






通过一个偶然的项目实践经历,我接触了计算机视觉方面的相关知识,但是最开始我更多的是学习OpenCV相关的课程,在一个偶然的机会我了解到最近火爆全网的机器学习算法——Transfromer注意力机制算法,接下来我们就来看看他在图像处理方面究竟火在哪里:
定义:
Transformer 最初是作为机器翻译的 Seq2Seq 模型提出的。后来的工作表明,基于 Transformer 的预训练模型 (PTM) 可以在各种任务上实现 SOTA。因此,Transformer,特别是 PTM,已成为 NLP 中的首选架构。除了语言相关的应用,Transformer 还被 CV,音频处理甚至其他学科采用。在过去几年中提出了各种 Transformer 变体(又名 X-former),这些 X-former 也从不同的角度改进了原版 Transformer。
1. 模型效率。应用 Transformer 的一个关键挑战是其处理长序列的效率较低,这主要是由于 self-attention 的计算和内存复杂性。改进方法包括轻量化注意力模块(例如稀疏注意力)和分而治之的方法(例如循环和分层机制)。
2. 模型泛化。由于 Transformer 是一种灵活的架构,并且对输入数据的结构偏差几乎没有假设,因此很难在小规模数据上进行训练。改进方法包括引入结构偏差或正则化,对大规模未标记数据进行预训练等。
3. 模型适配。这一系列工作旨在使 Transformer 适应特定的下游任务和应用程序。
在这篇笔记中我们更多将从处理过程等方面全方面了解2022这个火爆大江南北的算法
Attention机制
Attention机制起源于自然语言处理中的seq2seq模型, 这个模型是一个RNN的结构, 输入一个句子, 输出机器翻译后的句子, 或者是这个句子的下一段话。

我们可以看出,在这种模型上,存在一个问题就是每一层传给下一层的向量长度是固定的,当我们用固定的长度向量来表达信息时,效果较为一般
而Transfromer的注意力机制会让我们在有限的的空间内较为有限的关注有限的向量长度,这样将留给我们更多向量信息。具体我们可以参考下图
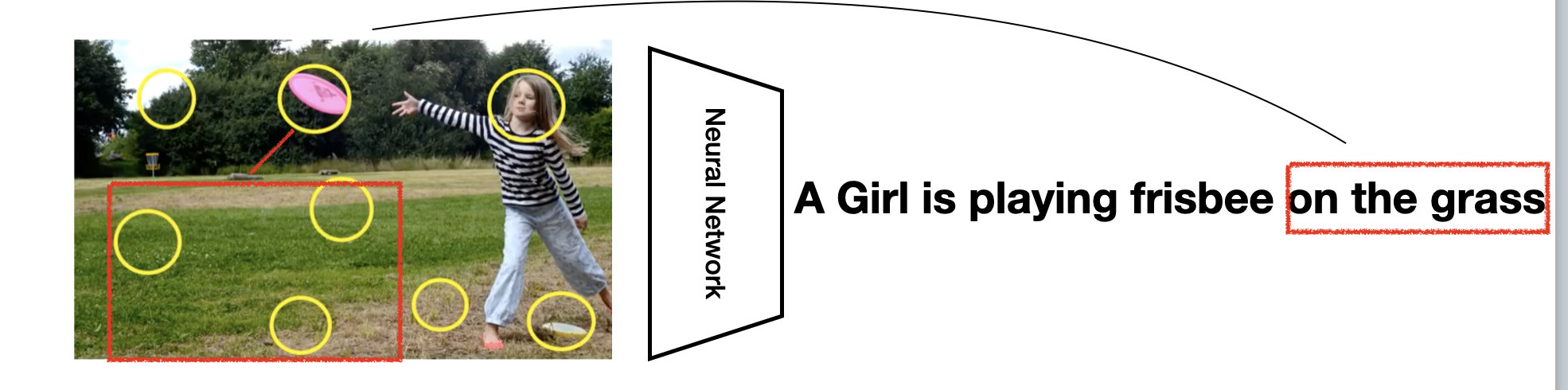
用Transformer做图像分类
如上图而言,我们做Transformer图像分类时分为一个一个小块的像素点,也就是采用了图像分块的方式,当我们需要识别的图片是由多个物体覆盖到一起时,可以通过此类方法完美地识别所有物体,具体原理参考下图
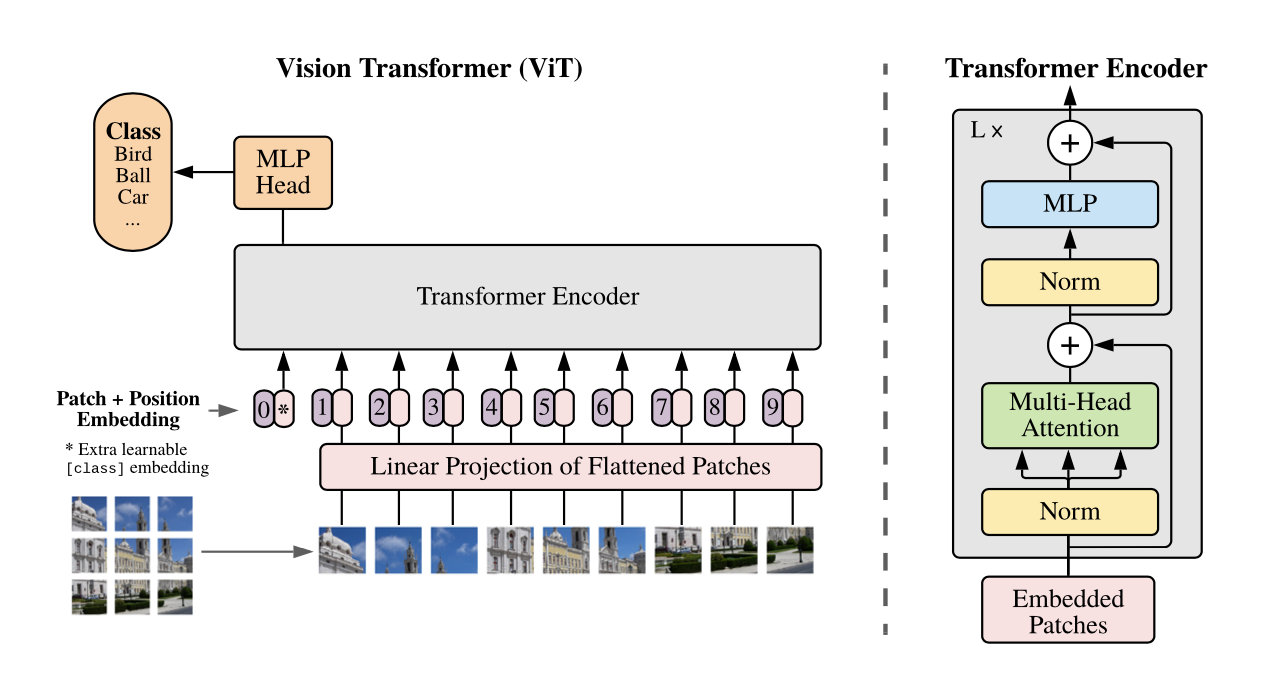
这里我们采用VIT模型为例,实现对数据CiFar10的分类处理,使我们的模型性能来提升,以下为代码段展示:
1.1导入模型
import os
import math
import numpy as np
import pickle as p
import tensorflow as tffrom tensorflow
import kerasimport matplotlib.pyplot as pltfrom tensorflow.keras
import layersimport tensorflow_addons as tfa
%matplotlib inline1.2 定义批量导入数据的函数
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb')as f:
# 一个样本由标签和图像数据组成
# (3072=32x32x3)
# ...
data_dict = p.load(f, encoding='bytes')
images= data_dict[b'data']
labels = data_dict[b'labels']
# 把原始数据结构调整为: BCWH
images = images.reshape(10000, 3, 32, 32)
# tensorflow处理图像数据的结构:BWHC
# 把通道数据C移动到最后一个维度
images = images.transpose (0,2,3,1)
labels = np.array(labels)
return images, labels1.3定义加载的数据函数
def load_CIFAR_data(data_dir):
"""load CIFAR data"""
images_train=[]
labels_train=[]
for i in range(5):
f=os.path.join(data_dir,'data_batch_%d' % (i+1))
print('loading ',f)
# 调用 load_CIFAR_batch( )获得批量的图像及其对应的标签
image_batch,label_batch=load_CIFAR_batch(f)
images_train.append(image_batch)
labels_train.append(label_batch)
Xtrain=np.concatenate(images_train)
Ytrain=np.concatenate(labels_train)
del image_batch ,label_batch
Xtest,Ytest=load_CIFAR_batch(os.path.join(data_dir,'test_batch'))
print('finished loadding CIFAR-10 data')
# 返回训练集的图像和标签,测试集的图像和标签
return (Xtrain,Ytrain),(Xtest,Ytest)1.4导入数据
data_dir = r'data\cifar-10-batches-py'
(x_train,y_train),(x_test,y_test) = load_CIFAR_data(data_dir)
运行结果
loading data\cifar-10-batches-py\data_batch_1
loading data\cifar-10-batches-py\data_batch_2
loading data\cifar-10-batches-py\data_batch_3
loading data\cifar-10-batches-py\data_batch_4
loading data\cifar-10-batches-py\data_batch_5
finished loadding CIFAR-10 data1.5 可视化加载数据
label_dict = {0:"airplane", 1:"
automobile", 2:"bird", 3:"cat", 4:"deer",
5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
def plot_images_labels(images, labels, num):
total = len(images)
fig = plt.gcf()
fig.set_size_inches(15, math.ceil(num / 10) * 7)
for i in range(0, num):
choose_n = np.random.randint(0, total)
ax = plt.subplot(math.ceil(num / 5), 5, 1 + i)
ax.imshow(images[choose_n], cmap='binary')
title = label_dict[labels[choose_n]]
ax.set_title(title, fontsize=10)
plt.show()
plot_images_labels(x_train, y_train, 10)运行结果:


总结与展望
Transformer由于其与卷积神经网络相比,具有竞争性的性能和巨大的潜力,正在成为计算机视觉领域的热门话题。为了发现和利用变换器的力量,正如调查中所总结的那样,近年来提出了许多解决方案。这些方法在广泛的视觉任务上表现出优异的性能,包括基本图像分类、高级视觉、低级视觉和视频处理。我们有理由相信,只需一个模型就可以完成更多任务。















 1788
1788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









