







 本文介绍了在生物统计学中,特别是在随机区组设计中处理不完全区组的方法,如平衡不完全区组设计(BIB)。该设计强调了经济性、平衡性和灵活性,通过严格的数学方法进行误差校正,确保试验精度。文章还提及了统计分析过程,包括使用无重复观测值的两因素方差分析模型和处理平均数的矫正。
本文介绍了在生物统计学中,特别是在随机区组设计中处理不完全区组的方法,如平衡不完全区组设计(BIB)。该设计强调了经济性、平衡性和灵活性,通过严格的数学方法进行误差校正,确保试验精度。文章还提及了统计分析过程,包括使用无重复观测值的两因素方差分析模型和处理平均数的矫正。
参考资料:生物统计学
在随机区组设计中,每个区组包含全部处理,这种区组称为完全区组。如果一个区组只包含部分处理,则称为不完全区组,在生态学及农林田间试验中,由于受地形、土壤等客观条件的限制,一个区组内无法容纳全部的实验处理时,只能容纳其中的一部分处理,即一个区组只包含一部分的处理,这时候就需要采用不完全区组设计。
1、设计方法
平衡不完全区组设计(balanced incomplete block design),简称BIB设计,是不完全区组设计方法中使用较多的一种。进行BIB设计时:
①先根据试验处理数a、重复数n及每个区组的小区数k计算试验的区组数b,以及两个处理在同一区组相遇的次数λ=n(k-1)/(a-1);
②根据每一区组的小区数将处理组合排入区组,保证任意两个处理在一个小区相遇的概率相等;
③对各区组内的处理做随机排列;
④对区组进行随机排列。
2、主要特点
①经济性:全部试验水平可以不安排在同一区组内进行,对区组的要求较低,经济地解决了试验成本。
②平衡性:每个实验处理的重复数相同;每个区组包含的处理数相同;任意两个处理对在试验中相遇的次数相同。
③灵活性:可以根据每个区组的小区数灵活、分散地进行试验。
④计算的严密性:有严格的数学方法有效的消除系统误差,故试验精度稿。
3、试验结果的统计分析
和随机区组设计一样,平衡不完全区组设计资料的统计分析也采用无重复观测值的两因素方差分析模型,但需要对处理平方和进行矫正,去除区组的影响。数学模型为:
其中:为处理水平i区组j的地k个观测值;αi为处理效应;βj为区组效应;
为误差。平方和与自由度的分解为:
,
,
,
,
其中:T为总变异,tc为矫正的处理变异,R为区组变异,e为误差;a为试验处理数,n为重复数据,b为区组数,k为每个区组的处理数,na=bk;Ti为处理i的观测值之和,Tj为区组j的观测值之和;,T为所有观测值的总和。
,Vi为含处理i的区组的观测值之和。进行多重比较时,也需要对处理平均数进行矫正。校正后的处理平均数为:
标准误为:
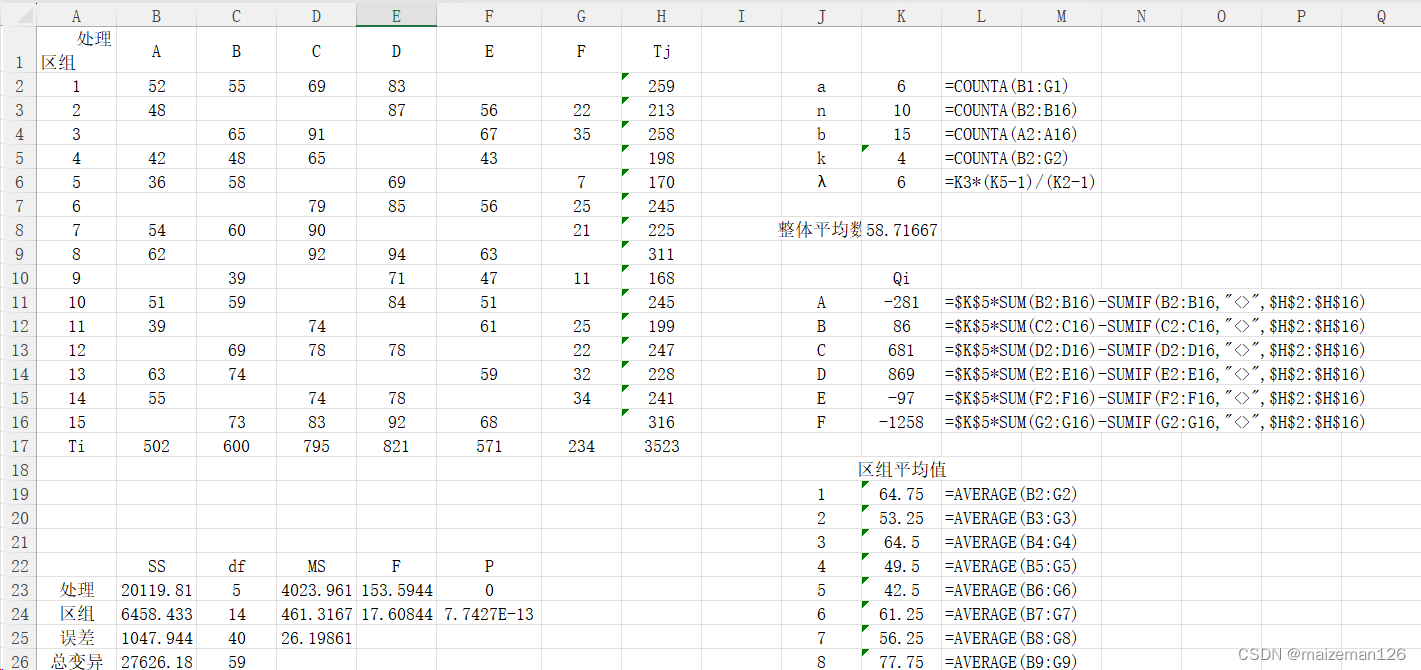
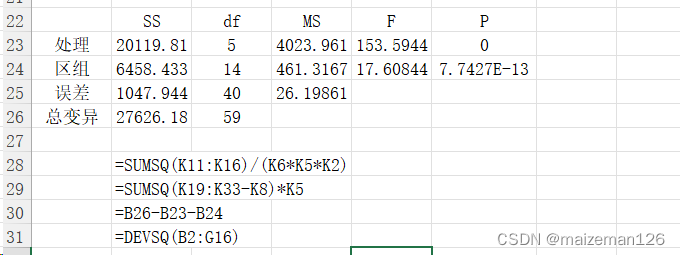
excel操作案例如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









