







 注意力机制受到人类视觉注意力启发,常用于深度学习,特别是在自然语言处理中。它通过分配权重来关注输入信息的特定部分,如最大池化、平均池化、多头注意力等。多头注意力允许模型在不同子空间学习信息,提高模型性能。在机器翻译、文本分类等任务中,注意力机制能提高可解释性和克服RNN的挑战,但也增加了计算量。
注意力机制受到人类视觉注意力启发,常用于深度学习,特别是在自然语言处理中。它通过分配权重来关注输入信息的特定部分,如最大池化、平均池化、多头注意力等。多头注意力允许模型在不同子空间学习信息,提高模型性能。在机器翻译、文本分类等任务中,注意力机制能提高可解释性和克服RNN的挑战,但也增加了计算量。
文章目录
产生原因
受到人类注意力机制的启发。人们在进行观察图像的时候,其实并不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。


注意力机制类型
注意力机制其实也是一种池化,是一种对输入分配偏好的通用池化方法,通常是含常数的,也可以带来非参数模型。注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。


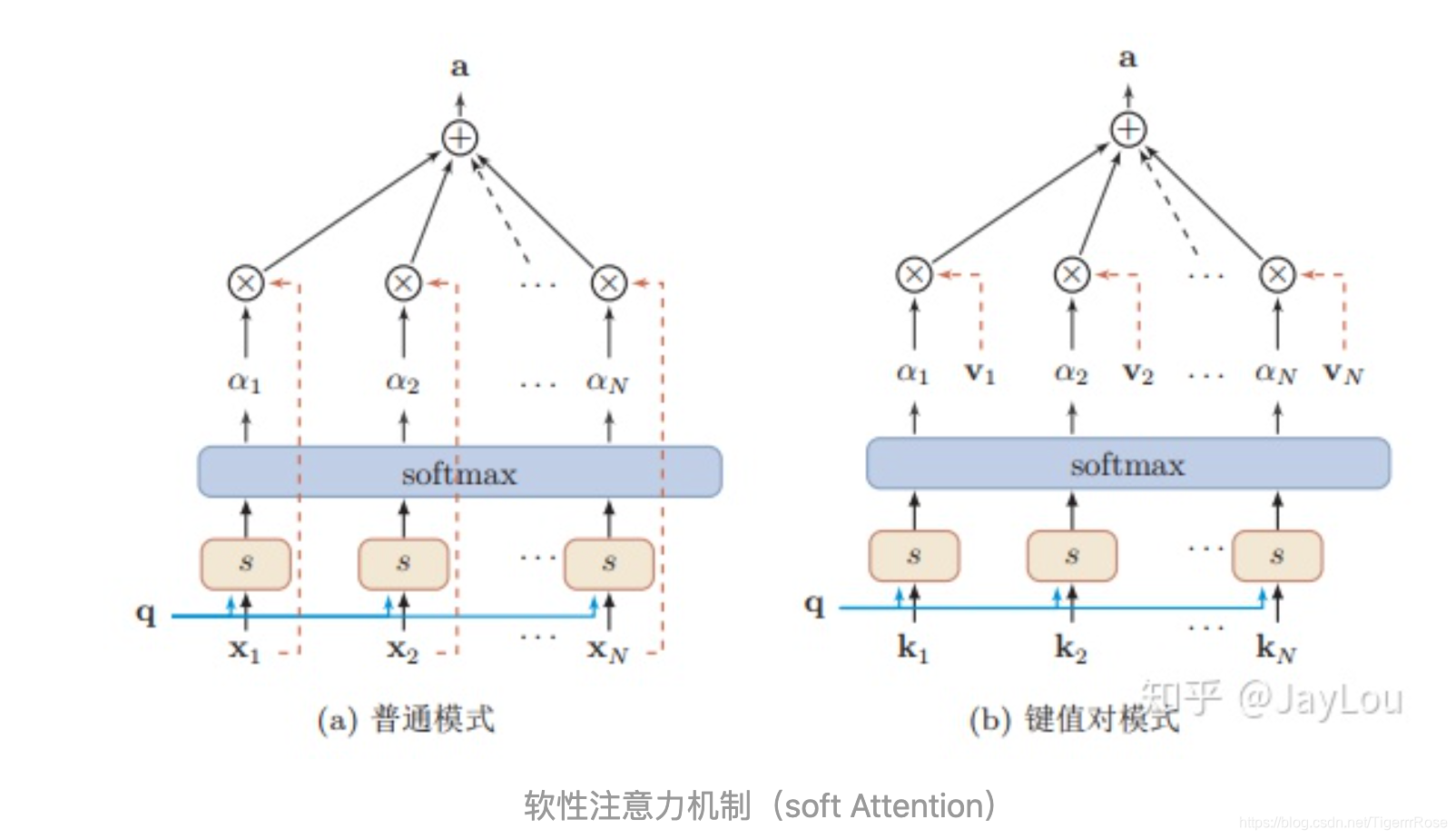
最常用的形式是通过query(问询矩阵)*key(比如用rnn的隐藏层ht加入全连接生成或者用lstm的细胞状态全连接生成) 对两个矩阵点乘的结果(标准化)套入softmax进行生成概率分布,再于value 矩阵相乘的得到包含注意力机制的词/句子表示。
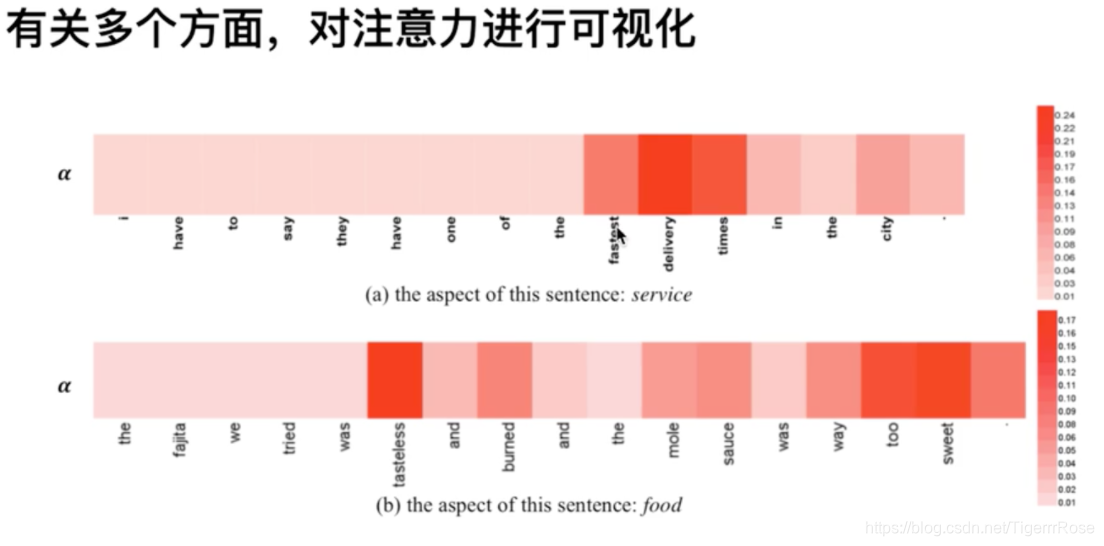
比如输入是the food is good but the service is bad 这个文本做情感分类,如果问的是食物的情感,则通过query embedding加大注意力在前四个词语(通过概率的数值加大前面四个词的比重)而尽可能忽略but后面的词语。如果问的是服务,则尽可能忽略but前面的词语,实现形式是通过问题生成query embedding作为Q矩阵与键K矩阵相乘经过softmax得到每个词的注意力权重(其实这是一种概率的体现), 再与V值矩阵相乘得到注意力机制的表示。该例子:对注意力可视化如下:
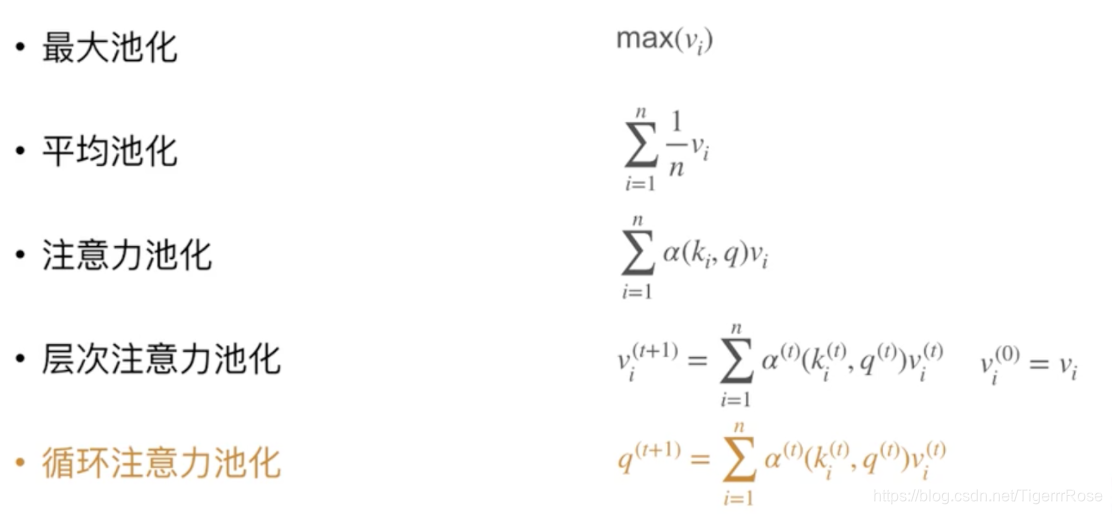
最大池化与平均池化的注意力机制
最大池化容易过拟合,平均池化容易欠拟合
最早的注意力机制其实是一种平均池化:


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









