







 本文深入浅出地介绍了深度学习中注意力机制的原理,以机器翻译为例,探讨了其在自然语言处理、图像识别和语音识别中的应用。注意力机制借鉴了人类视觉注意力,通过选择性关注关键信息,提高处理效率。文章还讨论了Encoder-Decoder框架和Soft Attention模型,阐述了注意力模型的本质思想和Self Attention模型的作用。
本文深入浅出地介绍了深度学习中注意力机制的原理,以机器翻译为例,探讨了其在自然语言处理、图像识别和语音识别中的应用。注意力机制借鉴了人类视觉注意力,通过选择性关注关键信息,提高处理效率。文章还讨论了Encoder-Decoder框架和Soft Attention模型,阐述了注意力模型的本质思想和Self Attention模型的作用。
/* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/
张俊林
(本文2017年发表于《程序员》杂志7月刊)
(想更系统的学习深度学习知识?请参考:深度学习枕边书)
如果看图片有问题的同学可以到知乎看相同文章:深度学习中的注意力机制(2017版)
最近两年,注意力模型(Attention Model)被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。
本文以机器翻译为例,深入浅出地介绍了深度学习中注意力机制的原理及关键计算机制,同时也抽象出其本质思想,并介绍了注意力模型在图像及语音等领域的典型应用场景。
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
人类的视觉注意力
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
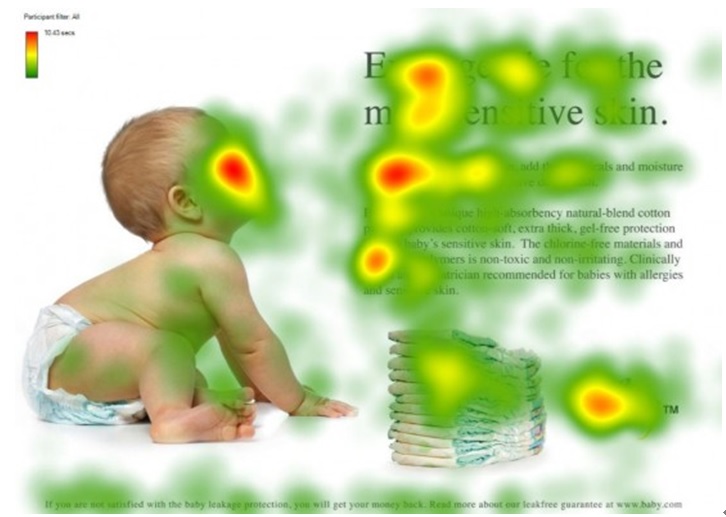
图1 人类的视觉注意力
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
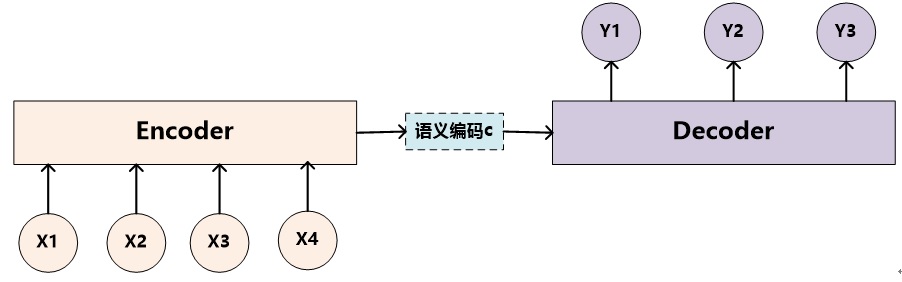
图2 抽象的文本处理领域的Encoder-Decoder框架
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
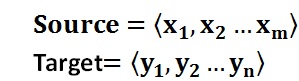
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
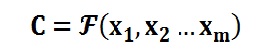
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息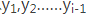
 :
:
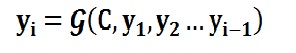
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









