






目录
local attention/truncated attention
Self-Attention与Transformer的结构代码
摘要
神经网络中的注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务。关于如何让自注意力机制更有效的问题,学习了self-attention的多种变形,包括减少注意力矩阵的计算量、加快注意力机制的运算速度、去掉attention等。将self-attention机制用代码的形式实现,最后通过代码熟练计算过程,总结比较了各种变形的方法以及优势。
Abstract
The attention mechanism in neural networks can quickly extract important features of sparse data, so it is widely used in Natural language processing tasks. Regarding the issue of how to make the self attention mechanism more effective, we learned various variants of self attention, including reducing the computational complexity of the attention matrix, accelerating the computational speed of the attention mechanism, and removing attention. Implement the self attention mechanism in the form of code, and finally proficiently calculate the process through code, summarize and compare various deformation methods and advantages.
如何让self-attention更有效
自制力机制里面的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
第一个过程中,输入一个向量,可通过乘以不同的矩阵得到一个query和一个key的向量序列,长度都和输入序列一样(假设为N)。由query和key 两个序列做点积就可以得到attention matrix,这个运算量是NN级的。这种方式最大的问题就是当序列长度太长的时候,对应的 Attention Matrix 维度太大,会给计算带来麻烦。当N很小的时候,运算量放在整个网络里面可以忽略不计,但当N很大的时候,self-attention就有可能主导整个网络的运算量,这时优化self-attention的计算就可以得到显著的影响,这样我们加快self attention 才会对神经网络有帮助。
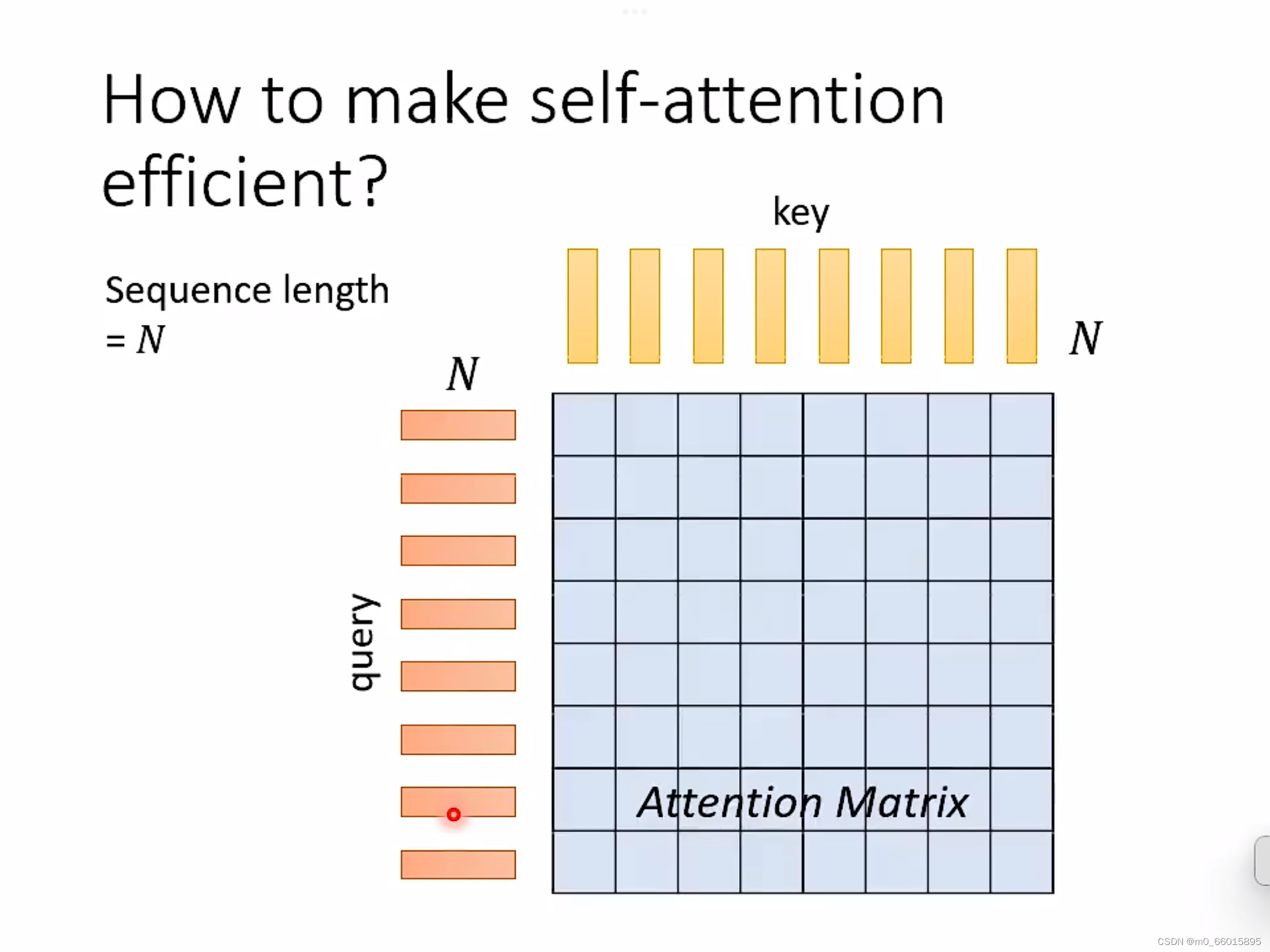
在self attention里面,我们最大的计算量就是要计算N*N的矩阵,因此主要是优化矩阵,有些问题在做self-attention的时候不用看全局信息,有些位置的数值不需要计算,怎么让self-attention更有效呢?方法有多种。
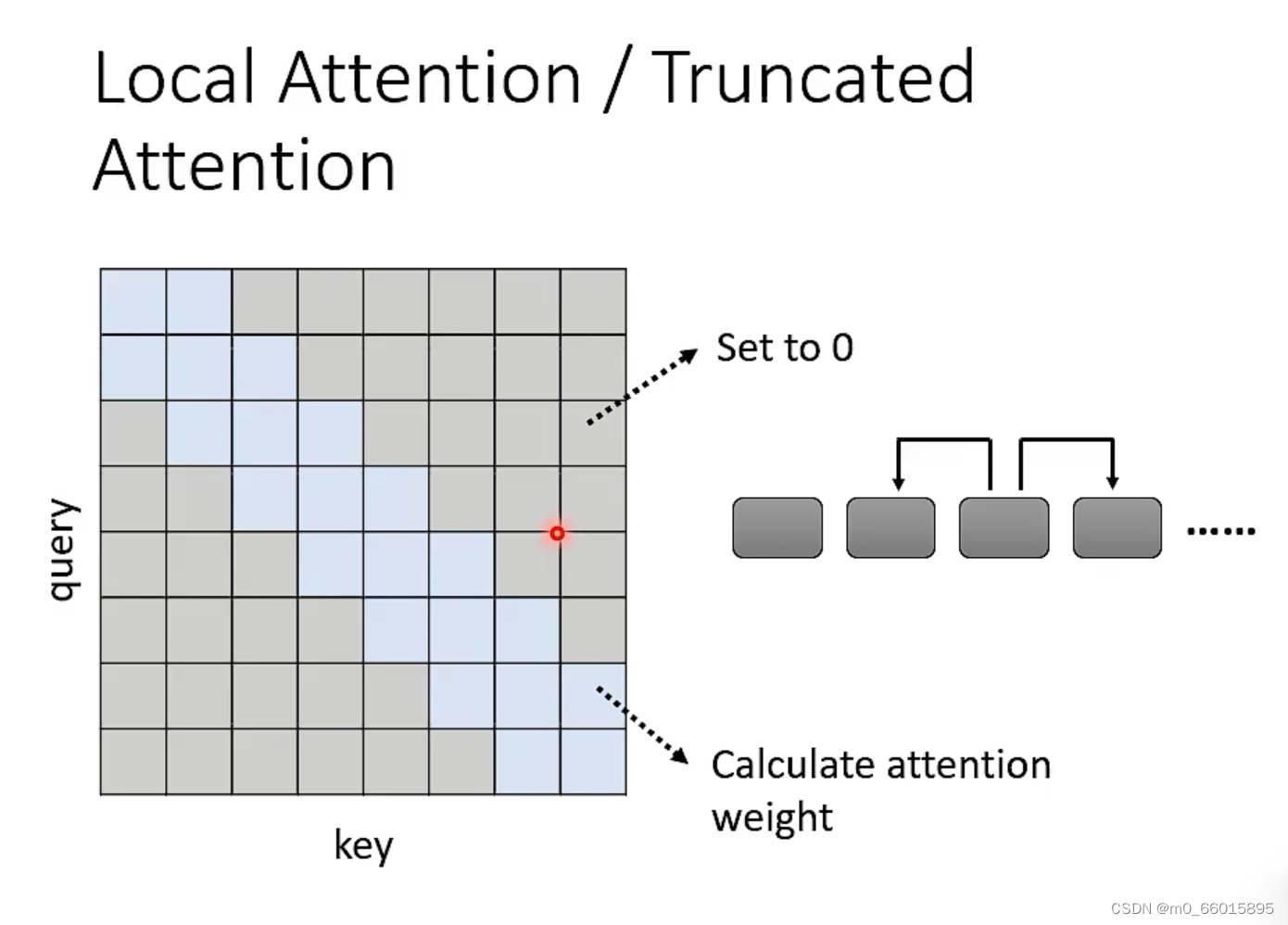
local attention/truncated attention
例如只看前后两个位置的时候,那么与其他位置的值就可以直接设置为0,例如图中灰色的位置。但是这个这个明显有问题,我们在做attention的时候只能看到小范围的数值,那这个就跟CNN非常相似了,local attention是可以加快我们的attention的方法,但是不一定能得到很好的结果。
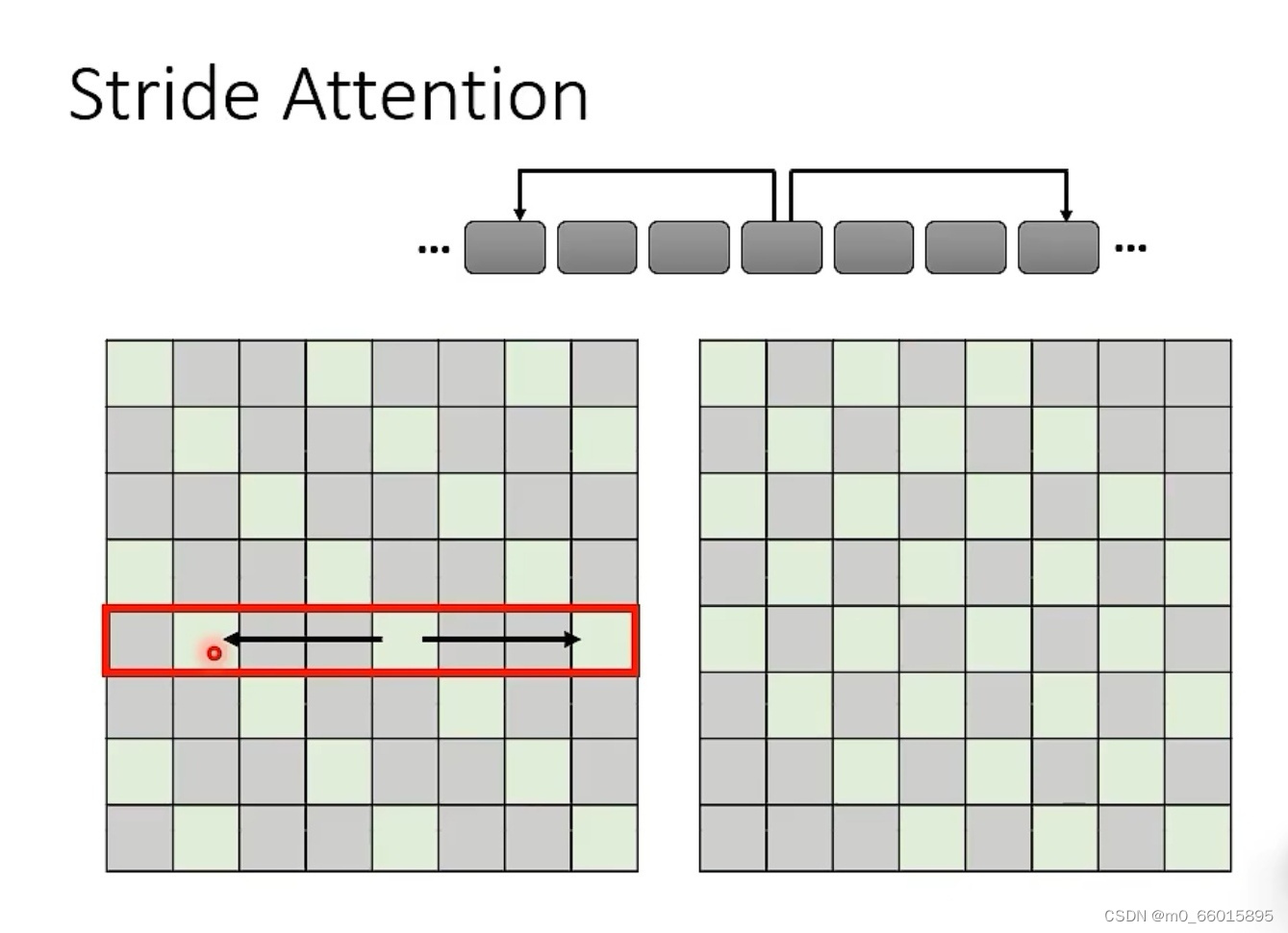
stride attention
上面是看前后一步的位置,这样只能看到局部的信息,而stride attention可以看指定步长的邻居,因此可以考虑范围相对广一些,下图的例子考虑间隔两格的邻居,步长设置为2,根据实际问题需要可以设置不同的步长。
global attention
如果需要考虑所有的输入,又不想计算量太大,就可以用到global attention。核心思想是加入一个特殊token到原始的sequence里面,在global attention,每个特殊的token都加入每一个token,收集全局信息。每个特殊的token都被其他所有的token加入,以用来获取全局信息。

这三种方法各有所长,并不是只能选择一种,因为有多个head,而每个head从不同的维度提取特征,因此对于不同的heads我们选择不同的attention。

Longformer 就是组合了上面的三种 attention
Big Bird 就是在 Longformer 基础上随机选择 attention 赋值,进一步提高计算效率。
data driving
在一个self-attention里面的矩阵里面,某些位置有很大的值,有些位置又有很小的值,那我们是否可以把很小的值变为0,那我们是否能估计矩阵哪里有大值,哪里有小值吗?这个方法叫做clustering。在reformer和routing transformer两篇文章里面,都用了一个方法——clustering。
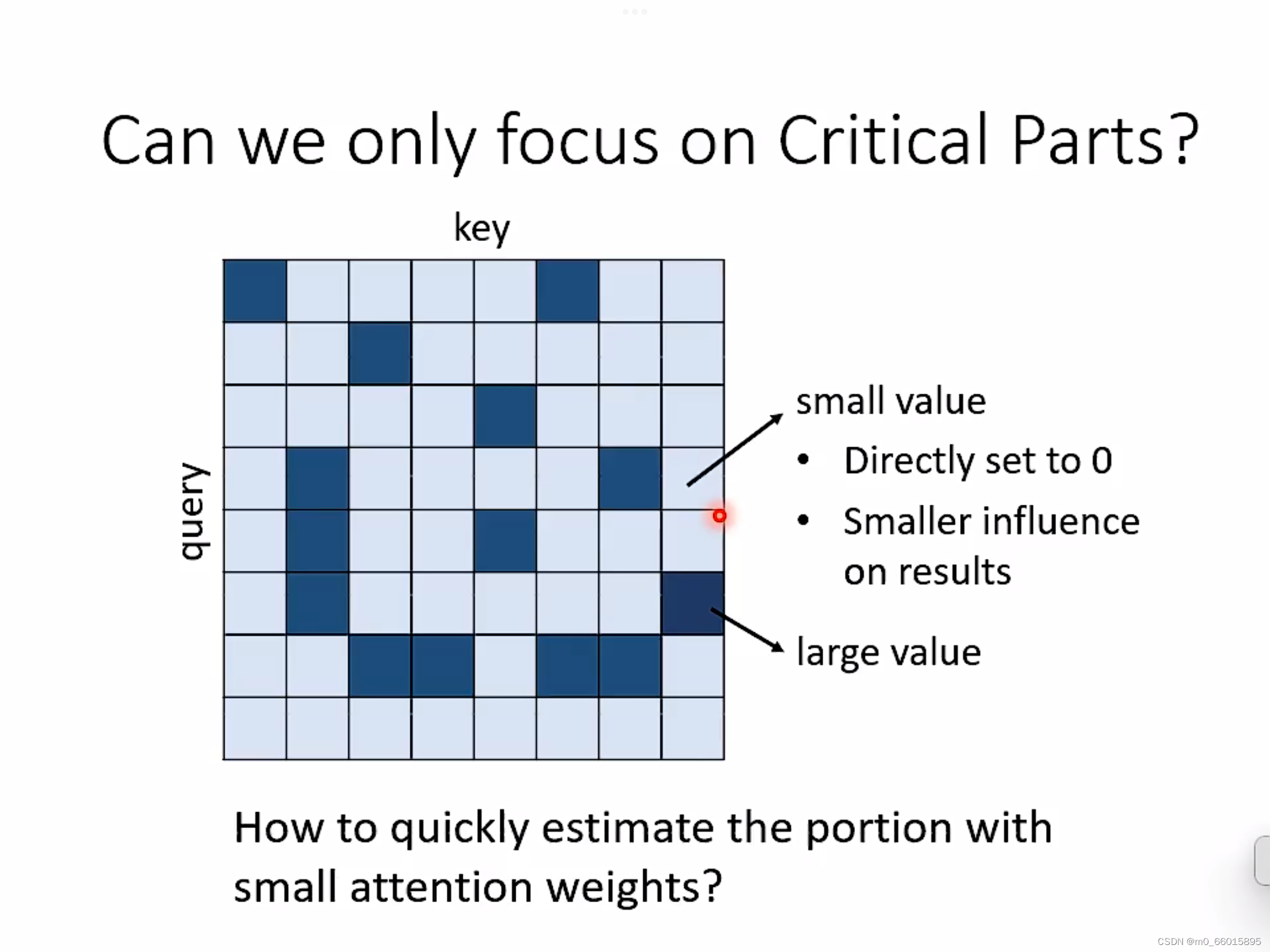
clustering
步骤一:我们先把query和key取出来,然后根据query和key的相近程度做clustering。对于相近的数据就放在一起,对于比较远的数据就属于不同的cluster。下面我们有四个cluster,用不同的颜色来标出。这里可能有个问题,我们在做cluster的时候可能会出现运算量大的问题!其实事实上我们的cluster还是有很多快速的方法的。

对于query和key形成的attention matrix来说,只有当query和key的cluster是一样的时候,我们才计算他们的attention weight。对于不属于同一个cluster的两个query和key,就把他们设为0。这种方法可以加速我们的运算,这是一种基于数据来决定的!

sinkhorn sorting network
上面的方法是通过人为决定attention matrix 里面哪些位置不需要计算。而在sinkhorn sorting network里面,#机器自己直接学习另外一个network来决定怎么输出这个矩阵。

我们把输入的序列,经过一个NN之后产生另外一排向量序列,生成一个N×N的的矩阵。我们要把这个生成的不是二进制的矩阵变成我们的attention matrix。这个过程是不用经过二进制变换的,可以直接输出attention matrix。
通过NN产生attention matrix的方法比直接计算要快吗?
虽然没有太大区别,但是在sinkhorn sorting network里面可以向量复用,好几个输入的向量会共用一个经过NN产生的向量。
在一篇linformer的文章里面提到,我们并不需要一个full attention matrix,因为在一个attention matrix里会有很多冗余的列,很多列都是重复的,因此可以去掉冗余的列,缩小attention matrix,加快attention的速度呢。简化attention matrix的方法:减少计算attention的key的数量。
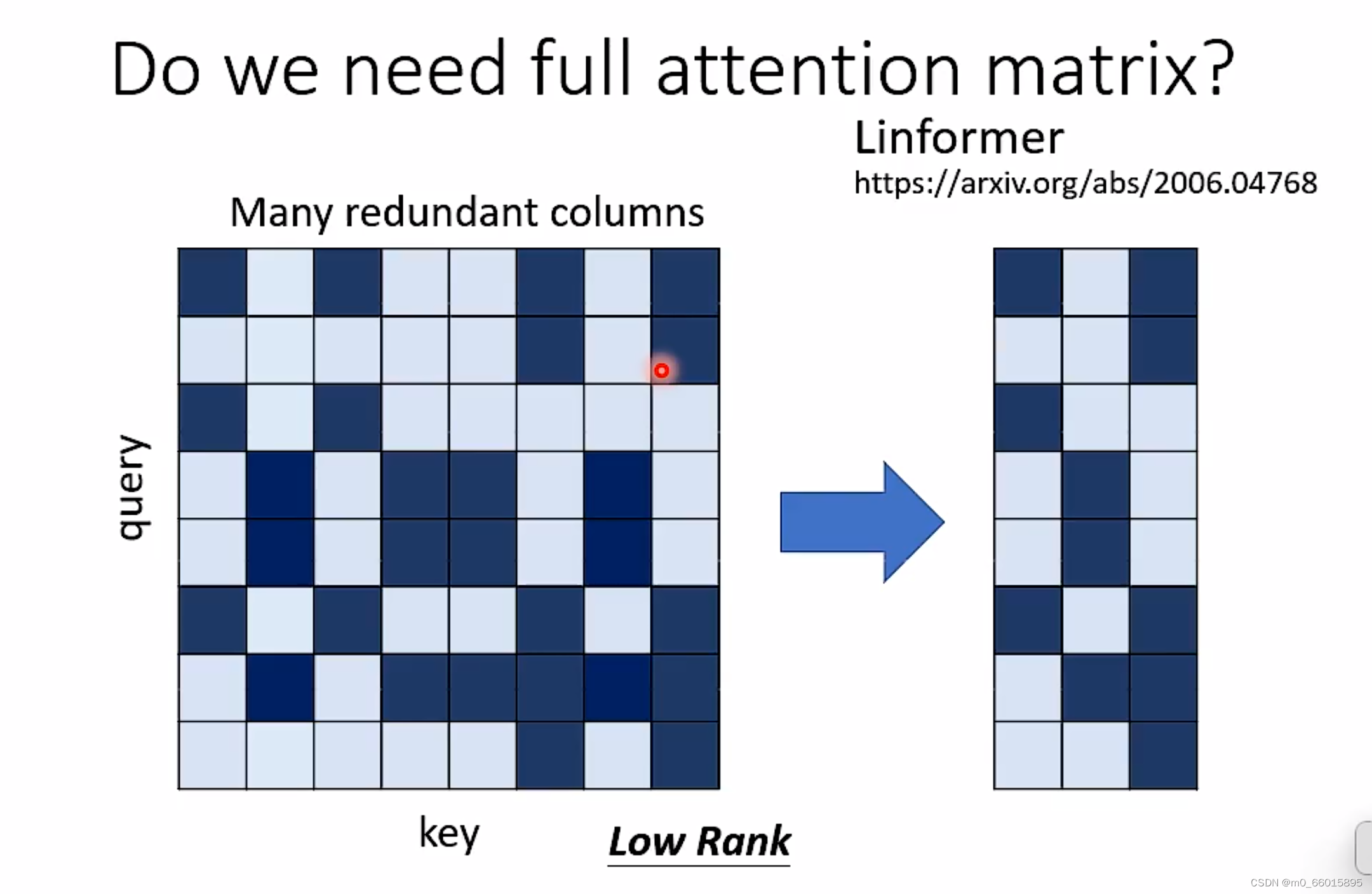
选取representative keys
假设有N个key,从中选取K个代表的key。然后与N个query序列相乘得到一个N×K的矩阵,然后从N个value,也选取K个代表value。然后我们把这K个value和attention matrix做weight sum加权和,就得到attention matrix layer的输出。

为什么选择代表key,而不选择代表query呢?
因为在self-attention里面输入和输出长度一致,如果改变了query的长度那么就改变了输出的长度,如果是输入一个序列输出一个数值的模型就可以选择代表query。
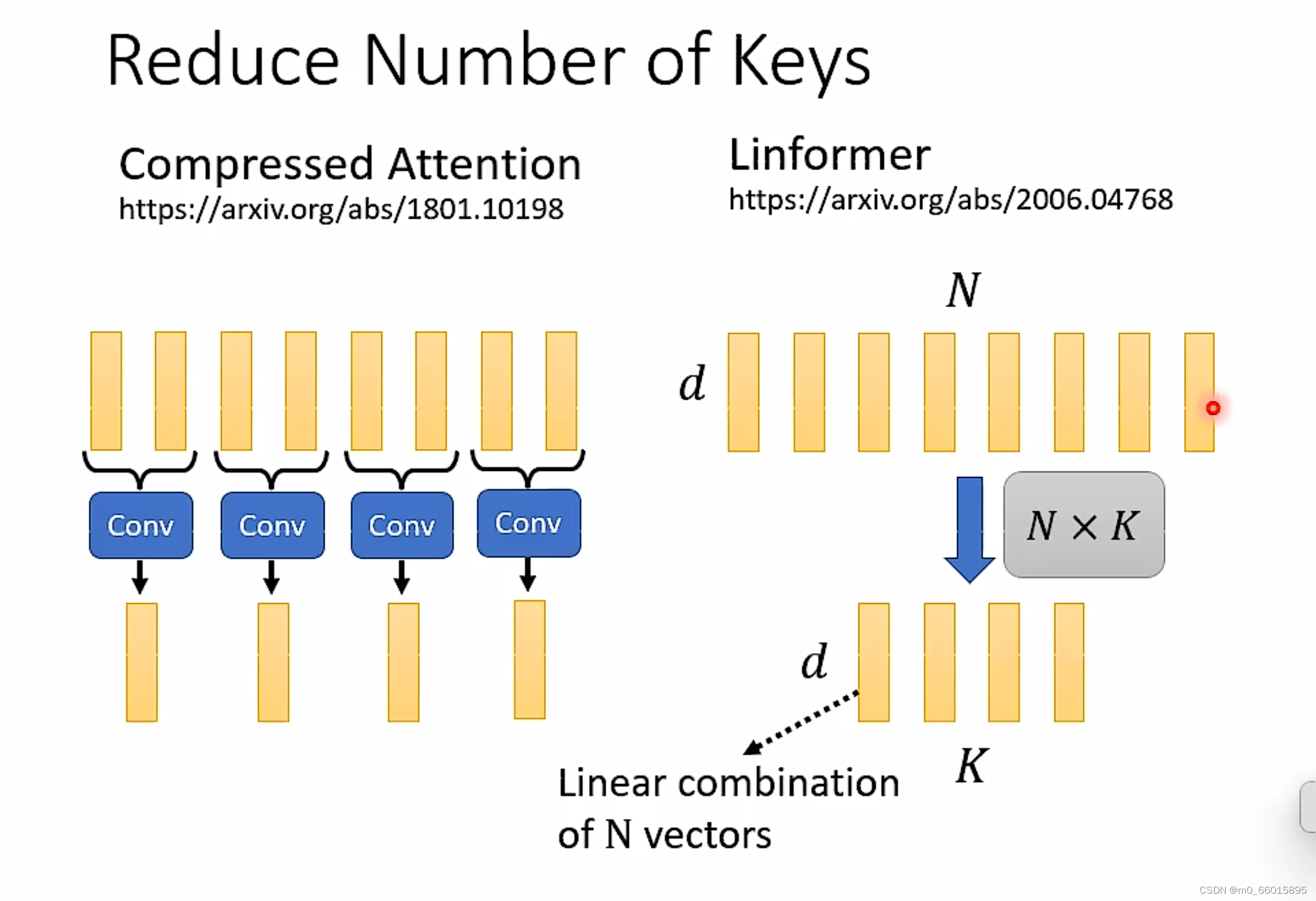
减少Keys的数量方法
一、用CNN来扫过输入的key序列,得到一个更短的序列,那这个就是代表性的key。
二、输入的key序列可以看成是一个d×N的矩阵,由线性代数知识可知,将一个k×N的矩阵乘上一个N×K的矩阵,然后就得到了d*K的矩阵。那这个得到的新矩阵就是代表性key序列。
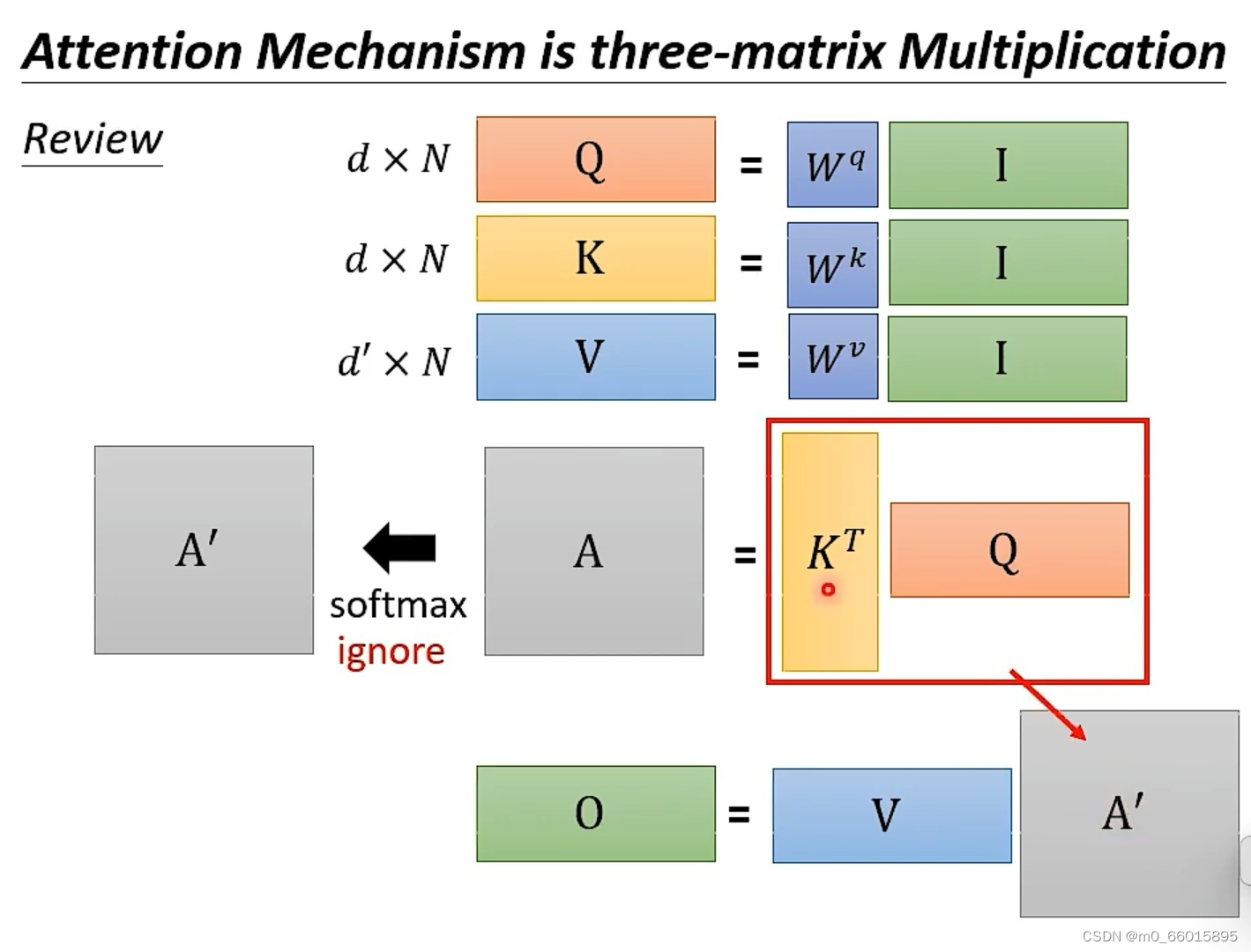
self-attention机制
其实attention的整个过程,其实就是矩阵相乘,输入是一个矩阵I,I乘上一个linear transformer Wq得到另外一个矩阵Q(dN)。然后再做以下的运算:Q和K的维度d要一样,因为要做点积。但是V可以不为dN。
省略softmax
因此这个过程有没有优化方法?假设我们没有做softmax这个步骤,那A=A’,O=VKTQ。
因此整个公式变成如下:

这三个矩阵前两个先乘与后两个先乘有什么不同?
计算结果相同当计算量不相同
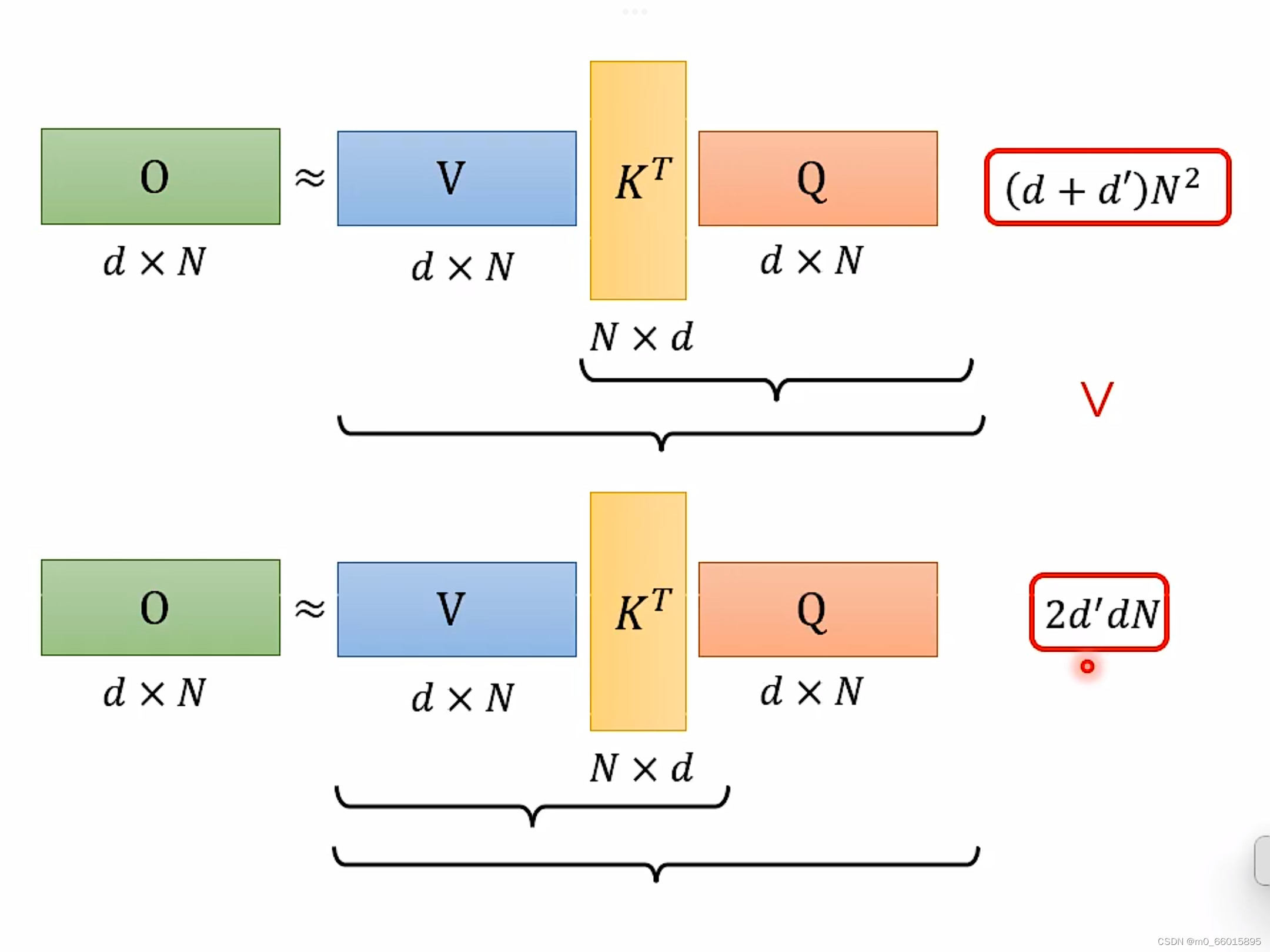
一、后两个先乘:KT和Q相乘的乘法次数需要N×d×N次,得到A(attention matrix)。V与A的乘法次数是d×N×N,因此计算得到O总的计算次数就是(d+d’)N^2。
二、前两个先乘:乘法次数只要2dd’N,比上面的计算量少了很多。
如果加上softmax,那么完整的计算过程如下:
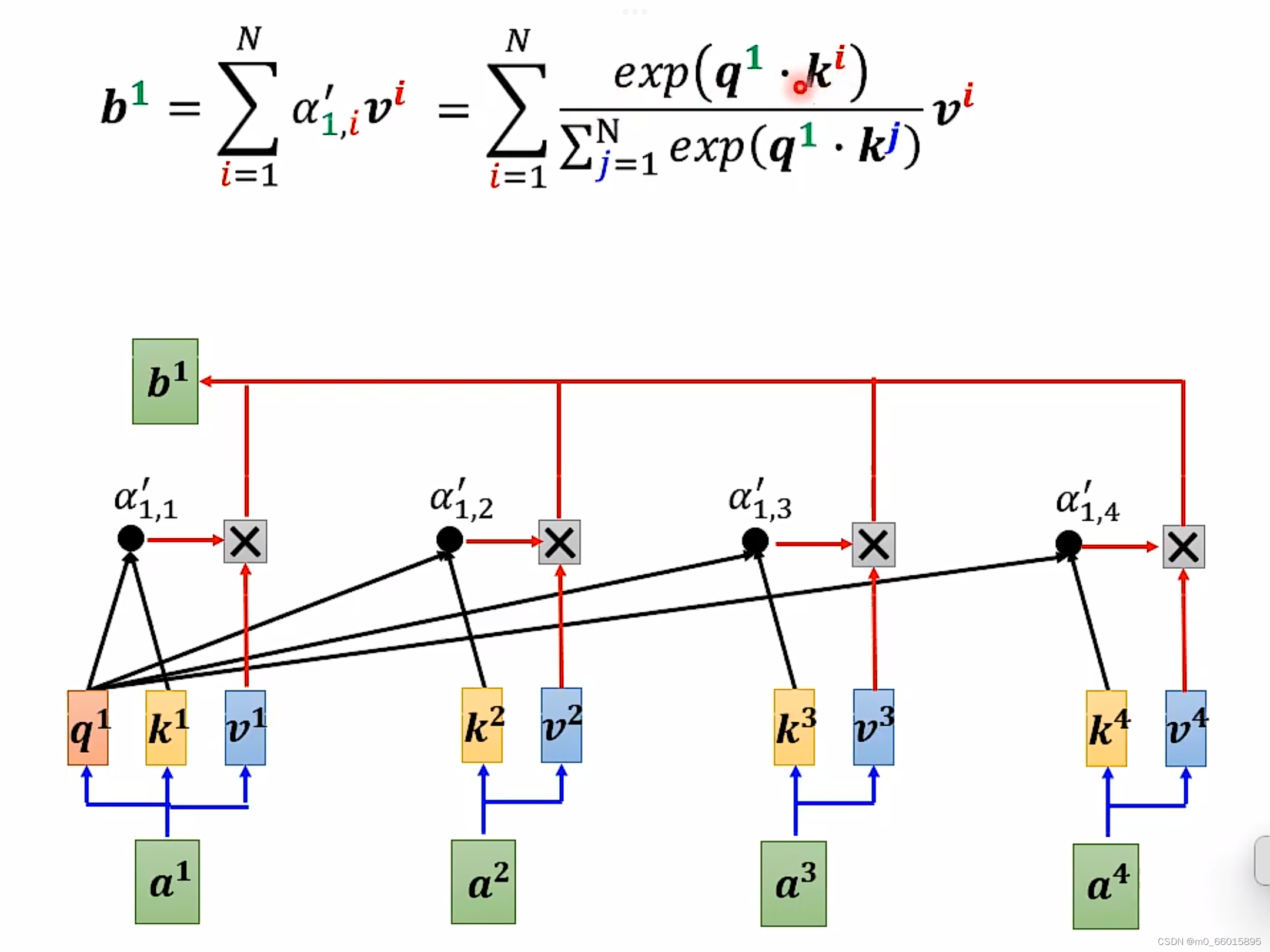
实际上图中的这个过程是可以简化的,通过转换的方法,把指数expornatial的矩阵运算变成φ的点积。

由下图可以看出蓝色的 vector 和黄色的 vector 其实跟 b1 中的 1 是没有关系的。
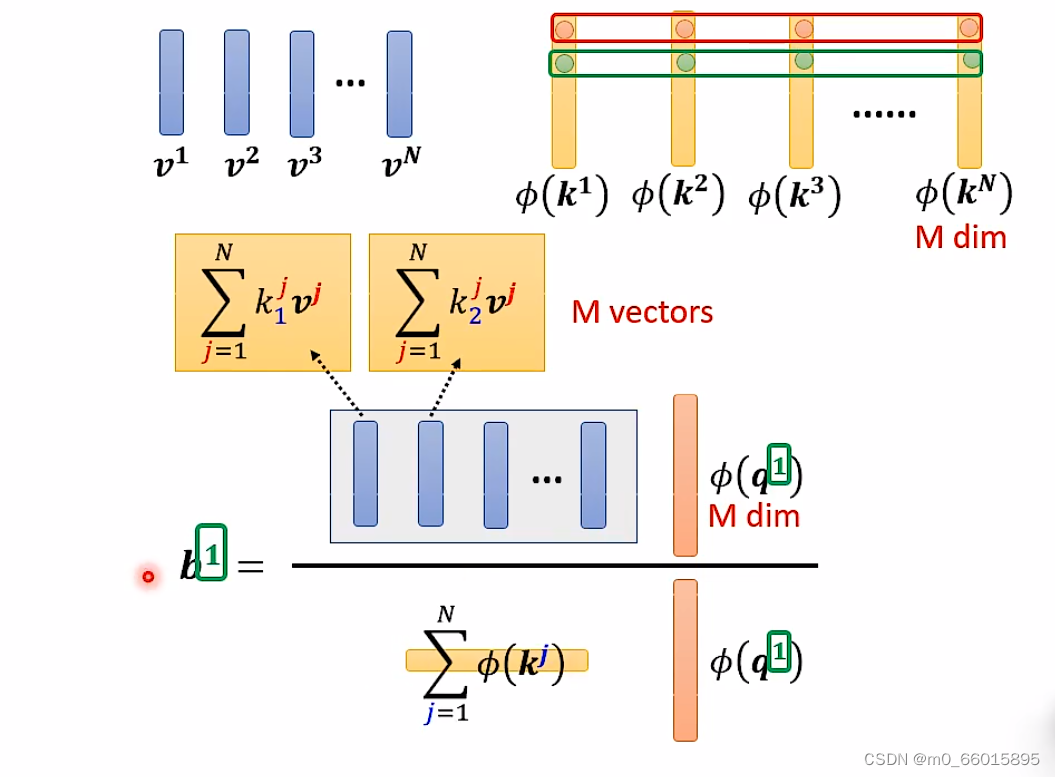
也就是说,当我们算 b2、b3... 的时候,蓝色的 vector 和黄色的 vector 不需要再重复计算,大大减少了重复的计算量。
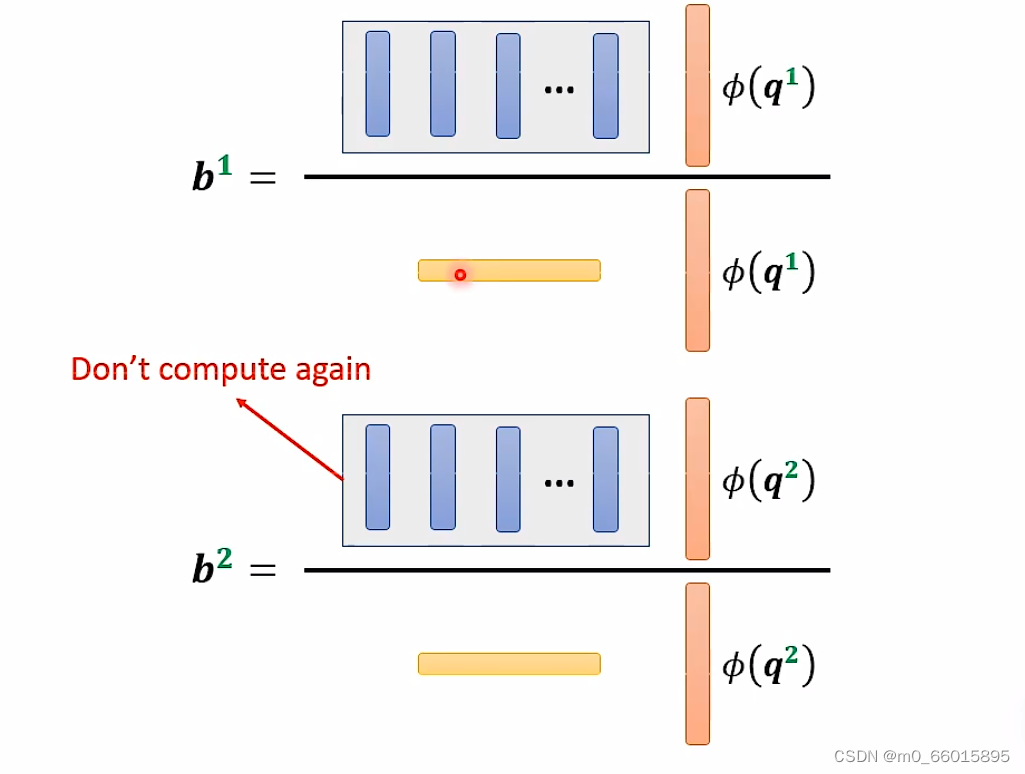
因此self-attention 还可以用另一种方法来看待。这个计算的方法跟原来的 self-attention 计算出的结果几乎一样,但是运算量会大幅度减少。简单来说,先找到一个转换的方式 φ(),首先将 k 进行转换,然后跟 v 做 dot-product 得到 M 维的 vector。再对 q 做转换,跟 M 对应维度相乘。其中 M 维的 vector 只需要计算一次。

计算b可知不用再计算q和v的点积,直接用b做经过转换后的向量与M维的向量做加权和即可得到b的值。
可以将 φ(k) 跟 v 计算得到的没一个 vector 当做一个 template,因此self-attention的过程可以理解为通过 φ(q) 去寻找哪个 template 是最重要的,也就是找哪个template对b的值有影响,并进行矩阵的运算,得到输出 b。
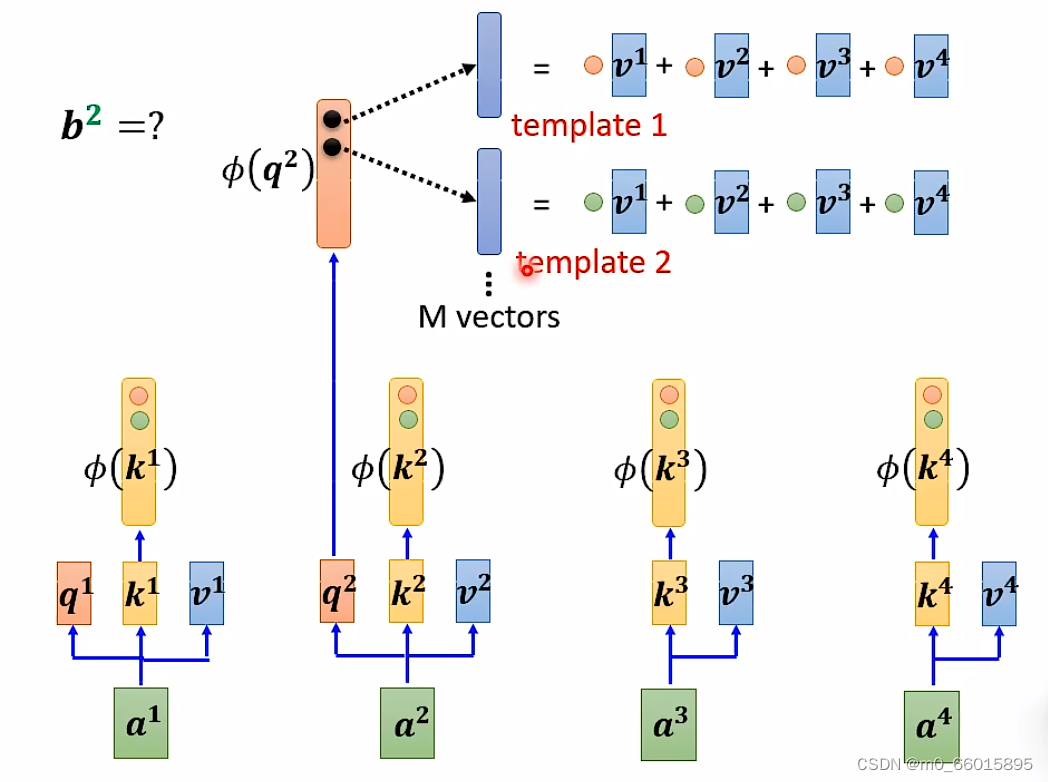
Synthesizer
在计算 self-attention 的时候一定需要 计算attention matrix吗?

不一定。在 Synthesizer 文献里面,对于 attention matrix 不是通过 q 和 k 得到的,而是作为网络参数学习得到。对于不同的输入而attention matrix作为网络参数是固定不变的,但这performance没有什么影响。
注意力机制结构代码
NLP中序注意力机制的计算过程可以分为以下几个步骤
1.输入序列:首先,需要输入一个包含多个元素的序列,这些元素通常是词语或者是字符。
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
]
x=torch.tensor(x,dtype=torch.float32)2.初始化权重
w_key=[[0,0,1],
[1,1,0],
[0,1,0],
[1,1,0]
]
w_query=[[1,0,1],
[1,0,0],
[0,0,1],
[0,1,1]
]
w_value=[[0,2,0],
[0,3,0],
[1,0,3],
[1,1,0]
]
w_key=torch.tensor(w_key,dtype=torch.float32)
w_query=torch.tensor(w_query,dtype=torch.float32)
w_value=torch.tensor(w_value,dtype=torch.float32)
3.计算keys、querys、values,对序列中的每个元素进行特征提取
keys = x @ w_key
#keys = numpy.matmul(x,w_key)
querys = x @ w_query
values = x @ w_value
print(keys)
# tensor([[0., 1., 1.],
# [4., 4., 0.],
# [2., 3., 1.]])
print(querys)
# tensor([[1., 0., 2.],
# [2., 2., 2.],
# [2., 1., 3.]])
print(values)
# tensor([[1., 2., 3.],
# [2., 8., 0.],
4.计算注意力分数:对于每个元素,都需要计算一个注意力分数,这个分数表示该元素的重要程度。通常来说,注意力分数是根据元素的特征向量和查询向量之间的相似度来计算的。
attn_scores = querys @ keys.T
print(attn_scores)
# tensor([[ 2., 4., 4.], # attention scores from Query 1
# [ 4., 16., 12.], # attention scores from Query 2
# [ 4., 12., 10.]]) # attention scores from Query 3
5.计算softmax层
attn_scores_softmax = softmax(attn_scores,dim=-1)#求每一行的softmax
print(attn_scores_softmax)
#attn_scores_softmax=[[0.0,0.5,0.5],
# [0.0,1.0,0.0],
# [0.0,0.9,0.1]
# ]
attn_scores_softmax=torch.tensor(attn_scores_softmax)
5.加权求和: 对于输入序列中的每个元素,都将其特征向量与查询向量进行比较,计算出一个注意力分数。然后,将所有元素的特征向量与注意力分数进行加权求和,得到一个新的向量,这个向量表示了输入序列中重要信息的概括。
print(values[:,None,:])
#print(attn_scores_softmax.T[:,:,None])
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
#None,即将维度(3,3)变为(3,1,3)。将维度(3,3)变为(3,3,1)
print(weighted_values)#(3,3,3)
# tensor([[[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]],
#
# [[1.0000, 4.0000, 0.0000],
# [2.0000, 8.0000, 0.0000],
# [1.8000, 7.2000, 0.0000]],
#
# [[1.0000, 3.0000, 1.5000],
# [0.0000, 0.0000, 0.0000],
# [0.2000, 0.6000, 0.3000]]])
6.得到输出
outputs = weighted_values.sum(dim=0)
#按第一维度相加
print(outputs)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3Self-Attention与Transformer的结构代码
将self-attention扩展到Transformer架构,实现注意力机制的代码会包含以下几个部分:
1.一个编码器,用于将输入序列编码成状态向量。
# 定义编码器
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
""" 初始化函数的参数有2个
第一个是input_size,代表词嵌入的维度大小, 同时也代表解码器层的尺寸,
第二个是hidden_size,代表隐藏层数量
"""
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size) #定义lstm
def forward(self, inputs, hidden):
# 将输入序列编码成状态向量
outputs, hidden = self.lstm(inputs, hidden)
return outputs, hidden
2.一个注意力机制,用于计算注意力权重,计算attention得分。
# 定义注意力机制
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size))
def forward(self, hidden, encoder_outputs):
# 计算注意力权重
max_len = encoder_outputs.size(0)
h = hidden.repeat(max_len, 1, 1).transpose(0, 1)
attn_energies = self.score(h, encoder_outputs)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
def score(self, hidden, encoder_outputs):
# 计算注意力得分
energy = F.tanh(self.attn(torch.cat([hidden, encoder_outputs], 2)))
energy = energy.transpose(1, 2)
v = self.v.repeat(energy.size(0), 1).unsqueeze(1)
energy = torch.bmm(v, energy).squeeze(1)
return energy
3.一个解码器,用于根据注意力权重来生成输出序列。
# 定义编码器
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attention = Attention(self.hidden_size)
self.gru = nn.GRU(self.hidden_size * 2, self.hidden_size)
self.out = nn.Linear(self.hidden_size * 2, self.output_size)
def forward(self, input, hidden, encoder_outputs):
# 解码生成输出序列
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = self.attention(hidden, encoder_outputs)
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
context = context.transpose(0, 1)
output, hidden = self.gru(torch.cat([embedded, context], 2), hidden)
output = F.log_softmax(self.out(torch.cat([output, context], 2)), dim=1)
return output, hidden, attn_weights
总结
最后这页图为所有讲述的方法的总结。下图中,纵轴的 LRA Score 数值越大,则网络表现越好;横轴表示每秒可以处理多少 sequence,越往右速度越快;圈圈越大,代表用到的 memory 越多(计算量越大)。

这周学习了之前了解的自注意力机制的各种改进形式,在不改变结果和表现的情况下,降低计算复杂度,加快模型的处理速度。通过推导分清楚求解以及优化的过程。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









