






本文章采用的Hadoop版本是3.1.3,可以到Hadoop官网下载安装文件(http://mirrors.cnnic.cn/apache/hadoop/common/)
前言
Hadoop包括三种安装模式:
- 单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
- 伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
- 分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
本章中只讲了前面两种“单机”和“伪分布式”,第三种“分布式”打算后续单独写一篇,因为这个也是搭建HADOOP的集群了,所以希望这些也能帮助到你们。这些内容素材也来自“林子雨教程”
一、下载安装文件
前提:下载好hadoop的3.1.3的安装包并用PTF传送到hadoop用户下的下载目录
![]()
1,请使用hadoop用户登录虚拟机,并打开一个终端,执行一下命令:
$ sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限
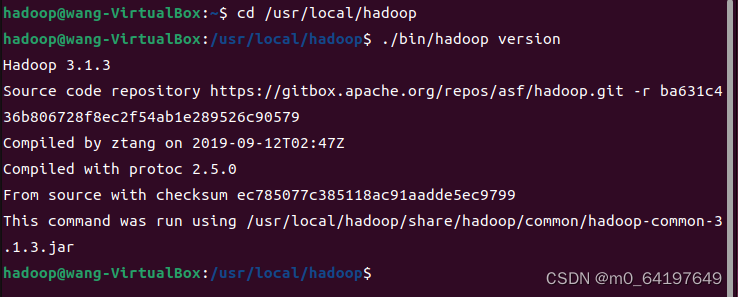
2,输入一下命令检测Hadoop解压是否可以用,成功会显示其版本:
$ cd /usr/local/hadoop
$ ./bin/hadoop version
二、单击模式匹配
1,Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。Hadoop附带了丰富的例子,运行如下命令可以查看所有例子:
代码如下(示例):
$ cd /usr/local/hadoop
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
2,这里选择运行grep例子:
$ cd /usr/local/hadoop
$ mkdir input
$ cp ./etc/hadoop/*.xml ./input # 将配置文件复制到input目录下
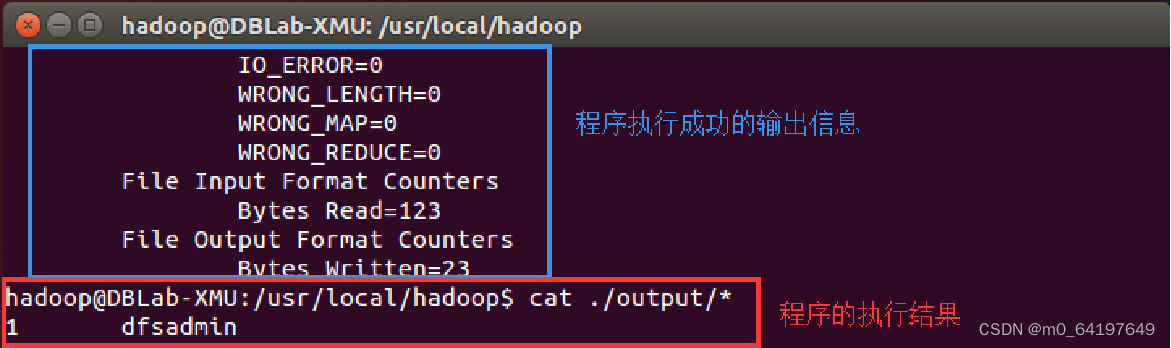
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
$ cat ./output/* # 查看运行结果
三、伪分布式模式匹配
1,修改配置文件(这两个文件在分布式模式匹配时也要修改)
这个两个文件的路径是在以下代码中:
$ cd ~
$ cd /usr/local/hadoop/etc/hadoop
修改以后,core-site.xml文件的内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样,需要修改配置文件hdfs-site.xml,修改后的内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
2,执行名称结点格式化
修改配置文件以后,要执行名称节点的格式化,命令如下:
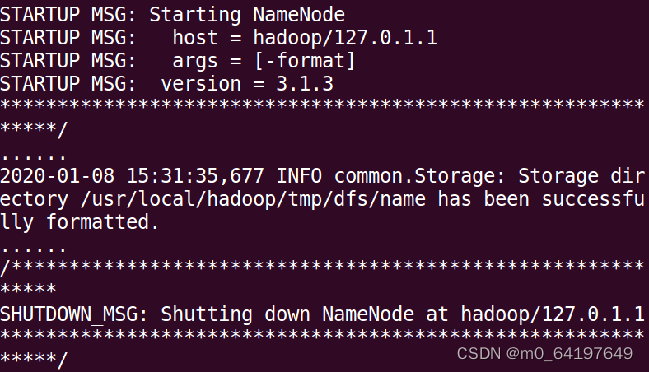
$ cd /usr/local/hadoop
$ ./bin/hdfs namenode -format
如果格式化成功,会看到“successfully formatted”的提示信息:
3,启动hadoop
执行下面命令启动Hadoop:
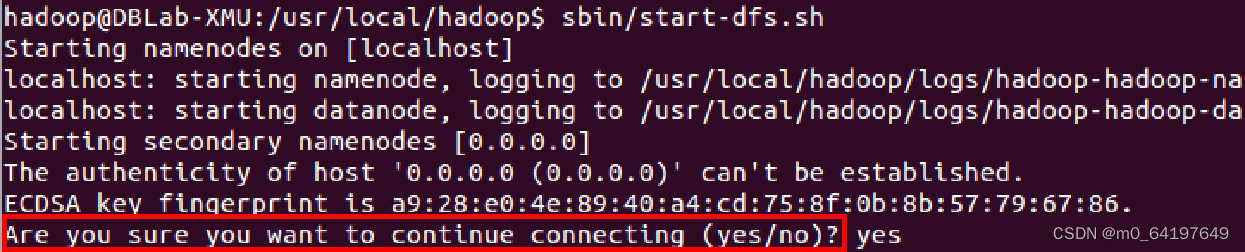
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格如果出现下图的SSH提示,输入yes即可:
4,运行Hadoop伪分布式实例
需要在HDFS中创建目录,在hadoop用户下进行:
$ cd /usr/local/hadoop
$ ./bin/hdfs dfs -mkdir -p /user/hadoop
需要把本地文件系统的“/usr/local/hadoop/etc/hadoop”目录中的所有xml文件作为输入文件,复制到分布式文件系统HDFS中的“/user/hadoop/input”目录中,命令如下:
$ cd /usr/local/hadoop
$ ./bin/hdfs dfs -mkdir input #在HDFS中创建hadoop用户对应的input目录
$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml input #把本地文件复制到HDFS中
实例如图所示:
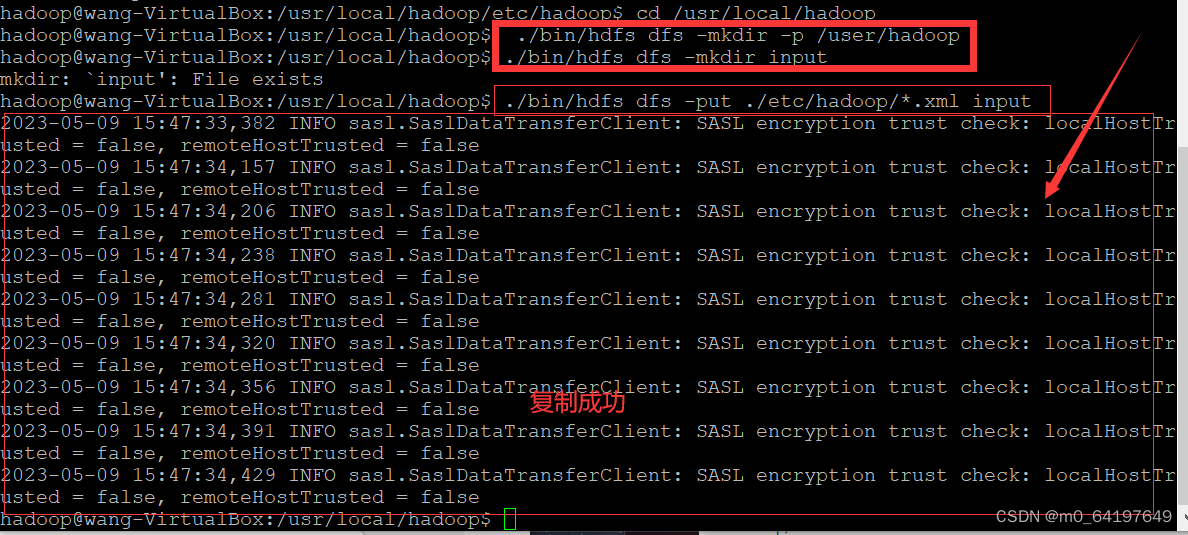
现在就可以运行Hadoop自带的grep程序,命令如下:
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
运行结束后,可以通过如下命令查看HDFS中的output文件夹中的内容:
$ ./bin/hdfs dfs -cat output/*
运行结果为:

5,关闭Hadoop
如果要关闭Hadoop,可以执行下面命令:
$ cd /usr/local/hadoop
$ ./sbin/stop-dfs.sh
6,配置PATH变量
首先使用vim编辑器打开“~/.bashrc”这个文件,然后,在这个文件最前面位置加入如下一行:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
然后执行命令
$source ~/.bashrc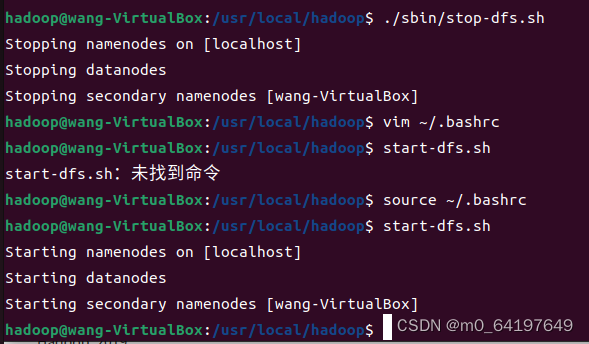
让配置生效。设置生效后,在任何目录下启动Hadoop,都只要直接输入start-dfs.sh命令即可,同理,停止Hadoop,也只需要在任何目录下输入stop-dfs.sh命令即可。















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









