







最近在研究AIGC🤖️技术,看了很多微调方法、论文层。但搞技术这么能纸上谈兵呢?今天本柯南迷就想来实践生成美少女小兰👸
在这篇文章里,我选用了 textual inversion和dreambooth📷来做比较,这两种方法都是通过扩大词字典的嵌入,来插入新的概念。
训练图片处理
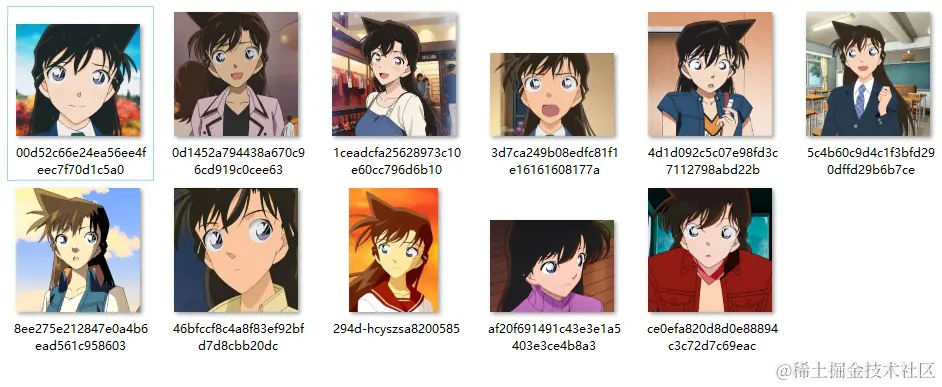 在网上找到了11张高清的小兰🌸特写图,尽量找人物主体比较鲜明的图片,这样才能让模型更好地学习到人物特征~ 为了图片不因为resize而变形,这里使用letterbox方法将图片先处理为512×512大小的尺寸:
在网上找到了11张高清的小兰🌸特写图,尽量找人物主体比较鲜明的图片,这样才能让模型更好地学习到人物特征~ 为了图片不因为resize而变形,这里使用letterbox方法将图片先处理为512×512大小的尺寸:
def letterbox_image(image, size=(512, 512), color=(0, 0, 0), scale=False):
iw, ih = image.size
w, h = size
scale = min(w / iw, h / ih)
nw = int(iw * scale)
nh = int(ih * scale)
image = image.resize((nw, nh), Image.BICUBIC)
new_image = Image.new('RGB', size, color)
new_image.paste(image, ((w - nw) // 2, (h - nh) // 2))
return new_image
到这一步,我们需要训练的人物主体数据就处理好啦~
dreambooth微调
dreambooth的效果类似于照相摄影棚——一旦拍摄了几张某个对象的照片,摄影棚就会生成包含该对象在不同条件和场景下的照片。 dreambooth的目标是扩展模型的语言视觉词典,一旦新词典嵌入模型,模型就可以在不同的背景场景下生成新词主题,同时保留其关键识别特征。
这个新词可以用标识符(identifier)来表示,为了防止语言漂移,需要在标识符的后面加入这个新词的大类,比如:“A [V] dog”,[V]为标识符,dog为大类。
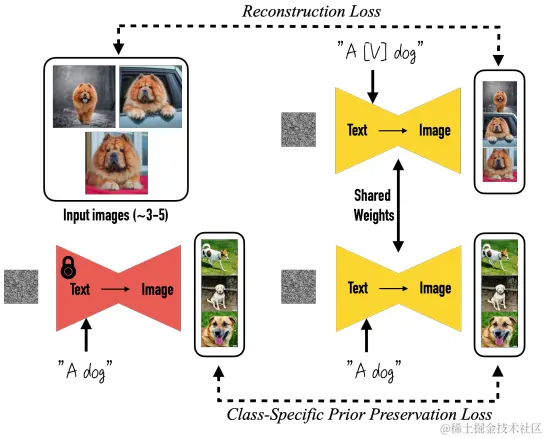
为了防止语言漂移,研究者提出了 Class-specific Prior Preservation Loss
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









