







文章目录
1.数据、工具库导入
1.1将官方给定数据集导入,并了解数据构成
1.1.1计算总用时
import time
from datetime import datetime
start_time = time.time()
1.1.2引用主干部分所需库
%matplotlib inline
import numpy as np
from numpy.random import seed
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
import warnings
warnings.filterwarnings('ignore')
1.1.3模型、结果计算所需工具导入
# SVC
from sklearn.svm import SVC
# ensemble
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier
# Logistic
from sklearn.linear_model import LogisticRegression
# SGD
from sklearn.linear_model import SGDClassifier
# KNN
from sklearn.neighbors import KNeighborsClassifier
# model selection
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
# preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.compose import ColumnTransformer
# Vote
from sklearn.ensemble import VotingClassifier
from sklearn.model_selection import train_test_split
1.1.4导入数据
train_data = pd.read_csv(r'train.csv')
test_data = pd.read_csv(r'test.csv')
data_Age = train_data.copy()
PassengerId = test_data['PassengerId']
test_data['Survived'] = -1
train_data['Set'] = "Train"
test_data['Set'] = "Test"
DATA = train_data.append(test_data)
DATA.reset_index(inplace=True)
1.1.5 分别查看实验数据集和预测数据集数据
print('实验数据大小:',train_data.shape)
print('预测数据大小:',test_data.shape)
实验数据大小: (891, 13)
预测数据大小: (418, 13)
1.1.6 输出数据前五行,查看数据的构成
display(train_data.head())
test_data.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Set | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | Train |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | Train |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | Train |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | Train |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | Train |
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Survived | Set | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q | -1 | Test |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S | -1 | Test |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q | -1 | Test |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S | -1 | Test |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S | -1 | Test |
-
可以看到数据集中排除ID和存活情况,涵盖了乘客的十项基本信息。
-
分别是Pclass、Name、Sex、Age、SibSp、Parch、Ticket、Fare、Cabin、Embarked
-
而预测数据集比实验数据集少一栏"Survived"数据
1.2数据查看
- 故接下来首先简单看一下乘客不同属性的分布,通过数据可视化的方式输出图表,方便进行观察思考
import matplotlib.pyplot as plt
import pylab as mp1
mp1.rcParams['font.sans-serif']=['SimHei']
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((5,3),(0,0)) #分出子图
train_data.Survived.value_counts().plot(kind='bar')
plt.title(u"获救情况") #标题设定
plt.ylabel(u"人数")
plt.subplot2grid((5,3),(0,2))
train_data.Pclass.value_counts().plot(kind="bar")
plt.title(u"乘客等级分布")
plt.ylabel(u"人数")
plt.subplot2grid((5,2),(2,0), colspan=2)
train_data.Age[train_data.Pclass == 1].plot(kind='kde')
train_data.Age[train_data.Pclass == 2].plot(kind='kde')
train_data.Age[train_data.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")
plt.ylabel(u"密度")
plt.title(u"各等级乘客年龄分布")
plt.legend((u'1等舱', u'2等舱',u'3等舱'),loc='best')
plt.subplot2grid((5,3),(4,0))
train_data.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.subplot2grid((5,3),(4,2))
train_data.Sex.value_counts().plot(kind="bar")
plt.title(u"乘客性别分布")
plt.ylabel(u"人数")
plt.show()

可以从图表中获得以下一些基础信息:
- 1、其中死亡人数是远远大于获救人数,高达总人数的2/3
- 2、乘客中男性人数远远大于女性人数
- 3、不同船舱年龄分布总体趋势相近,但细节有所不同。一等舱和二等舱以三四十岁左右的人居多,三等舱以二十岁左右的人居多
- 4、在S港口登船的人占绝大多数,同时S、C、Q呈递减状态
- 5、处于三等舱的人员最多
借此引发思考:
- 1、因为在沉船时有秉承女人和孩子先走的原则,故之后可对不同性别以及不同年龄的存活率进行比较
- 2、船舱等级(票价)的不同或许代表着社会地位的不同,地位高的人或许会在沉船时享受特权,获得优先离船的权利,之后可根据此进行对比分析
- 3、或许不同的登船口对最后存活率也有影响,不排除某些港口女性、孩子或者地位高的人较多的可能,可结合以上两点比较
- 4、数据中还给了亲属关系,船票连号的人员可能是一家人,不排除家人之间互相让获救机会的可能,可简单分析比较
……
2.填充缺失值
- 首先观察一下给定数组中是否有缺失值的存在,若有想办法进行填充以提高特征分析的准确率
DATA.isnull().sum()
index 0
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 1014
Embarked 2
Set 0
dtype: int64
- 可以看到数据中Age、Cabin、Embarked都有空缺,而之前思考中需要对这几个特征值进行比较分析,故需要进行缺失值填充
2.1船舱位置Cabin
-
由于船舱缺失值较多,将近一半,且数据十分分散。
-
通过简单的观察可以看到其由字母和数字构成,猜测字母应该代表某片区域,数字代表具体座位或者房间号。
-
因为认为其仍旧有一定的比较价值,故打算用unknown的开头字母U填补所有的空缺值,后续提取其余数据的开头字母A-E,由此对其存活率进行比较。
#自定义函数
def fd(cabin):
if cabin is np.nan:
return 'U'
else:
return cabin[0]
DATA['Cabin'] = DATA['Cabin'].apply(fd)
DATA['Cabin'].head(10)
0 U
1 C
2 U
3 C
4 U
5 U
6 E
7 U
8 U
9 U
Name: Cabin, dtype: object
- 可以看到上述代码将 “Cabin” 类填充并直接提取了开头字母,使得数据整体更简洁。
2.2港口位置Embarked
- 由上述简单数据查看中可知,港口位置缺失值只有两个,且通过图表可看到在S港口登船的人员最多,因此选择用众数进行填充
DATA['Embarked'] = DATA['Embarked'].fillna('S')
2.3年龄age
-
年龄的缺失值偏中等,原本可以运用均值或中位数的方法进行填充,但由于年龄在规律寻找中的特征占比十分重要,其准确度会极大影响后续结果,为了提高准确度,打算寻求其他办法。
-
这里选择用称谓给乘客分类,再取每种称谓的中位数填补age
DATA['Title']=DATA['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip()) #从name中导出含有称谓的信息
pd.crosstab(DATA['Title'],DATA['Sex'])
| Sex | female | male |
|---|---|---|
| Title | ||
| Capt | 0 | 1 |
| Col | 0 | 4 |
| Don | 0 | 1 |
| Dona | 1 | 0 |
| Dr | 1 | 7 |
| Jonkheer | 0 | 1 |
| Lady | 1 | 0 |
| Major | 0 | 2 |
| Master | 0 | 61 |
| Miss | 260 | 0 |
| Mlle | 2 | 0 |
| Mme | 1 | 0 |
| Mr | 0 | 757 |
| Mrs | 197 | 0 |
| Ms | 2 | 0 |
| Rev | 0 | 8 |
| Sir | 0 | 1 |
| the Countess | 1 | 0 |
- 可以看到数据中对乘客的称呼,如:Mr、Miss、Mrs等,可以从中看到他们的年龄和性别,同时有如 Dr、Capt、Lady等,我们可以看到他们的社会地位,关于社会地位可以在后续特征分析中加以利用,但这里只需要通过简单的性别分类称谓,故会将这些代表不同身份的称谓暂时归类到Mr、Miss、Mrs、Master里面。
2.3.1对title信息的整合
TitleDict = {} #重新整合键
TitleDict['Capt'] = 'Mr'
TitleDict['Col'] = 'Mr'
TitleDict['Don'] = 'Mr'
TitleDict['Dr'] = 'Mr' #由于Dr数据占比不大对结果影响较小,出于方便,直接将其中一名女性归类到Mr里
TitleDict['Lady'] = 'Mrs'
TitleDict['Jonkheer'] = 'Mrs'
TitleDict['Major'] = 'Mr'
TitleDict['Miss'] = 'Miss'
TitleDict['Mlle'] = 'Miss'
TitleDict['Master'] = 'Master'
TitleDict['Mme'] = 'Mrs'
TitleDict['Mr'] = 'Mr'
TitleDict['Mrs'] = 'Mrs'
TitleDict['Ms'] = 'Mrs'
TitleDict['Rev'] = 'Mr'
TitleDict['Sir'] = 'Mr'
TitleDict['the Countess'] = 'Mrs'
import copy
data_name = DATA.copy() #创建一个拥有新内存地址的字典将data_train赋值,以免影响后续分析
data_name['Title'] = data_name['Title'].map(TitleDict)
data_name['Title'].value_counts() #查看各自所占的比例
Mr 782
Miss 262
Mrs 203
Master 61
Name: Title, dtype: int64
- 以上可以看到已经将所有的根据"Title"分出了四类,并且也可以看到船中确实是年长男性偏多
2.3.2将已有的称谓再分类,提高准确率
df = data_name.copy()
df = df.dropna(how='any')
#查看每个称谓段里年龄的最大最小值
df1 = df.loc[df['Title'].isin(['Mr'])]
print('Mr 最大年龄为:',df1['Age'].max())
print('Mr 最小年龄为:',df1['Age'].min())
df2 = df.loc[df['Title'].isin(['Miss'])]
print('Miss 最大年龄为:',df2['Age'].max())
print('Miss 最小年龄为:',df2['Age'].min())
df3 = df.loc[df['Title'].isin(['Mrs'])]
print('Mrs 最大年龄为:',df3['Age'].max())
print('Mrs 最小年龄为:',df3['Age'].min())
df4 = df.loc[df['Title'].isin(['Master'])]
print('Master 最大年龄为:',df4['Age'].max())
print('Master 最小年龄为:',df4['Age'].min())
Mr 最大年龄为: 80.0
Mr 最小年龄为: 11.0
Miss 最大年龄为: 63.0
Miss 最小年龄为: 0.17
Mrs 最大年龄为: 76.0
Mrs 最小年龄为: 14.0
Master 最大年龄为: 14.5
Master 最小年龄为: 0.33
由上述代码可以看出除了 "Master" 类之外,其他三类称谓中包含的年龄仍有较大跨度,故接下来为提高准确性仍旧需要进行再分类。
-
首先将所有的年龄缺失值补充为0;
-
其次构建函数;
-
对于Age值存在的数据:由于数据中 “Master” 类的最大值为12,故这里也取12作为分界值。而 “Mr”、“Miss”、“Mrs” 类中的最大年龄可以忽略,但需要添入 “Girl” 称谓,将 “Mrs”、“Miss” 类中所有年龄小于等于12且不等于0的人归于此类。同样的,将 “Mr” 类中年龄小于等于12且不等于0的归于 “Master” 类。
-
对于Age值不存在的数据:显然年龄小于等于12的孩子在船上一般会有父母陪同,故将年龄值为0且有直系亲属的 “Miss” 类归于 “Girl” 类,同样的,将 “Mr” 类中年龄值为0的归于 “Master” 类。
2.3.3最后用不同称谓的中位数进行年龄的填补
data_name=data_name.fillna(0)
#自定义函数
def girl(aa):
if (aa.Age!=0) & (aa.Sex=='female') & (aa.Age<=12):
return 'Girl'
elif (aa.Age==0) & (aa.Title=='Miss') & (aa.Parch!=0):
return 'Girl'
else:
return aa.Title
def master(bb):
if (bb.Age!=0) & (bb.Sex=='male') & (bb.Age<=14):
return 'Master'
elif (bb.Age==0) & (bb.Title=='Master') & (bb.Parch!=0):
return 'Master'
else:
return bb.Title
data_name['Title']=data_name.apply(master,axis=1) #调用函数
data_name['Title']=data_name.apply(girl,axis=1)
dict=['Mr','Miss','Mrs','Master','Girl']
#循环,当遇到Age值为0时,进行填充
for i in dict:
data_name.loc[(data_name.Age==0)&(data_name.Title==i),'Age']=data_name.loc[data_name.Title==i,'Age'].median()
DATA['Age']=data_name['Age'].copy()
data_name['Title'].value_counts() #查看各自所占的比例
Mr 777
Miss 208
Mrs 203
Master 66
Girl 54
0 1
Name: Title, dtype: int64
- 通过上述代码已经填补了Age所有的缺失值,也同样可以看到称谓也根据年龄进行了一定的调整
2.4Fare
- 由于Fare缺失值只有一个,故可以用中位数进行填补
DATA['Fare']=DATA['Fare'].fillna(DATA['Fare'].median())
2.5再次观察数据
DATA.isnull().sum()
index 0
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
Set 0
Title 0
dtype: int64
- 可以看到所有的缺失值已经被填充完毕。
3.数据可视化
3.1Sex 性别差异
colors = ['lightsteelblue','slategray']
train_data['Sex'].value_counts().plot.pie(autopct = '%1.2f%%',colors = colors,textprops={'fontsize': 13.5})
#绘制饼图,调整颜色属性及文字大小
plt.show()

- 可以看到在Titanic上男性的人数是远远大于女性的,那是否男性存活率也会大于女性呢,以下就进行存活率的可视化
colors = ['lightsteelblue','slategray']
sns.barplot(x="Sex", y="Survived", data=train_data,palette = colors,alpha=0.7)
plt.show()

- 从上图可以看出虽然男性所占人数更大,但女性活下来概率是远远大于男性的,甚至将近4:1;
所以一方面可以知道Titanic在救援时确实有践行Lady first的原则,另一方面也可以知道Sex要作为重要特征放入最后的模型中。
3.2Pclass 船舱等级差异
colors = ['slategray','lightsteelblue','cornflowerblue']
sns.barplot(x="Pclass", y="Survived", data=train_data,palette = colors,alpha=0.7)
plt.show()

-
可以看到一等舱的存活率是最高的,二等舱次之,三等舱为末。
-
猜测应该是船舱等级高的人群社会地位较高,或许能够相对优先获得逃生机会,但所得信息较少,仍需继续分析。
3.2.1 不同船舱等级下,不同性别的生存情况
colors = ['lightsteelblue','slategray']
sns.barplot(data = train_data, x = 'Pclass',y = 'Survived',hue = "Sex", palette = colors,alpha=0.7);
plt.show()

- 首先总体来看,每个船舱都是女性生存率远远高于男性
3.3Age 年龄差异
3.3.1 总体年龄分布
#绘制直方图
plt.figure(figsize=(15,7)) #大小设定
data_Age['Age'].hist(bins=70,color='darkred',alpha=0.5)
plt.xlabel('Age')
plt.ylabel('Num')
plt.show()

- 可以看到年龄分布从0至80都有涵盖,但总体还是以20至40岁的人居多
思考:是否是人数涵盖最广的年龄段存活率更高,是否存在年龄较小的乘客存活率更高的可能?年龄和性别是否相互影响?故需要继续深入分析
3.3.2 不同性别在不同年龄的生存分布
#绘制直方图比较
survived = 'survived'
not_survived = 'not survived'
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(16, 8))
women = data_Age[data_Age['Sex']=='female']
men = data_Age[data_Age['Sex']=='male']
ax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[0], kde =False, color="orange")
ax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[0], kde =False, color="r")
ax.legend()
ax.set_title('Female')
ax = sns.distplot( men[men['Survived']==1].Age.dropna(),bins=18, label = survived, ax = axes[1], kde = False, color="orange")
ax = sns.distplot(men[men['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[1], kde = False, color="r")
ax.legend()
ax.set_title('Male');

-
可以看到女性差不多在15—35间的生存人数占比更多,而男性在30左右以及0—5间的生存人数占比更多;
-
但从图中也大致可以看出女性在15-35间的存活率同样较高,而男性在0-10间的生存率会更高一点。
3.3.3 不同年龄层下生还情况
#自定义函数分出三个年龄段
def cut_age(age):
if age <= 15:
return 'child'
if age >= 60:
return 'senior'
return 'adult'
data_Age['Age_Cat'] = data_Age.Age.apply(cut_age) #调用函数
#绘图
colors = ['orange','r','purple']
sns.barplot(x="Age_Cat", y="Survived", data=data_Age,palette = colors,alpha=0.7)
plt.show()

- 所以最终我们可以看到,child的存活率是最高的,其后依次为adult、senior;
所以可以知道Titanic在救援时也有孩子先走的优先原则,同样的,Age也是重要特征之一。
3.4不同称呼的生存率
#从name中导出含有称谓的信息
train_data['Title']=train_data['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
#给称谓重新分类
Title_Dict = {}
TitleDict['Capt'] = 'Officer'
TitleDict['Col'] = 'Officer'
TitleDict['Major'] = 'Officer'
TitleDict['Dr'] = 'Officer'
TitleDict['Rev'] = 'Officer'
TitleDict['Don'] = 'Royalty'
TitleDict['Sir'] = 'Royalty'
TitleDict['the Countess'] = 'Royalty'
TitleDict['Lady'] = 'Royalty'
TitleDict['Mme'] = 'Mrs'
TitleDict['Ms'] = 'Mrs'
TitleDict['Mrs'] = 'Mrs'
TitleDict['Miss'] = 'Miss'
TitleDict['Mlle'] = 'Miss'
TitleDict['Mr'] = 'Mr'
TitleDict['Jonkheer'] = 'Mr'
TitleDict['Master'] = 'Master'
data_title = train_data.copy()
data_title['Title'] = data_title['Title'].map(TitleDict)
#绘图
sns.barplot(x="Title", y="Survived", data=data_title)
plt.show()

-
可以看到称谓为 “Royalty”、“Mrs”、“Miss” 类的乘客存活率相对较高,“Mr” 类的乘客存活率最低。
-
原本猜测或许社会地位较高的人群或许拥有特权的可能性确实存在,因为 “Royalty” 类存活率确实较高,故称谓也需要进行考量。
3.5Parch SibSp 亲友人数差异
之前对亲属人数的有所思考:有亲友的人是否会因为亲人之间的互相好虎而拥有更大存活率?
3.5.1 数量分布查看
sns.barplot(data=train_data,x='Parch',y='Survived')
plt.show()

- 上图展现的是拥有不同直系亲属的乘客的存活率,可以看到有1-3个直系亲属时存活率高一点,但总体特征并没有很明显。
sns.barplot(data=train_data,x='SibSp',y='Survived')
plt.show()

- 同直系亲属给出的结论相似,我们可以看到有1-2个兄弟姐妹的乘客存活率高,没有或兄弟姐妹更多的存活率相对较低,但总体特征不明显
故打算考虑有无的区别看存活率
3.5.2 观察有亲属和无亲属的区别
sibsp_df = train_data[train_data['SibSp'] != 0]
no_sibsp_df = train_data[train_data['SibSp'] == 0]
colors = ['lightsteelblue','slategray']
plt.figure(figsize=(10,5))
#绘制有兄弟姐妹的存活饼图
plt.subplot(121)
sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%',colors=colors)
plt.xlabel('sibsp')
#无兄弟姐妹
plt.subplot(122)
no_sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%',colors=colors)
plt.xlabel('no_sibsp')
parch_df = train_data[train_data['Parch'] != 0]
no_parch_df = train_data[train_data['Parch'] == 0]
colors = ['m','thistle']
plt.figure(figsize=(10,5))
plt.subplot(121)
#绘制有父母孩子的存活饼图
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%',colors=colors)
plt.xlabel('parch')
#无父母孩子
plt.subplot(122)
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%',colors=colors)
plt.xlabel('no_parch')
plt.show()
plt.show()


- 由上面四张图可以看出,对于没有亲属即既没有兄弟姐妹也没有父母孩子的乘客来说,两张图概率近乎趋于一致,存活率都在35%左右;
但对于有家人在船上的乘客来说,存活概率相较于其余乘客存活率上升了,差不多到了1:1;
由此我们可以知道,有亲属在船上的乘客出于各自原因,其存活率是大幅上升了。
3.6Fare 票价差异
#绘图
ageFacet=sns.FacetGrid(train_data,hue='Survived',aspect=3)
ageFacet.map(sns.kdeplot,'Fare',shade=True)
ageFacet.set(xlim=(0,150))
ageFacet.add_legend()
plt.show()

-
从上图可以明显看到,票价低的乘客存活率远远小于票价高的乘客;
-
由于从票价的信息中我们可以大致得出乘客的贫富水平,从而推出乘客的阶级差距,故票价的信息还可以与之前的称谓信息联合分析。
#计算不同称谓下票价的均值
df11 = data_title.loc[data_title['Title']=='Mr']['Fare'].mean()
df12 = data_title.loc[data_title['Title']=='Mrs']['Fare'].mean()
df13 = data_title.loc[data_title['Title']=='Miss']['Fare'].mean()
df14 = data_title.loc[data_title['Title']=='Master']['Fare'].mean()
df15 = data_title.loc[data_title['Title']=='Officer']['Fare'].mean()
df16 = data_title.loc[data_title['Title']=='Royalty']['Fare'].mean()
df22 = pd.DataFrame({
'Title':['Mr','Mrs','Miss','Master','Officer','Royalty'],
'Fare':[df11,df12,df13,df14,df15,df16]
})
#绘图
sns.barplot(data = df22, x = 'Title',y = 'Fare',palette=colors);
plt.show()
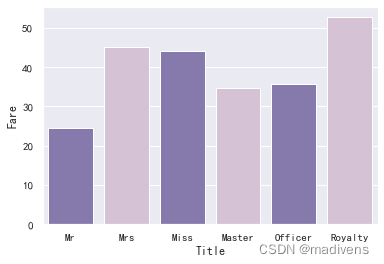
-
可以看到,确实是 “Royalty” 类的乘客所拥有的票价均值最高,也印证了上述所说,社会地位越高的乘客,票价越贵,同时存活率也更高。
故之后称谓可以和票价结合整理出社会地位高低之分,也是重要特征之一。
3.7Cabin 船舱位置差异
#自定义函数
def fd(cabin):
if cabin is np.nan:
return 'U'
else:
return cabin[0]
train_data['Cabin'] = train_data['Cabin'].apply(fd)
train_data['Cabin'].head(10)
0 U
1 C
2 U
3 C
4 U
5 U
6 E
7 U
8 U
9 U
Name: Cabin, dtype: object
colors = ['slategray','lightsteelblue']
sns.countplot(data = train_data, x = 'Cabin', hue = "Survived",palette=colors);
plt.show()

- 由于之前 “Cabin” 缺失值较多,故绘制图后 “unknown” 占了大多数使得图表不太清晰,但我们仍旧可以看到,C、E、D、B船舱的乘客存活人数是多于死亡人数的,但由于确实难以比较,故往下使用存活率进行绘图。
sns.barplot(data = train_data, x = 'Cabin', y = "Survived");
plt.show()

-
从上图可以看到,位于E、D、B船舱的乘客存活率较高,之后F、C、G、A、unknown依次递减。
-
猜测可能是有些船舱位置更靠近逃生地点或者有些船舱位置最先被水淹没,但不论是何种原因,不同的船舱位置确实存活率大不相同,故后期可进行参考。
3.8Embarked 港口差异
3.8.1各港口人数查看
colors = ['slategray','lightsteelblue']
sns.countplot(data = train_data, x = 'Embarked', hue = "Survived",palette=colors);
plt.show()

- 以上我们可以看到在 “S” 港口上传的人数最多,但同时自身对比,其实存活率并没有很高,数据的图不太清晰,故下面仍旧是对存活率进行绘图。
3.8.2各港口生存率
colors = ['slategray','lightsteelblue','cornflowerblue']
sns.barplot(data = train_data, x = 'Embarked', y = "Survived",palette=colors);

- 上图可以清晰看到 “C” 港口上船的乘客存活率更高,“Q” 港次之,"S"港最末。十分有趣的是,“S” 港的乘客数是远远大于其他两个港口的。
故打算查看一下
3.8.3结合称谓查看
#sns.barplot(data = data_title, x = 'Embarked',y = 'Survived',hue = "Title", palette = colors,alpha=0.7);
data = data_title[data_title['Title']=='Royalty']
ax1 = sns.countplot(x="Embarked", hue="Title", data=data)
plt.show()

-
可以看到"C"港的 "Royalty"类的乘客最多;
-
或许是影响的信息之一。总而言之,"C"港乘客的存活率相对更高可以在或许特征分析中有所参考。
4.特征分析归类
4.1主要特征
4.1.1前文所分 adult、senior、child三类
DATA['Age_Cat'] = DATA.Age.apply(cut_age)
4.1.2自定义函数取出姓名和称谓
def get_title(sex,name):
split_name = name.split(",")
surname = split_name[0].strip(" ")
title = split_name[1].split('.')[0].strip(' ')
common_titles = ['Mr', 'Miss', 'Mrs', 'Master']
if title not in common_titles:
title = sex
return title,surname
DATA[['Title', 'Surname']] = DATA[['Sex','Name']].apply(lambda row: get_title(*row), axis=1, result_type= 'expand')
DATA['FamilySize'] = DATA.SibSp + DATA.Parch + 1 #合并亲属人数组成家庭规模这一类
4.1.3给家庭规模大小分类
def familySize_to_cat(size):
if size == 1: return "alone"
if size >= 2 and size <= 4: return 'small'
if size >= 5 and size <= 7: return 'medium'
if size > 7 : return "large"
DATA['FamilySizeCategory'] = DATA.FamilySize.apply(familySize_to_cat)
4.1.4根据家庭分类,计算每一个家庭每个成员的真正票价
DATA['RealFare'] = DATA.Fare / DATA.FamilySize
index_zero = list(DATA['RealFare'][(DATA['RealFare'] == 0) | (DATA['Fare'].isna())].index)
for i in index_zero:
med_fare = DATA['RealFare'][(DATA.Pclass == DATA.iloc[i]['Pclass'])].median()
DATA.loc[DATA.index[i],'RealFare'] = med_fare
DATA['RealFare'] = DATA['RealFare'].apply(lambda row: np.log(row) if row > 0 else 0)
4.1.5对存活的人分组
for i in DATA.index:
# adult male
if DATA.iloc[i]['Sex'] == 'male' and DATA.iloc[i]['Age_Cat'] == 'adult':
DATA.loc[DATA.index[i],'SG'] = "adult_male"
continue
family = DATA[(DATA.Surname == DATA.iloc[i]["Surname"]) & (DATA.Ticket == DATA.iloc[i]["Ticket"])]
kids = family[family.Age_Cat == 'child']
N_kids = len(kids)
# no_children
if N_kids == 0:
DATA.loc[DATA.index[i],'SG'] = "no_chilren"
continue
if N_kids == 1 and len(family) == 1:
DATA.loc[DATA.index[i],'SG'] = "solo_kid"
continue
wc_group = family[family.Title != 'Mr']
survived = wc_group[wc_group.Survived != -1]['Survived'].to_list()
if len(survived) == 0:
# in memoriam 'peacock family', is this cheating?
DATA.loc[DATA.index[i],'SG'] = "group_died"
continue
if np.mean(survived) >= 0.5:
DATA.loc[DATA.index[i],'SG'] = "group_survived"
else:
DATA.loc[DATA.index[i],'SG'] = "group_died"
sns.countplot(data = DATA[DATA.Set == 'Train'], x = 'SG', hue = "Survived")
plt.show()

-
adult_male: 死亡率较高
-
no_chilren: 女孩更容易生存
-
solo_kid: 这些孩子不一定是独自一人的(可能是父母让出逃出机会)
-
group_survived: 大多数妇女+儿童家庭组存活
-
group_died: 大多数妇女+儿童家庭组存活
4.2其余数据特征
ax = sns.heatmap(DATA[DATA.Set == 'Train'][['RealFare','Survived',"SibSp","Parch"]].corr(),annot=True, fmt = ".2f", cmap = "coolwarm");
ax.set_title("Survival correlation to numeric features");

- 各项数据的生存相关性表中,不难看出,RealFare和Survived、SibSp和Parch具有较强的正相关性,RealFare和SibSp、RealFare和Parch具有较强的负相关性,Survived和SibSp、Survived和Parch相关性不显著。
4.3尺度数值特征
mm = MinMaxScaler()
scale_features = ['RealFare',"SibSp","Parch"]
DATA[scale_features] = mm.fit_transform(DATA[scale_features])
5.删除和编码特征
5.1保存特征以供评审
#训练集
_Embarked = DATA[DATA.Set == 'Train'].Embarked
_PClass = DATA[DATA.Set == 'Train'].Pclass
_Cabin = DATA[DATA.Set == 'Train'].Cabin
_Title = DATA[DATA.Set == 'Train'].Title
_Family = DATA[DATA.Set == 'Train'].FamilySizeCategory
_Sex = DATA[DATA.Set == 'Train'].Sex
_Age = DATA[DATA.Set == 'Train'].Age
_Fare = DATA[DATA.Set == 'Train'].RealFare
_SG = DATA[DATA.Set == 'Train'].SG
#测试集
T_Embarked = DATA[DATA.Set == 'Test'].Embarked
T_PClass = DATA[DATA.Set == 'Test'].Pclass
T_Cabin = DATA[DATA.Set == 'Test'].Cabin
T_Title = DATA[DATA.Set == 'Test'].Title
T_Family = DATA[DATA.Set == 'Test'].FamilySizeCategory
T_Sex = DATA[DATA.Set == 'Test'].Sex
T_Age = DATA[DATA.Set == 'Test'].Age
T_Fare = DATA[DATA.Set == 'Test'].RealFare
T_SG = DATA[DATA.Set == 'Test'].SG
5.2删除词条
redundant_features = ['Age', 'Ticket',"FamilySize", "Name",'Surname','Fare']
DATA.drop(redundant_features, inplace = True, axis = 1)
5.3多重哑变量
categorical = ['Cabin','Pclass','FamilySizeCategory','Title','Embarked', "SG", "Age_Cat", "Sex"]
DATA = pd.get_dummies(DATA,columns=categorical)
5.4特征展示
fig, ax = plt.subplots(figsize=(10,10))
g = sns.heatmap(DATA[DATA.Set == 'Train'].corr(),annot=False, cmap = "coolwarm")

- 对Cabin、Pclass、FamilySizeCategory、Title、Embarked等变量进行深入的分类排序后,进行热图的特征分析,得到的图片易得仅少数几个具有明显的相关性,超过半数的表现不显著
5.5拆分数据
TRAIN = DATA[DATA.Set == 'Train']
TEST = DATA[DATA.Set == 'Test']
PassengerIds = TEST.PassengerId.to_list()
TEST = TEST.drop(['PassengerId','Set',"Survived",'index'], axis = 1)
y = TRAIN.Survived
X = TRAIN.drop(['Survived','PassengerId','Set','index'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.3, random_state = 13, stratify=y)
X.head()
| SibSp | Parch | RealFare | Cabin_A | Cabin_B | Cabin_C | Cabin_D | Cabin_E | Cabin_F | Cabin_G | ... | SG_adult_male | SG_group_died | SG_group_survived | SG_no_chilren | SG_solo_kid | Age_Cat_adult | Age_Cat_child | Age_Cat_senior | Sex_female | Sex_male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.125 | 0.0 | 0.192836 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 0.125 | 0.0 | 0.565460 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 2 | 0.000 | 0.0 | 0.320351 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 3 | 0.125 | 0.0 | 0.517451 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 4 | 0.000 | 0.0 | 0.322902 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
5 rows × 38 columns
- 试输出X的开头五个词条
TEST.head()
| SibSp | Parch | RealFare | Cabin_A | Cabin_B | Cabin_C | Cabin_D | Cabin_E | Cabin_F | Cabin_G | ... | SG_adult_male | SG_group_died | SG_group_survived | SG_no_chilren | SG_solo_kid | Age_Cat_adult | Age_Cat_child | Age_Cat_senior | Sex_female | Sex_male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 891 | 0.000 | 0.000000 | 0.318368 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 892 | 0.125 | 0.000000 | 0.187115 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 893 | 0.000 | 0.000000 | 0.353089 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 894 | 0.000 | 0.000000 | 0.334857 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 895 | 0.125 | 0.111111 | 0.212744 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
5 rows × 38 columns
- 试输出TEST的开头五个词条
6.具体的八种模型实现
6.1 Random Forest随机森林
#建立一个随机森林模型rf_model
rf_model = RandomForestClassifier(max_depth=6, n_estimators= 50, max_features='auto')
#sklearn数据预处理、数据拟合
rf_model.fit(X_train, y_train)
rf_train_score = rf_model.score(X_train, y_train)#训练集
rf_accuracy = rf_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(rf_train_score * 100))
print("Test: {:.2f} %".format(rf_accuracy*100))
print('Overfit: {:.2f} %'.format((rf_train_score-rf_accuracy)*100))
Train: 87.80 %
Test: 85.45 %
Overfit: 2.35 %
#Random Forest模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"RF":features})#创建DataFrame
importances.sort_values("RF", ascending = False, inplace=True)#数据排序
RF_best_features = list(importances[importances.RF > 0.03].index)
importances.plot.bar()#作图
print("RF_best_features:",RF_best_features, len(RF_best_features))#对应下标题
plt.show()
RF_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.2 Support Vector Machines支持向量机算法
#建立一个Support Vector Machine模型SVM_model
SVM_model = SVC(C = 100, gamma= 0.001, kernel='rbf')
#sklearn数据预处理、数据拟合
SVM_model.fit(X_train, y_train)
svm_train_score = SVM_model.score(X_train, y_train)#训练集
SVM_accuracy = SVM_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(svm_train_score*100))
print("Test: {:.2f} %".format(SVM_accuracy*100))
print('Overfit: {:.2f} %'.format((svm_train_score-SVM_accuracy)*100))
Train: 84.59 %
Test: 86.57 %
Overfit: -1.98 %
#SVM模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"SVM":features})#创建DataFrame
importances.sort_values("SVM", ascending = False, inplace=True)#数据排序
importances
SVM_best_features = list(importances[importances.SVM > 0.03].index)
importances.plot.bar()#作图
print("SVM_best_features:",SVM_best_features, len(SVM_best_features))#对应下标题
SVM_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.3 Logistic回归
#建立一个Logistics回归模型LR_model
LR_model = LogisticRegression(solver='liblinear', C=2.78, penalty='l2')
#sklearn数据预处理、数据拟合
LR_model.fit(X_train, y_train)
LR_train_score = LR_model.score(X_train, y_train)#训练集
LR_accuracy = LR_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(LR_train_score*100))
print("Test: {:.2f} %".format(LR_accuracy*100))
print('Overfit: {:.2f} %'.format((LR_train_score-LR_accuracy)*100))
Train: 85.23 %
Test: 83.58 %
Overfit: 1.65 %
#Logistics回归模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"LR":features})#创建DataFrame
importances.sort_values("LR", ascending = False, inplace=True)#数据排序
importances
LR_best_features = list(importances[importances.LR > 0.03].index)
importances.plot.bar()#作图
print("LR_best_features:",LR_best_features, len(LR_best_features))#对应下标题
LR_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.4 K-NearestNeighbor邻近算法
#建立一个K-NearestNeighbor模型KNN_model
KNN_model = KNeighborsClassifier(n_neighbors=11,metric='euclidean',weights='uniform')
#sklearn数据预处理、数据拟合
KNN_model.fit(X_train, y_train)
KNN_train_score = KNN_model.score(X_train, y_train)#训练集
KNN_accuracy = KNN_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(KNN_train_score*100))
print("Test: {:.2f} %".format(KNN_accuracy*100))
print('Overfit: {:.2f} %'.format((KNN_train_score-KNN_accuracy)*100))
Train: 86.36 %
Test: 84.33 %
Overfit: 2.03 %
#KNN模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"KNN":features})#创建DataFrame
importances.sort_values("KNN", ascending = False, inplace=True)#数据排序
importances
KNN_best_features = list(importances[importances.KNN > 0.03].index)
importances.plot.bar()#作图
print("KNN_best_features:",KNN_best_features, len(KNN_best_features))#对应下标题
KNN_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.5 ADA Boost迭代最终分类器
#建立一个ADA Boost模型ADA_model
ADA_model = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=5, min_samples_leaf=10), n_estimators=200, learning_rate = 0.001)
#sklearn数据预处理、数据拟合
ADA_model.fit(X_train,y_train)
ADA_train_score = ADA_model.score(X_train, y_train)#训练集
ADA_accuracy = ADA_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(ADA_train_score*100))
print("Test: {:.2f} %".format(ADA_accuracy*100))
print('Overfit: {:.2f} %'.format((ADA_train_score - ADA_accuracy)*100))
Train: 87.00 %
Test: 85.82 %
Overfit: 1.18 %
#ADA模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"ADA":features})#创建DataFrame
importances.sort_values("ADA", ascending = False, inplace=True)#数据排序
importances
ADA_best_features = list(importances[importances.ADA > 0.03].index)
importances.plot.bar()#作图
print("ADA_best_features:",ADA_best_features, len(ADA_best_features))#对应下标题
ADA_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.6 ExtraTrees极端随机树
#建立一个ExtraTrees模型ETC_model
ETC_model = ExtraTreesClassifier(max_features=4, min_samples_leaf=10, n_estimators=300, min_samples_split=3)
#sklearn数据预处理、数据拟合
ETC_model.fit(X_train, y_train)
ETC_train_score = ETC_model.score(X_train, y_train)#训练集
ETC_accuracy = ETC_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(ETC_train_score*100))
print("Test: {:.2f} %".format(ETC_accuracy*100))
print('Overfit: {:.2f} %'.format((ETC_train_score-ETC_accuracy)*100))
Train: 84.27 %
Test: 85.82 %
Overfit: -1.55 %
#ETC模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"ETC":features})#创建DataFrame
importances.sort_values("ETC", ascending = False, inplace=True)#数据排序
importances
ETC_best_features = list(importances[importances.ETC > 0.03].index)
importances.plot.bar()#作图
print("ETC_best_features:",ETC_best_features, len(ETC_best_features))#对应下标题
ETC_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.7 Gradient Boost 梯度迭代
#建立一个GradientBoost模型GBC_model
GBC_model = GradientBoostingClassifier(max_depth=4, max_features=0.3, min_samples_leaf=100, n_estimators=300)
#sklearn数据预处理、数据拟合
GBC_model.fit(X_train, y_train)
GBC_train_score = GBC_model.score(X_train, y_train)#训练集
GBC_accuracy = GBC_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(GBC_train_score*100))
print("Test: {:.2f} %".format(GBC_accuracy*100))
print('Overfit: {:.2f} %'.format((GBC_train_score-GBC_accuracy)*100))
Train: 84.27 %
Test: 81.72 %
Overfit: 2.55 %
#GBC模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"GBC":features})#创建DataFrame
importances.sort_values("GBC", ascending = False, inplace=True)#数据排序
GBC_best_features = list(importances[importances.GBC > 0.03].index)
importances.plot.bar()#作图
print("GBC_best_features:",GBC_best_features, len(GBC_best_features))#对应下标题
GBC_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.8 Stochastic Gradient Descent随机梯度下降
#建立一个Stochastic Gradient Descent模型SGD_model
SGD_model = SGDClassifier(alpha=0.01, penalty='elasticnet', loss='hinge')
#sklearn数据预处理、数据拟合
SGD_model.fit(X_train, y_train)
SGD_train_score = SGD_model.score(X_train, y_train)#训练集
SGD_accuracy = SGD_model.score(X_test, y_test)#准确性
#输出结果
print("Train: {:.2f} %".format(SGD_train_score*100))
print("Test: {:.2f} %".format(SGD_accuracy*100))
print('Overfit: {:.2f} %'.format((SGD_train_score-SGD_accuracy)*100))
Train: 84.59 %
Test: 86.57 %
Overfit: -1.98 %
#SGD模型特征重要性可视化
features = {}
for feature, importance in zip(X_train.columns, rf_model.feature_importances_):
features[feature] = importance
importances = pd.DataFrame({"SGD":features})#创建DataFrame
importances.sort_values("SGD", ascending = False, inplace=True)#数据排序
SGD_best_features = list(importances[importances.SGD > 0.03].index)
importances.plot.bar()#作图
print("SGD_best_features:",SGD_best_features, len(SGD_best_features))#对应下标题
SGD_best_features: ['Sex_female', 'Title_Mr', 'Sex_male', 'RealFare', 'SG_group_survived', 'SG_no_chilren', 'SG_group_died', 'Pclass_3', 'SG_adult_male', 'Cabin_U'] 10

- 由图中特征重要性柱状图易得:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、
'Cabin_U’具有较强重要性,其余特征均无明显重要性表现。
6.9 输出各个模型种,特征影响最大的类
L = min(len(RF_best_features), len(ADA_best_features), len(KNN_best_features), len(LR_best_features), len(SVM_best_features),
len(ETC_best_features), len(GBC_best_features), len(SGD_best_features))
TF = pd.DataFrame({"ADA":ADA_best_features[:L], "KNN": KNN_best_features[:L], "LR": LR_best_features[:L],
"SVM":SVM_best_features[:L], "RF":RF_best_features[:L],
"ETC":ETC_best_features[:L], "GBC":GBC_best_features[:L], "SGD":SGD_best_features[:L]} )
TF
| ADA | KNN | LR | SVM | RF | ETC | GBC | SGD | |
|---|---|---|---|---|---|---|---|---|
| 0 | Sex_female | Sex_female | Sex_female | Sex_female | Sex_female | Sex_female | Sex_female | Sex_female |
| 1 | Title_Mr | Title_Mr | Title_Mr | Title_Mr | Title_Mr | Title_Mr | Title_Mr | Title_Mr |
| 2 | Sex_male | Sex_male | Sex_male | Sex_male | Sex_male | Sex_male | Sex_male | Sex_male |
| 3 | RealFare | RealFare | RealFare | RealFare | RealFare | RealFare | RealFare | RealFare |
| 4 | SG_group_survived | SG_group_survived | SG_group_survived | SG_group_survived | SG_group_survived | SG_group_survived | SG_group_survived | SG_group_survived |
| 5 | SG_no_chilren | SG_no_chilren | SG_no_chilren | SG_no_chilren | SG_no_chilren | SG_no_chilren | SG_no_chilren | SG_no_chilren |
| 6 | SG_group_died | SG_group_died | SG_group_died | SG_group_died | SG_group_died | SG_group_died | SG_group_died | SG_group_died |
| 7 | Pclass_3 | Pclass_3 | Pclass_3 | Pclass_3 | Pclass_3 | Pclass_3 | Pclass_3 | Pclass_3 |
| 8 | SG_adult_male | SG_adult_male | SG_adult_male | SG_adult_male | SG_adult_male | SG_adult_male | SG_adult_male | SG_adult_male |
| 9 | Cabin_U | Cabin_U | Cabin_U | Cabin_U | Cabin_U | Cabin_U | Cabin_U | Cabin_U |
- 综上:
‘SG_adult_male’、‘Sex_female’、‘Title_Mr’、‘RealFare’、‘Sex_male’、‘SG_no_chilren’、‘SG_group_died’、‘SG_group_survived’、‘Pclass_3’、‘Pclass_1’、'Cabin_U’具有较强重要性
7.汇总各个算法的准确性
print("Accuracy Scores:")
print("==========================================================")
print("RandomForest: {:.3f}".format(rf_accuracy))
print("SVM classifier: {:.3f}".format(SVM_accuracy))
print("LR classifier: {:.3f}".format(LR_accuracy))
print("KNN classifier: {:.3f}".format(KNN_accuracy))
print("ADA Boost classifier: {:.3f}".format(ADA_accuracy))
print("Extra Tree classifier: {:.3f}".format(ETC_accuracy))
print("Gradient Boosting classifier: {:.3f}".format(GBC_accuracy))
print("Stochastic Gradient descent: {:.3f}".format(SGD_accuracy))
print("==========================================================")
Accuracy Scores:
==========================================================
RandomForest: 0.854
SVM classifier: 0.866
LR classifier: 0.836
KNN classifier: 0.843
ADA Boost classifier: 0.858
Extra Tree classifier: 0.858
Gradient Boosting classifier: 0.817
Stochastic Gradient descent: 0.866
==========================================================
7.1运用模型预测TEST集合
rf_predictions = rf_model.predict(TEST)
svm_predictions = SVM_model.predict(TEST)
lr_predictions = LR_model.predict(TEST)
knn_predictions = KNN_model.predict(TEST)
ada_predictions = ADA_model.predict(TEST)
etc_predictions = ETC_model.predict(TEST)
gbc_predictions = GBC_model.predict(TEST)
sgd_predictions = SGD_model.predict(TEST)
7.2等比重多模型计数预测
def vote(votes):
weight_dict = {'RF':1,'LR':1,"SVM":1, "KNN":1, "ADA":1, "ETC":1, "GBC": 1, "SGD":1}#比重都是1
weights = np.array(list(weight_dict.values()))
sw = weights.sum()
v = [v * weights[i] for i,v in enumerate(votes)]
return sum(v)/ sw
#创建DataFrame储存模型结果和分类标题
ALL_PREDICTIONS = pd.DataFrame({'PassengerId': PassengerIds,
'RF':rf_predictions,'LR': lr_predictions,
"SVM":svm_predictions, "KNN":knn_predictions, "ADA":ada_predictions, "ETC":etc_predictions, "GBC":gbc_predictions,
"SGD":sgd_predictions,
'Sex':T_Sex,'Age': T_Age,'Fare':T_Fare, "FamilySize":T_Family, "Title": T_Title, "PClass": T_PClass, "SG":T_SG})
clfs = ['RF','LR',"SVM", "KNN", "ADA", "ETC", "GBC", "SGD"]
ALL_PREDICTIONS['Vote'] = ALL_PREDICTIONS[clfs].apply(lambda row: vote(row), axis = 1)
ALL_PREDICTIONS['Predict'] = ALL_PREDICTIONS.Vote.apply(lambda row: int(np.rint(row)))
vc_predictions = ALL_PREDICTIONS.Predict
ALL_PREDICTIONS.head(20)
| PassengerId | RF | LR | SVM | KNN | ADA | ETC | GBC | SGD | Sex | Age | Fare | FamilySize | Title | PClass | SG | Vote | Predict | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 891 | 892 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 34.5 | 0.318368 | alone | Mr | 3 | adult_male | 0.000 | 0 |
| 892 | 893 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | female | 47.0 | 0.187115 | small | Mrs | 3 | no_chilren | 0.750 | 1 |
| 893 | 894 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 62.0 | 0.353089 | alone | Mr | 2 | no_chilren | 0.000 | 0 |
| 894 | 895 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 27.0 | 0.334857 | alone | Mr | 3 | adult_male | 0.000 | 0 |
| 895 | 896 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 22.0 | 0.212744 | small | Mrs | 3 | group_survived | 1.000 | 1 |
| 896 | 897 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 14.0 | 0.345114 | alone | Mr | 3 | solo_kid | 0.000 | 0 |
| 897 | 898 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 30.0 | 0.314149 | alone | Miss | 3 | no_chilren | 1.000 | 1 |
| 898 | 899 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 26.0 | 0.352738 | small | Mr | 2 | adult_male | 0.000 | 0 |
| 899 | 900 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 18.0 | 0.305369 | alone | Mrs | 3 | no_chilren | 1.000 | 1 |
| 900 | 901 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 21.0 | 0.322902 | small | Mr | 3 | adult_male | 0.000 | 0 |
| 901 | 902 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 26.0 | 0.319749 | alone | Mr | 3 | adult_male | 0.000 | 0 |
| 902 | 903 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 46.0 | 0.514038 | alone | Mr | 1 | adult_male | 0.000 | 0 |
| 903 | 904 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 23.0 | 0.588822 | small | Mrs | 1 | no_chilren | 1.000 | 1 |
| 904 | 905 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 63.0 | 0.401037 | small | Mr | 2 | no_chilren | 0.000 | 0 |
| 905 | 906 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 47.0 | 0.540529 | small | Mrs | 1 | no_chilren | 1.000 | 1 |
| 906 | 907 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | female | 24.0 | 0.411485 | small | Mrs | 2 | no_chilren | 1.000 | 1 |
| 907 | 908 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 35.0 | 0.392675 | alone | Mr | 2 | adult_male | 0.000 | 0 |
| 908 | 909 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | male | 21.0 | 0.305275 | alone | Mr | 3 | adult_male | 0.000 | 0 |
| 909 | 910 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | female | 27.0 | 0.207349 | small | Miss | 3 | no_chilren | 0.500 | 0 |
| 910 | 911 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | female | 45.0 | 0.305275 | alone | Mrs | 3 | no_chilren | 0.875 | 1 |
- 输出前20位数据,8个模型的投票结果预测符合源数据
7.3检查模型训练结果
#训练预测
rf_train = rf_model.predict(X)
svm_train = SVM_model.predict(X)
lr_train = LR_model.predict(X)
knn_train = KNN_model.predict(X)
ada_train = ADA_model.predict(X)
etc_train = ETC_model.predict(X)
gbc_train = GBC_model.predict(X)
sgd_train = SGD_model.predict(X)
#训练结果投票
TRAIN_PREDICTIONS = pd.DataFrame({'Survived':train_data.Survived,'Sex':_Sex,'Age': _Age,'Fare':_Fare,
"FamilySize":_Family, "Title": _Title,
"PClass": _PClass,
"SG": _SG,
'RF':rf_train,'LR': lr_train,
"SVM":svm_train, "KNN":knn_train, "ADA":ada_train,
"ETC":etc_train, "GBC":gbc_train, "SGD":sgd_train})
TRAIN_PREDICTIONS['Vote'] = TRAIN_PREDICTIONS[clfs].apply(lambda row: vote(row), axis = 1)
TRAIN_PREDICTIONS['VC'] = TRAIN_PREDICTIONS.Vote.apply(lambda row: int(np.rint(row+0.01)))
#错误反馈
wrong = TRAIN_PREDICTIONS[TRAIN_PREDICTIONS.Survived != TRAIN_PREDICTIONS.VC]
print(len(wrong))
wrong[(wrong.Vote == 0.4)].head(20)
127
| Survived | Sex | Age | Fare | FamilySize | Title | PClass | SG | RF | LR | SVM | KNN | ADA | ETC | GBC | SGD | Vote | VC |
|---|
- 输出vote=0.4的结果VC=1
#各个模型的错误累计计算
scores = {}
for c in clfs:
scores[c] = 0
for i in wrong.index:
s = TRAIN_PREDICTIONS.loc[TRAIN_PREDICTIONS.index[i],'Survived']
#print(i, s)
for c in clfs:
if TRAIN_PREDICTIONS.loc[TRAIN_PREDICTIONS.index[i],c] == s:
scores[c] += 1
scores
{'RF': 17,
'LR': 15,
'SVM': 6,
'KNN': 38,
'ADA': 38,
'ETC': 5,
'GBC': 34,
'SGD': 6}
- 不同模型的错误累计有:
‘RF’: 16, ‘LR’: 14, ‘SVM’: 8, ‘KNN’: 38, ‘ADA’: 37, ‘ETC’: 6, ‘GBC’: 35, ‘SGD’: 8
7.4训练结果/作图
train_scores = {}
for clf in [*clfs, 'VC']:
train_scores[clf] = [len(TRAIN_PREDICTIONS[TRAIN_PREDICTIONS.Survived == TRAIN_PREDICTIONS[clf]]) / TRAIN_PREDICTIONS.shape[0]]
TRAIN_SCORES = pd.DataFrame(train_scores)
TRAIN_SCORES
| RF | LR | SVM | KNN | ADA | ETC | GBC | SGD | VC | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.870932 | 0.847363 | 0.851852 | 0.857464 | 0.866442 | 0.847363 | 0.835017 | 0.851852 | 0.857464 |
TRAIN_SCORES.plot.bar();

- 输出八个模型以及均值的投票结果,九者机器学习匹配结果
output = pd.DataFrame({'PassengerId': PassengerIds, 'Survived': vc_predictions})
output.head(20)
| PassengerId | Survived | |
|---|---|---|
| 891 | 892 | 0 |
| 892 | 893 | 1 |
| 893 | 894 | 0 |
| 894 | 895 | 0 |
| 895 | 896 | 1 |
| 896 | 897 | 0 |
| 897 | 898 | 1 |
| 898 | 899 | 0 |
| 899 | 900 | 1 |
| 900 | 901 | 0 |
| 901 | 902 | 0 |
| 902 | 903 | 0 |
| 903 | 904 | 1 |
| 904 | 905 | 0 |
| 905 | 906 | 1 |
| 906 | 907 | 1 |
| 907 | 908 | 0 |
| 908 | 909 | 0 |
| 909 | 910 | 0 |
| 910 | 911 | 1 |
- 试输出前20位存活情况的匹配结果,符合预期
8.输出结果
#output
output.to_csv('submission.csv', index=False)
print("Submission was successfully saved!")
Submission was successfully saved!
- 成功输出预测test.csv文件的结果到submission文件中
end_time = time.time()
print("Notebook run time: {:.1f} seconds. Finished at {}".format(end_time - start_time, datetime.now()) )
Notebook run time: 43.3 seconds. Finished at 2021-11-10 22:54:56.691928
- 计算所用时间和结束具体时间
9.kaggle网站截图(score=0.80143)

10.参考文献
- https://blog.csdn.net/wydyttxs/article/details/76695205
- https://www.kaggle.com/lovroselic/titanic-ls
- https://blog.csdn.net/qq_17793969/article/details/80714903?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163655666716780255287999%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=163655666716780255287999&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-80714903.first_rank_v2_pc_rank_v29&utm_term=Kaggle+Titanic%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%92%8C%E9%A2%84%E6%B5%8B&spm=1018.2226.3001.4187
- https://www.nyckel.com/blog/titanic-vs-transformers/
- https://zhuanlan.zhihu.com/p/50194676
- https://www.kaggle.com/c/titanic/discussion/285454















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









