







lecture 19:MapReduce、Hadoop、Spark
目录
1MapReduce分布式计算的框架
一些开源的软件项目提供了海量数据处理的解决方案,其中一个项目就是Hadoop,它采用Java语言编写,支持在大量机器上分布式处理数据。
Hadoop是MapReduce框架的一个免费开源实现


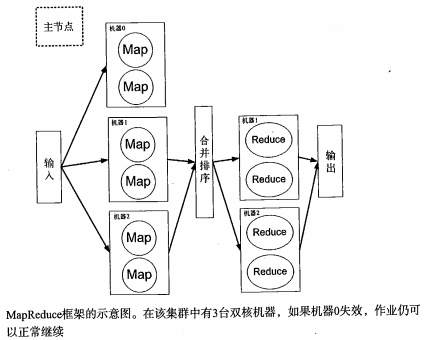

2Hadoop流
分布式计算均值和方差的mapper、reducer
3Spark
参考博客:http://blog.csdn.net/swing2008/article/details/60869183
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
- Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求
- 官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍
目录:
- 架构及生态
- spark 与 hadoop
- 运行流程及特点
- 常用术语
- standalone模式
- yarn集群
- RDD运行流程
3.1架构及生态
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:
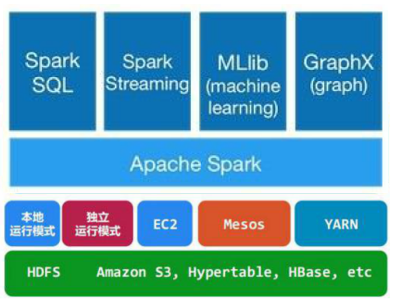
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
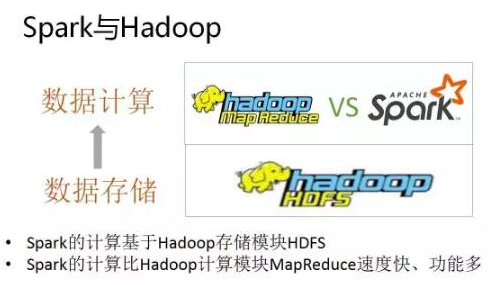
3.2Spark与hadoop
- Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
- spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS
- Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富
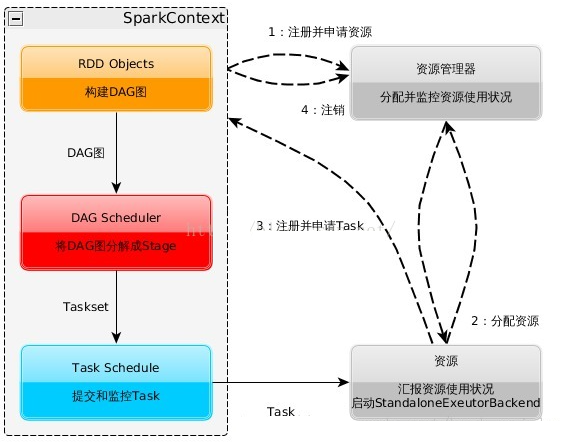
3.3运行流程
4Spark例子
https://www.cnblogs.com/shiyanlou/p/7199460.html
http://blog.csdn.net/gongpulin/article/details/51534754















 6363
6363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









