







最全干货!分享一个CNN神经网络猫狗分类代码(文末附模型)
关键字:CNN,Tensorflow,Python,cats-vs-dogs
前言
经过几天的学习和打磨程序,笔者逐渐熟悉了如何利用Tensorflow搭建机器学习模型,如何预处理数据集,以及在训练过程中,怎样实现随机地使神经元失活和动态调整学习率等。本文目的在于分享完整的代码及模型,方便和我一样的小白们对机器学习算法有一个深入的了解。
设备参数:
win10
CPU = i56300HQ(四核)
RAM = 8G
GPU = GTX960
CUDA version = 11.2
python version = 3.7.6
Tensorflow version = 2.4.1
主要参考学习了如下资料:
1.一本书《简单粗暴 Tensorflow2》: https://tf.wiki/zh_hans/basic/models.html.
2.微信公众号:“小白学视觉”,后台回复“Python视觉实战项目31讲”,即可获得相关PDF网盘链接(尊重原创,这里不补连接了)
数据集获取
https://www.floydhub.com/jobs.
搜索cats-vs-dogs即可
笔者用的是经过进一步处理的,电脑内存太小,所以事先将所有图片resize()为(100,100,3)的大小,这样做之后才能够训练所有数据。
CNN Model
不多bb直接上干货 :
- import packages
import tensorflow as tf
from tensorflow import keras
import numpy as np
import os
import random
- design model
#============================ model ============================#
#=================================================================#
def CNN():
model = keras.Sequential()
#block1
model.add(keras.layers.Conv2D(32,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu,input_shape = (input_rows,input_cols,3)))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(32,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size = [2,2]))
model.add(keras.layers.Dropout(0.2))
#block2
model.add(keras.layers.Conv2D(64,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(64,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D(pool_size = [2,2]))
model.add(keras.layers.Dropout(0.2))
#block3
model.add(keras.layers.Conv2D(128,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(128,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D())
model.add(keras.layers.Dropout(0.2))
#block4
model.add(keras.layers.Conv2D(256,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Conv2D(256,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.MaxPool2D())
model.add(keras.layers.Dropout(0.5))
#block5
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(64,activation = tf.nn.elu,kernel_initializer='he_normal'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.5))
#block6
model.add(keras.layers.Dense(32,activation = tf.nn.elu,kernel_initializer='he_normal'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.5))
#block7
model.add(keras.layers.Dense(num_class,activation = tf.nn.softmax,kernel_initializer='he_normal'))
print(model.summary(),'\n')
return model
模型参考微信公众号获得的PDF中人脸表情识别的模型(其实是直接搬过来的,哈哈哈),model通过如下方式来搭建:
model = keras.Sequential()
后续只需一步步model.add()即可,真的十分简单!
搭建好的model分为7个block,1-4block构成类似,只是神经元数量不一样,均包含:Conv2D卷积层,BatchNormalization均一化层,Conv2D卷积层,BatchNormalization均一化层,MaxPool2D池化层,Dropout()随机失活部分神经元。
model前半部分实现了特征提取功能,这也是卷积存在的意义。
需要注意的是,block1的第一个Conv2D卷积层不太一样:
input_shape = (input_rows,input_cols,3)
这是输入到网络的数据的张量形式,笔者的model中理解为图片的尺寸以及颜色通道数(宽,高,RGB)
以block1的第二个Conv2D卷积层为例,
model.add(keras.layers.Conv2D(32,[3,3],padding = 'same',kernel_initializer='he_normal',activation = tf.nn.elu))
参数的含义是:神经元数量,卷积核大小,padding(CNN内容,不详细说了),初始化权重,激活函数
另外MaxPool2D池化层的参数当然就是池化核的大小啦,最后Dropout的参数是失活神经元的比例,0.5就是一半神经元失活。
下面介绍model的后半部分block5。第一层是Flatten()展开层,类似于全班同学在体育老师的指导下站成一排,Flatten()将所有数据一字排开。这里没有任何参数,比如神经元的数量定义,因为有多少个数据就会有同样数量的神经元。
接着是Dense全连接层,即上一层的每一个神经元都与Dense全连接层的每一个神经元建立连接,上一层与Dense层之间没有两两不连接的神经元。
5,6,7blocks实现的功能是进行逻辑推理,最终输出分类结果,block7的Dense全连接层神经元个数就是需要输出的类别数,笔者用num_class指定。
数据预处理(tf.data.Dataset)
笔者使用data.Dataset进行数据打包,分批,并使用map_fun进行图像增强。Dataset的使用方法资料一讲的非常详细,建议仔细阅读
#============================= data ============================#
#=================================================================#
DATA_DIR = 'F:/data/cats-and-dogs/' #数据根目录
LABLE = {0:'cats',1:'dogs'} #分类标签
#'F:/data/cats-and-dogs/train/cats' #猫的训练样本路径,其余类似
def data_set(DATA_DIR,option): #根据option是train还是test加载对应文件夹的数据
if option == 'train':
k = num_train
else:
k = num_test
Filenames = []
Lable = np.zeros(shape = (k,1))
i = 0
for lable in LABLE: #lable是0即进入cats文件夹,是1则进入dogs文件夹
for filename in os.listdir(DATA_DIR + option + '/' + LABLE[lable]):
Filenames.append(DATA_DIR + option + '/' + LABLE[lable] + '/' + filename)
Lable[i] = (lable)
i += 1
return Filenames,Lable #返回图片地址list和对应标签np数组
def map_fun(filename,lable): #数据增强函数,包含旋转,镜像,翻转
image_string = tf.io.read_file(filename)
image = tf.image.decode_jpeg(image_string,channels =3)
#必须要进行上面两步,将图像地址转换为图像数据
rand = random.random()
if rand > 0.5:
image = tf.image.rot90(image)
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
image = image / 255 #数据处理为[0,1]区间的值,据说有利于计算和收敛
return image,lable
#下面是main中的内容,给搬过来了
#======================== funs and main ========================#
#=================================================================#
TRAN_Filenames,TRAN_Lable = data_set(DATA_DIR,'train')
tran_dataset = tf.data.Dataset.from_tensor_slices((TRAN_Filenames,TRAN_Lable))
#上面这步需要注意注意再注意!!!一定是(TRAN_Filenames,TRAN_Lable),带上括号作为参数,不然,嘿嘿,报错都找不见在哪
tran_dataset = tran_dataset.map(map_func = map_fun,num_parallel_calls = num_parallel_calls)
tran_dataset = tran_dataset.shuffle(23000)
tran_dataset = tran_dataset.batch(batch_size)
tran_dataset = tran_dataset.prefetch(tf.data.experimental.AUTOTUNE)
TEST_Filenames,TEST_Lable = data_set(DATA_DIR,'test')
test_dataset = tf.data.Dataset.from_tensor_slices((TEST_Filenames,TEST_Lable))
test_dataset = test_dataset.map(map_func = map_fun,num_parallel_calls=num_parallel_calls)
test_dataset = test_dataset.batch(batch_size)
main()
#======================== funs and main ========================#
#=================================================================#
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self,logs = {}):
self.losses = []
def on_batch_end(self,batch,logs = {}):
self.losses.append(logs.get('loss'))
num_epochs = 100 #遍历数据集的次数
num_class = 2 #类别数
num_train = 23000 #训练样本总数
num_test = 2000 #测试样本总数
input_rows,input_cols = 100,100 #输入图片尺寸
batch_size = 32 #批次大小
learning_rate = 0.01 #初始学习率
loss_value = [] #记录损失值
num_parallel_calls = 4
#================================================================#
#=注意!!!num_parallel_calls是数据增强使使用的CPU核心数,根据实际调整=#
#================================================================#
if __name__ == '__main__':
TRAN_Filenames,TRAN_Lable = data_set(DATA_DIR,'train')
tran_dataset = tf.data.Dataset.from_tensor_slices((TRAN_Filenames,TRAN_Lable))
tran_dataset = tran_dataset.map(map_func = map_fun,num_parallel_calls=num_parallel_calls)
tran_dataset = tran_dataset.shuffle(23000)
tran_dataset = tran_dataset.batch(batch_size)
tran_dataset = tran_dataset.prefetch(tf.data.experimental.AUTOTUNE)
TEST_Filenames,TEST_Lable = data_set(DATA_DIR,'test')
test_dataset = tf.data.Dataset.from_tensor_slices((TEST_Filenames,TEST_Lable))
test_dataset = test_dataset.map(map_func = map_fun,num_parallel_calls=num_parallel_calls)
test_dataset = test_dataset.batch(batch_size)
#================上面是data相关处理================#
model = CNN() #赋予模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
#使用compile函数定义优化器optimizer,详见资料1
#以下四个参数与callbacks的使用有关
reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss',
factor = 0.2,
patience = 4,
verbose = 1,
min_delta = 0.00001)
#动态调整学习率
earlystop = keras.callbacks.EarlyStopping(monitor = 'val_loss',
min_delta = 0,
patience = 10,
verbose = 1,
restore_best_weights = True)
#当模型不在进步时提前结束训练
history = LossHistory()
#通过LossHistory将训练loss值保存history中
checkpoint = keras.callbacks.ModelCheckpoint('best_model.h5',
monitor = 'val_loss',
mode = 'min',
save_best_only = True,
verbose = 1)
#查看当前模型是否最优,只保存训练中最优的模型
callbacks = [history,reduce_lr,earlystop,checkpoint]
#将需要参数打包成list
model.fit(tran_dataset,batch_size = batch_size,epochs = num_epochs, callbacks = callbacks,validation_data = test_dataset)
#训练模型,设置callbacks,validation_data = test_dataset可以在一个epoch后用测试集进行测试,
#上面reduce_lr等中的'val_loss'就是测试集的loss,以此作为保存最优模型,和调整学习率的指标
#tf.saved_model.save(model, "F:/data/cats-and-dogs")
#这也是一种模型保存的方式(详见资料1),不过是在训练结束后保存最新的模型,格式为.pb,模型一个.pb文件和两个文件夹
//补充一下,上述代码笔者跑完一共进行了47个epoch,耗时2h左右
如何使用保存的model
import tensorflow as tf
import cv2 as cv #opencv-python _version_ = 4.5.1.48
import numpy as np
#.pb模型加载
#model = tf.saved_model.load("F:/data/cats-and-dogs")
#.h5模型加载
model = tf.keras.models.load_model("best_model.h5")
#此处注意工作文件夹和模型路径
path = 'C:/Users/Lenovo/Desktop/15153791488040144.jpg'
#待分类的图片
test_image = cv.imread(path)
imagecv = cv.resize(test_image, (100,100)) / 255
imagecv = np.expand_dims(imagecv,axis = 0)
imagecv = imagecv.astype(np.float32)
#这部分是将图片转换成可输入model的形式,还记得前面输入形式是(100,100,3)吗,这里要严格对应,包括第二行在张量第0维进行扩充,以及转换成float32都是为了能够输入模型当中
image = tf.constant(imagecv)
#将np数组转换成tensor数据格式
pred = model(image)
#使用模型进行分类预测
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
sparse_categorical_accuracy.update_state(y_true=0, y_pred=pred)
is_cat = sparse_categorical_accuracy.result().numpy()
#其实不用上面这部分,直接通过下面得到的percent分类概率进行一下大小比较就可以知道是猫是狗了
percent = pred.numpy()
percent = list(percent[0])
print('\n')
if is_cat == 1:
print('This is a cat (%f'%(percent[0] * 100),'% )')
lable = 'cat'
else:
print('This is a dog (%f'%(percent[1] * 100),'% )')
lable = 'dog'
#打印结果
cv.imshow(lable,cv.resize(test_image,(400,400)))
cv.waitKey (0)
cv.destroyAllWindows()
#OpenCV显示图像
另外还可以结合
import shutil
import os
来把那些识别错误的元凶给揪出来,使用os.listdir读取文件名,之后调用我们的model进行识别,最后用shutil.move()进行重命名,把train和test下cats里识别成dog的图片命名成dog******,dogs文件夹里识别成cat的图片命名成cat******。
这样一眼就可以找出识别错误的那些图片是谁了。当然可以把它们踢出去再训练我们的模型,感觉也不是不可以哈哈。
model = tf.saved_model.load("F:/data/cats-and-dogs/model-v4")
DIR = 'F:/data/cats-and-dogs/train/dogs/'
filenames = os.listdir(DIR)
k = 0
for i in filenames:
k += 1
test_image = cv.imread(DIR + i)
imagecv = cv.resize(test_image, (100,100)) / 255
imagecv = np.expand_dims(imagecv,axis = 0)
imagecv = imagecv.astype(np.float32)
image = tf.constant(imagecv)
pred = model(image)
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
sparse_categorical_accuracy.update_state(y_true=0, y_pred=pred)
is_cat = sparse_categorical_accuracy.result().numpy()
percent = pred.numpy()
percent = list(percent[0])
print(k)
if is_cat == 1:
#print(i),print(' is a cat (%f'%(percent[0] * 100),'% )')
shutil.move(DIR + i,DIR + 'cat.' + str('%f' %(percent[0] * 100)) + '%.jpg')
else:
#print(i),print(' is a dog (%f'%(percent[1] * 100),'% )')
shutil.move(DIR + i,DIR + 'dog.' + str('%f' %(percent[1] * 100)) + '%.jpg')
结语
笔者能力有限,只能到此做一个简单的分享,更多的知识小伙伴们需要自己去寻找哦!
//另外,分享一个我最满意的分类模型,它比我得到的任何一个模型都要精确,我记得测试集准确率达到了95%,在percent上表现的也很棒。不过后来有改动一些参数,所以非常遗憾的是,运行上面的代码得不到这个模型了。现在的模型远远不及它,可能跟我改变了图像增强函数有关。
链接: https://pan.baidu.com/s/1636UmEKWD6LdWdMsI_vzSQ.
提取码:yghk
这是上面的代码跑出来的模型预测结果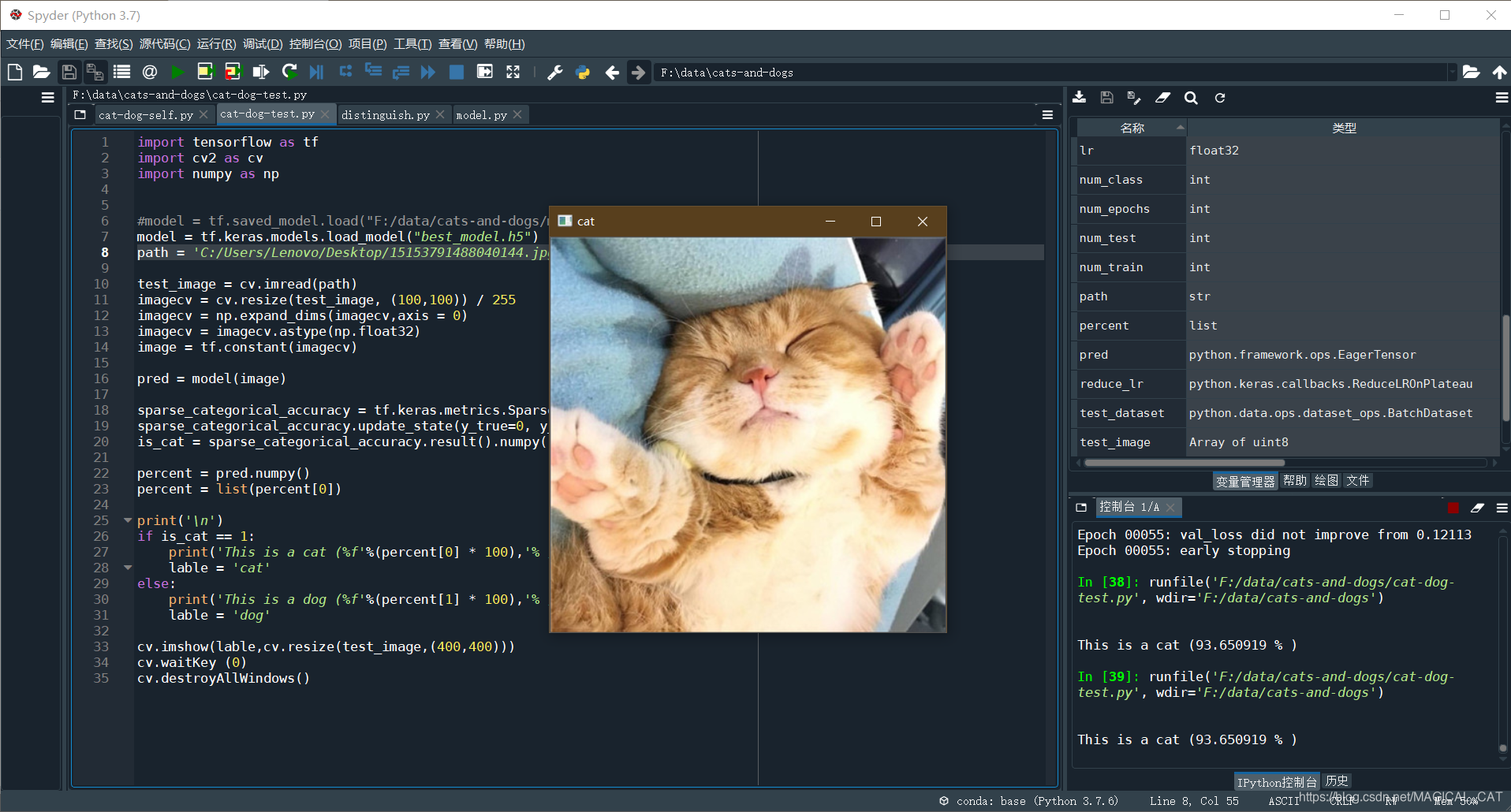
这是我最满意的模型预测的结果
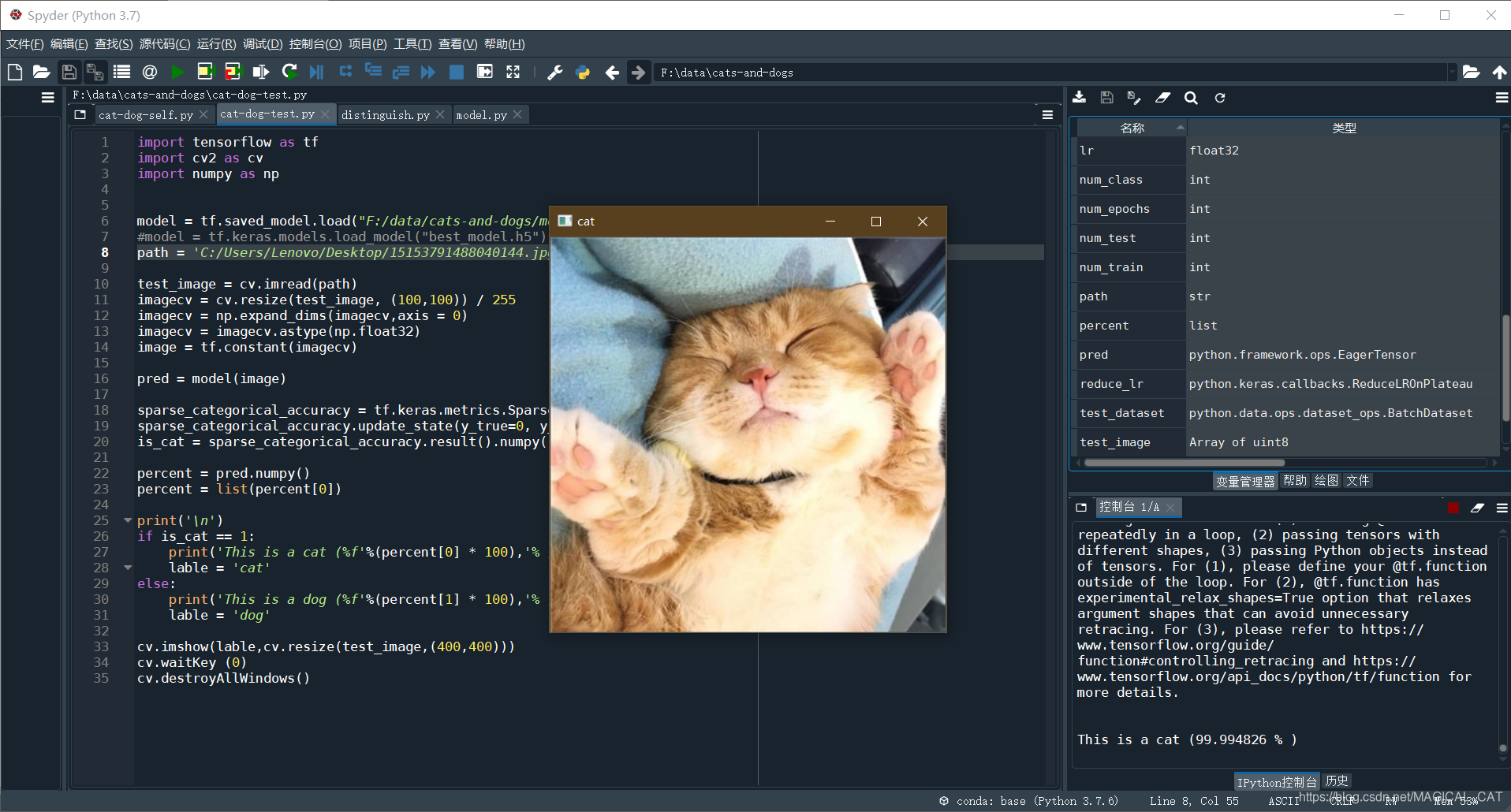
显然,后者要优秀的多,特征这么明显的一幅图没有99.99%有点说不过去吧,毕竟这可是猫的正脸写真,哈哈哈。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









