










Elasticsearch 是什么? | Elastic
https://www.elastic.co/cn/what-is/elasticsearch
Quick start | Elasticsearch Guide [8.2] | Elastic
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.html
Download Elasticsearch | Elastic
https://www.elastic.co/cn/downloads/elasticsearch
全文搜索引擎 Elasticsearch 入门教程 - 阮一峰的网络日志
http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
ElasticSearch原理 - 神一样的存在 - 博客园
https://www.cnblogs.com/dreamroute/p/8484457.html
Elasticsearch学习,请先看这一篇!_achuo的博客-CSDN博客_elasticsearch
https://blog.csdn.net/achuo/article/details/87865141
分布式全文搜索引擎ElasticSearch—超详细 - wings丶xh - 博客园
https://www.cnblogs.com/wings-xh/p/12080240.html
ElasticSearch_你天加练的全战攻城狮梦的博客-CSDN博客
https://blog.csdn.net/u010122604/article/details/107089333
Releases · medcl/elasticsearch-analysis-ik · GitHub
https://github.com/medcl/elasticsearch-analysis-ik/releases
沉淀再出发:ElasticSearch的中文分词器ik - 精心出精品 - 博客园
https://www.cnblogs.com/zyrblog/p/9830624.html
ElasticSearch编程操作 - 林染plus - 博客园
https://www.cnblogs.com/mayuan01/p/12391968.html
IK分词器和ElasticSearch集成使用 - 林染plus - 博客园
https://www.cnblogs.com/mayuan01/p/12391942.html
Elasticsearch是一个开源的高扩展的实时分析的分布式全文搜索引擎,实现分布式的实时文件存储,每个字段都可被索引并搜索;本身扩展性很好,可扩展到上百台服务器,可处理PB级结构化或非结构化数据的数据。
Elasticsearch使用Java开发并使用Lucene来实现索引建立和搜索的功能,Elasticsearch是Lucene的封装,提供了RESTful API的操作接口,开箱即用,让全文搜索变得简单并隐藏Lucene的复杂性。API基本格式如下:http://<ip>:<port>/<索引>/<类型>/<文档id>。
Elasticsearch是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,建议使用固态硬盘,使用RAID 0,挂载多块硬盘,避免使用 NFS(Network File System)等远程存储设备。
Kibana是一个开源的分析和可视化平台,旨在与Elasticsearch合作。Kibana提供搜索、查看和与存储在Elasticsearch索引中的数据进行交互的功能,开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。


(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)。
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type)。
(3)一个数据库表(Table)下的数据由多行(row,记录)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多个Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。与之对应的,在ES中,Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查select操作等价于ES中的增PUT、删DELETE、改POST、查GET。
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念,可定义任意多的索引。
类型(type)
在一个索引中,可以定义一种或多种类型。一个类型是索引的一个逻辑上的分类或分区,通常会为具有一组共同字段的文档定义一个类型。比如,一个博客平台的各种数据存储到一个索引中,在这个索引中,可以为用户数据定义一个类型,为博客数据定义一个类型,当然,也可以为评论数据定义一个类型。类型类似于关系型数据库中Table的概念。
文档(document)
一个文档是一个可被索引的基础信息单元。比如,可以是某个客户的文档,某个产品的文档,或某个订单的文档。文档以JSON(Javascript Object Notation)格式来表示。
在一个index/type里面,可以存储任意多的文档,文档必须被赋予一个index的type。文档类似于关系型数据库中Record的概念。实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。指定id用PUT,自动生成id用POST。 
分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。创建一个索引的时候,可以指定想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
允许水平分割/扩展内容容量
允许在分片之上进行分布式并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对用户来说都是透明的。
在一个网络/云的环境里,失败随时都可能发生,某个分片/节点不知怎么就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此,Elasticsearch允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
在分片/节点失败的情况下,提供了高可用性。复制分片从不与主分片置于同一节点上是非常重要的。
扩展搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。索引创建之后,可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果集群中至少有两个节点,索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,取决于集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
Mapping是Elasticsearch中很重要的一个内容,类似于传统关系型数据中table的schema,用于定义一个索引(index)的某个类型(type)的文档(document)的结构。
Mapping主要包括字段名、字段数据类型和字段索引类型这3个方面的定义。
字段名:与传统数据库字段名作用一样,就是给字段起个唯一的名字,让系统和用户能识别。
字段数据类型:定义该字段保存的数据的类型,不符合数据类型定义的数据不能保存到Elasticsearch中。下表列出的是Elasticsearch支持的数据类型。 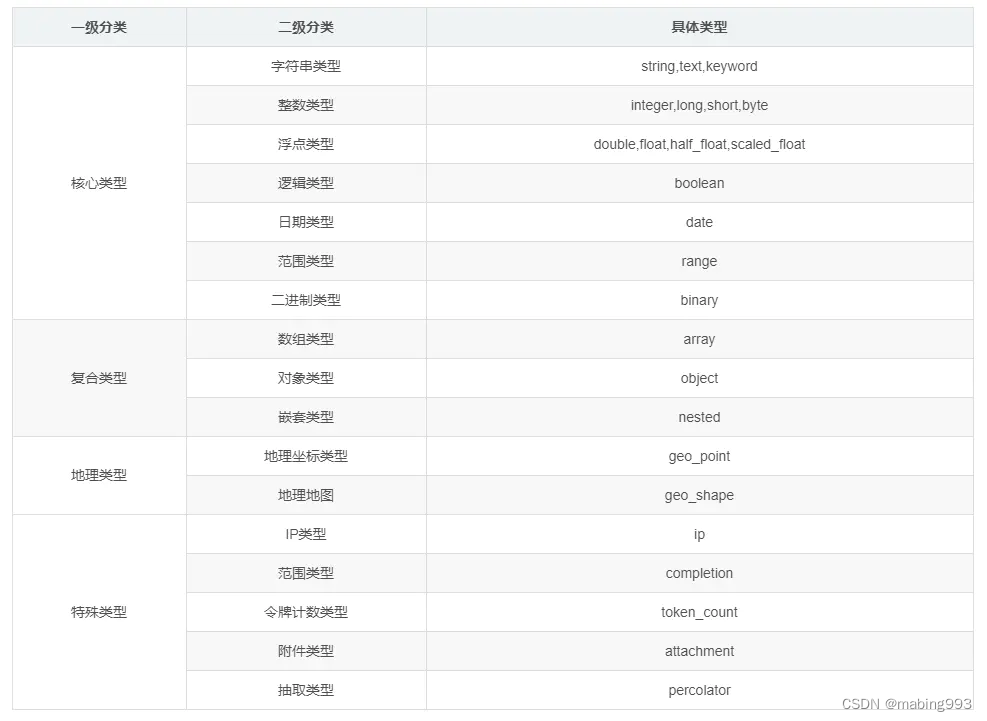
string在旧版本中使用较多,从Elasticsearch5.x开始不再支持string,由text和keyword替代。text用于全文搜索,而keyword用于关键词搜索。
text:会分词,然后进行索引;支持模糊、精确查询;不支持聚合
keyword:不进行分词,直接索引;支持模糊、精确查询;支持聚合
如果不指定数据类型,ElasticSearch字符串将默认被同时映射成text和keyword。
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword类型适用于索引结构化的字段,比如Email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
字段索引类型:索引是ES中的核心,ES之所以能够实现实时搜索,完全归功于Lucene这个优秀的Java开源索引。在传统数据库中,如果在字段上建立索引,仍然能以该字段作为查询条件进行查询,只不过查询速度慢点。而在ES中,字段如果不建立索引,就不能以这个字段作为查询条件来搜索。也就是说,不建立索引的字段仅仅能起到数据载体的作用。string是日常使用最多的数据类型,下图介绍mapping中string可以配置的索引类型。
Elasticsearch对字符串有两种完全不同的搜索方式。可以按照整个文本进行匹配,即关键词搜索(keyword search)——not_analyzed,也可以按单个字符匹配,即全文搜索(full-text search)——analyzed。
ElasticSearch7.x默认不再支持指定索引类型,在ES中,不需要专门单独创建索引、类型,而是可以直接向索引、类型中插入数据,如果索引、类型当时不存在,它们会被自动创建。同理,如果插入数据时,id已经存在,则会自动重写文档,即变成了更新操作,而且ES默认会对document每个field都建立倒排索引,让其可以被搜索。
ElasticSearch 7.x 报错:Root mapping definition has unsupported parameters_咖啡掠地狮的博客-CSDN博客
https://blog.csdn.net/andwey/article/details/107150087
一、配置
Java jre就可以了,sudo apt-get install default-jre
在/etc/sysctl.conf文件最后添加一行并执行sysctl -p
vm.max_map_count=262144
默认情况下,Elasticsearch只允许本机访问,如果需要远程访问,可以修改 Elasticsearch安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何IP都可访问。线上服务不要这样设置,要设成具体的IP。
配置data和logs目录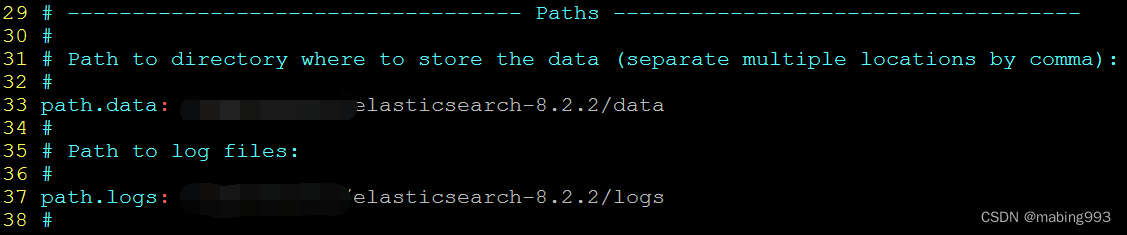
Elasticsearch默认开启了ssl认证,导致无法访问9200端口,修改elasticsearch.yml的xpack.security.enabled:把true改成false。其他配置可根据需求更改,可参考
Important Elasticsearch configuration | Elasticsearch Guide [8.2] | Elastic
https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html
Important system configuration | Elasticsearch Guide [8.2] | Elastic
https://www.elastic.co/guide/en/elasticsearch/reference/current/system-config.html
Elasticsearch入门,这一篇就够了 - sunsky303 - 博客园
https://www.cnblogs.com/sunsky303/p/9438737.html
Elasticsearch启动需要时间,并且要占用大量内存,如下便是启动成功。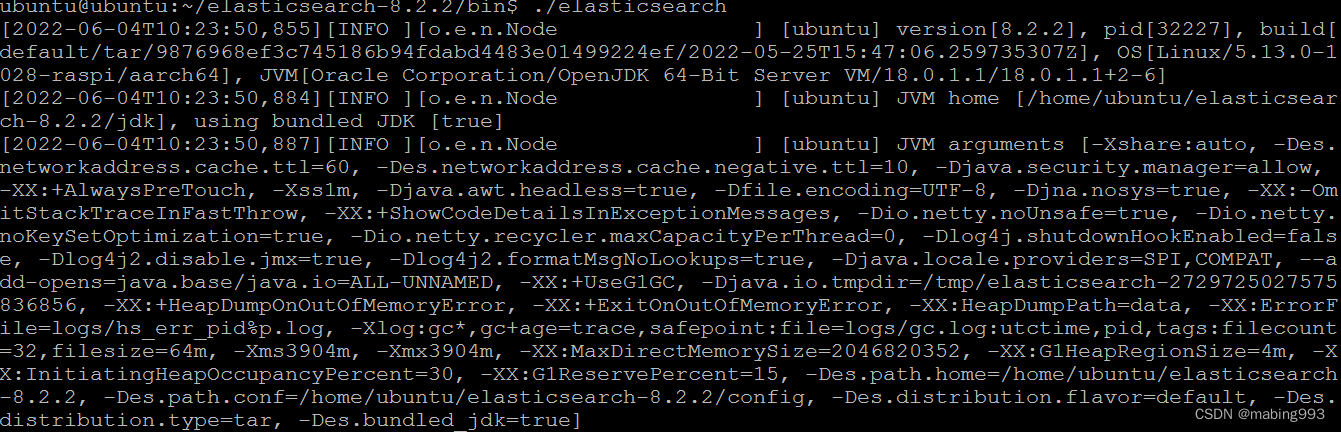
查看信息http://localhost:9200/

查看健康信息http://localhost:9200/_cat/health?v

查看节点http://localhost:9200/_cat/nodes?v

查看索引http://localhost:9200/_cat/indices?v

Kibana介绍、安装和使用_少年阿峣_从零单排的博客-CSDN博客
https://blog.csdn.net/qq_18769269/article/details/80843810
配置kibana.yml
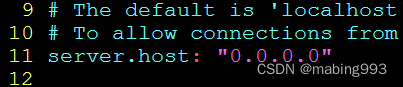


查看状态http://localhost:5601/status
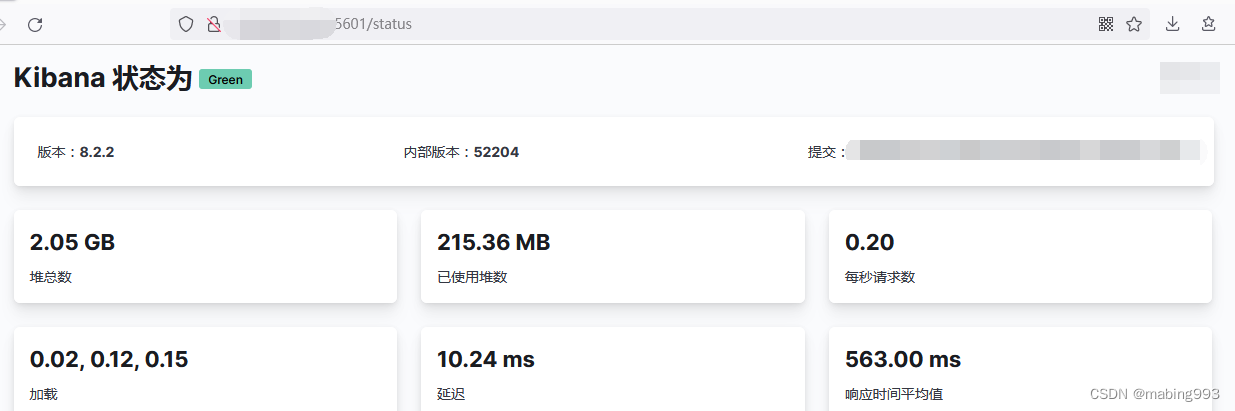
Kibana默认包含X-Pack,无需额外安装

写入自启动,写成单独脚本,然后放到/etc/rc.local开机执行


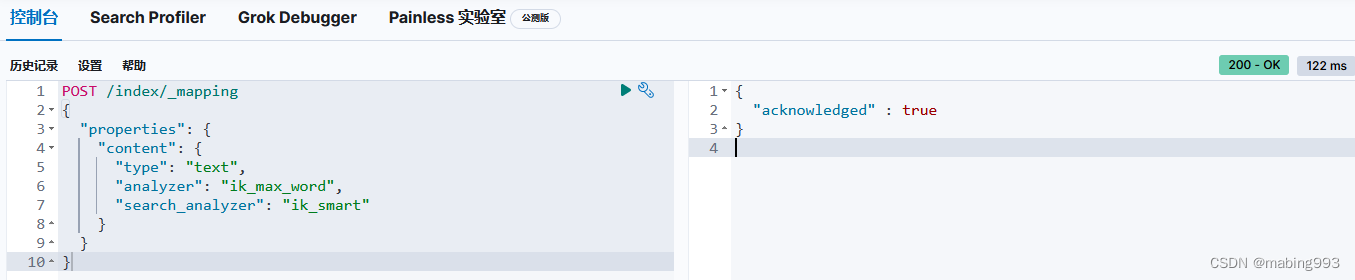
Elasticsearch的分词器称为analyzer,analyzer是字段文本的分词器,search_analyzer是搜索词的分词器,在定义Mapping时要用到。
IK5.0.0版本移除analyzer(分析器)和tokenizer(分词器),请分别使用ik_smart和ik_max_word。
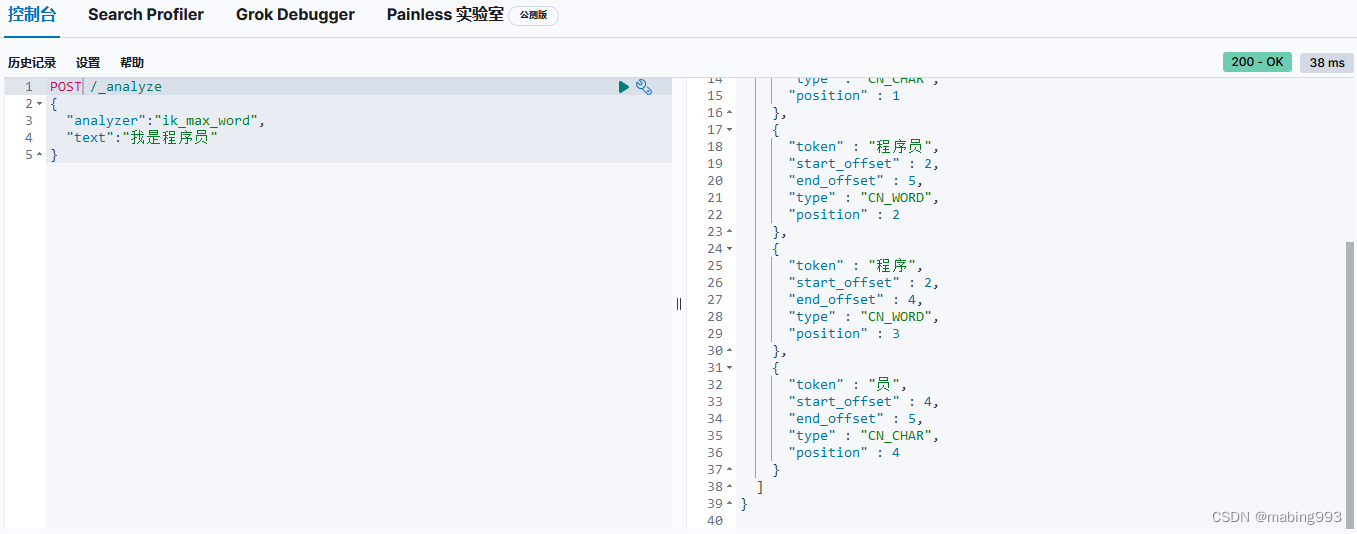
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合。
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
github选择v8.2.0,支持Elasticsearch8.2.2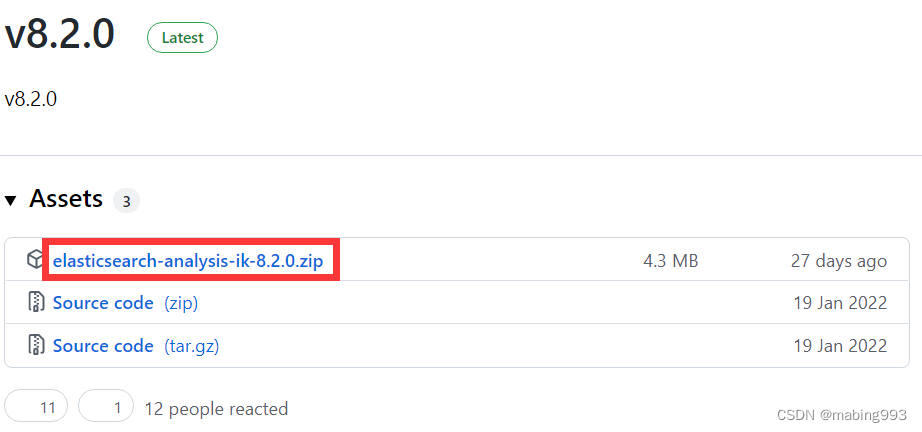
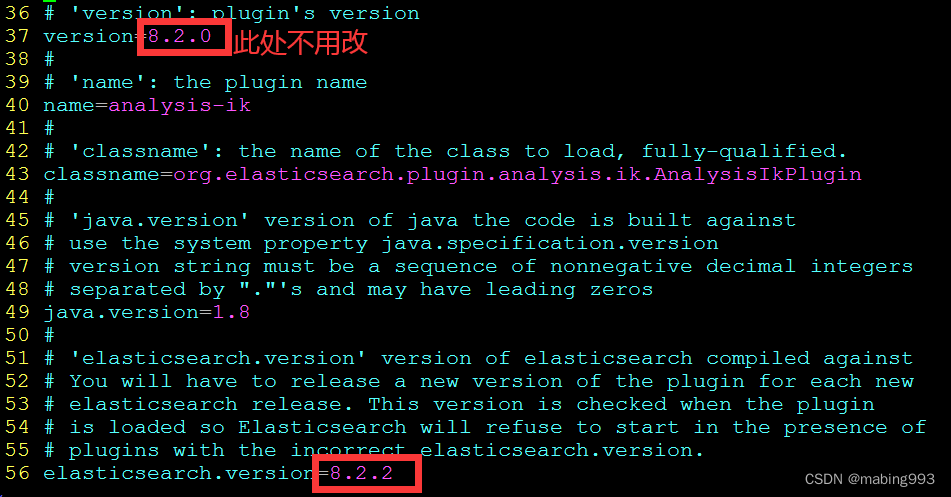
修改plugin-descriptor.properties版本为8.2.2
重启ES,ES重启完成后,Kibana也重启

扩展分词可参考
elasticsearch ik分词--实现专有名词分词 同义词解析_【随风飘流】的博客-CSDN博客_ik分词器同义词
https://blog.csdn.net/LG772EF/article/details/104062113
远程热更新可参考
ik分词器热更新_sun_duoLong的博客-CSDN博客_ik分词热更新
https://blog.csdn.net/sun_duoLong/article/details/79212618
elasticsearch的ik分词器实现词库热更新的三种方案_Yic.z的博客-CSDN博客_elasticsearch ik分词库热更新
https://blog.csdn.net/qq_40592041/article/details/107856588
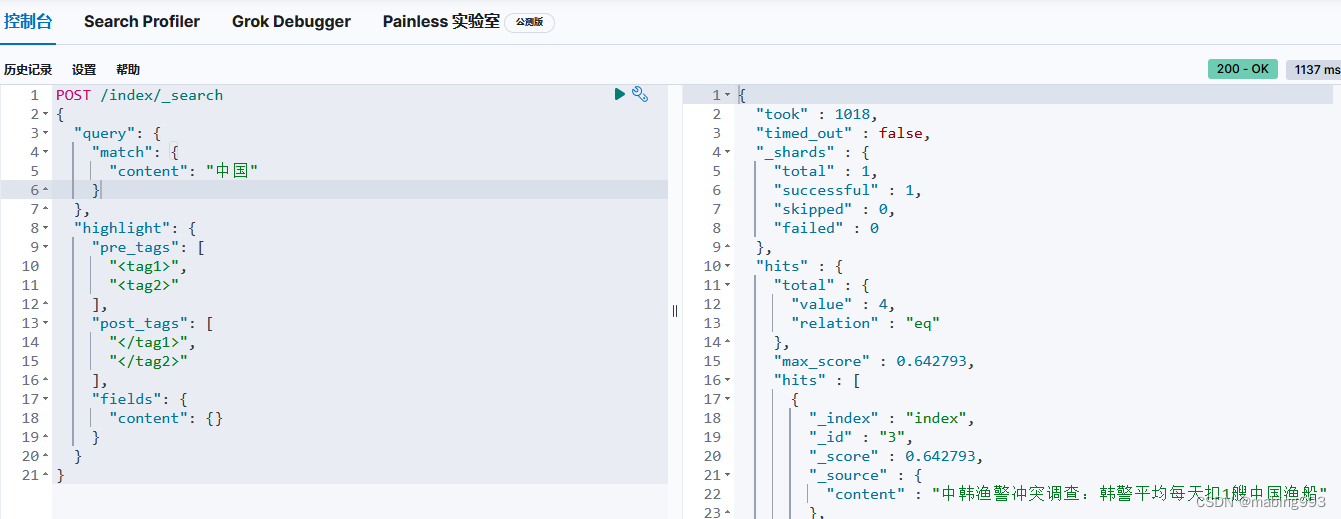
Kibana测试一下IK,使用下面的example
GitHub - medcl/elasticsearch-analysis-ik at v8.2.0
https://github.com/medcl/elasticsearch-analysis-ik/tree/v8.2.0

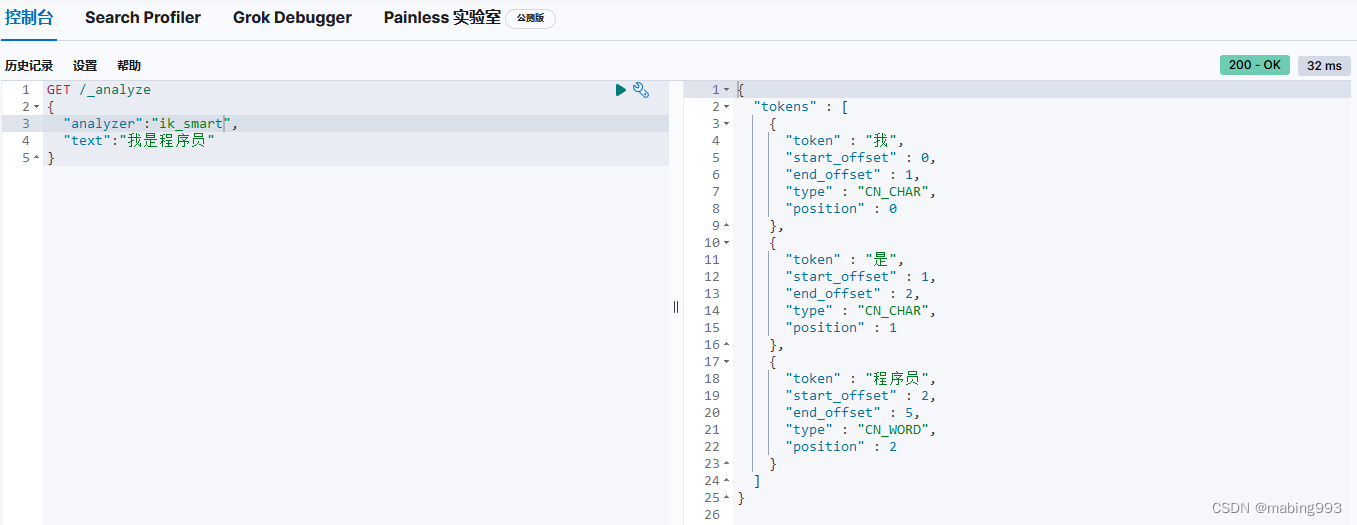
ES6.0版本以下,查看分词效果,可直接在URL中指定分词器和查询词,方法是GET,如:
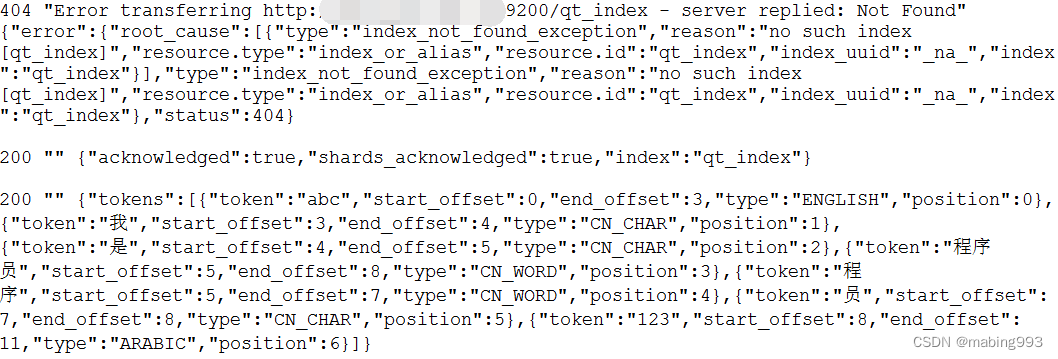
http://localhost:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员
http://localhost:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
ES6.0版本以上,查看分词效果,可使用GET或POST,但是分词器和查询器需要以json的形式写在body里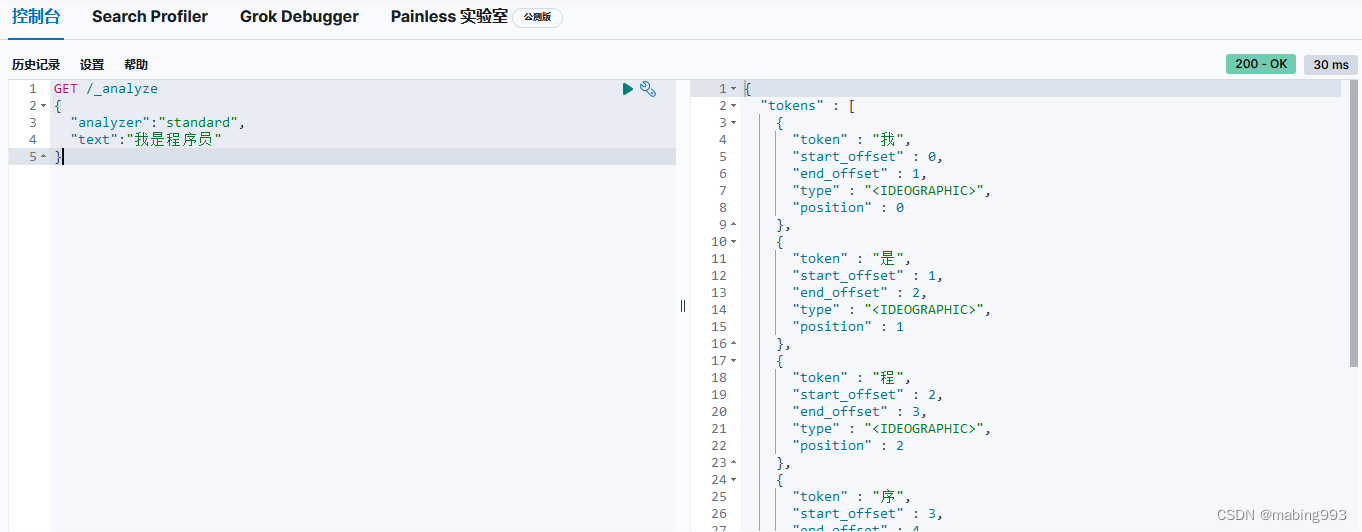
GitHub - elastic/elasticsearch-py: Official Elasticsearch client library for Python
https://github.com/elastic/elasticsearch-py
sudo pip3 install elasticsearch 
出现错误和警告不影响使用
如何使用Qt调用基于SpringCloud的Rest服务_第一本座的博客-CSDN博客_qt 微服务
https://blog.csdn.net/m0_37182645/article/details/82120668
QT调用Restful服务_kinghero123456的博客-CSDN博客_qt restful
https://blog.csdn.net/u014378771/article/details/97759043
pro加QT += network
#include "mainwindow.h"
#include "ui_mainwindow.h"
#include <QtNetwork/QNetworkRequest>
#include <QtNetwork/QNetworkReply>
#include <QtCore/QJsonObject>
#include <QtCore/QJsonDocument>
#include <QDebug>
MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent),
ui(new Ui::MainWindow)
{
ui->setupUi(this);
{
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200";
QString strInput;
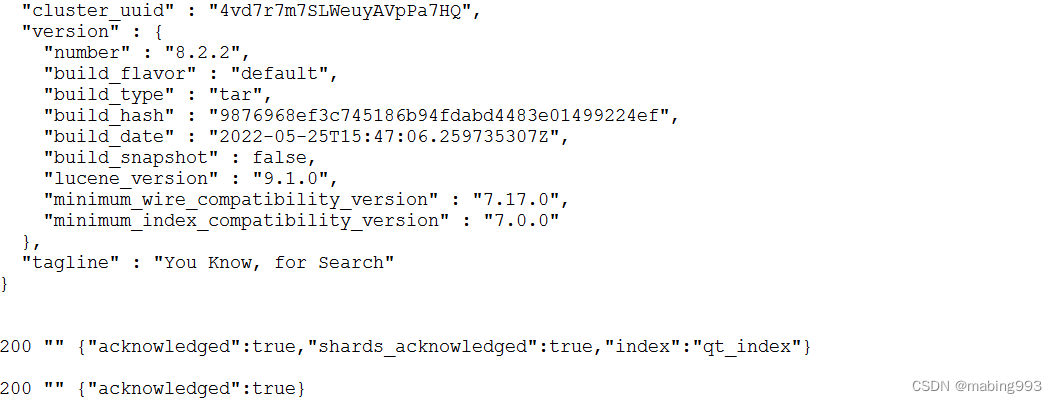
int code = SendAndGetText(strUrl, "GET", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
{
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200/qt_index";
QString strInput;
int code = SendAndGetText(strUrl, "PUT", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
{
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200/qt_index";
QString strInput;
int code = SendAndGetText(strUrl, "DELETE", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
{
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200/qt_index";
QString strInput;
int code = SendAndGetText(strUrl, "DELETE", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
{
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200/qt_index";
QString strInput;
int code = SendAndGetText(strUrl, "PUT", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
{
QJsonObject oSendObject;
oSendObject.insert("analyzer", "ik_max_word");
oSendObject.insert("text", QStringLiteral("abc我是程序员123"));
QJsonDocument doc;
doc.setObject(oSendObject);
QByteArray body = doc.toJson();
QString strMessage;
QString strResult;
QString strUrl = "http://localhost:9200/_analyze";
QString strInput = body;
int code = SendAndGetText(strUrl, "POST", strInput, strMessage, strResult);
qDebug() << code << strMessage << qUtf8Printable(strResult) << endl;
}
}
MainWindow::~MainWindow()
{
delete ui;
}
int MainWindow::SendAndGetText(QString strUrl, QString method, QString strInput, QString &strMessage,QString &strResult)
{
QNetworkRequest oNetRequest;
oNetRequest.setUrl(QUrl(strUrl));
oNetRequest.setRawHeader("Content-Type", "application/json");
QNetworkAccessManager oNetAccessManager;
QNetworkReply* oNetReply = Q_NULLPTR;
if (method == "POST")
{
oNetReply = oNetAccessManager.post(oNetRequest, strInput.toUtf8().data());
}
else if (method == "PUT")
{
oNetReply = oNetAccessManager.put(oNetRequest, strInput.toUtf8().data());
}
else if (method == "GET")
{
oNetReply = oNetAccessManager.get(oNetRequest);
}
else if (method == "DELETE")
{
oNetReply = oNetAccessManager.deleteResource(oNetRequest);
}
QEventLoop loop;
connect(oNetReply, SIGNAL(finished()), &loop, SLOT(quit()));
loop.exec();
int httpCode = oNetReply->attribute(QNetworkRequest::HttpStatusCodeAttribute).toInt();
strResult = oNetReply->readAll();
if (oNetReply->error())
{
strMessage = oNetReply->errorString();
}
oNetReply->deleteLater();
return httpCode;
}















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









