







探究算法细节,深入了解算法原理
LightGBM参考资料
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree(论文原文,NIPS@2017,微软)
- LightGBM英文文档
- LightGBM中文文档
- LightGBM github
- LightGBM github 中文
1. 提出LightGBM的动机
1.1 GBDT的应用
- GBDT是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。
- GBDT在工业界应用广泛,通常被用于点击率预测,搜索排序等任务。
- GBDT也是各种数据挖掘竞赛的致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。
1.2 GBDT的缺点
- GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。
- 如果把整个训练数据装进内存则会限制训练数据的大小;
- 如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
- 尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
1.3 XGBoost的缺点
(1)XGBoost是基于预排序的方法
- 对所有特征都按照特征的数值进行预排序
- 在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。
- 预排序算法的优点:能精确地找到分割点。
(2)预排序的缺点:
- 空间消耗大。保存数据的特征值、排序结果(排序后的索引,为了后续快速的计算分割点),消耗训练数据两倍的内存。
- 时间开销大。遍历每个分割点的时候,都需要进行分裂增益的计算。
- 对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层生长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
1.4 LightGBM的优点
- 更快的训练速度
- 更低的内存消耗
- 更高的准确率
- 支持分布式,可以快速处理海量数据
2. LightGBM做的优化
- 基于Histogram的决策树算法
- 带深度限制的Leaf-wise的叶子生长策略
- 直方图做差加速
- 支持类别特征
- Cache命中率优化
- 基于直方图的稀疏特征多线程优化
2.1 Histogram算法
直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数(其实是分桶的思想,这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。
- 在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量
- 当遍历一次数据后,直方图累积了需要的统计量
- 然后根据直方图的离散值,遍历寻找最优的分割点。
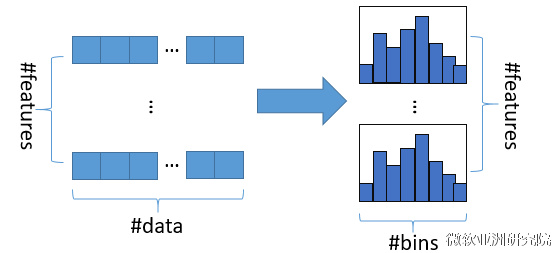
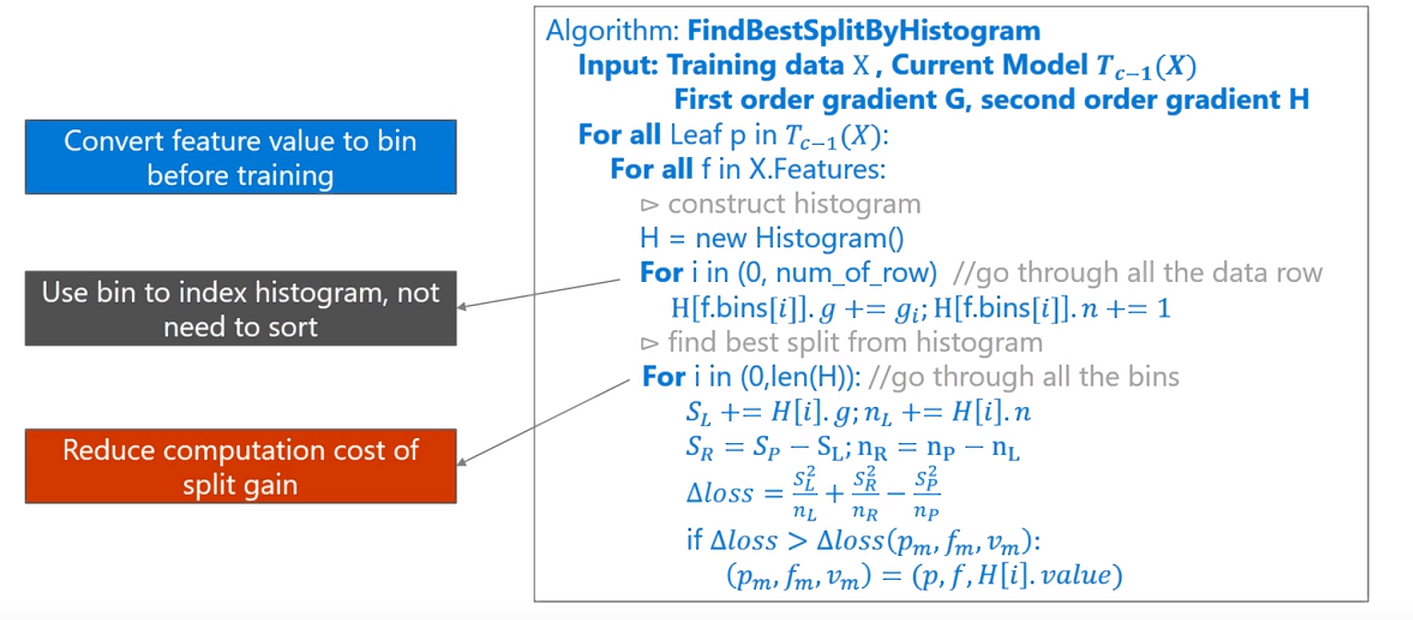
直方图算法的优点:
- 降低消耗的内存:不需要存储预排序的结果。只保存特征离散化后的值,而且一般用整型存储就够了,不再需要浮点类型。
- 降低计算复杂度:预排序O(#data*#feature),直方图O(#bin*#feature)
直方图算法的缺点(也是它的优点):
- 特征离散化后,分割点不精确。但实验表明影响并不大,甚至效果会更好一点。
- 较粗的分割点也有正则化的效果,可以防止过拟合
2.2 带深度限制的Leaf-wise的叶子生长策略
(1)XGBoost 的层次生长策略,称为 Level-wise tree growth
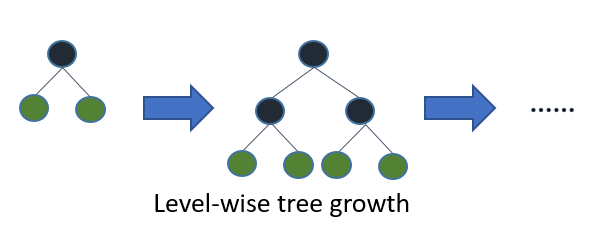
- 同一层的所有节点都做分裂
- 可以同时分裂同一层的叶子,容易多线程优化,也好控制模型复杂度,不容易过拟合
- 但算法低效,因为不加区分的对待同一层的叶子,带来了很多没必要的开销。
- 实际上很多叶子节点的分裂增益较低,没必要进行搜索和分裂。
(2)LightGBM 的带有深度限制的按叶子生长 (leaf-wise)策略

- Leaf-wise是一种更高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。
- 与Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
- Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
2.3 直方图差加速
现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟节点的直方图做差得到。
- 通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。
- 用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

2.4 数值型特征
和XGBoost是一样的
在得到叶子节点的输出后,给定输出的叶子节点分割增益(左右子树累加起来)为:
G j w j + 1 2 ( H j + λ ) w j 2 G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2 Gjwj+21(Hj+λ)wj2
XGBoost的分割增益如下:
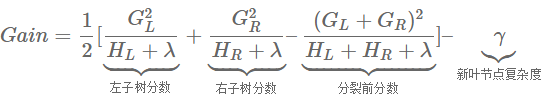
2.5 直接支持类别特征
- 实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征转化到多维的0/1特征,降低了空间和时间的效率。
- LightGBM 可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
- 相比0/1展开的方法,训练速度可以加速很多倍,并且精度一致。LightGBM是第一个直接支持类别特征的GBDT工具。
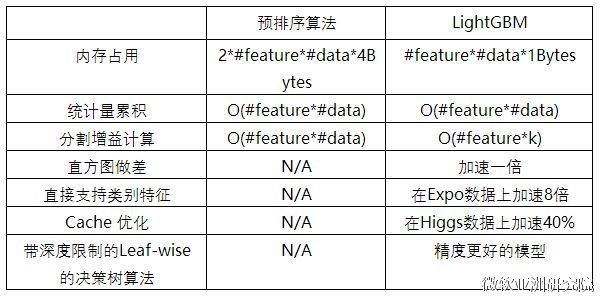
3. LightGBM的并行化
- 在特征并行中,在本地保存全部数据避免对数据切分结果的通信;
- 在数据并行中,使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
3.1 特征并行
特征并行:主要是并行化寻找最优分割点,这部分最耗时。
3.1.1 传统特征并行
传统特征并行方法:
- 垂直划分数据(对特征划分),不同的worker有不同的特征集
- 每个worker找到局部最佳的切分点{feature, threshold}
- worker使用点对点通信,找到全局最佳切分点
- 具有全局最佳切分点的worker进行节点分裂,然后广播切分后的结果(左右子树的实例索引)
- 其它worker根据收到的实例索引也进行划分
传统并行缺点:
- 无法加速 split 的过程,复杂度为O(#data),当数据量大的时候效率不高
- 需要广播划分的结果,1条数据1bit的话,大约需要花费O(#data/8)
3.1.2 LightGBM特征并行
每个worker保存所有的数据集,这样找到全局最佳切分点后各个worker都可以自行划分,就不用进行广播划分结果,减小了网络通信量。过程如下:
- 每个worker找到局部最佳的切分点{feature, threshold}
- worker使用点对点通信,找到全局最佳切分点
- 每个worker根据全局全局最佳切分点进行节点分裂
但是这样仍然有缺点:
- split过程的复杂度仍是O(#data),当数据量大的时候效率不高
- 每个worker保存所有数据,存储代价高
3.2 数据并行
数据并行:让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上寻找最优分割点。
3.2.1 传统数据并行
传统数据并行方法:
- 水平切分数据,不同的worker拥有部分数据
- 每个worker根据本地数据构建局部直方图
- 合并所有的局部直方图得到全局直方图
- 根据全局直方图找到最优切分点并进行分裂
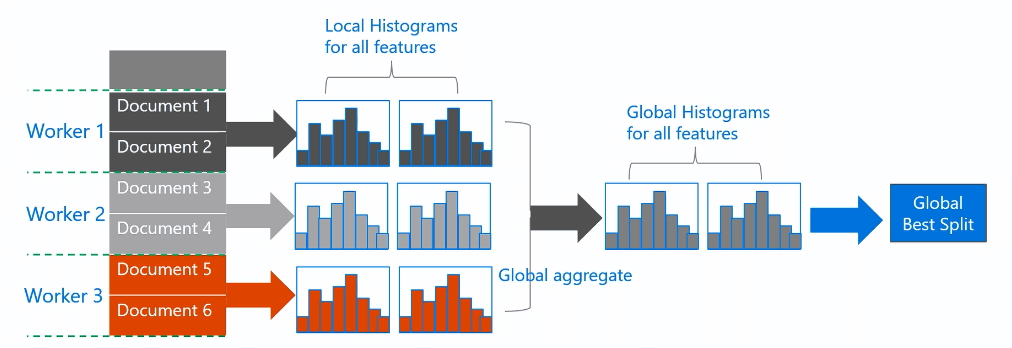
在第3步中,有两种合并方式:
-
采用点对点方式进行通讯,每个worker通讯量为O(#machine∗#feature∗#bin)
-
采用collective communication algorithm进行通讯(相当于有一个中心节点,通讯后在返回结果),每个worker的通讯量为O(2∗#feature∗#bin)
可以看出通信的代价是很高的,这也是数据并行的缺点。
3.2.2 LightGBM数据并行
- 使用“Reduce Scatter”将不同worker的不同特征的直方图合并,然后workers在局部合并的直方图中找到局部最优划分,最后同步全局最优划分。
- 通过直方图作差法得到兄弟节点的直方图,只需要通信一个节点的直方图。
通过上述两点做法,通信开销降为O(0.5∗#feature∗#bin)
3.3 LightGBM投票并行
LightGBM采用一种称为PV-Tree的算法进行投票并行(Voting Parallel),本质上也是一种数据并行。
PV-Tree和普通的决策树差不多,只是在寻找最优切分点上有所不同。
- ①水平切分数据,不同的worker拥有部分数据。
- ②Local voting: 每个worker构建直方图,找到top-k个最优的本地划分特征
- ③Global voting: 中心节点聚合得到最优的top-2k个全局划分特征(top-2k是对各个worker选择特征的个数进行计数,取最多的2k个)
- ④Best Attribute Identification: 中心节点向worker收集这top-2k个特征的直方图,并进行合并,然后计算得到全局的最优划分
- ⑤中心节点将全局最优划分广播给所有的worker,worker进行本地划分。
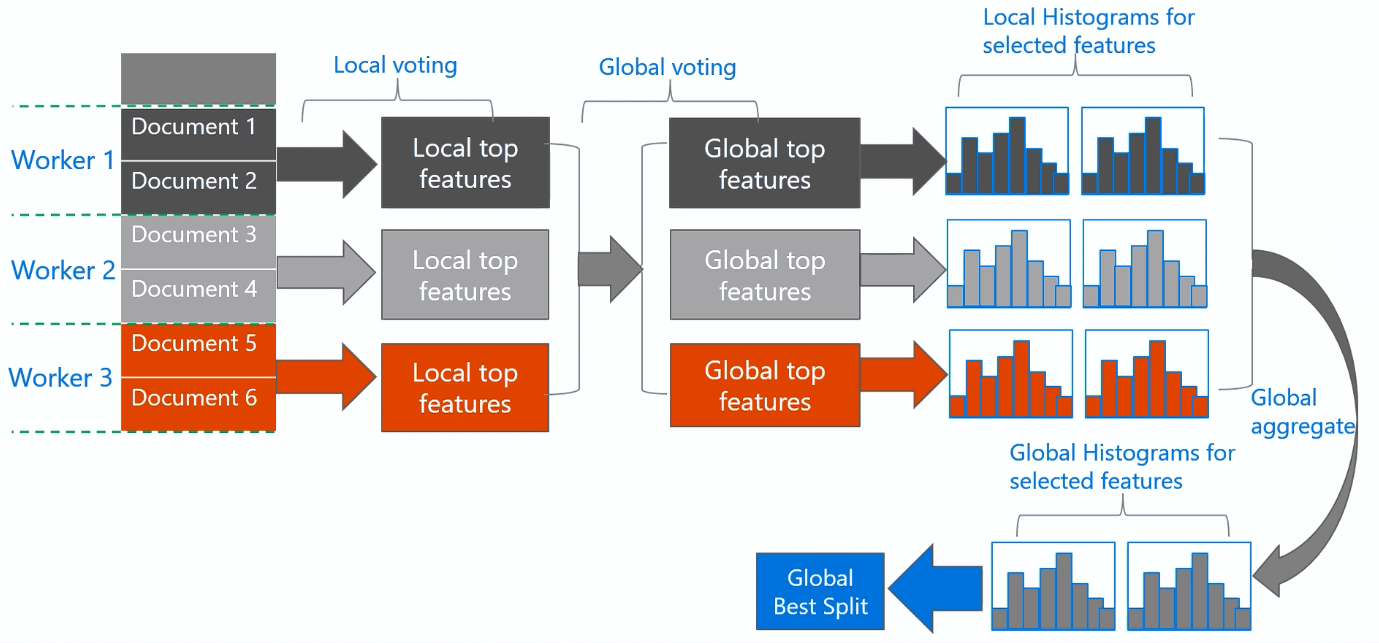
- PV-tree将#feature×#bin 变为了2k×#bin,通信开销得到降低。
- 当每个worker的数据足够多的时候,top-2k包含全局最佳切分点的概率非常高。
4. LightGBM论文原文解析
LightGBM: A Highly Efficient Gradient Boosting Decision Tree
4.1 Abstract
- 现有GBDT实现算法 XGBoost、pGBRT的缺点:当数据量很大,特征维度很高时,遍历每个特征的所有可能划分节点非常耗时。
- LightGBM提出两个新技术:Gradient-based One-side Sampling(GOSS,基于梯度的单边采样)、Exclusive Feature Bundling(EFB,互斥的特征捆绑)
- GOSS:排除小梯度的实例,只用剩下的实例来估计信息增益。
- EFB:捆绑互斥的特征(很少同时取非零值,如one-hot)来降低特征个数。捆绑互斥特征是NP难的,贪心策略求近似解。
4.2 Introduction
- GBDT算法复杂度受到数据量和特征量的影响,部分工作是根据样本权重采样来加速boosting的过程,但GBDT没有样本权重而不能应用。
- GOSS:GBDT虽然没有样本权重,但每个实例有不同的梯度,梯度大的实例对信息增益有更大的影响,下采样时,保留梯度大的样本,随机去掉梯度小的样本。
- EFB:将捆绑问题归约到图着色问题,贪心算法求近似解。
4.3 Preliminaries
- 学习决策树中找到最优切分点最消耗时间
- 预排序能精确找出最优分割点:训练速度和内存消耗上效率低
- 基于直方图:将连续的特征值抽象成离散的分箱,构建特征直方图,训练速度和内存消耗都更高效
- 直方图寻找最优切分点:建直方图消耗O(#data * #feature),寻找最优切分点消耗O(#bin * # feature),建直方图为主要时间消耗。(寻找最优切分点已经进行了优化,现在应该对建直方图进行优化)
4.4 GOSS and EFB
- GOSS是一种在减少数据量和保证精度上平衡的算法。
- 采样增加了弱学习器的多样性,潜在的提高了泛化性能。
- EFB介绍如何有效减少特征的数量
5. LightGBM调参
XGBoost有三类参数:通用参数、学习目标参数、Booster参数
LightGBM:核心参数、学习控制参数、IO参数、目标参数、度量参数、网络参数、GPU参数、模型参数。其中比较重要的是【核心参数、学习控制参数、度量参数】
5.1 核心参数
- boosting:可选gbdt,rf等
- num_thread
- application:可选 regression,binary,multi-class,lambdarank等
- learning_rate:shrinkage_rate
- num_leaves:默认31,一颗树上的叶子节点数
- num_iterations
- device:可选cpu,gpu
5.2 学习控制参数
- max_depth
- feature_fraction:也称sub_feature,colsample_bytree
- bagging_fraction:也称sub_row,subsample
- early_stopping_round
- min_data_in_leaf:默认20,一个叶子节点上数据的最小数量,用于防止过拟合
- min_gain_to_split
- max_bin:默认255,最大直方图数,越大越容易过拟合
5.3 LightGBM原生接口
import json
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
iris = load_iris()
data=iris.data
target = iris.target
X_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 一棵树的叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征采样比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # 每k次迭代执行bagging
}
# 训练 cv and train
gbm = lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5)
gbm.save_model('model.txt')
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
网格搜索:
parameters = {
'max_depth': [15, 20, 25, 30, 35],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'feature_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_freq': [2, 4, 5, 6, 8],
'lambda_l1': [0, 0.1, 0.4, 0.5, 0.6],
'lambda_l2': [0, 10, 15, 35, 40],
'cat_smooth': [1, 10, 15, 20, 35]
}
gbm = lgb.LGBMClassifier(boosting_type='gbdt',
objective = 'binary',
metric = 'auc',
verbose = 0,
learning_rate = 0.01,
num_leaves = 35,
feature_fraction=0.8,
bagging_fraction= 0.9,
bagging_freq= 8,
lambda_l1= 0.6,
lambda_l2= 0)
gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='accuracy', cv=3)
gsearch.fit(train_x, train_y)
print("Best score: %0.3f" % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
5.4 LightGBM调参核心
- 提高准确率:num_leaves,max_depth,learning_rate
- 降低过拟合:max_bin,min_data_in_leaf
- 降低过拟合:正则化L1, L2
- 降低过拟合:数据抽样(行采样),特征采样(列抽样)
处理过拟合的方法
- 使用较小的 max_bin
- 使用较小的 num_leaves
- 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf
- 设置 bagging_fraction 和 bagging_freq 来使用 bagging
- 设置 feature_fraction 来使用特征抽样
- 使用更大的训练数据
- 使用 lambda_l1,lambda_l2 和 min_gain_to_split 来使用正则化
- 尝试 max_depth 来避免生成过深的树
5.5 LightGBM GridSearchCV调参步骤
LightGBM的调参过程和RF、GBDT类似,其基本流程如下:
- 首先选择较高的学习率,大概0.1附近,为了加快收敛速度。
- 对决策树基本参数调参
- 正则化参数调参
- 最后降低学习率,为了最后提高准确率
5.5.1 学习率和迭代次数
- 我们先把学习率先定一个较高的值,这里取 learning_rate = 0.1。其次确定估计器boosting/boost/boosting_type的类型,不过默认都会选gbdt。
- 迭代的次数,即残差树的数目,参数名为n_estimators/num_iterations/num_boost_round。先将该参数设成一个较大的数,然后在cv结果中查看最优的迭代次数
- 选择迭代次数前,需要给其他重要的参数一个初始值。
以下参数根据具体项目要求定:
'boosting_type'/'boosting': 'gbdt'
'objective': 'binary'
'metric': 'auc'
以下是某些参数选择的初始值:
'max_depth': 5 # 数据集不是很大,所以选择了一个适中的值,其实4-10都无所谓
'num_leaves': 30 # LightGBM是leaves_wise生长,官方说法是要小于2^max_depth
'subsample'/'bagging_fraction':0.8 # 数据采样
'colsample_bytree'/'feature_fraction': 0.8 # 特征采样
下面用LightGBM的cv函数确定迭代次数:
import pandas as pd
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.cross_validation import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1,
'num_leaves':30,
'max_depth': 5,
'subsample': 0.8,
'colsample_bytree': 0.8,
}
data_train = lgb.Dataset(X_train, y_train)
cv_results = lgb.cv(params, data_train, num_boost_round=1000,
nfold=5, stratified=False, shuffle=True,
metrics='auc',early_stopping_rounds=50,seed=0)
print('best n_estimators:', len(cv_results['auc-mean']))
print('best cv score:', pd.Series(cv_results['auc-mean']).max())
# 输出结果如下:
('best n_estimators:', 188)
('best cv score:', 0.99134716298085424)
根据以上结果,取n_estimators=188
5.5.2 确定 max_depth 和 num_leaves
这是提高精确度的最重要的参数。
这里我们引入sklearn里的GridSearchCV()函数进行搜索。
from sklearn.grid_search import GridSearchCV
params_test1={'max_depth': range(3,8,1), 'num_leaves':range(5, 100, 5)}
gsearch1 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.1, n_estimators=188, max_depth=6, bagging_fraction = 0.8,feature_fraction = 0.8),
param_grid = params_test1, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch1.fit(X_train,y_train)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
# 输出结果如下:
([mean: 0.99248, std: 0.01033, params: {'num_leaves': 5, 'max_depth': 3},
mean: 0.99227, std: 0.01013, params: {'num_leaves': 10, 'max_depth': 3},
mean: 0.99227, std: 0.01013, params: {'num_leaves': 15, 'max_depth': 3},
······
mean: 0.99331, std: 0.00775, params: {'num_leaves': 85, 'max_depth': 7},
mean: 0.99331, std: 0.00775, params: {'num_leaves': 90, 'max_depth': 7},
mean: 0.99331, std: 0.00775, params: {'num_leaves': 95, 'max_depth': 7}],
{'max_depth': 4, 'num_leaves': 10},
0.9943573667711598)
根据结果,取max_depth=4,num_leaves=10
5.5.3 确定 min_data_in_leaf 和 max_bin
params_test2={'max_bin': range(5,256,10), 'min_data_in_leaf':range(1,102,10)}
gsearch2 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.1, n_estimators=188, max_depth=4, num_leaves=10,bagging_fraction = 0.8,feature_fraction = 0.8),
param_grid = params_test2, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch2.fit(X_train,y_train)
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_
# 输出结果如下:
([mean: 0.98715, std: 0.01044, params: {'min_data_in_leaf': 1, 'max_bin': 5},
mean: 0.98809, std: 0.01095, params: {'min_data_in_leaf': 11, 'max_bin': 5},
mean: 0.98809, std: 0.00952, params: {'min_data_in_leaf': 21, 'max_bin': 5},
······
mean: 0.99363, std: 0.00812, params: {'min_data_in_leaf': 81, 'max_bin': 255},
mean: 0.99133, std: 0.00788, params: {'min_data_in_leaf': 91, 'max_bin': 255},
mean: 0.98882, std: 0.01223, params: {'min_data_in_leaf': 101, 'max_bin': 255}],
{'max_bin': 15, 'min_data_in_leaf': 51},
0.9952978056426331)
根据结果,取min_data_in_leaf=51,max_bin in=15
5.5.4 确定 feature_fraction、bagging_fraction、bagging_freq
params_test3={'feature_fraction': [0.6,0.7,0.8,0.9,1.0],
'bagging_fraction': [0.6,0.7,0.8,0.9,1.0],
'bagging_freq': range(0,81,10)
}
gsearch3 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.1, n_estimators=188, max_depth=4, num_leaves=10,max_bin=15,min_data_in_leaf=51),
param_grid = params_test3, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch3.fit(X_train,y_train)
gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_
# 输出结果如下:
([mean: 0.99467, std: 0.00710, params: {'bagging_freq': 0, 'bagging_fraction': 0.6, 'feature_fraction': 0.6},
mean: 0.99415, std: 0.00804, params: {'bagging_freq': 0, 'bagging_fraction': 0.6, 'feature_fraction': 0.7},
mean: 0.99530, std: 0.00722, params: {'bagging_freq': 0, 'bagging_fraction': 0.6, 'feature_fraction': 0.8},
······
mean: 0.99530, std: 0.00722, params: {'bagging_freq': 80, 'bagging_fraction': 1.0, 'feature_fraction': 0.8},
mean: 0.99383, std: 0.00731, params: {'bagging_freq': 80, 'bagging_fraction': 1.0, 'feature_fraction': 0.9},
mean: 0.99383, std: 0.00766, params: {'bagging_freq': 80, 'bagging_fraction': 1.0, 'feature_fraction': 1.0}],
{'bagging_fraction': 0.6, 'bagging_freq': 0, 'feature_fraction': 0.8},
0.9952978056426331)
5.5.5 确定 lambda_l1 和 lambda_l2
params_test4={'lambda_l1': [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0],
'lambda_l2': [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]
}
gsearch4 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.1, n_estimators=188, max_depth=4, num_leaves=10,max_bin=15,min_data_in_leaf=51,bagging_fraction=0.6,bagging_freq= 0, feature_fraction= 0.8),
param_grid = params_test4, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch4.fit(X_train,y_train)
gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_
# 输出结果如下:
([mean: 0.99530, std: 0.00722, params: {'lambda_l1': 1e-05, 'lambda_l2': 1e-05},
mean: 0.99415, std: 0.00804, params: {'lambda_l1': 1e-05, 'lambda_l2': 0.001},
mean: 0.99331, std: 0.00826, params: {'lambda_l1': 1e-05, 'lambda_l2': 0.1},
·····
mean: 0.99049, std: 0.01047, params: {'lambda_l1': 1.0, 'lambda_l2': 0.7},
mean: 0.99049, std: 0.01013, params: {'lambda_l1': 1.0, 'lambda_l2': 0.9},
mean: 0.99070, std: 0.01071, params: {'lambda_l1': 1.0, 'lambda_l2': 1.0}],
{'lambda_l1': 1e-05, 'lambda_l2': 1e-05},
0.9952978056426331)
5.5.6 确定 min_split_gain
params_test5={'min_split_gain':[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]}
gsearch5 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.1, n_estimators=188, max_depth=4, num_leaves=10,max_bin=15,min_data_in_leaf=51,bagging_fraction=0.6,bagging_freq= 0, feature_fraction= 0.8,
lambda_l1=1e-05,lambda_l2=1e-05),
param_grid = params_test5, scoring='roc_auc',cv=5,n_jobs=-1)
gsearch5.fit(X_train,y_train)
gsearch5.grid_scores_, gsearch5.best_params_, gsearch5.best_score_
# 输出结果如下:
([mean: 0.99530, std: 0.00722, params: {'min_split_gain': 0.0},
mean: 0.99415, std: 0.00810, params: {'min_split_gain': 0.1},
mean: 0.99394, std: 0.00898, params: {'min_split_gain': 0.2},
mean: 0.99373, std: 0.00918, params: {'min_split_gain': 0.3},
mean: 0.99404, std: 0.00845, params: {'min_split_gain': 0.4},
mean: 0.99300, std: 0.00958, params: {'min_split_gain': 0.5},
mean: 0.99258, std: 0.00960, params: {'min_split_gain': 0.6},
mean: 0.99227, std: 0.01071, params: {'min_split_gain': 0.7},
mean: 0.99342, std: 0.00872, params: {'min_split_gain': 0.8},
mean: 0.99206, std: 0.01062, params: {'min_split_gain': 0.9},
mean: 0.99206, std: 0.01064, params: {'min_split_gain': 1.0}],
{'min_split_gain': 0.0},
0.9952978056426331)
5.5.7 降低学习率,增加迭代次数,验证模型
model=lgb.LGBMClassifier(boosting_type='gbdt',
objective='binary',
metrics='auc',
learning_rate=0.01,
n_estimators=1000,
max_depth=4,
num_leaves=10,
max_bin=15,
min_data_in_leaf=51,
bagging_fraction=0.6,
bagging_freq= 0,
feature_fraction= 0.8,
lambda_l1=1e-05,
lambda_l2=1e-05,
min_split_gain=0)
model.fit(X_train,y_train)
y_pre=model.predict(X_test)
print("acc:",metrics.accuracy_score(y_test,y_pre))
print("auc:",metrics.roc_auc_score(y_test,y_pre))
# 输出结果如下:
('acc:', 0.97368421052631582)
('auc:', 0.9744363289933311)
而使用默认参数时,模型表现如下:
model=lgb.LGBMClassifier()
model.fit(X_train,y_train)
y_pre=model.predict(X_test)
print("acc:",metrics.accuracy_score(y_test,y_pre))
print("auc:",metrics.roc_auc_score(y_test,y_pre))
# 输出结果如下:
('acc:', 0.96491228070175439)
('auc:', 0.96379803112099083)
可以看出在准确率和AUC得分都有所提高。
参考博客
1. 如何通俗理解LightGBM-七月在线
2. Lightgbm源论文解析:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
3. LightGBM调参笔记
4. XGBoost和LightGBM的参数以及调参















 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









