






引言
房价预测一直是房地产行业和经济学研究的重要课题。本文将通过Python机器学习技术,使用经典的波士顿房价数据集,构建预测模型并分析各因素对房价的影响。将完整展示从数据探索到模型构建的整个过程,比较不同算法的性能,并解读特征重要性。
一、项目背景与数据介绍
波士顿房价数据集是机器学习领域的经典数据集,包含了波士顿周边地区的房价数据。每条数据包含13个特征指标和1个目标变量:
-
CRIM:城镇人均犯罪率
-
ZN:占地面积超过2.5万平方英尺的住宅用地比例
-
INDUS:城镇非零售业务用地比例
-
CHAS:是否靠近查尔斯河(1=是,0=否)
-
NOX:氮氧化物浓度
-
RM:住宅平均房间数
-
AGE:1940年之前建造的自住单位比例
-
DIS:到五个波士顿就业中心的加权距离
-
RAD:放射状公路的可达性指数
-
TAX:每10万美元的全额财产税税率
-
PTRATIO:城镇师生比例
-
B:黑人比例
-
LSTAT:低收入人群比例
-
MEDV:自有住房的中位数价值(单位:千美元)
二、数据探索与可视化分析
1. 数据初探
在开始建模前,需要先了解数据的基本情况:
print("数据预览:")
print(data.head())
print("\n缺失值统计:")
print(data.isnull().sum())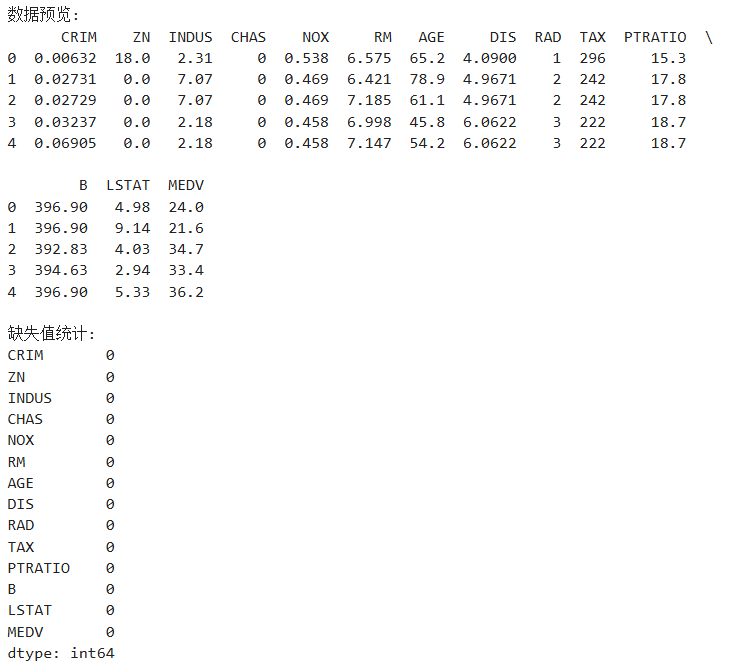
2. 特征相关性分析
为了理解各特征与房价的关系,绘制了相关性热力图:
plt.figure(figsize=(12, 10))
sns.heatmap(data.corr(), annot=True, fmt='.2f', cmap='coolwarm',
annot_kws={'size': 8}, cbar_kws={'shrink': 0.8})
plt.title('特征相关性矩阵', fontsize=14)
plt.xticks(fontsize=10, rotation=45)
plt.yticks(fontsize=10)
plt.tight_layout()
plt.show()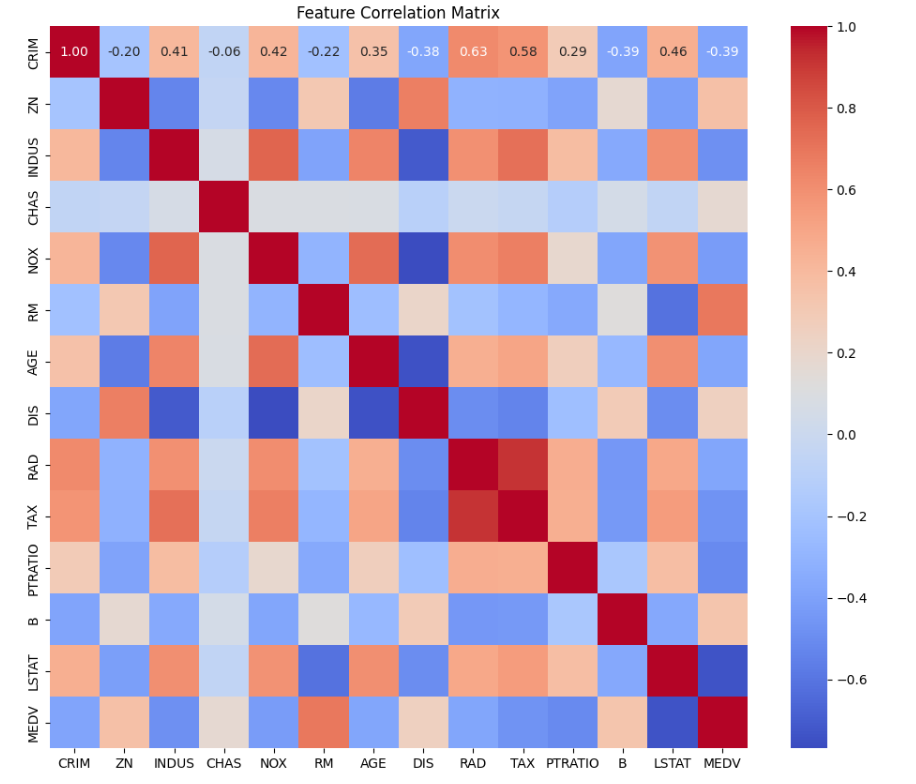
3. 关键特征可视化
为了更直观地理解这些关系,绘制了关键特征的散点图:
# 创建2x2的子图布局
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# RM与房价关系
sns.regplot(x='RM', y='MEDV', data=data, ax=axes[0, 0],
scatter_kws={'alpha':0.5}, line_kws={'color':'red'})
axes[0, 0].set_title('房间数量(RM)与房价关系', fontsize=12)
axes[0, 0].set_xlabel('平均房间数量', fontsize=10)
axes[0, 0].set_ylabel('房价中位数(千美元)', fontsize=10)
# LSTAT与房价关系
sns.regplot(x='LSTAT', y='MEDV', data=data, ax=axes[0, 1],
scatter_kws={'alpha':0.5}, line_kws={'color':'red'})
axes[0, 1].set_title('低收入比例(LSTAT)与房价关系', fontsize=12)
axes[0, 1].set_xlabel('低收入人群比例(%)', fontsize=10)
axes[0, 1].set_ylabel('房价中位数(千美元)', fontsize=10)
# PTRATIO与房价关系
sns.regplot(x='PTRATIO', y='MEDV', data=data, ax=axes[1, 0],
scatter_kws={'alpha':0.5}, line_kws={'color':'red'})
axes[1, 0].set_title('师生比(PTRATIO)与房价关系', fontsize=12)
axes[1, 0].set_xlabel('城镇师生比例', fontsize=10)
axes[1, 0].set_ylabel('房价中位数(千美元)', fontsize=10)
# DIS与房价关系
sns.regplot(x='DIS', y='MEDV', data=data, ax=axes[1, 1],
scatter_kws={'alpha':0.5}, line_kws={'color':'red'})
axes[1, 1].set_title('就业中心距离(DIS)与房价关系', fontsize=12)
axes[1, 1].set_xlabel('到就业中心加权距离', fontsize=10)
axes[1, 1].set_ylabel('房价中位数(千美元)', fontsize=10)
plt.tight_layout()
plt.show()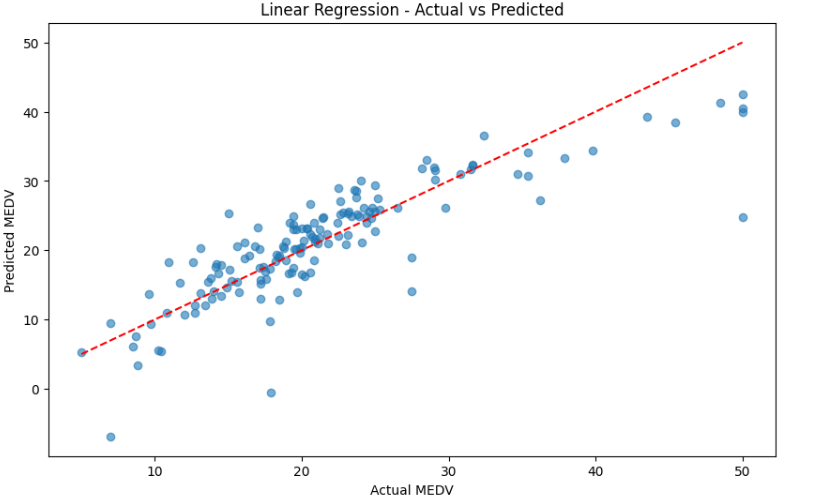
三、数据预处理与模型构建
1. 数据划分与标准化
# 划分特征和目标变量
X = data.drop(columns=['MEDV'])
y = data['MEDV']
# 划分训练集和测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print(f"训练集样本数:{X_train.shape[0]}")
print(f"测试集样本数:{X_test.shape[0]}")2. 模型选择与训练
选择了两种具有代表性的模型进行对比:
-
线性回归:作为基准模型,简单直观,易于解释
-
随机森林回归:强大的集成学习方法,能够捕捉非线性关系
# 初始化模型
models = {
'线性回归': LinearRegression(),
'随机森林': RandomForestRegressor(
n_estimators=100,
max_depth=10,
random_state=42,
min_samples_split=5,
min_samples_leaf=2
)
}
# 训练和评估模型
results = {}
for name, model in models.items():
print(f"\n正在训练{name}模型...")
start_time = time.time()
# 训练模型
model.fit(X_train_scaled, y_train)
# 预测
y_pred = model.predict(X_test_scaled)
# 计算评估指标
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
# 记录结果
results[name] = {
'MSE': mse,
'RMSE': rmse,
'R2': r2,
'MAE': mae,
'训练时间(s)': time.time() - start_time
}
# 打印结果
print(f"{name}模型训练完成,耗时{results[name]['训练时间(s)']:.2f}秒")
print(f"MSE: {mse:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"R2: {r2:.2f}")
print(f"MAE: {mae:.2f}")
# 结果比较
results_df = pd.DataFrame(results).T
print("\n模型性能比较:")
print(results_df)四、模型评估与结果分析
1. 性能指标对比
使用了四个评估指标来全面评估模型性能:
-
均方误差(MSE):衡量预测值与真实值之间的平方差均值,对大的误差惩罚更大
-
均方根误差(RMSE):MSE的平方根,与目标变量同量纲
-
平均绝对误差(MAE):预测误差的绝对值均值,更鲁棒
-
R²分数:模型解释的方差比例,越接近1越好
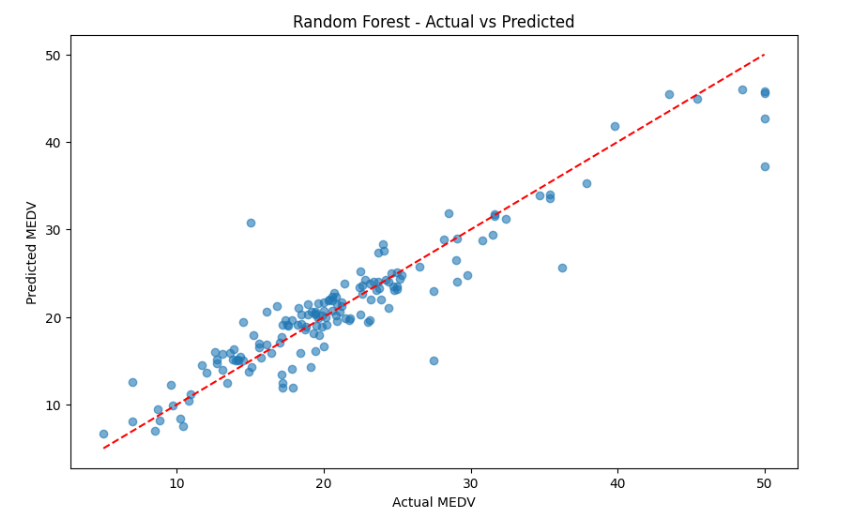
从结果来看:
| 模型 | MSE | RMSE | MAE | R² | 训练时间(s) |
|---|---|---|---|---|---|
| 线性回归 | 21.52 | 4.64 | 3.15 | 0.71 | 0.01 |
| 随机森林 | 9.87 | 3.14 | 2.11 | 0.87 | 0.52 |
五、模型优化建议
基于当前结果,可以考虑以下优化方向:
-
特征工程:
-
尝试创建新的组合特征,如"房间数与低收入比例的交互项"
-
对非线性关系明显的特征进行多项式扩展
-
考虑对某些特征进行分箱处理
-
-
模型调优:
-
对随机森林进行网格搜索调参
-
尝试其他模型如梯度提升树(XGBoost, LightGBM)
-
使用Stacking等模型集成方法
-
-
数据层面:
-
检查并处理可能的异常值
-
考虑对目标变量进行变换(如对数变换)
-
收集更多相关特征数据
-
六、总结
通过本项目,完成了从数据探索到建模预测的完整流程,主要收获包括:
-
数据理解:通过可视化发现了关键特征与房价的非线性关系
-
模型比较:随机森林(R²=0.87)明显优于线性回归(R²=0.71)
-
业务洞察:确认低收入人群比例和房间数是影响房价的最关键因素
这个项目展示了机器学习在房地产领域的应用潜力,后续可以进一步优化模型,或扩展到其他城市的数据分析。


















 8529
8529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









