







http://blog.csdn.net/wallwind/article/details/6996004
0前言
上周都在看都在学习unix环境高级编程的第八章——进程控制。也就是这一章中,让我理解了unix中一些进程的原理。下面我就主要按照进程中最重要的三个函数来进行讲解。让大家通过阅读这一篇文章彻底明白进程这点事。希望对大家有所帮助。
1进程环境
在学习进程之前,一定要了解一下unix的进程环境。系统如何对进程终止,和一个程序启动终止,程序运行的原理等,这些都有助于你理解进程的运行原理。这些内容都在我的上一篇文章中,请关注:http://blog.csdn.net/wallwind/article/details/6968323。文章中讲的较为详细。
2进程概念:
一个进程,主要包含三个元素:
a) 一个可以执行的程序;
b) 和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等);
c) 程序的执行上下文(execution context)。
不妨简单理解为,一个进程表示的,就是一个可执行程序的一次执行过程中的一个状态。操作系统对进程的管理,典型的情况,是通过进程表完成的。进程表中的每一个表项,记录的是当前操作系统中一个进程的情况。对于单 CPU的情况而言,每一特定时刻只有一个进程占用 CPU,但是系统中可能同时存在多个活动的(等待执行或继续执行的)进程。
3 fork()函数
fork()函数是进程的核心函数。当调用fork的时候,系统将创建一个新的进程,成为子进程(child process)。Fork函数定义形式如下:
- #include<unistd.h>
- Pid_t fork(void);//返回值:子进程返回0,父进程中返回子进程ID,出错则返回-1
从返回值我们可以看到,Fork函数调用了一次,但是返回两次。其区别在于在子进程中返回值是0,而父进程的返回值则是新子进程的进程ID.
上边的概念可能对初学者比较模糊,那么我们怎么理解fork呢?
当你看到fork的时候,你可以把fork理解成“分叉”,在分叉的同时,生成的一个子进程复制了父进程的基本是所有的东西,包括代码、数据和分配给进程的资源。也就是子进程几乎是和父进程是一模一样的。但是子进程可能会根据不同情况调用其他函数。比如exec函数。
下面我们用一个经典及比较典型简单的例子来看看。
- #include"apue.h"
- int glob=6;
- char buf[]="a write to stdout\n";
- int main(void)
- {
- int var=88;
- pid_t pid;
- if(write(STDOUT_FILENO,buf,sizeof(buf)-1)!=sizeof(buf)-1)
- printf("writeerror");
- printf("before fork with 换行符\n");
- printf("before fork without换行符");
- //printf("\n");
- if((pid=fork())<0){
- printf("fork error");
- }else if(pid==0){
- printf("I am is child process,pid=%d\n",getpid());
- printf("my parentprocess's pid=%d\n",getppid());
- glob++;
- var++;
- }else{
- printf("this is parentprocess,pid=%d\n",getpid());
- //var++;
- }
- printf("pid=%d,glob=%d,var=%d\n",getpid(),glob,var);
- exit(0);
- }
输出结果: 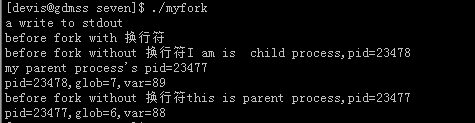
希望新手能够将以上代码自己敲一遍,然后自己运行一遍。
从上边的结果我们一步步分析。首先我们看到两行文字是只输出一遍的。
既”a write to stdout”
“Befork forkwhit h换行符”。
也就是只有一个进程执行这两个输出语句。我们先暂且不分析不带换行符的。
当程序调用fork的时候,这个时候程序就出现了一个进程,也就是两个进程在执行。
请看下边的简易图形
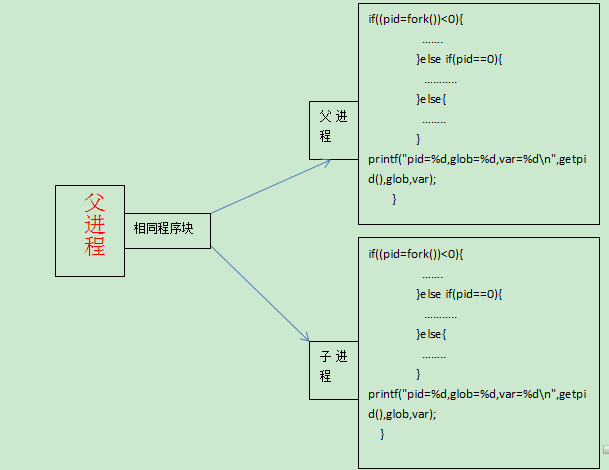
在上边我们已经讲过fork函数会因为不同调用返回不同的函数值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
现在我们看程序里的几个函数。Write函数是将buf内容写到标准流中。此处只作为输出用。
我们关心的是getpid()函数和getppid()函数。
getpid()函数是用来输出当前成进程的ID,getppid()则得到当前进程的父进程的ID,从输出结果比对可以看到,子进程得到的父ID和父进程得到自己的ID是相同的。
再来看一下全局变量glob,glob是函数外的变量。子进程将glob++处理,这个时候输出的是7,父进程没有进行处理直接输出6。我们可以知道,这两个glob变量显示是两份的。不相干的。
局部变量var也是同样的结果。。。。
现在我们来解释一下为什么
- printf("before fork with 换行符\n");
- printf("before fork without换行符");
上一句只输出了一次,而下边这句话就输出了两次。
我们可以发现printf("before fork with 换行符\n");这句带有\n既换行符的意思。而
- printf("before fork without换行符");
是没有带的。
这个我们要知道printf函数是有缓冲机制的,类似于我们使用的write函数,但我们将想要的东西输出的时候,系统仅仅是把内容放到stdout标准输出的缓冲队列的。当遇到“\n”的时候,系统就把缓冲里的东西给清掉,输出到屏幕上。
- printf("beforefork with 换行符\n");
执行后,缓冲里没有了数据,自然子进程再次执行的时候没有内容可输出了。但是printf("before fork without换行符");的时候,子进程也会把stdout的内容再次输出来。也就是导致了内容出处了两边。如果换一下书序的,结果是不一样的哦。
3 fork难度进阶
csdn看到一篇比较好的讲解fork的文章。较为深入的讲解。下面我就经过自己的调试和理解将呈现给大家。首先看一段代码:
- #include "apue.h"
- int main(void)
- {
- int i=0;
- pid_t pid;
- for(i=0;i<2;i++)
- {
- if((pid=fork())<0){
- printf("forkerror\n");
- }else if(pid==0){
- printf("%d,childself's pid=%d,parent's pid=%d,returnid=%d\n",i,getpid(),getppid(),pid);
- }else{
- printf("%d,parentself's pid=%d,parent's father's pid=%d,returnid=%d\n",i,getpid(),getppid(),pid);
- sleep(2);//inorder tochild output first
- }
- }
- exit(0);
- }
输出的结果为:
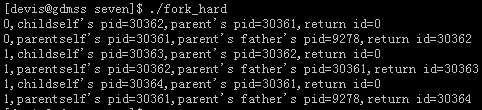
好好的分析一下我们的结果。0开始的输出为2行,1开头的输出4行。
然后我们开始观察PID的结果。从pid的结果我们找到一个关系
既9278-》30361-》30362-》30363
9278-》30361-》30364
要知道,fork函数子进程调用的时候返回0,而父进程调用的时候则返回子进程的ID。
程序运行第一步:
- if((pid=fork())<0){
- printf("forkerror\n");
- }else if(pid==0){
- printf("%d,childself's pid=%d,parent's pid=%d,returnid=%d\n",i,getpid(),getppid(),pid);
- }else{
- printf("%d,parentself's pid=%d,parent's father's pid=%d,returnid=%d\n",i,getpid(),getppid(),pid);
- sleep(2);//inorder tochild output first
- }
输出的结果为:
这是第一次循环输出输出的。
Childpid和return 均为父ID为30361生成的30361。
此时已经有了两个进程了。
进程ID分别为30362和30361。
第二次循环输出。
我们知道了此时两个进程30362和30361。这两个进程分别执行自己的代码。
ü 这个时候pid为30362的进程进行一次:
循环,得到结果为:
生成了一个子进程30363
ü 30361进程再次执行自己的代码,也就是上述循环的部分。

生成了一个子进程30364.
从程序和输出结果可以看到,其实我们的程序得到了6份的拷贝。
通过这个例子,fork了三次,产生了三个子进程,输出了6次,你可以深刻的理解了fork工作原理了。
再来一个例子:
这个是典型的循环例子:
- #include <unistd.h>
- #include<stdio.h>
- int main(void)
- {
- pid_t pid;
- int i=0;
- int c_cout=0;
- int p_cout=0;
- for(i=0;i<5;i++)
- {
- if((pid=fork())<0){
- printf("forkerror\n");
- }else if(pid==0){
- c_cout++;
- }else{
- p_cout++;
- }
- }
- printf("c_cout=%d,p_cout=%d,pid=%d\n",c_cout,p_cout,getpid());
- }
输出结果为:c_cout=5,p_cout=0,pid=1559
c_cout=4,p_cout=1,pid=1558
c_cout=4,p_cout=1,pid=1560
c_cout=3,p_cout=2,pid=1557
c_cout=4,p_cout=1,pid=1562
c_cout=3,p_cout=2,pid=1561
c_cout=4,p_cout=1,pid=1566
c_cout=3,p_cout=2,pid=1565
c_cout=3,p_cout=2,pid=1569
c_cout=2,p_cout=3,pid=1568
c_cout=4,p_cout=1,pid=1574
c_cout=3,p_cout=2,pid=1573
c_cout=3,p_cout=2,pid=1577
c_cout=2,p_cout=3,pid=1576
c_cout=3,p_cout=2,pid=1581
c_cout=2,p_cout=3,pid=1580
c_cout=2,p_cout=3,pid=1584
c_cout=1,p_cout=4,pid=1583
c_cout=3,p_cout=2,pid=1563
c_cout=2,p_cout=3,pid=1556
c_cout=2,p_cout=3,pid=1564
c_cout=2,p_cout=3,pid=1570
c_cout=1,p_cout=4,pid=1555
c_cout=3,p_cout=2,pid=1575
c_cout=2,p_cout=3,pid=1572
c_cout=2,p_cout=3,pid=1578
c_cout=1,p_cout=4,pid=1571
c_cout=2,p_cout=3,pid=1582
c_cout=1,p_cout=4,pid=1579
c_cout=1,p_cout=4,pid=1585
c_cout=0,p_cout=5,pid=1554
通过推理:引用网络文章可得到:
设f(n)表示程序中循环会执行n次时整个程序会产生的进程数,很容易得到递推公式:
f(n)=1+f(n-1)+f(n-2)+f(n-3)+…+f(0)
比如for i=0;i<N;I++< p>
因为i=0时fork()的子进程下次会继续循环n-1次,i=1时 fork()的子进程下次会仅需循环n-2 次。。。。
其中常数1是进程本身。
边界条件,f(0)=1
这样,我们就得到了问题的答案:
f(n)=1+f(n-1)+f(n-2)+…+f(0)
f(0)=1
这个可以求出闭形式:
f(0)=1
f(1)=2
f(2)=4
…
用数学归纳法可以得到f(n)=2^n
所以对于程序一,会打印出2^5-1=31行信息。
对于程序二,总共会产生2^5=32个进程。
不过,我还是不知道为什么两个变量的结果怎么是那种形式的输出,求指导啊!!!
下面贴一下比较有意思的一段代码:
- #include <stdio.h>
- #include <unistd.h>
- int main(int argc, char* argv[])
- {
- fork();
- fork() && fork() || fork();
- fork();
- return 0;
- }
我们要知道&& 和||运算符。&&有个短路现象。
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
通过画图我们可以得到如下
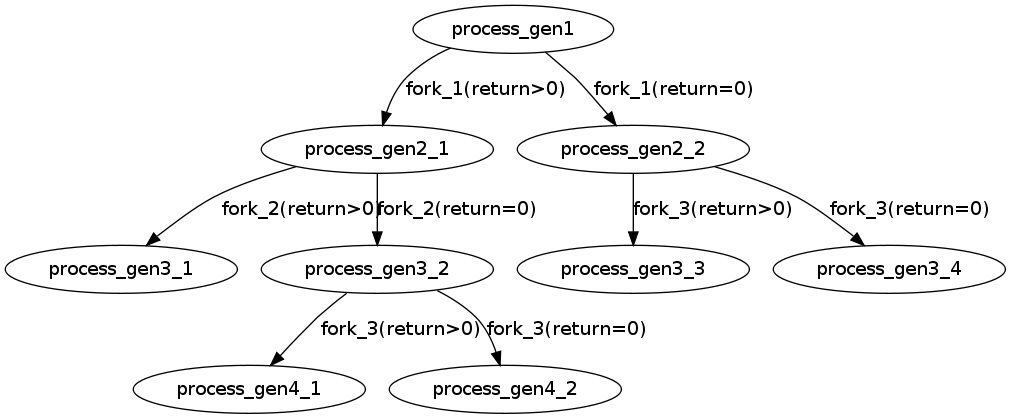
加上前面的fork和最后的fork,总共4*5=20个进程,除去main主进程,就是19个进程了。















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









