






1、创建内表,更sql其实是差不多的,只不过后面要声明根据什么标识符来区分你的字段,或者集合,举个栗子就懂了
我先创建一个表,声明他的字段和分割标识
> create table my_test(
> id int
> ,name string
> ,age int
> ,show_me string
> ,lovecity array<string>
> ,city_best map<String,string>
> ,luckeynumber array<int>
> ) //这是创建表
> row format delimited //行格式分隔
> fields terminated by ',' //字段分割
> collection items terminated by '/' //集合内部元素分割
> map keys terminated by ':' //map键值对分割
> ;上面我们就创建好了一张表,这个表是存在你使用的数据库里面 use xxx
接下来我们运用本地的文件,将文件的数据加载进表,其实Hive Load语句不会在加载数据的时候做任何转换工作,而是纯粹的把数据文件复制/移动到Hive表对应的地址。你load后会在hdfs的web页面找到你所加载的文件,内容是不有任何改变的,后面我们可以看看
我们先按照格式写一个txt文件
1,maketubu,24,i am maketubu!!,beijing/hangzhou/nanjing,beijing:top3/hangzhou:top1/nanjing:top2,7/22/99
2,hanmeimei,18,ni shi da ben dan!!,henan/shijiazhuang/hebei,henan:top1/shijiazhuang:top2/hebei:top3,8/88/888
3,lilei,20,wo jiu shi da ben dan la,chengdu/mianyang/taiwan,chengdu:top1/mianyang:top3/taiwan:top2,8/66/666先看看官方的load
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)]- filepath 可以是:
- 相对路径,如project/data1
- 绝对路径,如/user/hive/project/data1
- 完整的URL,如hdfs://namenode:9000/user/hive/project/data1
- 目标可以是一个表或是一个分区。如果目标表是分区表,必须指定是要加载到哪个分区。
- filepath 可以是一个文件,也可以是一个目录(会将目录下的所有文件都加载)。
- 如果命令中带LOCAL,表示:
- load命令从本地文件系统中加载数据,可以是相对路径,也可以是绝对路径。对于本地文件系统,也可以使用完整的URL,如file:///user/hive/project/data1
- load命令会根据指定的本地文件系统中的filepath复制文件到目标文件系统,然后再移到对应的表
- 如果命令中没有LOCAL,表示从HDFS加载文件,filepath可以使用完整的URL方式,或者使用fs.default.name定义的值
- 命令带OVERWRITE时加载数据之前会先清空目标表或分区中的内容,否则就是追加的方式。
- 如果命令中加了overwrite这个参数,那么你加载时,会把之前存在的数据先delete掉,在把新的数据放进去,如果不加,则会已追加的方式写入数据
现在我们把我们的数据load进去
load data local inpath '/opt/datas/my_test.txt' overwrite into table my_test;
load data local inpath '/opt/datas/my_test.txt' overwrite into table my_test;
Loading data to table test.my_test
Table test.my_test stats: [numFiles=1, numRows=0, totalSize=322, rawDataSize=0]
OK
Time taken: 1.981 seconds这时我们来查看这个表,这里没有对整齐(抱歉……^-^)
select *from my_test;
OK
1 maketubu 24 i am maketubu!! ["beijing","hangzhou","nanjing"] {"beijing":"top3","hangzhou":"top1","nanjing":"top2"} [7,22,99]
2 hanmeimei 18 ni shi da ben dan!! ["henan","shijiazhuang","hebei"] {"henan":"top1","shijiazhuang":"top2","hebei":"top3"} [8,88,888]
3 lilei 20 wo jiu shi da ben dan la!! ["chengdu","mianyang","taiwan"] {"chengdu":"top1","mianyang":"top3","taiwan":"top2"} [8,66,666]
Time taken: 0.604 seconds, Fetched: 3 row(s)
hive> 我们可以看到数据已经成功加进来了,这时我们去看看hdfs中的情况
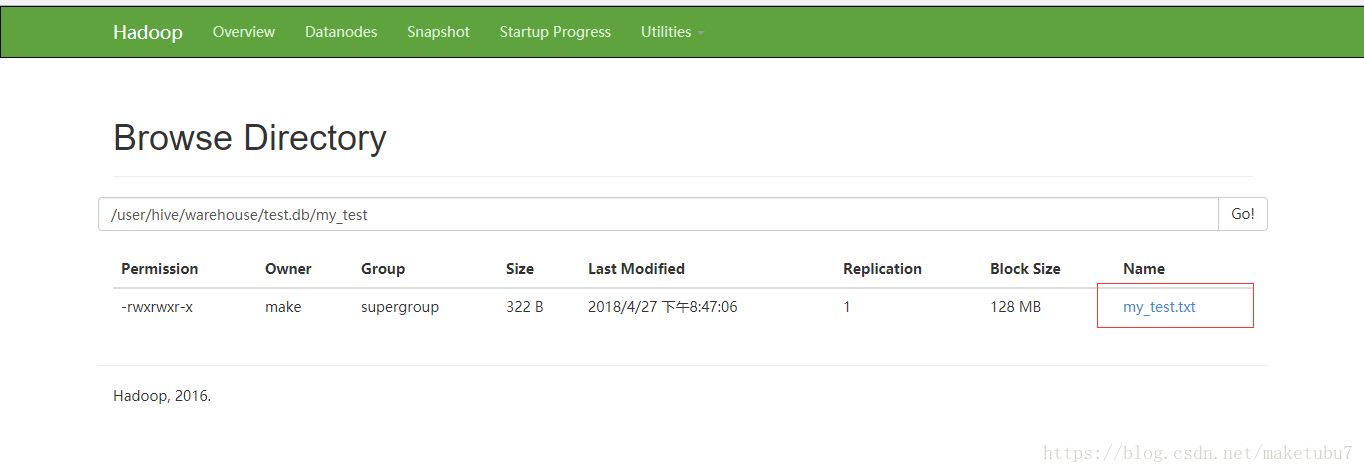
这就是把本地文件移动到了HDFS中而已,哈哈
、














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









