







参考资料:活用pandas库
1、转换
转换数据时,需要把DataFrame中的值传递给一个函数,而后由该函数“转换”数据。在《python数据分析——分组操作1》讲过aggregate接收多个值并返回单个(聚合)值。与aggregate不同,transform接收多个值,但返回的是与这些值一一对应的转换值,即transform方法不会减少数据量。
(1)计算z分数
z分数能如实反映一个给定分数距离平均数的标准差。它的中心0,标准差是1.这种方法能把数据标准化,便于比较不同变量。
x为数据集中的数据点。
μ为数据集的平均值。
σ是标准差。
# 导入库
import pandas as pd
# 导入数据集
df=pd.read_csv(r"...\data\gapminder.tsv",sep='\t')
# zscore转换方法一
# 创建自定义函数
def my_zscore(x):
"""
计算给定数据的z分数,
是一个向量或值序列
"""
return (x-x.mean())/x.std()
# 使用此自定义函数按组转换数据
transform_z=df.groupby('year').lifeExp.transform(my_zscore)
# 请注意,原DataFrame和transform_z的行数和数据的数量相同
# 输出数据的函数
print(df.shape)
# 输出转换之后值得个数
print(transform_z.size)
print(transform_z.shape)
# zscore转换方法二
# 使用scipy库中的zscore
# 从scipy.stats 导入zscore函数
from scipy.stats import zscore
# 计算分组的zscore
sp_z_grouped=df.groupby('year').lifeExp.transform(zscore)
# 两种方式获得的z分值略有差异,但均可用
# 输出transform_z的z分值
print(transform_z.head())
# 输出sp_z_grouped的z分值
print(sp_z_grouped.head())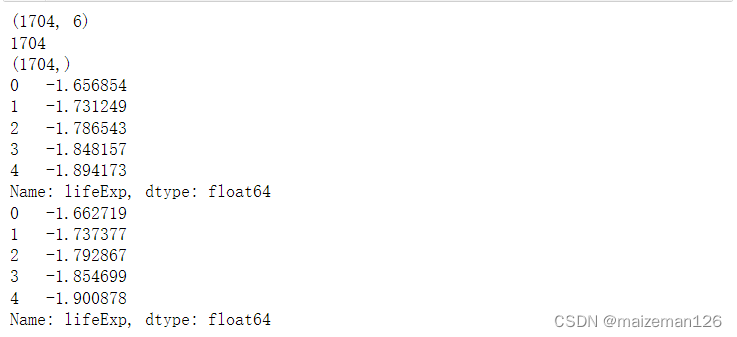
(2)缺失值填充
可以根据python数据分析——缺失数据-CSDN博客中的fillna方法对缺失数据进行填充。对于某些数据集,使用列的平均值来填充缺失值是可取的。而对于另一些数据集,根据特定组填充数据可能更好。
# 导入numpy库
import numpy as np
# 设置随机种子
np.random.seed(42)
# 读入数据
tips=pd.read_csv(r"...\seaborn常用数据案例\tips.csv")
# 从tips中抽取10个
tips_10=tips.sample(10)
# 随机挑选4个‘total_bill’创制缺失值
tips_10.loc[np.random.permutation(tips_10.index)[:4],'total_bill']=np.nan
print(tips_10)
# 查看缺失值数量
# 按sex统计非缺失值的数量
count_sex=tips_10.groupby('sex').count()
print(count_sex)
# 自定义函数
def fill_na_mean(x):
"""
返回向量,将原向量的缺失值填充为向量的均值
"""
avg=x.mean()
return (x.fillna(avg))
# 按sex计算total_bill平均值
total_bill_group_mean=tips_10.\
groupby('sex').\
total_bill.\
transform(fill_na_mean)
# 可以在原始数据中创建新列
# 也可以直接使用total_bill替换原始列
tips_10['fill_total_bill']=total_bill_group_mean
print(tips_10)2、过滤器
使用groupby方法还可以过来数据。它支持按键拆分数据,然后对数据执行某种布尔子集运算。
# 使用tips数据
# 查看原始数据的行数
print(tips.shape)
# 查看不同规模聚餐的次数
print(tips['size'].value_counts())
# 在分组运算的基础上使用filter方法实现数据的过滤
# 过滤数据,保留每组包含30个或更多观测值的组
tips_filtered=tips.groupby('size').filter(lambda x: x['size'].count()>=30)
print(tips_filtered.shape)
print(tips_filtered['size'].value_counts())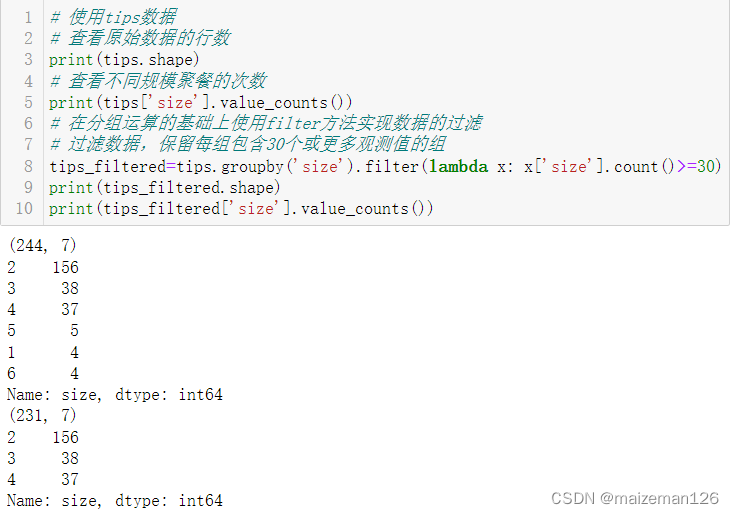















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









