







课程地址:https://class.coursera.org/ntumlone-001/class
课件讲义:http://download.csdn.net/download/malele4th/10208897
注明:文中图片来自《机器学习基石》课程和部分博客
建议:建议读者学习林轩田老师原课程,本文对原课程有自己的改动和理解
目录
Lecture 11 Linear Models for Classification
上一节课,我们介绍了Logistic Regression问题,建立cross-entropy error,并提出使用梯度下降算法gradient descnt来获得最好的logistic hypothesis。本节课继续介绍使用线性模型来解决分类问题。
Linear Models for Binary Classification
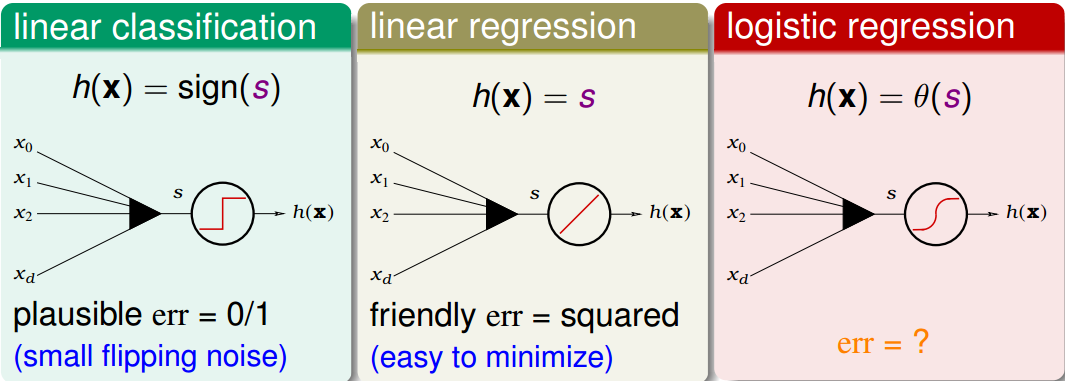

Stochastic Gradient Descent
Multiclass via Logistic Regression (one vs all)
之前我们一直讲的都是二分类问题,本节主要介绍多分类问题,通过linear classification来解决。假设平面上有四个类,分别是正方形、菱形、三角形和星形,如何进行分类模型的训练呢?
首先我们可以想到这样一个办法,就是先把正方形作为正类,其他三种形状都是负类,即把它当成一个二分类问题,通过linear classification模型进行训练,得出平面上某个图形是不是正方形,且只有{-1,+1}两种情况。然后再分别以菱形、三角形、星形为正类,进行二元分类。这样进行四次二分类之后,就完成了这个多分类问题。
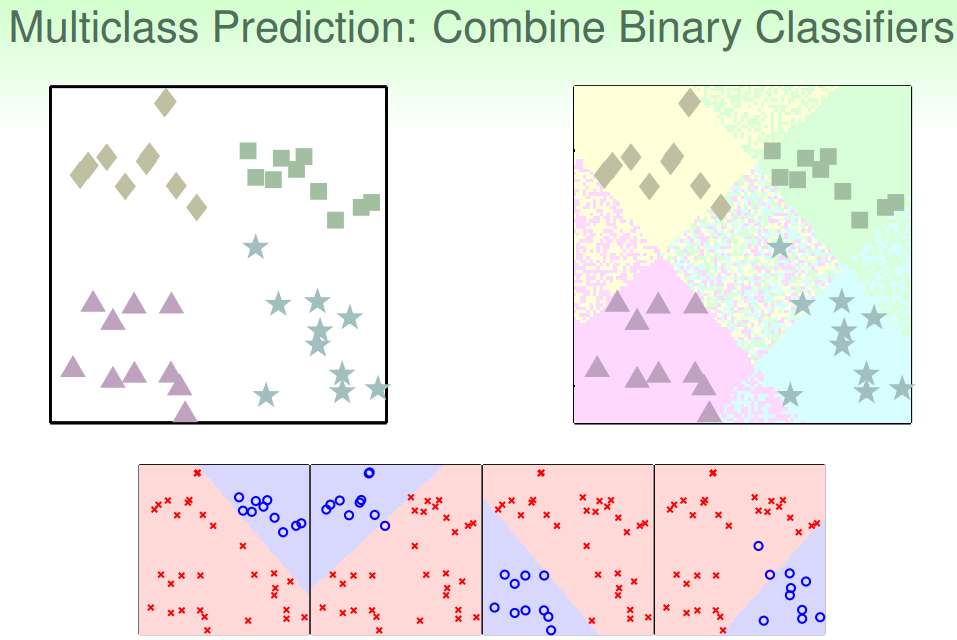
但是,这样的二分类会带来一些问题,因为我们只用{-1,+1}两个值来标记,那么平面上某些可能某些区域都被上述四次二分类模型判断为负类,即不属于四类中的任何一类;也可能会出现某些区域同时被两个类甚至多个类同时判断为正类,比如某个区域又判定为正方形又判定为菱形。那么对于这种情况,我们就无法进行多类别的准确判断,所以对于多类别,简单的binary classification不能解决问题。
针对这种问题,我们可以使用另外一种方法来解决:soft软性分类,即不用{-1,+1}这种binary classification,而是使用logistic regression,计算某点属于某类的概率、可能性,去概率最大的值为那一类就好。
soft classification的处理过程和之前类似,同样是分别令某类为正,其他三类为负,不同的是得到的是概率值,而不是{-1,+1}。最后得到某点分别属于四类的概率,取最大概率对应的哪一个类别就好。效果如下图所示:
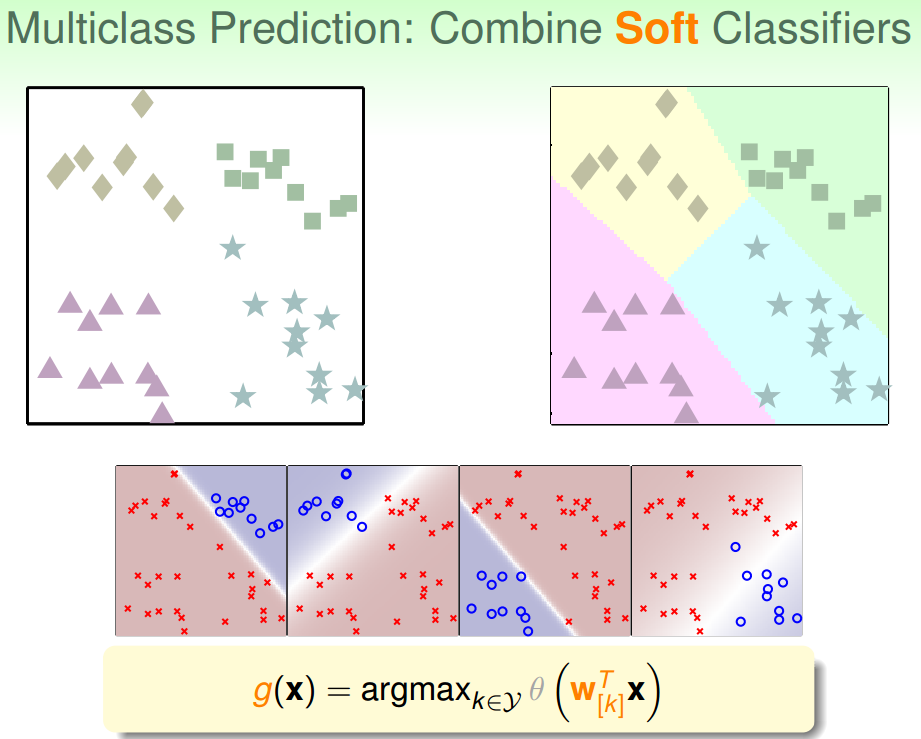
这种多分类的处理方式,我们称之为One-Versus-All(OVA) Decomposition。这种方法的优点是简单高效,可以使用logistic regression模型来解决;缺点是如果数据类别很多时,那么每次二分类问题中,正类和负类的数量差别就很大,数据不平衡unbalanced,这样会影响分类效果。但是,OVA还是非常常用的一种多分类算法。
Multiclass via Binary Classification (one vs one)
上一节,我们介绍了多分类算法OVA,但是这种方法存在一个问题,就是当类别k很多的时候,造成正负类数据unbalanced,会影响分类效果,表现不好。现在,我们介绍另一种方法来解决当k很大时,OVA带来的问题。
这种方法呢,每次只取两类进行binary classification,取值为{-1,+1}。假如k=4,那么总共需要进行
C24=6
次binary classification。那么,六次分类之后,如果平面有个点,有三个分类器判断它是正方形,一个分类器判断是菱形,另外两个判断是三角形,那么取最多的那个,即判断它属于正方形,我们的分类就完成了。这种形式就如同k个足球对进行单循环的比赛,每场比赛都有一个队赢,一个队输,赢了得1分,输了得0分。那么总共进行了
C2k
次的比赛,最终取得分最高的那个队就可以了。
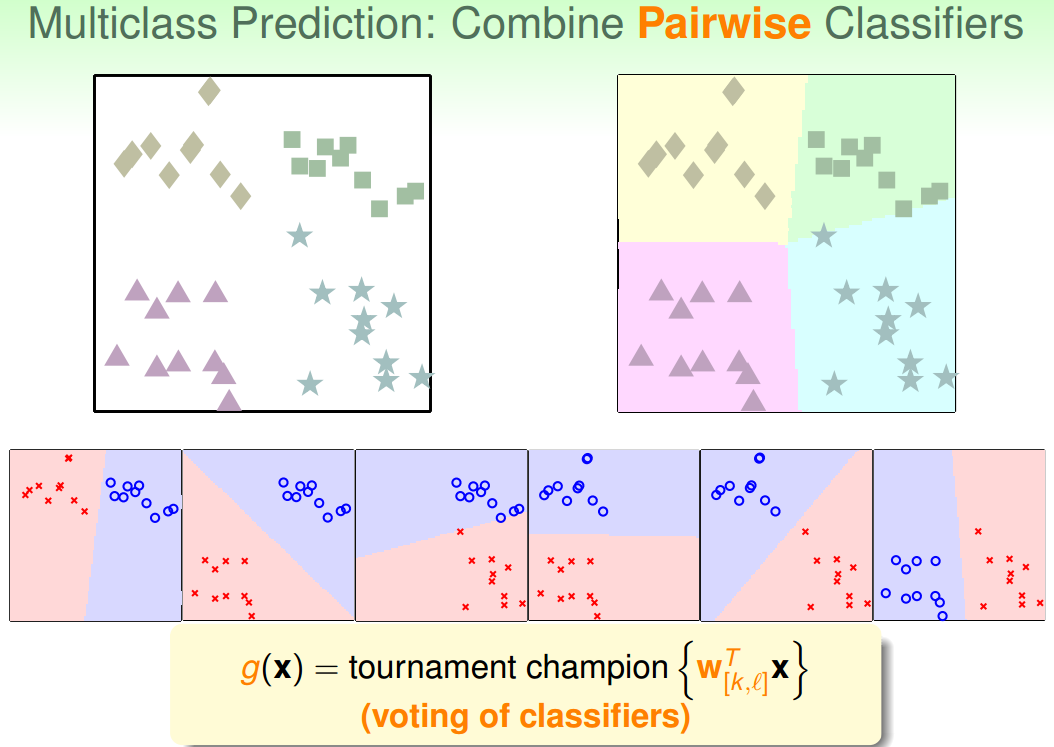
这种区别于OVA的多分类方法叫做One-Versus-One(OVO)。这种方法的优点是更加高效,因为虽然需要进行的分类次数增加了,但是每次只需要进行两个类别的比较,也就是说单次分类的数量减少了。而且一般不会出现数据unbalanced的情况。缺点是需要分类的次数多,时间复杂度和空间复杂度可能都比较高。
总结
本节课主要介绍了分类问题的三种线性模型:linear classification、linear regression和logistic regression。首先介绍了这三种linear models都可以来做binary classification。然后介绍了比梯度下降算法更加高效的SGD算法来进行logistic regression分析。最后讲解了两种多分类方法,一种是OVA,另一种是OVO。这两种方法各有优缺点,当类别数量k不多的时候,建议选择OVA,以减少分类次数。
Lecture 12 Nonlinear Transformation
Quadratic Hypothesis(二次假设)
之前介绍的线性模型,在2D平面上是一条直线,在3D空间中是一个平面。数学上,我们用线性得分函数s来表示: s=wTx 。其中,x为特征值向量,w为权重,s是线性的。
线性模型的优点就是,它的VC Dimension比较小,保证了Ein≈Eout。但是缺点也很明显,对某些非线性问题,可能会造成Ein很大,虽然Ein≈Eout,但是也造成Eout很大,分类效果不佳。

为了解决线性模型的缺点,我们可以使用非线性模型来进行分类。例如数据集D不是线性可分的,而是圆形可分的,圆形内部是正类,外面是负类。假设它的hypotheses可以写成:
基于这种非线性思想,我们之前讨论的PLA、Regression问题都可以有非线性的形式进行求解。
Nonlinear Transform
上一部分我们定义了什么了二次hypothesis,那么这部分将介绍如何设计一个好的二次hypothesis来达到良好的分类效果。那么目标就是在z域中设计一个最佳的分类线。
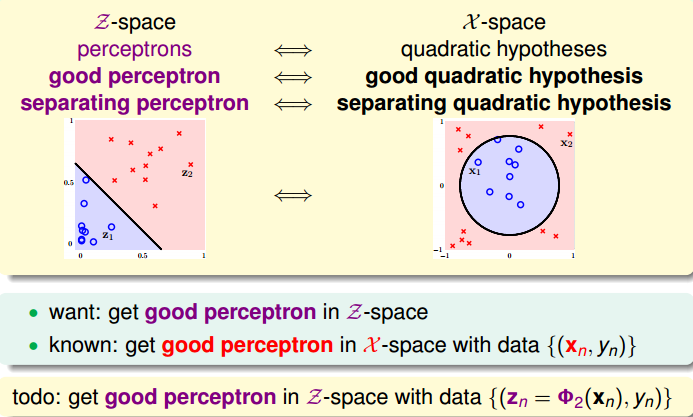
其实,做法很简单,利用映射变换的思想,通过映射关系,把x域中的最高阶二次的多项式转换为z域中的一次向量,也就是从quardratic hypothesis转换成了perceptrons问题。用z值代替x多项式,其中向量z的个数与x域中x多项式的个数一致(包含常数项)。这样就可以在z域中利用线性分类模型进行分类训练。训练好的线性模型之后,再将z替换为x的多项式就可以了。具体过程如下:
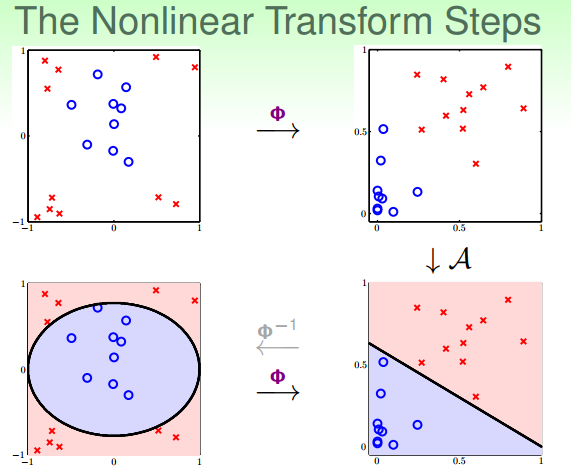
整个过程就是通过映射关系,换个空间去做线性分类,重点包括两个:
特征转换
训练线性模型
计算z域特征维度个数的时间复杂度是Q的d次方,随着Q和d的增大,计算量会变得很大。同时,空间复杂度也大。也就是说,这种特征变换的一个代价是计算的时间、空间复杂度都比较大。
另一方面,z域中特征个数随着Q和d增加变得很大,同时权重w也会增大,即自由度增加,VC Dimension增大。VC Dimension过大,模型的泛化能力会比较差。
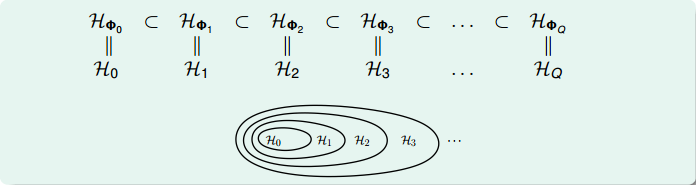
Structured Hypothesis Sets

总结
这节课主要介绍了非线性分类模型,通过非线性变换,将非线性模型映射到另一个空间,转换为线性模型,再来进行线性分类。本节课完整介绍了非线性变换的整体流程,以及非线性变换可能会带来的一些问题:时间复杂度和空间复杂度的增加。最后介绍了在要付出代价的情况下,使用非线性变换的最安全的做法,尽可能使用简单的模型,而不是模型越复杂越好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









