







今天呢,要感谢一位小姐姐,她的笔记帮助我理解了KMP算法。
那什么是KMP算法呢?
KMP算法是在BF算法上进行了优化,KMP算法的初衷是为了消除重复的比较,提高效率。
举个例子:
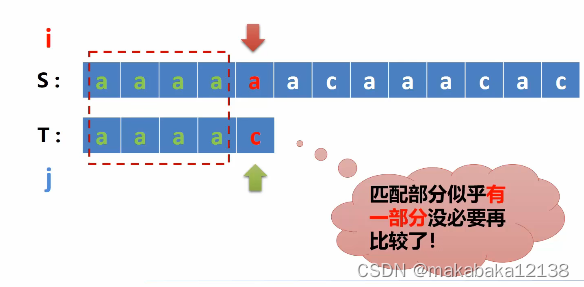
从S串中找到与T串符合的,仔细观察发现,T串前四个都是a,然后从S串查找的时候,也发现了四个a的情况,这个时候,不同BF算法,BF算法会立刻回溯主指针。而KMP算法,在匹配过程中出现字符比较不等的时候,不回溯主指针,而是利用已得到的不匹配的结果,将字串滑动尽可能远的一部分距离,继续进行比较。用图给大家解释一下。
用图解释之前,这里要介绍几个知识点:
前缀:指除了最后一个字符外,一个字符串的全部头部组合,从第一个字母开始组合
后缀:除了第一个字符外,一个字符串的全部尾部组合,从最后一个字母开始组合
最大共有长度:很重要,用来决定移动的距离,前缀和后缀的最长匹配
最大共有长度怎么算呢?
举个例子:以串 aaaac举例
a 前缀:0(解释:除了最后一个字符外,没有其他字符,无法组合) 后缀:0(除了第一个字符外,没有其他字符组合) ,所以最大共有长度为 0
aa 前缀:(解释:除了最后一个字符a,其他字符组合a) 后缀:0(除了第一个字符a,其他字符组合:a),所以前缀和后缀的交集就是a 最大共有长度就是1
aaa 前缀:(解释:除了最后一个字符a,其他字符组合:a,aa) 后缀:0(除了第一个字符a,其他字符,a,aa),所以最大共有长度就是 2
aaaa 前缀:0(解释:除了最后一个字符a,其他字符组合a,aa,aaa) 后缀:0(除了第一个字符a,其他字符组合a,aa,aaa),所以最大共有长度就是 :3
aaaac 前缀:0(解释:除了最后一个字符c,其他字符组合a,aa,aaa,aaaa) 后缀:0(除了第一个字符a,其他字符组合c,ac,aac,aaac).最大共有长度就是 0
所以字串 aaaac的最大共有长度就是:3,用KMP算法时,字串移动三格就行。
上面的步骤呢,我们用一个算法实现,然后记录到部分匹配表里面:
算法用来找到最大共有长度:

next数组就是部分匹配表。


接下来实现KMP算法:
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 255
typedef struct HString
{
char zfc[MAX_SIZE];
int length;
}HString;
//返回next数组(部分匹配表)
void Get_Next(HString child,int *next);
//KMP,返回字串在主串中的位置 pos是开始位置,不是开始下标
int KMPCompare(HString* parents,HString* child,int pos);
int main(void)
{
HString parents = {"aaaaaacaaacac",13};
HString child = {"aaaac",5};
printf("KMP查询的匹配位置是:%d",KMPCompare(&parents,&child,1));
return 0;
}
//返回next数组(部分匹配表)
void Get_Next(HString child,int *next)
{
int i = 0;
int j = -1;
next[0] = -1;
while(i<child.length)
{
if(j == -1 ||child.zfc[i]==child.zfc[j])
{
i++;
j++;
next[i] = j;
}
else
{
j = next[j];
}
}
}
//KMP,返回字串在主串中的位置
int KMPCompare(HString* parents,HString* child,int pos)
{
int next[MAX_SIZE];//这就是部分匹配表
Get_Next(*child,next);
int i = pos-1;
int j = 0;
while(i<parents->length && j < child->length)
{
if(j ==-1 ||parents->zfc[i] == child->zfc[j])
{
i++;
j++;
}
else
{
j = next[j]; //j回退的最大长度
}
}
if(j == child->length)
{
return (i+1)-j;
}
return 0;
}感谢这位小仙女姐姐的笔记

大家喜欢记得点个赞,点赞过三个,更新BF算法哦。















 5404
5404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









