







不记录过程的细节,只记录最直接的方法.如有问题请留言哦
Hadoop模式分为以下四类,本文介绍单机部署的方式
1、本地模式:
本地模式就是解压源码包,不需要做任何的配置。通常用于开发调试,或者感受hadoop。
2、伪分布模式:
在学习当中一般都是使用这种模式,伪分布模式就是在一台机器的多个进程运行多个模块。虽然每一个模块都有相应的进程,但是却还是运行在同一个系统里面。所以叫伪分布式。
3、完全分布式:
这种模式才是工作当中所用的模式,hadoop运行在多台机器上面,我们称之为hadoop集群。
4、HA:
在实际的工作当中,对于hadoop完全分布式来说,并不真正的可靠,因为hadoop完全分布式集群会有单点故障(namenode单点故障、yarn单点故障),所以一般都会对这个集群做HA,一般都是做namenode和yarn的高可用
首先必须要安装好Hadoop,可以参考Ubuntu下安装Hadoop
1.设置好本地ssh访问不需要密码
因为Hadoop启动的时候会通过ssh访问,不设置的话每次都要输入两次密码,很麻烦
先安装ssh
sudo apt-get install ssh | sudo apt-get install sshopen-server
生成key, -P是指指定密码 这里设置为’’,就是没有密码
输入后回车
ssh-keygen -t rsa -P ''
如果是root用户,就把公钥放到/root/.ssh/
如果是其他用户的话把公钥放到/home/用户/.ssh下
我这里是第二种情况,我的用户是ubuntu
cat /home/ubuntu/.ssh/id_rsa.pub >> authorized_keys
测试一下是否成功配置
ssh 你的本机名
ssh localhost
第一次输入他会提示你,输入yes回车就好了
Welcome to Ubuntu 16.04.5 LTS (GNU/Linux 4.4.0-130-generic x86_64)
2.Hadoop的core-site.xml
这是我hadoop的文件夹 /usr/lib/hadoop-2.7.7/,需要加上读写权限
vi /usr/lib/hadoop-2.7.7/etc/hadoop/core-site.xml
在文件最后一行输入
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/lib/hadoop-2.7.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop.tmp.dir指临时目录设定
fs.defaultFS指缺省的文件URI标识设定
3.Hadoop的hdfs-site.xml
vi /usr/lib/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
最后一行加入
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop-2.7.7/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop-2.7.7/data/data</value>
</property>
</configuration>
dfs.replication指块复制数量
dfs.namenode.name.dir指namenode存放数据的目录
dfs.datanode.data.dir指datanode存放数据的目录
4.Hadoop的mapred-site.xml
进入到Hadoop配置文件目录下,查看有没有mapred-site.xml
cd /usr/lib/hadoop-2.7.7/etc/hadoop/
如果没有,则把mapred-site.xml.template重命名成mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
修改文件
vi /usr/lib/hadoop-2.7.7/etc/hadoop/mapred-site.xml
然后在文件最后一行加入
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.Hadoop的yarn-site.xml
修改yarn.site.xml
vi /usr/lib/hadoop-2.7.7/etc/hadoop/yarn-site.xml
在最后一行加入
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.启动Hadoop
进入到Hadoop目录下的sbin目录,
cd /usr/lib/hadoop-2.7.7/sbin
启动Hadoop
start-all.sh

提示localhost:starting nodemanager,则启动成功了
jps
用jps 查看java进程
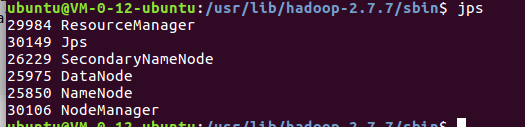
结束.















 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









