remove the tag foo_hello if it is present. The second example would remove a sad, unwanted tag as well.
删除tag
》感谢分享:
logstash input output filter 插件总结
https://doc.yonyoucloud.com/doc/logstash-best-practice-cn/get_start/index.html















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









