







论文:ArcFace: Additive Angular Margin Loss for Deep Face
代码:https://github.com/deepinsight/insightface
摘要:
利用深度卷积神经网络(DCNNs)进行大规模人脸识别的特征学习的主要挑战之一是设计适当的损失函数来增强鉴别性权力。 Centre loss 惩罚深度特征与其对应的类中心在欧几里德空间之间的距离,以实现类内紧凑。 SphereFace 假设 最后一个完全连接层中的线性变换矩阵可以用作角空间中类中心的表示,并惩罚深度特征和深度特征之间的角度,他们相应的权重以乘法的方式。在本文中,我们提出了一个 Additive Angular Margin Loss (ArcFace),以获得高鉴别特征的人脸识别。 提出的 ArcFace 具有清晰的几何解释。 我们提出了最广泛的实验评估,所有最近最先进的人脸识别方法超过10人脸识别基准包括一个新的大规模图像数据库,具有万亿级对和大规模视频数据集。我们表明,ArcFace 始终 state-of-the-art ,可以很容易地实现与可忽略的计算开销。 我们发布所有完善的培训数据,培训代码,pre-trained 模型和训练日志,这将有助于复制本文的结果。
介绍:
培养用于人脸识别的DCNN的研究主要有两条主线。 那些训练一个多类分类器,它可以在训练集中分离不同的标识,例如使用softmax分类器[33,24,6],以及那些直接学习embedding 的分类器,例如 triplet loss[29]。
Softmax loss 和 triplet loss 都有一些缺点。
对于Softmax loss:
(1)线性变换矩阵的大小随恒等式数n的线性增加;
(2)学习的特征对于闭集分类是可分离的问题,但对开放集人脸识别问题不够鉴别。(也就是没有在训练集上学习足够的一般性,类内收敛,类间分离)
对于triplet loss:
(1)人脸三重态的数量存在组合爆炸,特别是对于大数据集导致迭代步骤的数量显著增加;
(2)困难样本挖掘是有效模型训练的一个相当困难的问题。
为了提高Softmax损失的判别能力,提出了几种变体[38,9,46,18,37,35,7,34,27]。 [38]开创了 center loss ,即两地之间的欧几里得距离在每个特征向量及其类中心中,获得类内紧性,而类间色散由Softmax损失的联合惩罚来保证。 然而,由于中心损失会多了很多类中心的定义,导致 center loss 非常消耗GPU显存

通过观察,在Softmax损失上训练的分类DCNN的最后一个完全连接层的权重与每个类的中心具有概念上的相似性,在[18,19]提出了一种乘法角边差惩罚,以同时强制额外的类内紧性和类间差异,从而使训练后的模型具有更好的鉴别能力。也就是全连接×的权重相当于一个中心向量,最终的分类结果为特征向量与中心向量的夹角的余弦
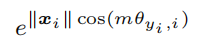
虽 SphereFace [18]引入了角边距的重要思想,但它们的损失函数需要一系列的近似才能计算,从而导致了角边距的不稳定训练网络。 为了稳定训练,他们提出了一个包含标准Softmax损失的混合损失函数。 经验上,Softmax损失主导了训练过程,因为基于整数的乘法角裕度使得目标逻辑曲线非常陡峭,从而阻碍了收敛。 CosFace [37,35]直接向目标逻辑添加余弦裕度惩罚,与SphereFace相比,获得了更好的性能,实现更容易,并从Softmax损失中解脱了联合监督的需要。

在本文中,我们提出了ArcFace,以进一步提高人脸识别模型的鉴别能力,并稳定训练过程。 如图所示图2,DCNN特征与最后一个完全连接层之间的点积等于特征和权重归一化后的余弦距离。我们利用 arc-cosine 计算当前特征与目标权重之间的夹角。 然后,我们在目标角上加入一个加性角裕度,得到目标由余弦函数再次返回。
ArcFace 优点:
- Engaging: 在归一化超球面中, ArcFace 通过角与弧的精确对应直接优化真实 margin 。 我们直观地说明了发生了什么在512-D空间中,通过分析特征和权重之间的角度统计。
- Effective: ArcFace 在十个人脸识别基准上达到了state-of-the-art 。
- Easy: ArcFace 基于计算图的深度学习框架非常容易实现,例如: MxNet[8],Pytorch[25]和Tensorflow[4]。 此外,与[18,19]中的工作相反,ArcFace不需要与其他损失函数相结合,就能具有稳定的性能,并且易于使用你收敛于任何训练数据集。
- Efficient: ArcFace 在训练过程中只增加了可忽略的计算复杂度。 目前的GPU可以很容易地支持数百万个身份进行培训和模型并行策略可以很容易地支持更多的身份。
ArcFace 详解:

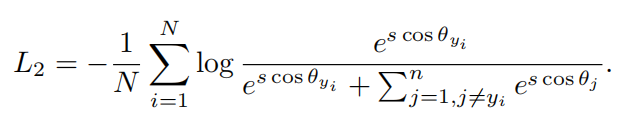
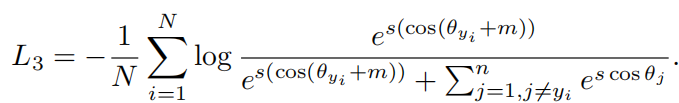

Input: Feature Scale s, Margin Parameter m in Eq. 3, Class Number n, Ground-Truth ID gt.
1. x = mx.symbol.L2Normalization (x, mode = ’instance’)
2. W = mx.symbol.L2Normalization (W, mode = ’instance’)
3. fc7 = mx.sym.FullyConnected (data = x, weight = W, no bias = True, num hidden = n)
4. original target logit = mx.sym.pick (fc7, gt, axis = 1)
5. theta = mx.sym.arccos (original target logit)
6. marginal target logit = mx.sym.cos (theta + m)
7. one hot = mx.sym.one hot (gt, depth = n, on value = 1.0, off value = 0.0)
8. fc7 = fc7 + mx.sym.broadcast mul (one hot, mx.sym.expand dims (marginal target logit - original target logit, 1))
9. fc7 = fc7 * s
Output: Class-wise affinity score f c7
ArcFace VS SphereFace and CosFace
SphereFace [18, 19], ArcFace 和 CosFace [37, 35],都是通过不同的方式添加了margin,总结起来就是:(cos(m1θ + m2) − m3)

看图说话:
(a)图为W和X的夹角在训练ArcFace的开始,中期,结束的分布图,可以看出,
刚开始分布在90°,慢慢移到35°,得到
的范围大致在【20°,100°】
(b)图为不同loss的逻辑曲线,就是曲线,区间在【20°,100°】
实验时间
数据集一览表:

细节:
- 我们遵循最近的论文[18,37]通过使用五个关键点来生成标准化的人脸裁剪(112×112)。
- 对于embedding network,我们采用了广泛使用的CNN架构,Res Net50和Res Net100[12,11]。
- 在最后一个卷积层之后,我们探索BN[14]-Dropout[31]-FC-BN结构,得到最终的512-D embedding 特征。
- 在这篇论文中,我们([训练数据集、网络结构、损失]),以促进对实验设置的理解。
- 我们遵循[37]将特征尺度s设置为64,并选择弧面的角边缘m为0.5。
- 本文中的所有实验都是由MXNet[8]实现的。
- 我们将批次大小设置为512,并在4个NVIDIA特斯拉P40(24GB)GPU上训练。
- 在CASIA上,学习率从0.1开始,在20K,28K迭代时除以10。 训练过程以32K迭代完成。
- 在MS1MV2上,我们d在100K,160K迭代中学习速率,并在180K迭代中完成。
- 我们设定动量为0.9,重量衰减为5e−4。
- 在测试过程中,我们只保留特征嵌入网络,而完全连接的层(160MB ResNet50和ResNet100的250MB),并为每个正常面部提取512-D特征(ResNet50的8.9ms/face 和ResNet100的15.4ms/face。
Ablation Study on Loss

- 在表2中,我们首先用ResNet50探索CASIA数据集上ArcFace的角边距设置。 在我们的实验中观察到的最佳裕度为0.5。
- SphereFace 和 CosFace的margin,我们发现在分别设置为1.35和0.35时具有最佳的性能。
- 我们对Sphere Face和Cos Face的实现都可以带来出色的性能,而任何收敛困难。
- 所提出的ArcFace在所有三个测试集上都达到了最高的验证精度。
- 此外,我们还对组合边缘框架(一些最佳性能)进行了广泛的实验观察到CM1(1,0.3,0.2)和CM2(0.9,0.4,0.15)由目标Logit曲线引导,但是不如Arcface
除了与基于边缘的方法进行比较外,我们还对ArcFace和其他损失进行了进一步的比较
作为基线,我们选择了Softmax损失,我们观察到CFP-FP和AgeDB-30 在 weight and feature normalisation.后的性能下降。 通过将Softmax与类内损失相结合,性能得到了提高,然而,将Softmax与类间损失相结合只会稍微提高精度。Triplet-loss 优于Norm-Softmax损失这一事实表明,裕度在提高性能方面的重要性。然而,在Triplet 样本中使用裕度惩罚比在X和W之间插入裕度更有效,就像在ArcFace中一样。最后,我们将内部损失、互损失和 Triplet-loss 合并到弧面中,但没有观察到任何改进,这导致我们相信弧面已经在加强类内密实度,类间差异和分类裕度。
为了更好地理解ArcFace的优越性,我们给出了表3中不同损失下训练数据(CASIA)和测试数据(LFW)的详细角度统计。

图咋看?
站着看:W-EC表示weight 与 emb中心之间的夹角平均值,W-Inter表示weight之间的夹角的平均值,“Intra1”和“Intra2”分别是x和 embedding 特征中心在CASIA和LFW上的角度平均值。“Inter1”和“Inter2”分别指在CASIA和LFW上 embedding 特征中心之间的最小角度的平均值
躺着看:NS:Norm-Softmax
结论:

- Norm-Softmax 与 ArcFace W-Inter相近,但W-EC差别较大,因为Norm-Softmax没有很好的类内聚集能力
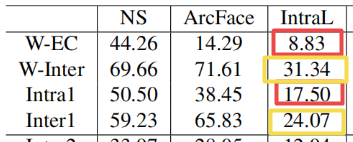
- Intra loss 可以有效地压缩类内变化,但也带来较小的类间角。
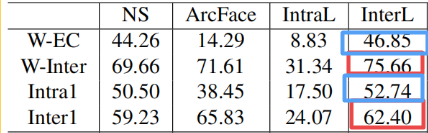
- Inter-Loss ,类间差异会略有增加,但也会增加类内角度。
- ArcFace 已经有很好的类内紧度和类间差。
- 与 ArcFace 相比,Triplet-Loss具有相似的类内紧度,但类间差较差。
-

LFW上生成的随机正对(红)/随机负对(蓝)([CASIA, ResNet50, loss*]) - 此外,在测试集上,与Triplet-Loss相比,Acface有一个更明显的边缘
Evaluation Results
LFW、YTF、CALFW和CPLFW。

LFW[13]和YTF[40]数据集是图像和视频上最广泛使用的无约束人脸验证基准。 在这篇论文中,我们遵循了不稳定反恐执行局与标记的外部数据协议,以报告性能。 正如表4所报告的,在MS1MV2上训练的ArcFace与ResNet100击败了(例如。 shpereFace[18]和CosFace[37])在LFW和YTF上均有显著的裕度,这表明加性角裕度惩罚能显著深度学习特征的鉴别能力,证明了ArcFace的有效性

除了在LFW和YTF数据集上,我们还报告了ArcFace在最近引入的数据集上的性能(例如。 CPLFW[48]和CALFW[49])具有较高的姿态和年龄变化来自LFW的数量。 在所有开放源人脸识别模型中,ArcFace模型被评估为排名靠前的人脸识别模型
下面是不同测试集下的结果:


在megeFace上结果

数据集有690K不同个体的1M图像,以及530人的100K照片的测试标准FaceScrub 。 在MegaFace上 如果包含超过0.5M的图像,则训练集被定义为大。 为了公平竞争,我们分别在CAISA和MS1MV2上对ArcFace进行了小协议和大协议的训练。 在表6中,在CASIA上训练的弧面实现了最佳的单模型识别和验证性能
当我们观察到识别和验证之间存在明显的性能差距时,我们对整个MegaFace数据集进行了彻底的手动检查,并发现了许多标签错误的人脸图像.因此,我们手动细化了整个MegaFace数据集,并在MegaFace上报告了ArcFace的正确性能。 ArcFace仍然明显优于CosFace,并达到了这一效果在验证和识别方面的最佳性能。

在大协议下,Arc Face比Face Net[29]有明显的优势,与Cos Face[37]相比,在识别和验证方面取得了较好的效果。 因为科斯·费森对于一个私人培训数据,我们在我们的MS1MV2数据集上用ResNet100重新培训CosFace。 在公平比较下,ArcFace显示出优于CosFace的优势,在识别和验证场景,如图8所示。(CMC 曲线指的是,不同的rank 在top-rank中包含识别身份的正确率曲线)
Results on IJB-B and IJB-C


IJB-C dataset
Results on Trillion-Pairs.

Results on iQIYI-VID

512-d超球空间是否足够大,足以保持大规模身份? 理论上,是的。
我们假设身份中心WJ遵循一个现实的球形均匀分布,期望最近的邻居分离
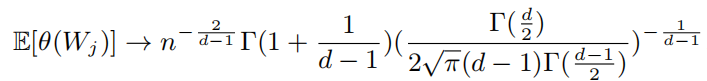
其中:
- d是空间维度
- n是身份数量
我们给出了128-d、256-d和512-d空间中的E[θ(Wj)],类号从10K到100M。 高维空间太大,当类数增加时,E[θ(Wj)]缓慢减小以指数方式减少。如图:
















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









