






在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程:

从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出主角—Flume
首先我们介绍Flume(日志收集系统):

flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
数据处理:
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力
Flume优势:
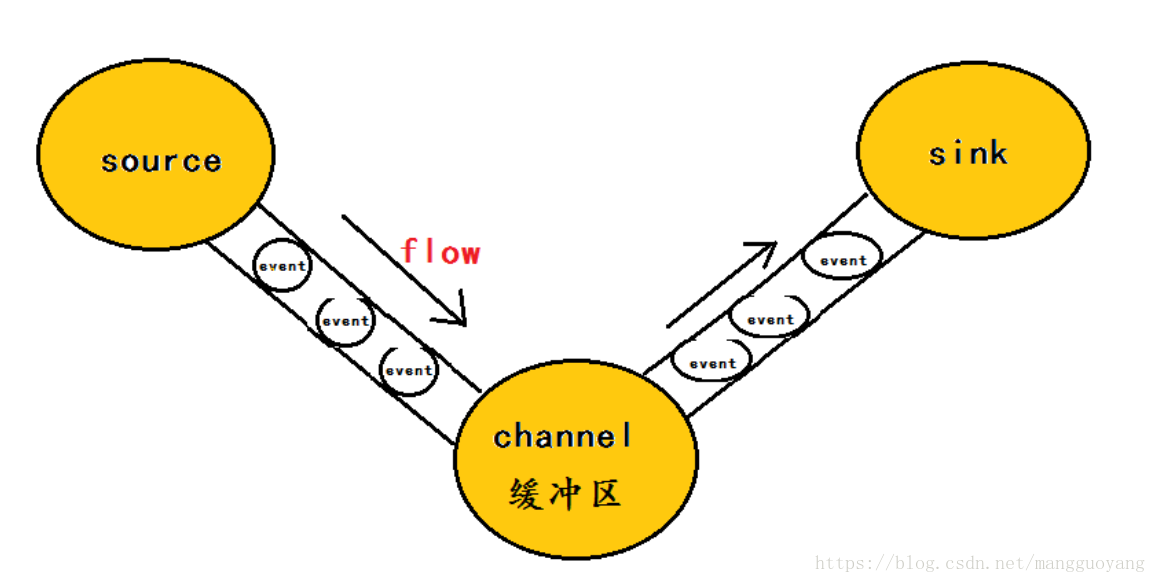
结构:
Agent主要由:source,channel,sink三个组件组成.
现在我们来安装Flume:
Flume版本: apache-flume-1.8.0-bin.tar.gz
下载完成后通过xftp传到Linux下的opt里,然后解压文件
tar -zxvf apache-flume-1.8.0-bin.tar.gz

解压完成后,我们需要在Flume的conf下创建新文件 a1.conf 并进行编辑:


我们在进行编写的时候注意:主机名换成我们自己的,我的端口号是22,但我这里写的是44444,我们尽量写4位数以上的。
上图所示的命令后是有注释的,最好不要在后面跟注释,不然会报错。

编辑完a1.conf后,我们启动agent,这个命令是需要回到flume-bin目录下运行,不然会报错
命令是:./bin/flume-ng agent -c conf -f conf/a1.conf -n a1 -Dflume.root.logger=INFO,console
我这里文件名是a1.conf,所以命令里是a1,根据自己文件名所写。

我们输入启动命令后,单独新建一个没有连接虚拟机的窗口。并给Flume发送事件,telnet python5 44444
输完命令后,到了如下图这里挺住后,我们输入hellow 如果返回ok,并在启动agent窗口监听到hellow,就
说明我们这里配置成功。我们现在已经可以监听网络了。
注:如果长时间不操作,自动断开。

还可以监听文件和目录:
我们现在进行监控文件的操作。
首先,我们在hadoop的根目录下创建一个测试文件a1.test

我们来修改我们刚才的a1.conf文件;也可以复制一份,但是里面的所有和文件名不能是a1.

其实,我们发现这个文件主要是改动了source里面的参数,监听的值换成了exec和监听的主机名换成了我们刚刚创建的那个测试文件的路径了。
然后我们重新启动我们的agent 命名还是刚刚那个特别长的。
这是我们在新的窗口(已连接hadoop)给测试文件里添加内容,但是好像不能是中文,我的中文乱码,也有长度显示限制,我添加的内容只显示一半。

由于我们刚刚监控了这个文件,所以我们一添加完内容,就会被收走。

我们最后学习监控目录
首先我们先创建一个目录用于测试

在这里为了跟之前有冲突,我们这里新建了一个a4.conf的文件。

并编辑a4.conf文件:

改这个文件要仔细,我是复制a1的文件,里面的有些都不能跟a1重复,全换成a4,不然运行时会异常。无法监听。
编辑完成后启动命令,
然后我们将刚才创建的a1.test文件放在a1_test目录中 我们就可以收集到a1.test里面的整体内容,并且添加进去的文件会出现这个后缀 .completed


在hadoop里出现这个文件夹,这里的名字跟a4里面的是一起的,里面如果有你刚刚监听到的文件,就证明这里配置没问题了。
也可以通过命令hadoop fs -ls :

这样我们就实现了通过Flume对网络,文件,目录的监控。















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









