







MapReduce组件
前置内容
为什么要学习MapReduce
1、MapReduce是人类有史以来第一代分布式计算引擎
2、后期的绝大多数的分布式计算引擎都借鉴了MapReduce的思想
3、学习了MapReduce可以为以后学习其他的分布式计算引擎打好基础
4、目前还有很多的框架底层代码就是MapReduce: Hive、Sqoop、Oozie
MapReduce要学习到什么程度?
1、MapReduce的学习是一半理论,一半代码
2、指导思想是:重理论,轻代码
3、上课的代码要求能看懂,自己敲一遍即可,不要求盲写
MapReduce的概述
分布式计算历代引擎
第一代:MapReduce(MR) 离线分析
第二代:Tez 离线分析
第三代:Spark 离线分析 + 实时分析
第四代:Flink 离线分析 + 实时分析
第五代:Doris , kylin ,ClickHouse, ES,
MapReduce的思想
1、MapReduce最基本的思想就是分而治之
2、MapReduce有两个阶段,一个Map阶段,负责任务的拆分,一个Reduce阶段负责任务的合并
3、MapReduce将一个大的任务进行拆分,拆分成小任务,拆分之后,放在不同的主机上运行,运行之后再将这些结果合并
4、MapReduce整个处理过程就是将原始数据转成一个个键值对,然后不断的对这些键值对进行迭代处理,直到得到最理想的键值对位,最后的键值对就是我们想要的结果

入门-WordCount案例
-
介绍
对文件中的单词数量进行统计

- 思路

-
代码
//=================================WorCountMapper类============================== package pack01_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 第一步:定义类继承Mapper类 * 四个泛型:K1的类型,V1的类型,K2的类型,V2的类型 */ public class WorCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> { /** * 第二步:重写map方法,在该方法中,将K1、V1,转为K2和V2 * @param key 表示K1,是每一行的偏移量,是系统自动转换得到 * @param value 表是V1, 是每一行的文本数据 * @param context 表示MapReduce的上下文对象,可以将我们的键值对传送到下一个处理环节 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1:获取K2 //1.1 对V1按照空格进行切割,获取的每个单词就是K2 String[] words = value.toString().split(" "); for (String k2 : words) { //2:获取V2,V2就是固定值1 //3:将K2和V2写入上下文中,送到下一个处理环节 context.write(new Text(k2),new LongWritable(1)); } } } //=================================WordCountReducer类============================= package pack01_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * 第一步:自定义类,继承Reducer类型 * 泛型:K2类型、V2类型、K3类型、V3类型 */ public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> { /** * 第二步:重写reduce方法,在该方法中,将新K2,V2,转为K3和V3 * @param key 新K2 * @param values [V2] * @param context 上下文对象 */ @Override protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { //1:获取K3, 新K2就是K3 //2:获取V3,遍历[V2]集合,将所有的值相加 long count = 0; //Iterator<LongWritable> iterator = values.iterator(); //while (iterator.hasNext()){ // long i = iterator.next().get(); // count += i; //} for (LongWritable value : values) { count += value.get(); } //3:将K3和V3写入上下文中 context.write(key,new LongWritable(count)); } } //=================================WordCountDriver类============================= package pack01_wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /** * 创建一个Job任务,设置Job任务每一个环节的处理流程,最后将该任务交Yarn执行 */ public class WordCountDriver { public static void main(String[] args) throws Exception{ //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job = Job.getInstance(configuration, "wordcount_basic"); //2、设置置作业驱动类 job.setJarByClass(WordCountDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 /* FileInputFormat父类:该类用来决定源数据的读取方式 TextInputFormat(默认子类):一行一行读取 */ //方式1-写法 //FileInputFormat.addInputPath(job, new Path("hdfs://node1:8020/mapreduce/input/wordcount")); FileInputFormat.addInputPath(job, new Path("file:///D:\\input\\wordcount")); //方式2-写法 /* job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/mapreduce/input/wordcount")); */ //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job.setMapperClass(WorCountMapper.class); job.setMapOutputKeyClass(Text.class); //设置K2类型 job.setMapOutputValueClass(LongWritable.class); //设置V2类型 //5:设置分区、排序,规约、分组(保留) //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); //设置K3类型 job.setOutputValueClass(LongWritable.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 /* FileOutputFormat父类:该类用来决定目标数据的写入方式 TextOutputFormat(默认子类):一行一行写入 */ //方式1-写法 //FileOutputFormat.setOutputPath(job, new Path("hdfs://node1:8020/mapreduce/output/wordcount")); FileOutputFormat.setOutputPath(job, new Path("file:///D:\\output\\wordcount")); //方式2-写法 /* job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:8020/mapreduce/input/wordcount")); */ //8、将设置好的job交给Yarn集群去执行 // 提交作业并等待执行完成 boolean resultFlag = job.waitForCompletion(true); //程序退出 System.exit(resultFlag ? 0 :1); } } -
测试
注意:测试之前一定要准备好数据,目标目录不能存在,否则报错
-
本地测试
直接右键执行, 注意该测试只是模拟,不是真正的Yarn集群执行 -
集群测试
1、代码打jar包 2、将jar包上传到Linux服务器 3、执行以下命令 hadoop jar module3_mapreduce-1.0-SNAPSHOT.jar pack01_wordcount.WordCountDriver
MapReduce的分区
- MR大致的框架
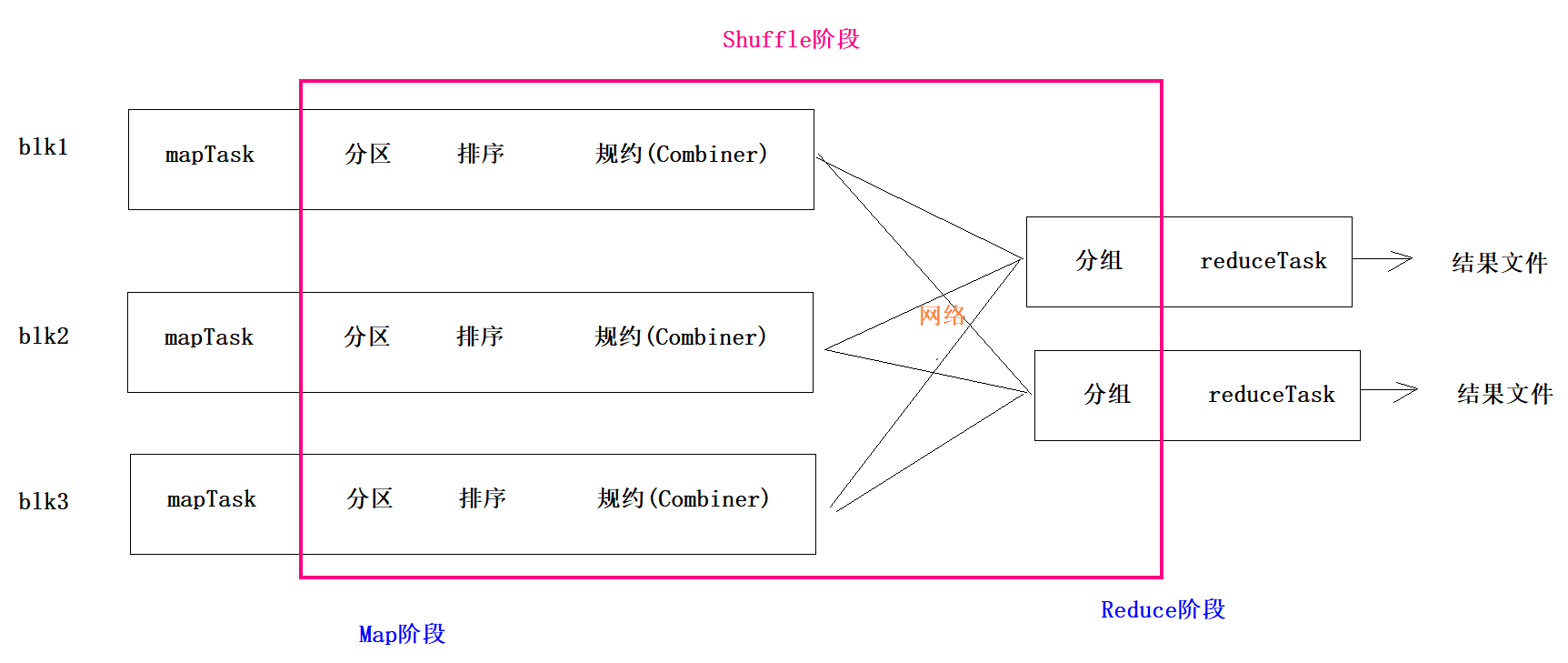
-
分区概念的引入
1、为了增加MR数据聚合的并行度,有时候需要增加Reduce的个数 2、增加了Reduce之后,就要面临一个问题,哪些键值对规哪个Reduce来聚合,你需要定义出一套规则,这套规则就是分区 3、分区就是对每一个K2和V2键值对打标记,标记相同的键值对就会跑到同一个Reduce 4、如果你定义分区,系统有默认的分区机制 5、MR的默认分区是按照键K2进行分区 -
自定义分区代码编写思路
#需求:将wordcount案例中的数据按照单词长度进行分区,长度>=5的单词和长度小于5的单词进行分区 1、定义类继承Partitioner类 2、重写getPartition方法,在该方法中对每一个K2和V2打标记,标记从0开始,0标记的键值对会被0编号的Reduce拉取进行聚合,1标记的键值对会被1编号的Reduce进行聚合 3、设置job你的自定义分区类 job.setPartitionerClass(MyPartitioner.class); 4、在主类中要设置Reduce的个数为 job.setNumReduceTasks(2); -
代码
//=================================CovidMapper类============================= package pack04_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 第一步:定义类继承Mapper类 * 四个泛型:K1的类型,V1的类型,K2的类型,V2的类型 */ public class WorCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> { /** * 第二步:重写map方法,在该方法中,将K1、V1,转为K2和V2 * @param key 表示K1,是每一行的偏移量,是系统自动转换得到 * @param value 表是V1, 是每一行的文本数据 * @param context 表示MapReduce的上下文对象,可以将我们的键值对传送到下一个处理环节 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1:获取K2 //1.1 对V1按照空格进行切割,获取的每个单词就是K2 String[] words = value.toString().split(" "); for (String k2 : words) { //2:获取V2,V2就是固定值1 //3:将K2和V2写入上下文中,送到下一个处理环节 context.write(new Text(k2),new LongWritable(1)); } } } //=================================CovidPartitioner类============================= package pack04_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /* 1、定义类继承Partitioner类 2、重写getPartition方法,在该方法中对每一个K2和V2打标记,标记从0开始,0标记的键值对会被0编号的Reduce拉取进行聚合,1标记的键值对会被1编号的Reduce进行聚合 3、在主类中要设置Reduce的个数为2 */ public class MyPartitioner extends Partitioner<Text, LongWritable> { /** * * @param text K2 * @param longWritable V2 * @param i Reduce的个数 * @return */ @Override public int getPartition(Text text, LongWritable longWritable, int i) { // 长度>=5的单词打标记为0 // 长度小于5的单词打标记为1 if(text.toString().length() >= 5){ return 0; }else { return 1; } } } //=================================CovidReducer类============================= package pack04_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 第一步:自定义类,继承Reducer类型 * 泛型:K2类型、V2类型、K3类型、V3类型 */ public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> { /** * 第二步:重写reduce方法,在该方法中,将新K2,V2,转为K3和V3 * @param key 新K2 * @param values [V2] * @param context 上下文对象 */ @Override protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { //1:获取K3, 新K2就是K3 //2:获取V3,遍历[V2]集合,将所有的值相加 long count = 0; //Iterator<LongWritable> iterator = values.iterator(); //while (iterator.hasNext()){ // long i = iterator.next().get(); // count += i; //} for (LongWritable value : values) { count += value.get(); } //3:将K3和V3写入上下文中 context.write(key,new LongWritable(count)); } } //=================================CovidDriver类============================= package pack04_wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /* 1、定义类继承Partitioner类 2、重写getPartition方法,在该方法中对每一个K2和V2打标记,标记从0开始,0标记的键值对会被0编号的Reduce拉取进行聚合,1标记的键值对会被1编号的Reduce进行聚合 3、在主类中要设置Reduce的个数为2 */ public class MyPartitioner extends Partitioner<Text, LongWritable> { /** * * @param text K2 * @param longWritable V2 * @param i Reduce的个数 * @return */ @Override public int getPartition(Text text, LongWritable longWritable, int i) { // 长度>=5的单词打标记为0 // 长度小于5的单词打标记为1 if(text.toString().length() >= 5){ return 0; }else { return 1; } } } -
默认分区代码
public class HashPartitioner<K, V> extends Partitioner<K, V> { public HashPartitioner() { } //根据每一个K2的hash进行分区,分区的效果是:每一个Reduce可以均衡的聚合数据 public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & 2147483647) % numReduceTasks; } } //---------------------------------------------------------------------- public class HashPartitioner<K, V> extends Partitioner<K, V> { public HashPartitioner() { } //根据每一个K2的hash进行分区,分区的效果是:每一个Reduce可以均衡的聚合数据 public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode()+随机数 & 2147483647) % numReduceTasks; } }
MapReduce的自定义类案例
-
需求
根据疫情数据,统计美国每个州的确诊病例数和死亡病例数 时间 县名 州名, 县编码 确诊人数 死亡人数 2021-01-28,Autauga,Alabama, 01001, 5554, 69 select 州名,sum(确诊人数),sum(死亡人数) from t_covid group by 州名 #最后结果 Alabama 192898 345 Arkansa 25109 875 -
思路
1、将州名作为K2,将确诊人数 死亡人数作为V2 2、可以将V2封装成一个Java类,如果一个自定义类出现在MapReduce中,必须保证该类能够被序列化和反序列化 --方式1:实现Writable #应用场景:JavaBean类对象不作为K2,不需要能够被排序 public class CovidBean implements Writable { //实现序列化 @Override public void write(DataOutput out) throws IOException { } //实现反序列化 @Override public void readFields(DataInput in) throws IOException { } } --方式2:实现WritableComparable #应用场景:JavaBean类对象作为K2,需要能够被排序 public class CovidBean implements WritableComparable<CovidBean> { //定义类对象排序的比较规则 @Override public int compareTo(CovidBean o) { return 0; } //实现序列化 @Override public void write(DataOutput out) throws IOException { } //实现反序列化 @Override public void readFields(DataInput in) throws IOException { } }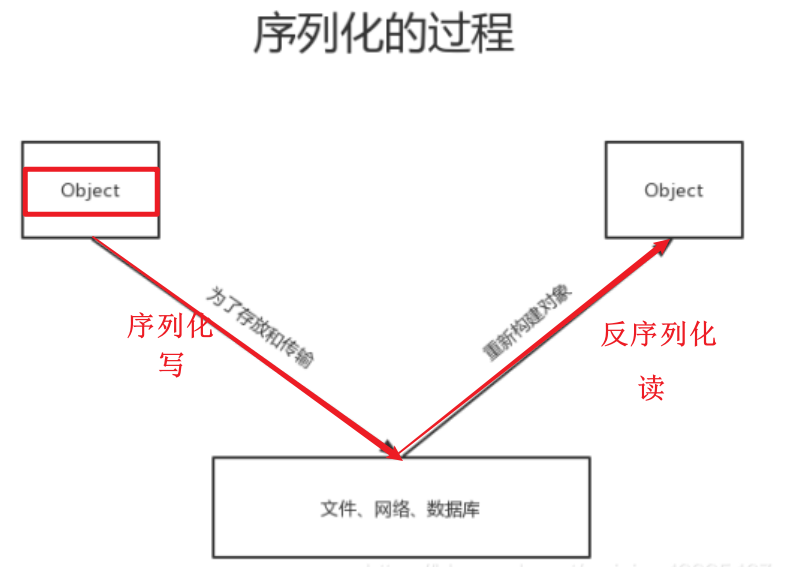

-
代码
package pack07_covid_bean; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /* 1、在MR中,如果要自定义Java类,如果该类不是K2,则直接实现Writable接口 2、在该接口中重写序列化方法和反序列化方法 */ public class CovidBean implements Writable { private int cases; //确诊人数 private int deaths; //死亡人数 public CovidBean(int cases, int deaths) { this.cases = cases; this.deaths = deaths; } public CovidBean() { } public int getCases() { return cases; } public void setCases(int cases) { this.cases = cases; } public int getDeaths() { return deaths; } public void setDeaths(int deaths) { this.deaths = deaths; } //实现序列化:写 @Override public void write(DataOutput out) throws IOException { out.writeInt(cases); out.writeInt(deaths); } //实现反序列化:读 @Override public void readFields(DataInput in) throws IOException { this.cases = in.readInt(); this.deaths = in.readInt(); } @Override public String toString() { return cases + "\t" + deaths ; } } //--------------------------------------- package pack07_covid_bean; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* 1、自定义Java类 */ public class CovidMapper extends Mapper<LongWritable, Text,Text,CovidBean> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, CovidBean>.Context context) throws IOException, InterruptedException { String[] array = value.toString().split(","); if(array.length != 6){ return; } //1:得到K2 String k2 = array[2]; //2:得到V2 CovidBean v2 = new CovidBean(); v2.setCases(Integer.parseInt(array[4])); v2.setDeaths(Integer.parseInt(array[5])); //3:将K2和V2写入上下文 context.write(new Text(k2),v2); } } //-------------------------------------------- package pack07_covid_bean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* 1、自定义Java类 */ public class CovidReducer extends Reducer<Text,CovidBean,Text,CovidBean> { @Override protected void reduce(Text key, Iterable<CovidBean> values, Reducer<Text, CovidBean, Text, CovidBean>.Context context) throws IOException, InterruptedException { /* K2 [V2] Alabama {Covid(18919,234),Covid(383883,119)} */ //1:得到K3,K2就是K3, //2:得到V3 int casesCount= 0; int deathsCount= 0; for (CovidBean value : values) { casesCount += value.getCases(); //累加确诊病例 deathsCount += value.getDeaths(); //累加死亡病例 } CovidBean covidBean = new CovidBean(); covidBean.setCases(casesCount); covidBean.setDeaths(deathsCount); //3:将K3和V3写入上下文中 context.write(key,covidBean); } } //------------------------------------------- package pack07_covid_bean; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import pack05_wordcount.WorCountMapper; import pack05_wordcount.WordCountDriver; import pack05_wordcount.WordCountReducer; import java.net.URI; /* 1、自定义Java类 */ public class CovidDriver { public static void main(String[] args) throws Exception { //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job = Job.getInstance(configuration, "covid_bean_demo"); //2、设置置作业驱动类 job.setJarByClass(CovidDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 //方式1-写法 //FileInputFormat.addInputPath(job, new Path("hdfs://node1:8020/mapreduce/input/wordcount")); //FileInputFormat.addInputPath(job, new Path("file:///D:\\input\\wordcount")); FileInputFormat.addInputPath(job, new Path(args[0])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job.setMapperClass(CovidMapper.class); job.setMapOutputKeyClass(Text.class); //设置K2类型 job.setMapOutputValueClass(CovidBean.class); //设置V2类型 //5:设置分区、排序,规约、分组(保留) //5.1 设置你的定义分区类 //job.setPartitionerClass(MyPartitioner.class); //5.2 设置Reduce个数 //job.setNumReduceTasks(2); //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job.setReducerClass(CovidReducer.class); job.setOutputKeyClass(Text.class); //设置K3类型 job.setOutputValueClass(CovidBean.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType = "file:///"; //String outputPath = "file:///D:\\output\\wordcount"; //String fsType = "hdfs://node1:8020"; //String outputPath = "hdfs://node1:8020/mapreduce/output/wordcount"; String outputPath = args[1]; URI uri = new URI(fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path(outputPath)); if(flag == true){ fileSystem.delete(new Path(outputPath),true); } FileOutputFormat.setOutputPath(job, new Path(outputPath)); //FileOutputFormat.setOutputPath(job, new Path("file:///D:\\output\\wordcount")); //8、将设置好的job交给Yarn集群去执行 // 提交作业并等待执行完成 boolean resultFlag = job.waitForCompletion(true); //程序退出 System.exit(resultFlag ? 0 :1); } }
MapReduce的排序
-
需求
#数据 Alabama 452734 7340 Alaska 53524 253 Arizona 745976 12861 #要求 基于以上数据对确诊病例数进行降序排序,如果确诊病例数相同 ,则按照死亡病例数升序排序 select * from A order by cases desc , deaths asc; -
思路
1、MR的排序只能按照K2排序,哪个字段要参与排序,则哪个字段就应该包含在K2中 2、如果你自定义类作为K2,则必须指定排序规则,实现WritableComparable接口,重写compareTo方法,其他的地方不需要再做任何的设置

-
代码
package pack08_covid_sort; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class CovidSortBean implements WritableComparable<CovidSortBean> { private String state; //州名 private int cases; //确诊人数 private int deaths; //死亡人数 public String getState() { return state; } public void setState(String state) { this.state = state; } public int getCases() { return cases; } public void setCases(int cases) { this.cases = cases; } public int getDeaths() { return deaths; } public void setDeaths(int deaths) { this.deaths = deaths; } @Override public String toString() { return state + "\t" + cases + "\t"+deaths ; } //定义你的JavaBean对象的排序规则 /* Alabama 452734 7340 Alaska 53524 253 Arizona 745976 12861 基于以上数据对确诊病例数进行降序排序,如果确诊病例数相同 ,则按照死亡病例数升序排序 select * from A order by cases desc , deaths asc; 我 > 他 返回大于0的值 我 < 他 返回小于0的值 我 = 他 返回等于0的值 */ @Override public int compareTo(CovidSortBean o) { int result = this.cases - o.cases; if(result == 0){ return this.deaths - o.deaths; } return result * -1; } //实现序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(state); out.writeInt(cases); out.writeInt(deaths); } //实现反序列化 @Override public void readFields(DataInput in) throws IOException { this.state = in.readUTF(); this.cases = in.readInt(); this.deaths = in.readInt(); } } #---------------------------------------- package pack08_covid_sort; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class CovidSortMapper extends Mapper<LongWritable, Text,CovidSortBean, NullWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, CovidSortBean, NullWritable>.Context context) throws IOException, InterruptedException { //1:得到K2 String[] array = value.toString().split("\t"); CovidSortBean k2 = new CovidSortBean(); k2.setState(array[0]); k2.setCases(Integer.parseInt(array[1])); k2.setDeaths(Integer.parseInt(array[2])); //2:得到V2,就是NullWritable //3:将K2和V2写入上下文中 context.write(k2,NullWritable.get()); } } #---------------------------------- package pack08_covid_sort; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class CovidSortReducer extends Reducer<CovidSortBean, NullWritable,CovidSortBean,NullWritable> { @Override protected void reduce(CovidSortBean key, Iterable<NullWritable> values, Reducer<CovidSortBean, NullWritable, CovidSortBean, NullWritable>.Context context) throws IOException, InterruptedException { //1:得到K3,就是K2 //2:得到V3,就是NullWritable //3:将K3和V3写入上下文中 context.write(key,NullWritable.get()); } } #---------------------------------- package pack08_covid_sort; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.net.URI; public class CovidSortDriver { public static void main(String[] args) throws Exception { //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job = Job.getInstance(configuration, "covid_sort_demo"); //2、设置置作业驱动类 job.setJarByClass(CovidSortDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 //方式1-写法 //FileInputFormat.addInputPath(job, new Path("hdfs://node1:8020/mapreduce/input/wordcount")); //FileInputFormat.addInputPath(job, new Path("file:///D:\\input\\wordcount")); FileInputFormat.addInputPath(job, new Path(args[0])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job.setMapperClass(CovidSortMapper.class); job.setMapOutputKeyClass(CovidSortBean.class); //设置K2类型 job.setMapOutputValueClass(NullWritable.class); //设置V2类型 //5:设置分区、排序,规约、分组(保留) //5.1 设置你的定义分区类 //job.setPartitionerClass(MyPartitioner.class); //5.2 设置Reduce个数 //job.setNumReduceTasks(2); //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job.setReducerClass(CovidSortReducer.class); job.setOutputKeyClass(CovidSortBean.class); //设置K3类型 job.setOutputValueClass(NullWritable.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType = "file:///"; //String outputPath = "file:///D:\\output\\wordcount"; //String fsType = "hdfs://node1:8020"; //String outputPath = "hdfs://node1:8020/mapreduce/output/wordcount"; String outputPath = args[1]; URI uri = new URI(fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path(outputPath)); if(flag == true){ fileSystem.delete(new Path(outputPath),true); } FileOutputFormat.setOutputPath(job, new Path(outputPath)); //FileOutputFormat.setOutputPath(job, new Path("file:///D:\\output\\wordcount")); //8、将设置好的job交给Yarn集群去执行 // 提交作业并等待执行完成 boolean resultFlag = job.waitForCompletion(true); //程序退出 System.exit(resultFlag ? 0 :1); } }
MapReduce的串联
-
介绍
当我们在使用MapReduce进行大数据分析时,很多时候使用一个MR并不能完成分析任务,需要使用多个MR进行串联 则我们可以使用MR提供的Job控制器来实现多个MR的依赖串联执行

-
代码
package pack09_mapreduce_series; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob; import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import pack07_covid_bean.CovidBean; import pack07_covid_bean.CovidDriver; import pack07_covid_bean.CovidMapper; import pack07_covid_bean.CovidReducer; import pack08_covid_sort.CovidSortBean; import pack08_covid_sort.CovidSortDriver; import pack08_covid_sort.CovidSortMapper; import pack08_covid_sort.CovidSortReducer; import java.net.URI; public class MapReduceSeriesJob { public static void main(String[] args) throws Exception { //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job1 = Job.getInstance(configuration, "covid_bean_demo"); //2、设置置作业驱动类 job1.setJarByClass(CovidDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 FileInputFormat.addInputPath(job1, new Path(args[0])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job1.setMapperClass(CovidMapper.class); job1.setMapOutputKeyClass(Text.class); //设置K2类型 job1.setMapOutputValueClass(CovidBean.class); //设置V2类型 //5:设置分区、排序,规约、分组(保留) //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job1.setReducerClass(CovidReducer.class); job1.setOutputKeyClass(Text.class); //设置K3类型 job1.setOutputValueClass(CovidBean.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType = "file:///"; String outputPath = args[1]; URI uri = new URI(fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path(outputPath)); if(flag == true){ fileSystem.delete(new Path(outputPath),true); } FileOutputFormat.setOutputPath(job1, new Path(outputPath)); //todo 将普通的作用包装成受控作业 ControlledJob cj1 = new ControlledJob(configuration); cj1.setJob(job1); //1:创建Job2任务对象 //configuration.set("参数名字","参数值"); Job job2 = Job.getInstance(configuration, "covid_sort_demo"); //2、设置置作业驱动类 job2.setJarByClass(CovidSortDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 FileInputFormat.addInputPath(job2, new Path(args[1])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job2.setMapperClass(CovidSortMapper.class); job2.setMapOutputKeyClass(CovidSortBean.class); //设置K2类型 job2.setMapOutputValueClass(NullWritable.class); //设置V2类型 //5:设置分区、排序,规约、分组(保留) //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job2.setReducerClass(CovidSortReducer.class); job2.setOutputKeyClass(CovidSortBean.class); //设置K3类型 job2.setOutputValueClass(NullWritable.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType2 = "file:///"; String outputPath2 = args[2]; URI uri2 = new URI(fsType); FileSystem fileSystem2 = FileSystem.get(uri2, configuration); boolean flag2 = fileSystem.exists(new Path(outputPath2)); if(flag2 == true){ fileSystem2.delete(new Path(outputPath2),true); } FileOutputFormat.setOutputPath(job2, new Path(outputPath2)); //todo 将普通的作用包装成受控作业 ControlledJob cj2 = new ControlledJob(configuration); cj2.setJob(job2); //todo 设置作业之间的依赖关系 cj2.addDependingJob(cj1); //todo 创建主控制器 控制上面两个作业 一起提交 JobControl jc = new JobControl("myctrl"); jc.addJob(cj1); jc.addJob(cj2); //使用线程启动JobControl Thread t = new Thread(jc); t.start(); while (true){ if(jc.allFinished()){ System.out.println(jc.getSuccessfulJobList()); jc.stop(); break; } } } } -
运行
- 本地运行

-
集群运行
hadoop jar module3_mapreduce-1.0-SNAPSHOT.jar /mapreduce/input/covid19 /mapreduce/output/covid19_bean /mapreduce/output/covid19_bean_sort #编写Shell脚本 #!/bin/bash HADOOP_PATH=/export/server/hadoop-3.3.0/bin/hadoop ${HADOOP_PATH} jar /root/mapreduce/module3_mapreduce-1.0-SNAPSHOT.jar /mapreduce/input/covid19 /mapreduce/output/covi d19_bean /mapreduce/output/covid19_bean_sort ~
MapReduce的规约(Combiner)
-
介绍
1、规约是MapReduce的一种优化手段,可有可无,有了就属于锦上添花,有或者没有,都不会改变最终的结果 2、规约并不是所有MapReduce任务都能使用,前提是不能影响最终结果 3、规约主要是对每一个Map端的数据做提前的聚合,减少Map端和Reduce端传输的数据量,提交计算效率 4、规约可以理解为将Reduce端代码在Map端提前执行 5、如果你的规约代码和Reducer代码一致,则规约代码可以不用写,直接使用Reducer代码即可 job.setCombinerClass(WordCountReducer.class); -
代码编写步骤
1、 自定义一个combiner继承Reducer,重写reduce方法,逻辑和Reducer一样 2、 在job中设置: job.setCombinerClass(CustomCombiner.class)
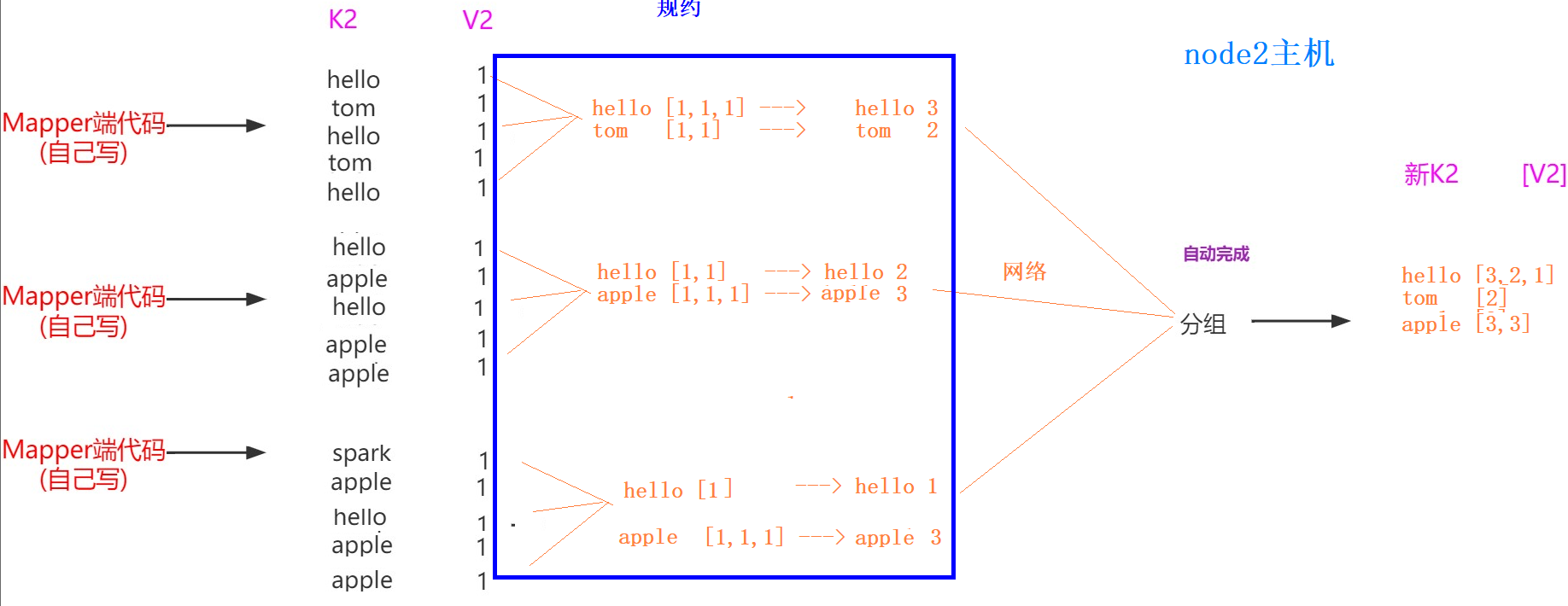
MapReduce的分组
-
介绍
1、分组是对Map端传输过来的数据进行去重聚合 # K2 V2 hello 1 hello 1 --分组--> hello [1,1,1] --reduce方法--> hello 3 hello 1 world 1 2、分区和分组区别? 分区是决定K2和V2去往哪一个Reduce进行处理 分组是在同一个Reduce内部进行聚合 3、一般默认的分组就能完成分析操作,但是有时候在特定场景下,默认的分组不能满足我们的需求,则需要我们自定义分组 -
需求
找出美国每个州state的确诊案例数最多的县county是哪一个。该问题也是俗称的TopN问题。 select * from t_covid order by cases desc limit 1; 找出美国每个州state的确诊案例数最多前三个县county是哪些。该问题也是俗称的TopN问题。 select * from t_covid order by cases desc limit 3; -
思路
#如何自定义分组 1、写类继承 WritableComparator,重写Compare方法。 2、job.setGroupingComparatorClass(xxxx.class);

-
代码
//----------------------------- package pack11_mapreduce_grouping; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class GroupingBean implements WritableComparable<GroupingBean> { private String state; //州 private int cases; //确诊病例数 public String getState() { return state; } public void setState(String state) { this.state = state; } public int getCases() { return cases; } public void setCases(int cases) { this.cases = cases; } //定义排序规则 /* 1:按照同一个州的确诊人数进行降序排序 */ @Override public int compareTo(GroupingBean o) { int result = this.state.compareTo(o.state); if(result == 0){ return o.cases - this.cases; } return result; } //序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(state); out.writeInt(cases); } //反序列化 @Override public void readFields(DataInput in) throws IOException { this.state = in.readUTF(); this.cases = in.readInt(); } } //----------------------------- package pack11_mapreduce_grouping; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class GroupingMapper extends Mapper<LongWritable, Text,GroupingBean,Text> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, GroupingBean, Text>.Context context) throws IOException, InterruptedException { //1:获取K2 String[] array = value.toString().split(","); GroupingBean k2 = new GroupingBean(); k2.setState(array[2]); k2.setCases(Integer.parseInt(array[4])); //2:获取V2,就是V1 //3:将K2和V2写入上下文 context.write(k2,value); } } //------------------------------------ package pack11_mapreduce_grouping; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; //1:自定义类去继承WritableComparator类 public class MyGroupingComparator extends WritableComparator { //2:编写无参构造,将你的自定义类传给父类 /* 参1:表示传给父类的JavaBean类型 参2:表示允许父类通过反射造子类对象 */ public MyGroupingComparator() { super(GroupingBean.class,true); } //3:在方法中指定分组的规则:两个GroupingBean对象只要你们的state(州)是一样的,就应该分到同一组 //这个方法会被自动调用,只要该方法返回0,则两个GroupingBean对象就分到同一组 @Override // GroupingBean GroupingBean public int compare(WritableComparable a, WritableComparable b) { GroupingBean g1 = (GroupingBean) a; GroupingBean g2 = (GroupingBean) b; //如果g1和g2的州state同,则应该return 0,则这两个对象就会被分到同一组 //if(g1.getState().equals(g2.getState())) { // return 0; //}else{ // return 1; //} return g1.getState().compareTo(g2.getState()); } } //------------------------------------ package pack11_mapreduce_grouping; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class GroupingReducer extends Reducer<GroupingBean, Text,Text, NullWritable> { @Override protected void reduce(GroupingBean key, Iterable<Text> values, Reducer<GroupingBean, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { //1:得到K3 //2:得到V3 //3:将K3和V3写入上下文中 int count = 1; for (Text value : values) { context.write(value,NullWritable.get()); if(++count > 1) { break; } } } } //------------------------------------------ package pack11_mapreduce_grouping; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import pack08_covid_sort.CovidSortBean; import pack08_covid_sort.CovidSortDriver; import pack08_covid_sort.CovidSortMapper; import pack08_covid_sort.CovidSortReducer; import pack10_mapreduce_combiner.WorCountMapper; import pack10_mapreduce_combiner.WordCountDriver; import pack10_mapreduce_combiner.WordCountReducer; import java.net.URI; public class GroupingDriver { public static void main(String[] args) throws Exception { //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job = Job.getInstance(configuration, "grouping_demo"); //2、设置置作业驱动类 job.setJarByClass(GroupingDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 FileInputFormat.addInputPath(job, new Path(args[0])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job.setMapperClass(GroupingMapper.class); job.setMapOutputKeyClass(GroupingBean.class); //设置K2类型 job.setMapOutputValueClass(Text.class); //设置V2类型 //5:设置分区、[排序],规约、分组(保留) job.setGroupingComparatorClass(MyGroupingComparator.class); //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job.setReducerClass(GroupingReducer.class); job.setOutputKeyClass(Text.class); //设置K3类型 job.setOutputValueClass(NullWritable.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType = "file:///"; //String outputPath = "file:///D:\\output\\wordcount"; //String fsType = "hdfs://node1:8020"; //String outputPath = "hdfs://node1:8020/mapreduce/output/wordcount"; String outputPath = args[1]; URI uri = new URI(fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path(outputPath)); if(flag == true){ fileSystem.delete(new Path(outputPath),true); } FileOutputFormat.setOutputPath(job, new Path(outputPath)); //8、将设置好的job交给Yarn集群去执行 // 提交作业并等待执行完成 boolean resultFlag = job.waitForCompletion(true); //程序退出 System.exit(resultFlag ? 0 :1); } }
MapReduce的Join操作
Reduce端join
-
介绍
1、Reduce Join是在Reduce完成Join操作 2、Reduce端Join,Join的文件在Map阶段K2就是Join字段 3、Reduce会存在数据倾斜的风险,如果存在该文件,则可以使用MapJoin来解决 4、Reduce端Join的代码必须放在集群运行,不能在本地运行 -
案例思路

-
代码
//------------------------------------ package pack12_reduce_join; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1:确定读取的是哪个源数据文件 FileSplit fileSplit = (FileSplit) context.getInputSplit(); //获取文件切片 String fileName = fileSplit.getPath().getName(); //获取源文件的名字 String[] array = value.toString().split("\\|"); //2:处理订单文件 if ("itheima_order_goods.txt".equals(fileName)) { //订单文件 //2.1:获取K2 String k2 = array[1]; //2.2:获取v2 String v2 = "o_"+array[0] + "\t" + array[2]; //2.3:将k2和v2写入上下文中 context.write(new Text(k2), new Text(v2)); } //3:处理商品文件 if ("itheima_goods.txt".equals(fileName)) { //商品文件 //3.1 获取K2 String k2 = array[0]; String v2 = "g_"+array[0] + "\t" + array[2]; //3.2:将k2和v2写入上下文中 context.write(new Text(k2), new Text(v2)); } } } //------------------------------------------- package pack12_reduce_join; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; public class ReduceJoinReducer extends Reducer<Text,Text,Text, NullWritable> { ArrayList<String> orderList = new ArrayList<>(); @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { orderList.clear(); String goods_value=""; //1: 遍历集合,分别获取订单信息和商品信息 for (Text value : values) { if(value.toString().startsWith("o_")){ //订单信息 orderList.add(value.toString().substring(2)); // o_12020203 } if(value.toString().startsWith("g_")){ //商品信息 goods_value = value.toString().substring(2); } } //2:将订单信息和商品信息进行拼接 for (String order : orderList) { System.out.println(order); context.write(new Text(order+"\t"+goods_value),NullWritable.get()); } } } //--------------------------------------- package pack12_reduce_join; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.net.URI; public class ReduceJoinDriver { public static void main(String[] args) throws Exception { //1:创建Job任务对象 Configuration configuration = new Configuration(); //configuration.set("参数名字","参数值"); Job job = Job.getInstance(configuration, "reduce_join_demo"); //2、设置置作业驱动类 job.setJarByClass(ReduceJoinDriver.class); //3、设置文件读取输入类的名字和文件的读取路径 FileInputFormat.addInputPath(job, new Path(args[0])); //4:设置你自定义的Mapper类信息、设置K2类型、设置V2类型 job.setMapperClass(ReduceJoinMapper.class); job.setMapOutputKeyClass(Text.class); //设置K2类型 job.setMapOutputValueClass(Text.class); //设置V2类型 //5:设置分区、[排序],规约、分组(保留) //6:设置你自定义的Reducer类信息、设置K3类型、设置V3类型 job.setReducerClass(ReduceJoinReducer.class); job.setOutputKeyClass(Text.class); //设置K3类型 job.setOutputValueClass(NullWritable.class); //设置V3类型 //7、设置文件读取输出类的名字和文件的写入路径 //7.1 如果目标目录存在,则删除 String fsType = "file:///"; //String outputPath = "file:///D:\\output\\wordcount"; //String fsType = "hdfs://node1:8020"; //String outputPath = "hdfs://node1:8020/mapreduce/output/wordcount"; String outputPath = args[1]; URI uri = new URI(fsType); FileSystem fileSystem = FileSystem.get(uri, configuration); boolean flag = fileSystem.exists(new Path(outputPath)); if(flag == true){ fileSystem.delete(new Path(outputPath),true); } FileOutputFormat.setOutputPath(job, new Path(outputPath)); //8、将设置好的job交给Yarn集群去执行 // 提交作业并等待执行完成 boolean resultFlag = job.waitForCompletion(true); //程序退出 System.exit(resultFlag ? 0 :1); } }
Map端Join
-
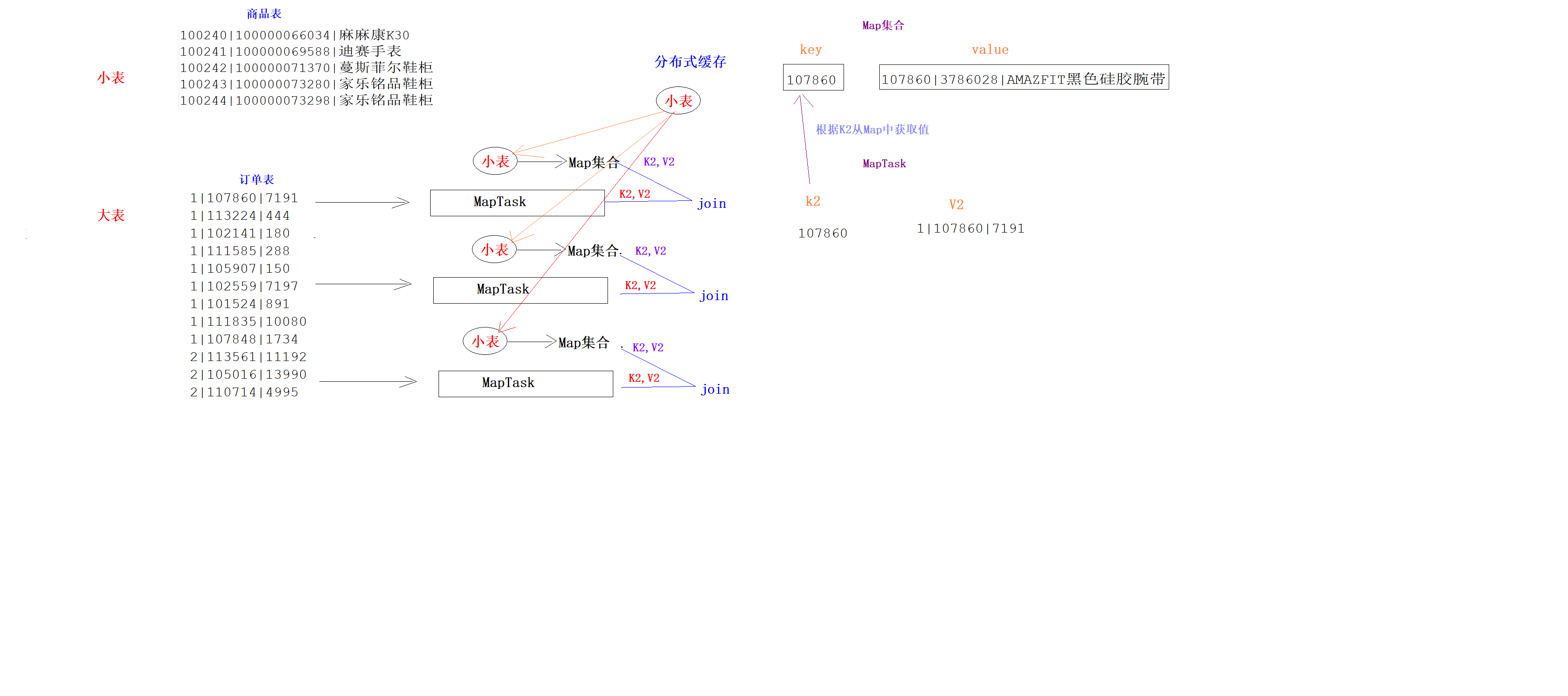
介绍
1、Map端join就是在Map端将Join操作完成 2、Map端join的前提是小表Join大表,小表的大小默认是20M 3、Map端Join需要将小表存在在分布式缓存中,然后读取到每一个MapTask的本地内存的Map集合中 4、Map端Join一般不会数据倾斜问题,因为Map的数量是由数据量大小自动决定的 5、Map端Join代码不需要Reduce -
案例思路
-
代码
package pack13_map_join; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.HashMap; public class MapJoinMapper extends Mapper<LongWritable, Text,Text,NullWritable> { HashMap<String, String> goodsMap = new HashMap<>(); /** * setup方法会在map方法执行之前先执行,而且只会执行一次,主要用来做初始化工作 * @param context * @throws IOException * @throws InterruptedException */ //将小表从分布式缓存中读取,存入Map集合 @Override protected void setup(Context context) throws IOException, InterruptedException { //1:获取分布式缓存中文件的输入流 BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream("itheima_goods.txt"))); String line = null; while ((line = bufferedReader.readLine()) != null){ String[] array = line.split("\\|"); goodsMap.put(array[0], array[2]); } /* {100101,四川果冻橙6个约180g/个} {100102,鲜丰水果秭归脐橙中华红} */ } @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //1:得到K2 String[] array = value.toString().split("\\|"); String k2 = array[1]; String v2 = array[0] + "\t" + array[2]; //2:将K2和Map集合进行Join String mapValue = goodsMap.get(k2); context.write(new Text(v2 + "\t" + mapValue), NullWritable.get()); } } //---------------------------------------- package pack13_map_join; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.net.URI; public class MapJoinDriver { public static void main(String[] args) throws Exception{ Configuration configuration = new Configuration(); //1:创建一个Job对象 Job job = Job.getInstance(configuration, "map_join"); //2:对Job进行设置 //2.1 设置当前的主类的名字 job.setJarByClass(MapJoinDriver.class); //2.2 设置数据读取的路径(大表路径) FileInputFormat.addInputPath(job,new Path("hdfs://node1:8020/mapreduce/input/map_join/big_file")); //2.3 指定你自定义的Mapper是哪个类及K2和V2的类型 job.setMapperClass(MapJoinMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); //2.3 指定你自定义的Reducer是哪个类及K3和V3的类型 //job.setReducerClass(ReduceJoinReducer.class); //job.setOutputKeyClass(Text.class); //job.setOutputValueClass(NullWritable.class); //将小表存入分布式缓存 job.addCacheFile(new URI("hdfs://node1:8020/mapreduce/input/map_join/small_file/itheima_goods.txt")); //2.4 设置数据输出的路径--该目录要求不能存在,否则报错 //Path outputPath = new Path("file:///D:\\output\\wordcount"); Path outputPath = new Path("hdfs://node1:8020/output/map_join"); FileOutputFormat.setOutputPath(job,outputPath); //2.5 设置Shuffle的分组类 FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration()); boolean is_exists = fileSystem.exists(outputPath); if(is_exists == true){ //如果目标文件存在,则删除 fileSystem.delete(outputPath,true); } //3:将Job提交为Yarn执行 boolean bl = job.waitForCompletion(true); //4:退出任务进程,释放资源 System.exit(bl ? 0 : 1); } }
MapReduce执行过程
- 流程图

-
MapReduce慢的原因
1、MapReduce在运行的过程中,要经过多次的IO操作,数据要多次落硬盘 2、后期几乎所有大数据计算框架都是基于内存处理 MR = 文件---》内存 ---》硬盘 --》内存 ---》文件 Spark = 文件---》内存 ---》内存 --》内存 ---》文件
















 1521
1521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











