







Visual Odometry of Computer Vision 视觉里程计设计中的数学部分
Principile Algorithm of Visual Odometry of Computer Vision ( Make sure You underStand LaTex )
Chrome Latex Extention is required, If Not, Please via:
https://blog.csdn.net/magicboom/article/details/113186548
Github Repo: https://github.com/Magicboomliu/VO
Some basic mathematical concepts 一些基本的数学概念
1.Camera Model 相机模型
假设P 的真实世界坐标为
[
X
,
Y
,
Z
]
T
[X,Y,Z]{^T}
[X,Y,Z]T, 相机的成像坐标为
[
X
′
,
Y
′
,
Z
′
]
T
[X',Y',Z']{^T}
[X′,Y′,Z′]T, 焦距为
f
f
f ,二者满足以下的关系:
X
′
=
X
Z
X' = \frac{X}{Z}
X′=ZX
Y
′
=
Y
Z
Y' = \frac{Y}{Z}
Y′=ZY
P像素坐标为
[
u
,
v
]
T
[u,v]{^T}
[u,v]T ,
u
u
u 、
v
v
v和
X
′
X'
X′、
Y
′
Y'
Y′之间又满足如下关系:
{
u
=
α
X
′
+
c
x
u
=
β
Y
′
+
c
y
\begin{cases} u =\alpha X' +c_x \\ u =\beta Y' +c_y \end{cases}
{u=αX′+cxu=βY′+cy
令
α
f
=
f
x
,
β
f
=
f
y
\alpha f = f_x, \beta f =f_y
αf=fx,βf=fy,
{
u
=
f
x
X
Z
v
=
f
y
Y
Z
\begin{cases} u =f_x\frac{X}{Z} \\ v = f_y \frac{Y}{Z} \end{cases}
{u=fxZXv=fyZY
以上的关系可以使用矩阵进行描述:
Z
[
u
v
1
]
=
[
f
x
,
0
,
c
x
0
,
f
y
,
c
y
0
,
0
,
1
]
[
X
Y
Z
]
=
K
P
Z \begin{bmatrix} u\\ v\\ 1 \end{bmatrix} = \begin{bmatrix} &f_x,&0,&c_x\\ & 0,&f_y,&c_y\\ & 0,&0,&1\\ \end{bmatrix} \begin{bmatrix} X\\ Y\\ Z \end{bmatrix} = KP
Z⎣⎡uv1⎦⎤=⎣⎡fx,0,0,0,fy,0,cxcy1⎦⎤⎣⎡XYZ⎦⎤=KP
K记录为相机内参矩阵,Camera Matrix.
在现实世界中,P位置记录为
P
w
P_w
Pw,
T
T
T为变换矩阵:
Z
P
u
v
=
Z
[
u
v
1
]
=
K
(
R
P
w
+
t
)
=
K
T
P
w
ZP_{uv} = Z \begin{bmatrix} u\\ v\\ 1 \end{bmatrix} = K(RP_w+t) = KTP_w
ZPuv=Z⎣⎡uv1⎦⎤=K(RPw+t)=KTPw
其中
T
P
w
TP_w
TPw为相机坐标系下的做坐标,一般为归一化坐标
P
c
P_c
Pc:
P
c
′
=
T
P
w
,
=
[
X
c
Y
c
Z
c
]
P_c '= TP_w, = \begin{bmatrix} X_c\\ Y_c\\ Z_c\\ \end{bmatrix}
Pc′=TPw,=⎣⎡XcYcZc⎦⎤
P
c
=
N
o
r
m
a
l
(
T
P
w
)
=
[
X
c
/
Z
Y
c
/
Z
Z
c
/
Z
]
P_c = Normal(TP_w) = \begin{bmatrix} X_c/Z\\ Y_c/Z\\ Z_c/Z\\ \end{bmatrix}
Pc=Normal(TPw)=⎣⎡Xc/ZYc/ZZc/Z⎦⎤
2.Epipolar Geometry 对极几何
设第一个特征点为
p
1
p1
p1,第二个坐标点为
p
2
p2
p2, 初始状态下相机Pose 为 0,
则满足:
{
x
1
p
1
=
K
P
x
2
p
2
=
K
(
R
P
+
t
)
\begin{cases} x_1p_1 = KP \\ x_2p_2 =K(RP+t) \end{cases}
{x1p1=KPx2p2=K(RP+t)
令:
{
x
1
=
K
−
1
p
1
x
2
=
K
−
1
p
2
\begin{cases}x_1 = K^{-1}p_1 \\ x_2 = K^{-1}p_2 \end{cases}
{x1=K−1p1x2=K−1p2
则
x
1
x_1
x1,
x
2
x_2
x2 满足对极约束:(ram代表 Real antisymmetric matrix)
x
2
T
t
r
a
m
R
x
1
=
0
x_2{^T}t_{ram} Rx_1=0
x2TtramRx1=0
如果用
p
1
p_1
p1,
p
2
p_2
p2表示为:
p
2
T
K
−
T
t
r
a
m
R
K
−
1
p
1
=
0
p_2^{T}K^{-T}t_{ram} RK^{-1}p_1=0
p2TK−TtramRK−1p1=0
其中,记录 E = t r a m R E= t_{ram}R E=tramR为本质矩阵(Essential matrix), F = K − T E K − 1 F= K^{-T}EK^{-1} F=K−TEK−1为基本矩阵。(Fundamental matrix)
补充: 若三维向量 a = [ a 1 a 2 a 3 ] a=\begin{bmatrix} a_1\\ a_2\\ a_3\\ \end{bmatrix} a=⎣⎡a1a2a3⎦⎤ 那么a的反对称矩阵:
a r a m = [ 0 , − a 3 , a 2 a 3 , 0 , − a 1 − a 2 , a 1 , 0 ] a_{ram}=\begin{bmatrix} 0,&-a_3,&a_2\\ a3,&0,&-a_1\\ -a_2,&a1,&0\\ \end{bmatrix} aram=⎣⎡0,a3,−a2,−a3,0,a1,a2−a10⎦⎤
VO的基本思路之一: 根据匹配特征点算E,F, 根据E,F用SVD或是Bundle Adjustment算R,t.
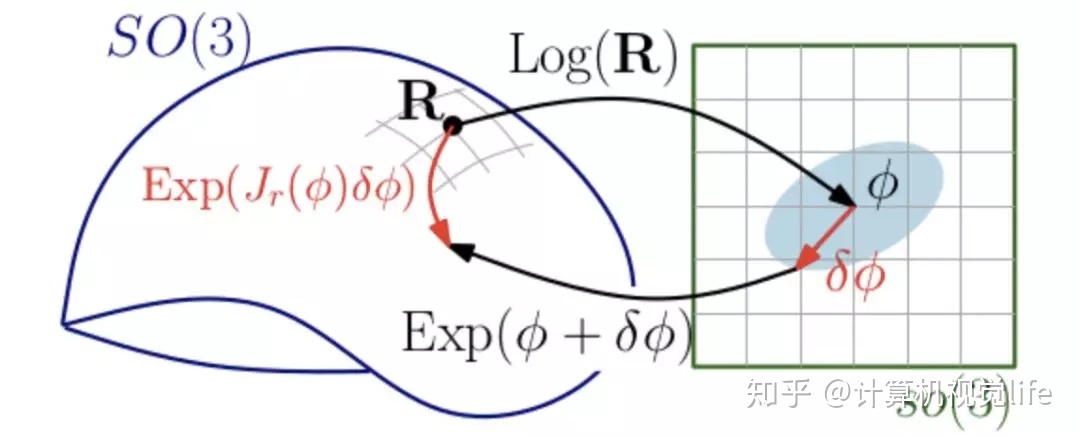
3 Lie algebra 李代数
李代数的存在是方便对旋转矩阵求微分, 从而达到优化的效果。因为旋转矩阵本身不满足“群”的性质: 比如 一个旋转矩阵 R 1 R_1 R1加上另外一个旋转矩阵 R 2 R_2 R2不能保证为旋转矩阵,因此很难进行微分运算, 因此我们把旋转矩阵映射到一个特殊的群上,使其能够满足进行微分运算的性质,这个群就是 “李群”。李代数对应李群的正切空间,它描述了李群局部的导数。
矩阵是可以微分的, 矩阵对时间
t
t
t的微分为一个反对称(也叫斜对称)矩阵左乘它本身,对于某个时刻的R(t)(李群空间),存在一个三维向量φ=(φ1,φ2,φ3)(李代数空间),用来描述R在t时刻的局部的导数:
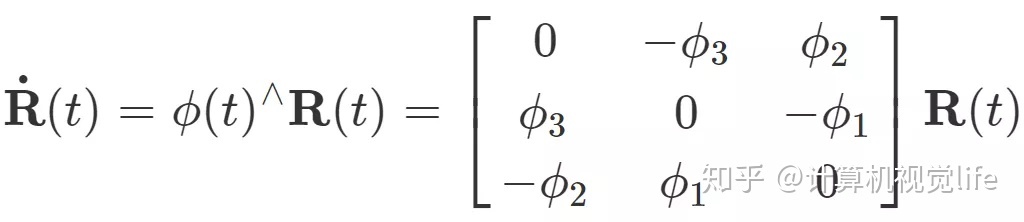
SO(3)上的原点 φ0 附近的正切空间上。这个φ正是李群大SO(3)对应的李代数小so(3), 即在原点附近,满足以下关系:
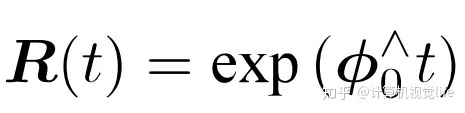
李代数小so(3)是三维向量φ的集合,每个向量φi的反对称矩阵都可以表达李群(大SO(3))上旋转矩阵R的导数,而R和φ是一个指数映射关系。
然后可以使使用Taylor公式对
R
(
t
)
R(t)
R(t)进行计算:

由此可以看出, so(3)本质上由旋转向量组成的的空间,这样我们可以说旋转矩阵的导数可以由其对应的旋转向量指定,指导如何在旋转矩阵中进行微积分运算。
SO(3) SE(3)和 so(3) se(3)的转换关系:

矩阵优化的思路:
- 李代数表示Pose,使用李代数加法求导。(李代数求导模型)
- 使用李代数左乘,右乘微小扰动,对该扰动求导。(扰动模型)
p为空间内部一点,R为Pose,我们对R求导。
(1)用李代数表示姿态,然后根据李代数加法来对李代数求导。即传统求导的思路,把增量直接定义在李代数上。

(2) 对李群SO(3)左乘或者右乘微小扰动,然后对该扰动求导,称为左扰动和右扰动模型。即把增量扰动直接添加在李群上,然后使用李代数表示此扰动。
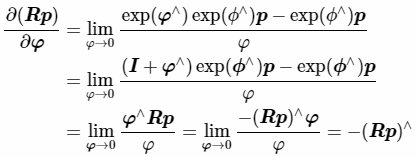
(3)SE(3)上面,含义是:考虑一个空间点P(需要是齐次坐标,否则维数不对),受到刚体变换T,得到TP:

上面最后一行矩阵除法,与矩阵乘法规则类似,只是乘号变成了除号。其使用一个4×1矩阵除以一个1×6矩阵得到一个4×6矩阵
引入李群李代数的意义:第一个是因为在欧式变换矩阵上不好定义导数,引入李群李代数使得导数定义变得自然合理;第二个是本来旋转矩阵与欧式变换矩阵具有本身的约束,使得将它们作为优化变量会引入额外约束,通过李群李代数可以使得问题变成一个无约束的优化问题(旋转变量有约束,因为旋转矩阵必须满足正交矩阵行列式为1,优化起来不方便).
4. 非线性优化问题 Nonlinear optimization problem
不能保证特征点绝对准确, 存在造成因素使得
R
R
R,$
t$求解出来不一定正确,因此需要Nonlinear optimization。
假设优化函数为
f
(
x
)
f(x)
f(x), 将该优化目标进行Taylor展开:
f
(
x
+
Δ
x
)
=
f
(
x
)
+
J
(
x
)
Δ
x
f(x+\Delta x) = f(x)+ J(x)\Delta x
f(x+Δx)=f(x)+J(x)Δx
求解最小2乘问题:
Δ
x
∗
=
a
r
g
m
i
n
Δ
x
∗
1
2
∥
f
(
x
)
+
J
(
x
)
Δ
x
∥
2
\Delta x^* = argmin_{\Delta x^*} \frac{1}{2}\parallel {f(x)+J(x)\Delta x}\parallel ^2
Δx∗=argminΔx∗21∥f(x)+J(x)Δx∥2
求解
Δ
x
\Delta x
Δx的导数使其为0.得到如下方程:
J
(
x
)
T
J
(
X
)
Δ
x
=
−
J
(
x
)
f
(
x
)
J(x)^{T}J(X)\Delta x = -J(x)f(x)
J(x)TJ(X)Δx=−J(x)f(x)
这个方程成为增量方程(Incremental equation), 也叫高斯牛顿方程(G-N equation,) 其中我们定义
J
(
x
)
T
J
(
X
)
J(x)^{T}J(X)
J(x)TJ(X) 为 H(近似于2阶导数,Hessian Matrix),
−
J
(
x
)
f
(
x
)
-J(x)f(x)
−J(x)f(x)为 g(有些地方写成 b), 则增量方程可以写成:
H
Δ
x
=
g
H\Delta x = g
HΔx=g
现在给出G-N算法的流程:
- 给定初始值 x 0 x_0 x0
- 计算此时的误差 f ( x 0 ) f(x_0) f(x0)和对应的J(x).
- 计算H和g
- 计算 Δ x \Delta x Δx
- Let x ′ = x 0 + Δ x x' = x_0 + \Delta x x′=x0+Δx
- 重新计算误差 f ( x 0 ) f(x_0) f(x0)和对应的J(x),重复以上行为
- 当 Δ x \Delta x Δx足够小,停止。
高斯-牛顿(Gausss-Newton)G-N法对应前段 B u n d l e A d j u s t m e n t Bundle Adjustment BundleAdjustment
误差为重投影误差(Reprojection error), 一般用于优化PnP问题或是ICP问题。
已知n个三维的空间点坐标P和投影p(像素坐标),希望计算相机Pose 的 R 和 t, Pose 对应的se(3)为
ξ
\xi
ξ, 则根据相机模型,满足如下关系:
s
i
u
i
=
K
e
x
p
(
ξ
r
a
m
)
P
i
s_iu_i = K exp(\xi_{ram})P_i
siui=Kexp(ξram)Pi
重投影误差计算为:
ξ
∗
=
a
r
g
m
i
n
ξ
1
2
∑
i
=
1
n
∥
u
i
−
1
s
i
K
e
x
p
(
ξ
r
a
m
)
P
i
∥
2
\xi^*=argmin_{\xi}\frac{1}{2} \sum_{i=1}^{n} \parallel u_i -\frac{1}{s_i}K exp(\xi_{ram}) P_i \parallel ^2
ξ∗=argminξ21i=1∑n∥ui−si1Kexp(ξram)Pi∥2
在优化前, 首先我们需要知道每个点的3维度相机坐标系下坐标:
P
′
=
e
x
p
(
ξ
r
a
m
P
)
1
:
3
=
[
X
′
,
Y
′
,
Z
′
]
P' = exp(\xi_{ram}P)_{1:3} = [X' , Y', Z']
P′=exp(ξramP)1:3=[X′,Y′,Z′]
这个可以根据相机模型去获得(根据相机坐标u ,v),因为:
{
u
=
f
x
X
′
Z
′
v
=
f
y
Y
′
Z
′
\begin{cases}u = f_x\frac{X'}{Z'} \\ v = f_y\frac{Y'}{Z'} \end{cases}
{u=fxZ′X′v=fyZ′Y′
使用G-N方法,解的的$J(x)为一个 2 x 6 的雅克比矩阵:
∂
e
∂
δ
ξ
=
−
[
f
x
Z
′
,
0
,
−
f
x
X
′
Z
′
2
,
−
f
x
X
′
Y
′
Z
′
2
,
f
x
+
f
x
X
2
Z
′
2
,
−
f
x
Y
′
Z
′
0
,
f
y
Z
′
,
−
f
y
Y
′
Z
′
2
,
−
f
y
−
f
y
Y
′
2
Z
′
2
,
−
f
y
X
′
Y
′
Z
′
2
,
−
f
y
X
′
Z
′
]
\frac{\partial e}{\partial \delta\xi} = - \begin{bmatrix} \frac{f_x}{Z'}, &0,&-\frac{f_xX'}{Z'^2},& -\frac{f_xX'Y'}{Z'^2}, &f_x +\frac{f_xX^2}{Z'^2}, &-\frac{f_xY'}{Z'} \\ 0, &\frac{f_y}{Z'}, &-\frac{f_yY'}{Z'^2},&-f_y -\frac{f_yY'^2}{Z'^2}, &-\frac{f_yX'Y'}{Z'^2}, &-\frac{f_yX'}{Z'} \end{bmatrix}
∂δξ∂e=−[Z′fx,0,0,Z′fy,−Z′2fxX′,−Z′2fyY′,−Z′2fxX′Y′,−fy−Z′2fyY′2,fx+Z′2fxX2,−Z′2fyX′Y′,−Z′fxY′−Z′fyX′]
根据这个J(x)可以计算H, 在根据H,f(x),J(x)计算
Δ
ξ
\Delta \xi
Δξ, 更新
ξ
\xi
ξ,从而更新R和t。
BA算法出来优化Pose之外,还可以优化点P的坐标得到的J(x)是一个2 x3 的矩阵:
∂
e
∂
P
=
−
[
f
x
Z
′
,
0
,
−
f
x
X
′
Z
′
2
0
,
f
y
Z
′
,
−
f
y
Y
′
Z
′
2
]
R
\frac{\partial e}{\partial P} = - \begin{bmatrix} \frac{f_x}{Z'}, &0,&-\frac{f_xX'}{Z'^2} \\ 0, &\frac{f_y}{Z'},&-\frac{f_yY'}{Z'^2} \end{bmatrix} R
∂P∂e=−[Z′fx,0,0,Z′fy,−Z′2fxX′−Z′2fyY′]R
然后计算
Δ
P
\Delta P
ΔP,更新P。
下面展示 高翔博士 用G-N 做BA求解R和t 的 C++ Code
[
f
x
,
0
,
c
x
0
,
f
y
,
c
y
0
,
0
,
1
]
\begin{bmatrix} &f_x,&0,&c_x\\ & 0,&f_y,&c_y\\ & 0,&0,&1\\ \end{bmatrix}
⎣⎡fx,0,0,0,fy,0,cxcy1⎦⎤
为相机内参K, 第一步是// 将坐标转为相机坐标系下的坐标
// 将坐标转为相机坐标系下的坐标
Point2d pixel2cam(const Point2d &p, const Mat &K) {
return Point2d
(
(p.x - K.at<double>(0, 2)) / K.at<double>(0, 0),
(p.y - K.at<double>(1, 2)) / K.at<double>(1, 1)
);
}
这里得到的Point2d其实是[ X ′ Z ′ \frac{X'}{Z'} Z′X′, Y ′ Z ′ \frac{Y'}{Z'} Z′Y′], 可以理解为用 Z ′ Z' Z′归一化的相机坐标系下的坐标。
接下来就是计算 ξ \xi ξ
void bundleAdjustmentGaussNewton(
const VecVector3d &points_3d,
const VecVector2d &points_2d,
const Mat &K,
Sophus::SE3d &pose) {
typedef Eigen::Matrix<double, 6, 1> Vector6d;
const int iterations = 10;
double cost = 0, lastCost = 0;
double fx = K.at<double>(0, 0);
double fy = K.at<double>(1, 1);
double cx = K.at<double>(0, 2);
double cy = K.at<double>(1, 2);
for (int iter = 0; iter < iterations; iter++) {
Eigen::Matrix<double, 6, 6> H = Eigen::Matrix<double, 6, 6>::Zero(); //这里之所以是 6 x 6 是因为J(x)TJ(X) = H, J(X)是2 x 6
Vector6d b = Vector6d::Zero(); // b = J(x)Tf(x), J(x)T是 6 x 2, f(x)是 x,y 2个维度的误差,所以是2 x 1.
cost = 0;
// compute cost
for (int i = 0; i < points_3d.size(); i++) {
Eigen::Vector3d pc = pose * points_3d[i];
double inv_z = 1.0 / pc[2]; // 1/Z'
double inv_z2 = inv_z * inv_z; // 1/Z^2
Eigen::Vector2d proj(fx * pc[0] / pc[2] + cx, fy * pc[1] / pc[2] + cy);
Eigen::Vector2d e = points_2d[i] - proj; // 重投影误差
cost += e.squaredNorm();
Eigen::Matrix<double, 2, 6> J; // 可以直接套结论的矩阵
J << -fx * inv_z,
0,
fx * pc[0] * inv_z2,
fx * pc[0] * pc[1] * inv_z2,
-fx - fx * pc[0] * pc[0] * inv_z2,
fx * pc[1] * inv_z,
0,
-fy * inv_z,
fy * pc[1] * inv_z2,
fy + fy * pc[1] * pc[1] * inv_z2,
-fy * pc[0] * pc[1] * inv_z2,
-fy * pc[0] * inv_z;
H += J.transpose() * J; // n点累加
b += -J.transpose() * e;
}
Vector6d dx;
dx = H.ldlt().solve(b); // 更新 se3
if (isnan(dx[0])) {
cout << "result is nan!" << endl;
break;
}
if (iter > 0 && cost >= lastCost) {
// cost increase, update is not good
cout << "cost: " << cost << ", last cost: " << lastCost << endl;
break;
}
// update your estimation // 更新SE(3)
pose = Sophus::SE3d::exp(dx) * pose;
lastCost = cost;
cout << "iteration " << iter << " cost=" << std::setprecision(12) << cost << endl;
if (dx.norm() < 1e-6) { // 当需要更新的左乘se(3)足够小。
// converge
break;
}
}
cout << "pose by g-n: \n" << pose.matrix() << endl;
}
在main ()函数中调用:
int main(int argc, char** argv){
// ......前期求特征点或是三角测量 省略........
............
Point2d p1 = pixel2cam(keypoints_1[m.queryIdx].pt, K);
pts_3d.push_back(Point3f(p1.x * dd, p1.y * dd, dd)); // dd为深度, 第一个图知道3D
pts_2d.push_back(keypoints_2[m.trainIdx].pt); // 第2个图知道2d, 这个是3d-2d,问题
// 使用 P-n-P求解
Mat r, t;
solvePnP(pts_3d, pts_2d, K, Mat(), r, t, false); // 调用OpenCV 的 PnP 求解,可选择EPNP,DLS等方法
Mat R;
cv::Rodrigues(r, R); // r为旋转向量形式,用Rodrigues公式转换为矩阵
cout << "solve pnp in opencv cost time: " << time_used.count() << " seconds." << endl;
// 这是不用BA的解法
cout << "R=" << endl << R << endl;
cout << "t=" << endl << t << endl;
// 下面我们使用BA
VecVector3d pts_3d_eigen;
VecVector2d pts_2d_eigen;
for (size_t i = 0; i < pts_3d.size(); ++i) {
pts_3d_eigen.push_back(Eigen::Vector3d(pts_3d[i].x, pts_3d[i].y, pts_3d[i].z));
pts_2d_eigen.push_back(Eigen::Vector2d(pts_2d[i].x, pts_2d[i].y));
}
cout << "Calling bundle adjustment by gauss newton" << endl;
Sophus::SE3d pose_gn;
bundleAdjustmentGaussNewton(pts_3d_eigen, pts_2d_eigen, K, pose_gn);
cout<<"T="<<endl<<pose_gn.matirx()<<endl;
}
Levenberg-Marquardt(列文伯格-马夸尔特)算法
LM方法在一定程度上修正了这些问题,一般认为它比GN更为鲁棒。尽管它的收敛速度可能比GN慢,被称之为阻尼牛顿法.由于GN中采用近似的二阶泰勒展开只能在展开点附近有较好的近似效果,所以我们很自然的想到应该给 Δ x \Delta x Δx 添加一个信赖区域(Trust Region),不能让它太大使得近似不准确。非线性优化有一系列这类方法,这类方法也被称之为信赖区域方法(Trust Region Method)。在信赖区域里面,我们认为近似是有效的,出了这个区域,近似可能会出问题。
那么如何确认这个信赖区域的范围?一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定。如果差异够小,我们让范围尽可能大。如果差异大,我们就缩小这个近似范围。因此,可以考虑使用
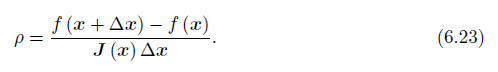
来判断泰勒近似是否够好, 分子式实际函数下降的值,分母是近似模型下降的值。如果接近于1,则近似是好的。如果太小,说明实际减小的值远少于近似减少的值,这认为近似比较差。反之,如果 比较大,则说明实际下降的比预计的更大,我们可以放大近似范围.

相当于一个带约束的最小2乘法:

最后可以得到增量方程:

记录 D T D = I D^TD = I DTD=I, 简化增量方程:
我们看到,当参数
λ
\lambda
λ 比较小时,
H
H
H 占主要地位,这说明二次近似模型在该范围内是比较好的,LM方法更接近于GN法。另一方面,当
λ
\lambda
λ比较大时,
λ
I
\lambda I
λI占主要地位,LM更接近于一阶梯度下降法,这说明附近二次近似不够好。LM的求解方法可以一定程度避免线性方程组的系数矩阵非奇异和病态问题,提供更稳定更准确的增量
Δ
x
\Delta x
Δx。

伪代码逻辑:

补充: 如何使用 G2O进行图优化
SLAM领域,基于图优化的一个用的非常广泛的库就是g2o,它是General Graphic Optimization 的简称,是一个用来优化非线性误差函数的c++框架。
G2O的基本框架如下:

G2O 本身的核心是一个稀疏矩阵的优化器。即图中的SparseOptimizer, 由图可知, 它一个优化图OptimizableGraph,也是一个超图HyperGraph, 这个超图包含了许多顶点(HyperGraph::Vertex)和边(HyperGraph::Edge)。而这些顶点顶点继承自 Base Vertex,也就是OptimizableGraph::Vertex,而边可以继承自 BaseUnaryEdge(单边), BaseBinaryEdge(双边)或BaseMultiEdge(多边),它们都叫做OptimizableGraph::Edge。
在G2O中,顶点 Vertex 代表优化的对象,比如相机Pose(R,t), 而边 Edge 表示误差,即用来优化 Vertex 的量(如重投影误差)。
整个图的核心SparseOptimizer 包含一个优化算法(OptimizationAlgorithm)的对象。OptimizationAlgorithm是通过 OptimizationWithHessian 来实现的。其中迭代策略可以从Gauss-Newton(高斯牛顿法,简称GN), Levernberg-Marquardt(简称LM法), Powell’s dogleg 三者中间选择一个(我们常用的是GN和LM)
OptimizationWithHessian 内部包含一个求解器(Solver),这个Solver实际是由一个BlockSolver组成的。这个BlockSolver有两个部分,一个是SparseBlockMatrix ,用于计算稀疏的雅可比和Hessian矩阵;一个是线性方程的求解器(LinearSolver),它用于计算迭代过程中最关键的一步HΔx=−b,LinearSolver有几种方法可以选择:PCG, CSparse, Choldmod。
但是在写代码时候, 我们需要从定义BlockSovler,LinearSolver开始写起: 写G2O代码的逻辑步骤如下:
- 创建一个线性求解器LinearSolver。(解增量方程H△X=-b,可以制定解法)
- 创建BlockSolver。并用上面定义的线性求解器初始化
- 创建总求解器solver。并从GN, LM, DogLeg 中选一个,再用上述块求解器BlockSolver初始化
- 创建终极大boss 稀疏优化器(SparseOptimizer),并用已定义求解器作为求解方法。
- 定义图的顶点和边。并添加到SparseOptimizer中。
- 设置优化参数,开始执行优化。
具体每一个部分参考 《一起动手SLAM》的文章, 介绍很详细:
G2O框架介绍
G2O Vertex的定义方法
G2O Edge的定义方法















 1580
1580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









