



本文转载于个人博客:https://docs.wziqi.vip/
此处省略搭建ES集群和Kibana连接的步骤,可以看前一篇帖子有详细文档
理论
filebeat: (数据采集,数据传输)
input ---> 指定源数据
output ---> 指定数据的目的地
ElasticSearch:
索引(index) ---> 数据的逻辑存储名称
分片(shard) ---> 一个索引至少有一个或多个分片
副本(replica) ---> 一个分片至少有0或多个副本
Kibana:
索引模式 ---> ES上的索引,创建索引模式时至少匹配一个或多个索引
偏移量数据存储文件目录:/var/lib/filebeat/文档地址
官网文档地址: https://www.elastic.co/guide/index.html
rpm包/源码下载地址:https://www.elastic.co/cn/downloads
filebeat rpm包下载:wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.14.0-x86_64.rpm
filebeat官方文档:https://www.elastic.co/guide/en/beats/filebeat/7.14/configuration-filebeat-options.html环境准备
# 切到一个单独目录
mkdir /opt/es && cd /opt/es
# 安装filebeat 跟ES版本一致
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.14.0-x86_64.rpm
yum -y localinstall filebeat-7.14.0-x86_64.rpm开始配置收集日志
流程图

先创建两个测试文件
touch /var/log/elk-test.log
touch /var/log/elk-prod.log创建filebeat配置文件
# 切到filebeat工作目录
cd /etc/filebeat# 创建配置文件
vim filebeat.yml
filebeat.inputs: # Filebeat 的输入配置开始的地方
- type: log # 这是一个日志输入类型从文件中获取
enabled: true # 这个输入被启用
paths: # 这个输入会读取以下路径的日志文件
- /var/log/elk-prod.log # 这是要读取的日志文件的路径
tags: ["prod"] # 这个输入的日志会被添加 "prod" 标签方便筛选日志
- type: log # 这是另一个日志输入类型
enabled: true # 这个输入也被启用
paths: # 这个输入会读取以下路径的日志文件
- /var/log/elk-test.log # 这是要读取的另一个日志文件的路径
tags: ["test"] # 这个输入的日志会被添加 "test" 标签方便筛选日志
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "nginx-prod-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "prod" 时,使用这个索引名规则
when.contains: # 当满足以下条件时
tags: "prod" # 日志的标签包含 "prod" 的创建到一个索引中
- index: "nginx-test-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "test" 时,使用这个索引名规则
when.contains: # 当满足以下条件时
tags: "test" # 日志的标签包含 "test" 的创建到一个索引中
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1官网配置文档地址:Configure inputs | Filebeat Reference [7.14] | Elastic
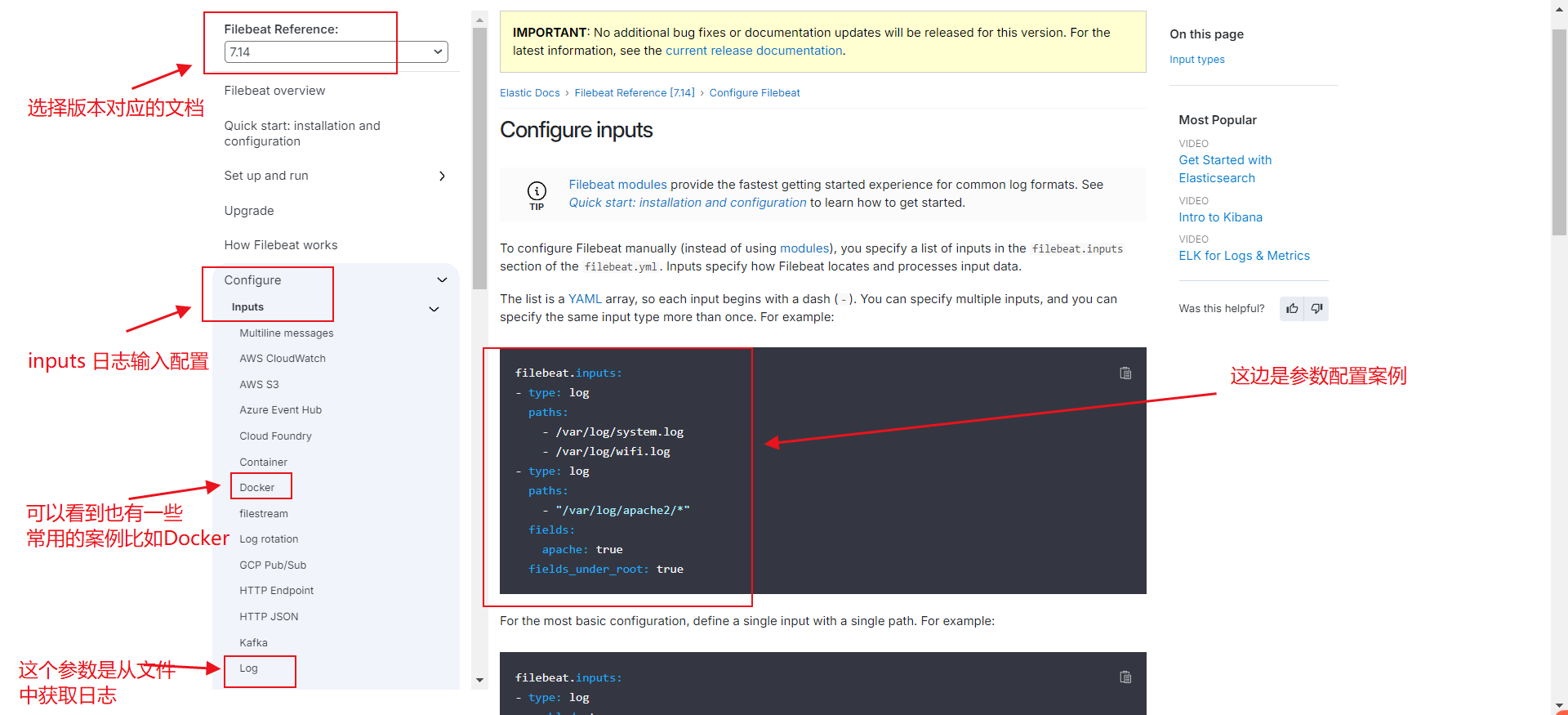
测试日志收集效果
启动filebeat
# 在安装了filebeat的机器执行启动命令
filebeat -e -c filebeat.yml
启动后等下不报错之后就去写入日志测试效果
echo elk-test-01 >> /var/log/elk-test.log && echo elk-test-02 >> /var/log/elk-test.log && echo elk-test-03 >> /var/log/elk-test.log && echo elk-test-04 >> /var/log/elk-test.log && echo elk-test-05 >> /var/log/elk-test.log && echo elk-test-06 >> /var/log/elk-test.log
echo elk-prod-01 >> /var/log/elk-prod.log && echo elk-prod-02 >> /var/log/elk-prod.log && echo elk-prod-03 >> /var/log/elk-prod.log && echo elk-prod-04 >> /var/log/elk-prod.log && echoelk-prod-05 >> /var/log/elk-prod.log && echoelk-prod-06 >> /var/log/elk-prod.logkibana查看
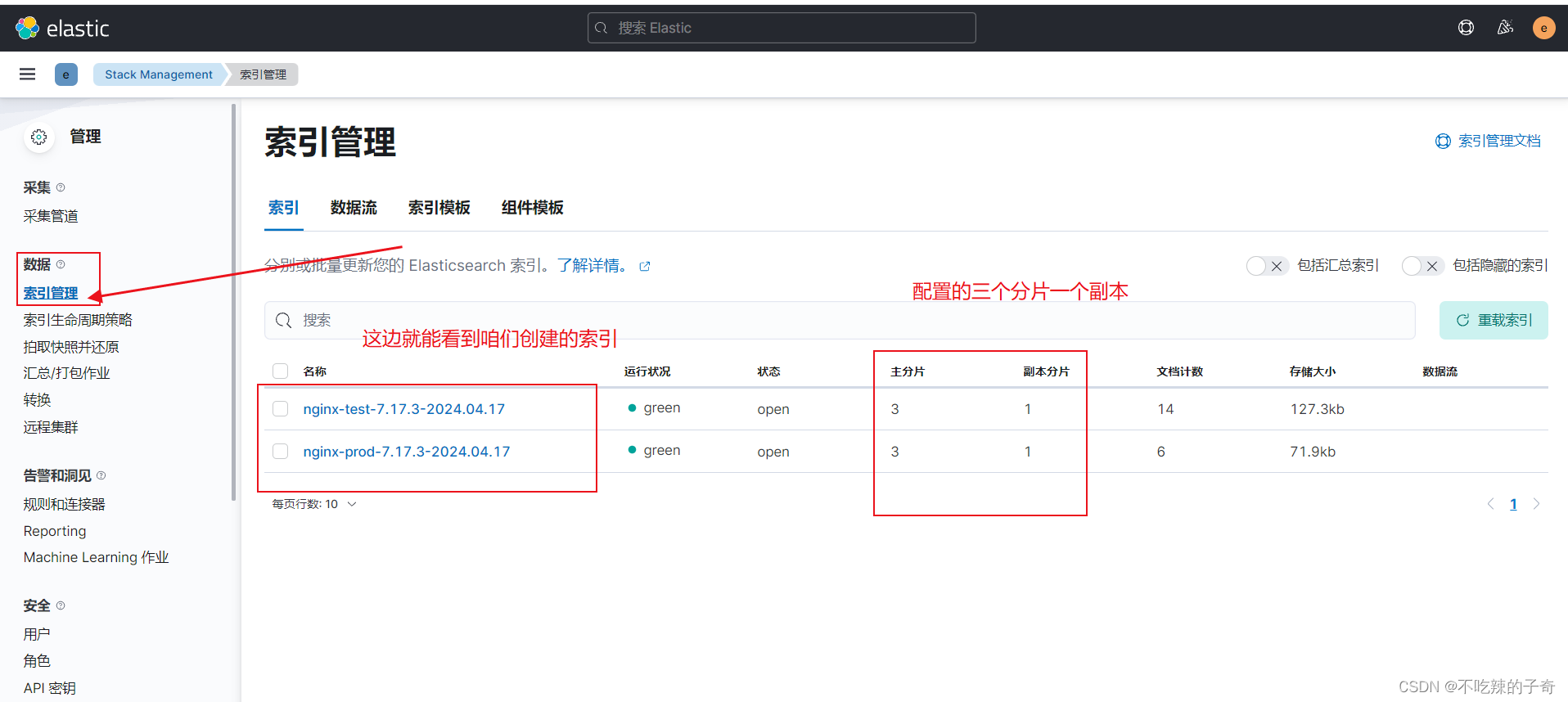
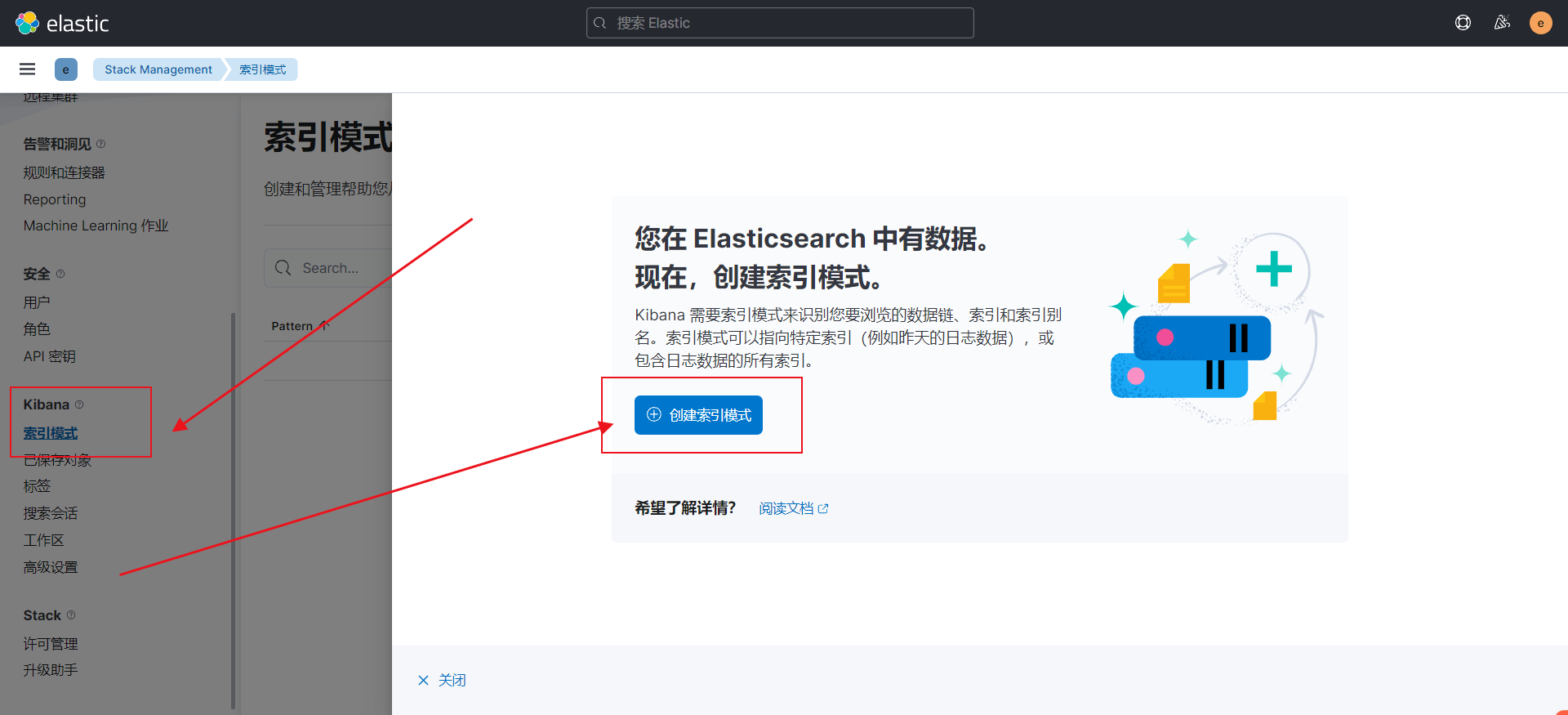
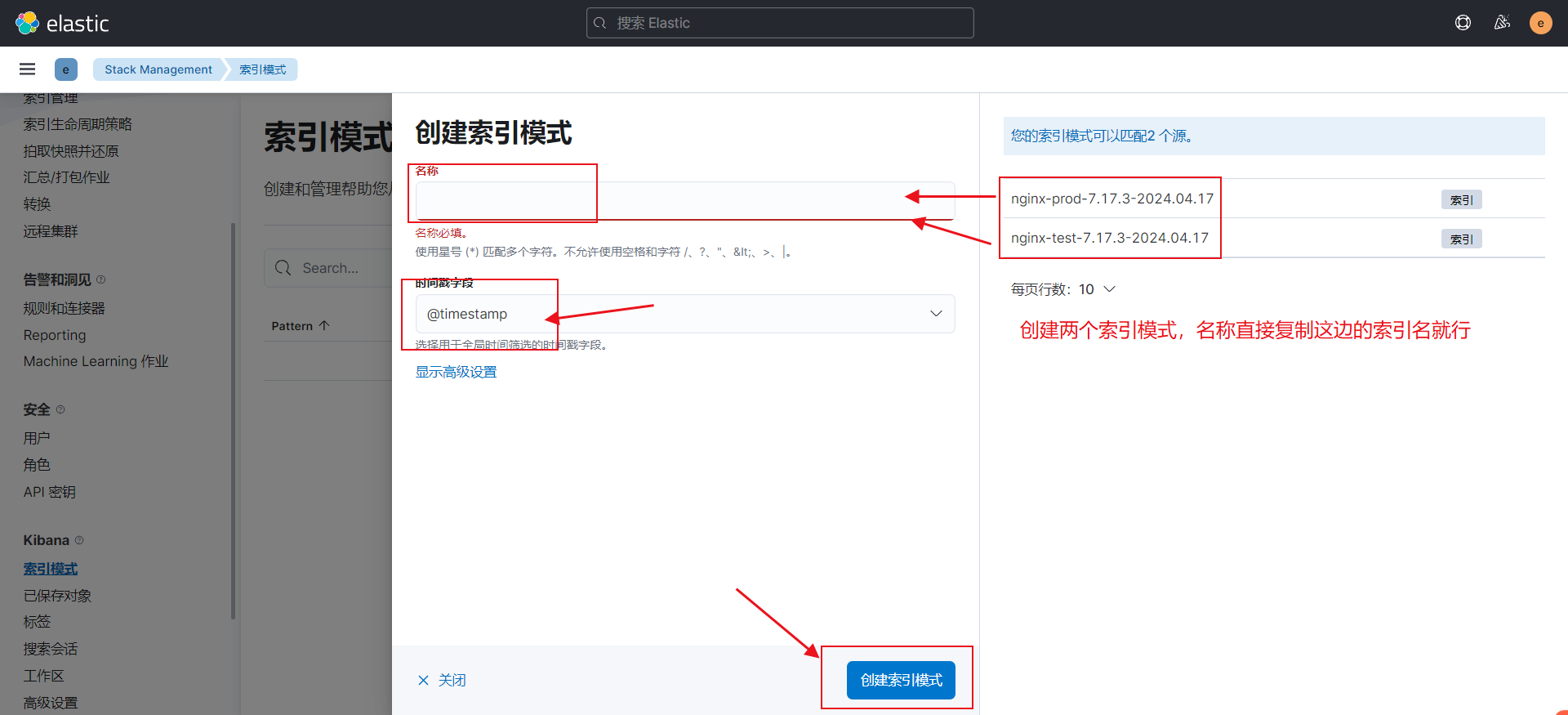

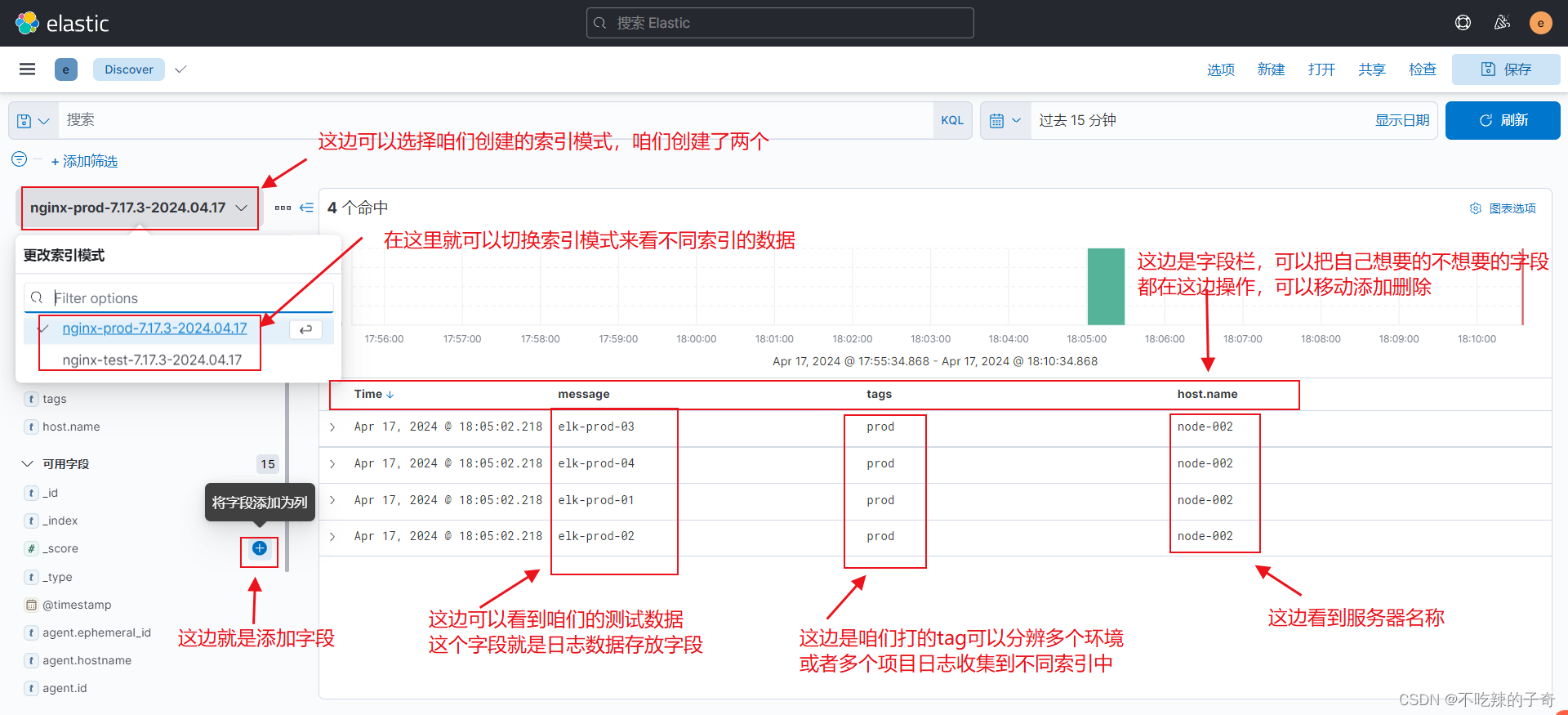
启动两个filebeat.yml实例
filebeat -e -c filebeat1.yml # 第一个
mkdir filebeat2 # 创建一个数据目录
filebeat -e -c filebeat2.yml --path.data=./filebeat2 # 启动第二个案例演示
1. nginx日志以json方式收集
流程图
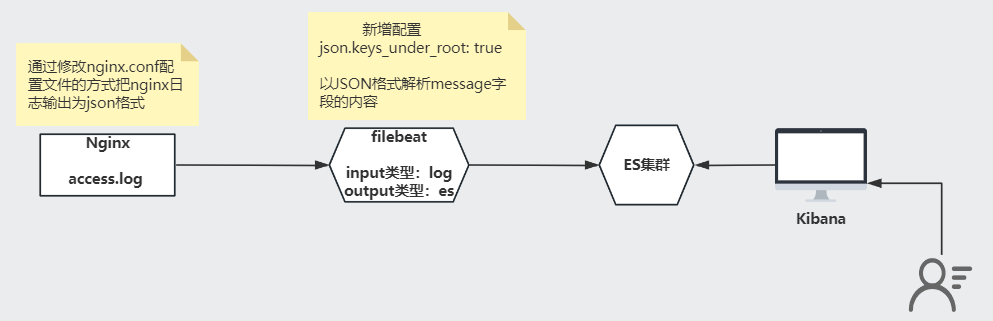
1)修改nginx配置文件
vim /etc/nginx/nginx.conf
...
log_format oldboyedu_nginx_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,' '"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"uri":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"tcp_xff":"$proxy_protocol_addr",'
'"http_user_agent":"$http_user_agent",'
'"status":"$status"}';
access_log /var/log/nginx/access.log oldboyedu_nginx_json;2)检查nginx配置文件重启
nginx -t
nginx -s reload3)修改filebeat配置文件
cd /etc/filebeat/ && vim filebeat.yml
filebeat.inputs:
- type: log # 配置log格式
paths:
- /var/log/nginx/access.log # 配置文件路径
tags: ["nginx"]
json.keys_under_root: true # 以JSON格式解析message字段的内容
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作为输出
#enabled: true
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "nginx" 时,使用这个索引名规则
when.contains: # 当满足以下条件时
tags: "nginx" # 日志的标签包含 "nginx" 的创建到一个索引中
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 14)测试效果
filebeat -e -c filebeat.yml5)可以看到索引已经创建
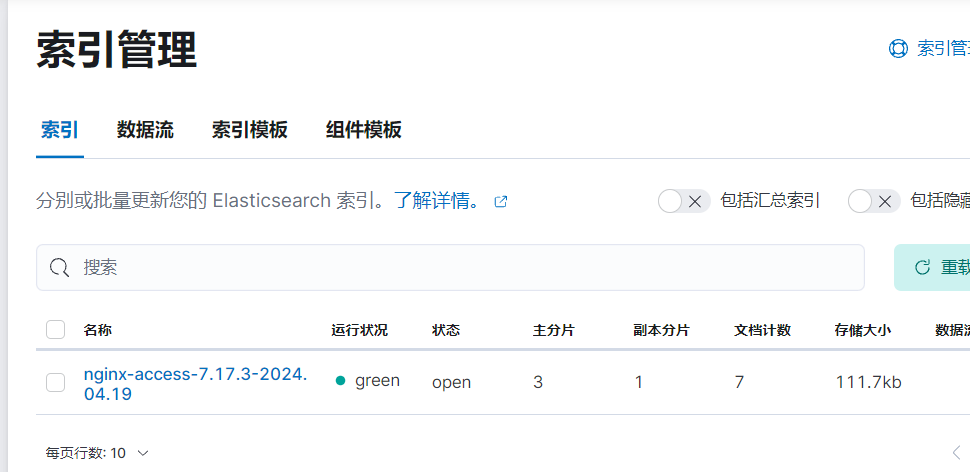
6)查看json格式日志,可以自定义想查看的key
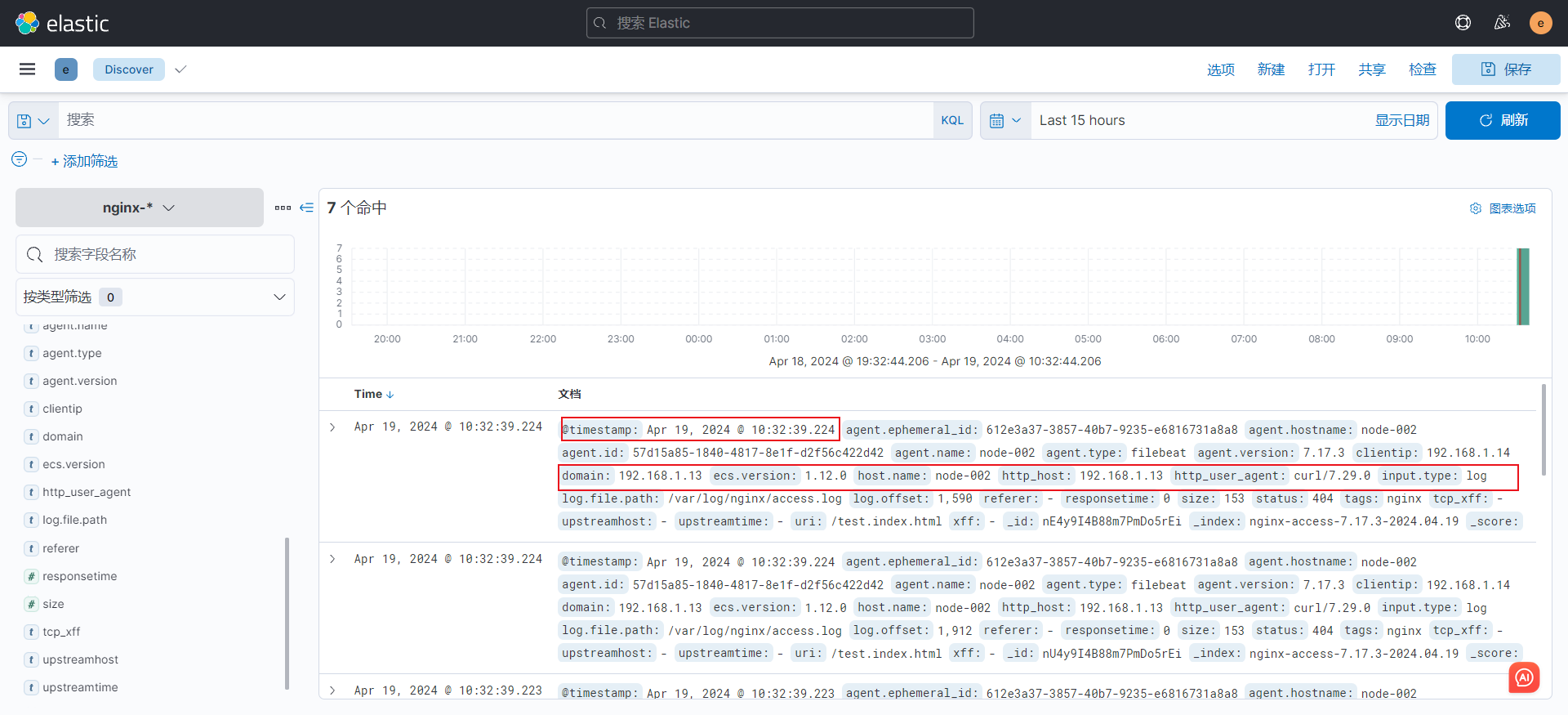
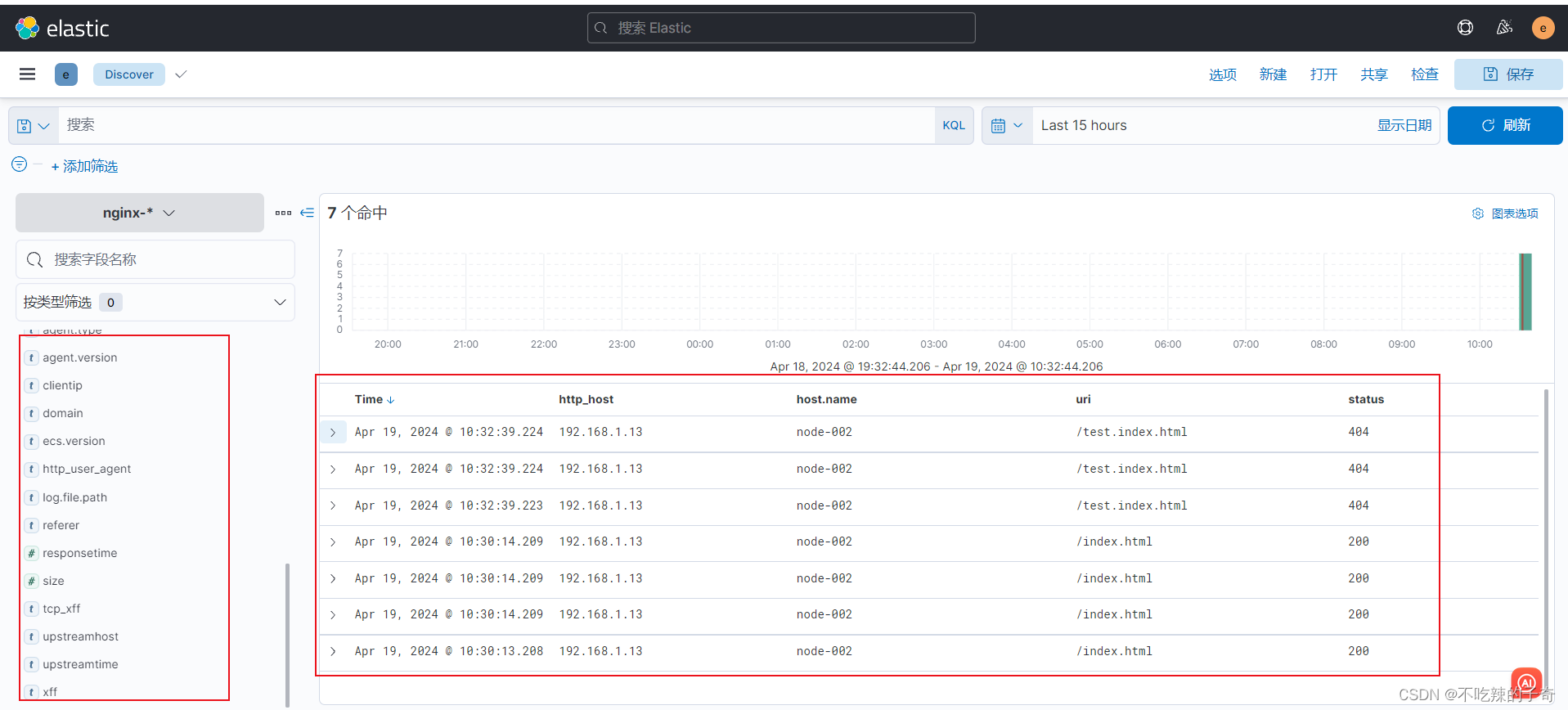
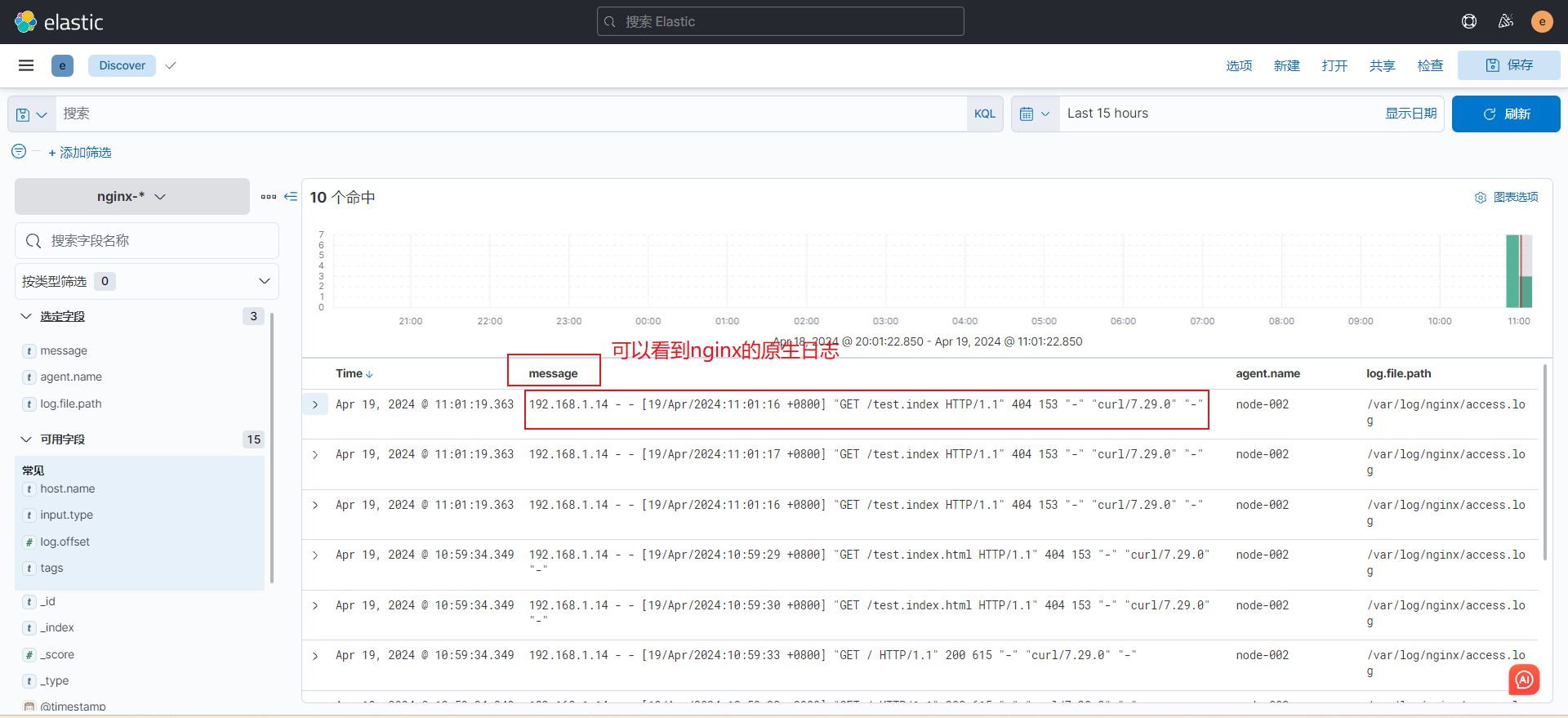
2. 收集nginx原生日志
流程图
1)nginx配置文件log日志格式不用动
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;2)修改 filebeat.yml
filebeat.inputs:
- type: log # 配置log格式
paths:
- /var/log/nginx/access.log # 配置文件路径
tags: ["nginx"]
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
#enabled: true
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "nginx-access-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "nginx" 时,使用这个>索引名规则
when.contains: # 当满足以下条件时
tags: "nginx" # 日志的标签包含 "nginx" 的创建到>一个索引中
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 13)测试效果
filebeat -e -c filebeat.yml
3. 收集Docker容器日志
流程图
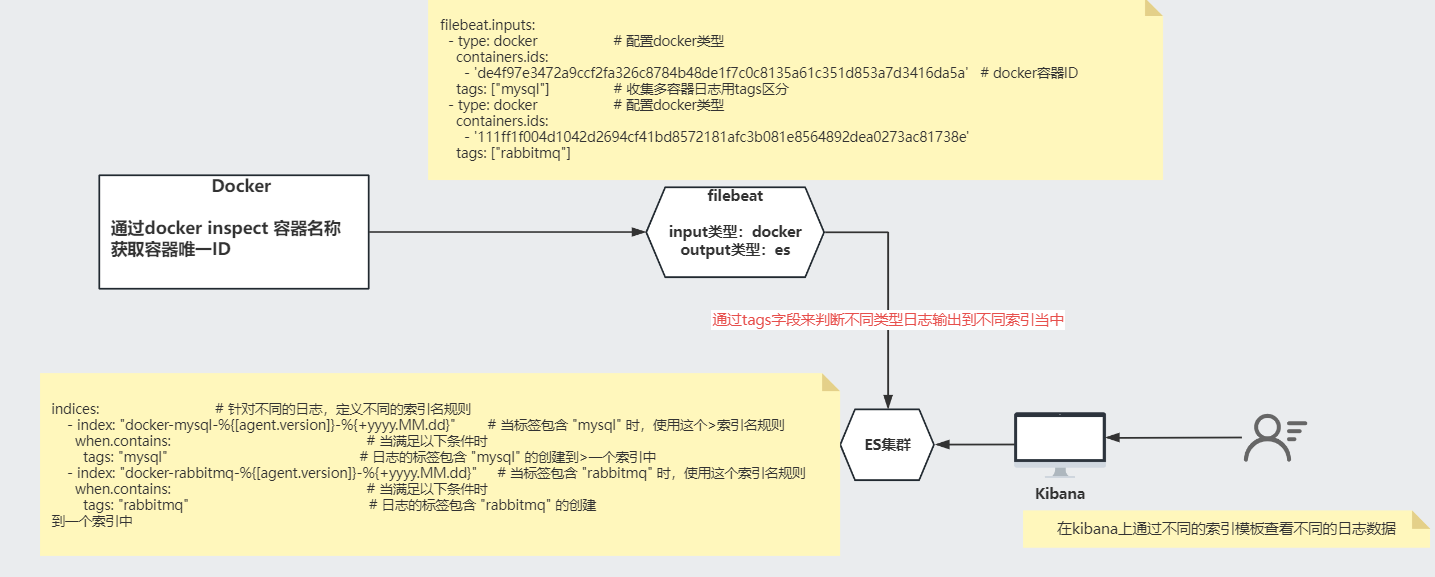
官方文档:Docker input | Filebeat Reference [7.17] | Elastic
1)获取docker容器id
指定 docker inspect 命令来获取一下容器的唯一ID
docker inspect mysql8.0
[
{
"Id": "de4f97e3472a9ccf2fa326c8784b48de1f7c0c8135a61c351d853a7d3416da5a", # 就这条
"Created": "2024-04-18T09:05:40.538032621Z",
"Path": "docker-entrypoint.sh",
"Args": [
"mysqld"
],2)修改filebeat.yml文件
containers.ids是根据容器id来找到对应的容器的,但是如果容器重新构建id变更了就会有问题,所以也可以用containers.path来指定容器的目录,启动容器的时候配置 -v /tmp/docker/{name}/:/logs ,把容器的日志文件映射出来filebeat.inputs:
- type: docker # 配置docker类型
containers.ids:
- 'de4f97e3472a9ccf2fa326c8784b48de1f7c0c8135a61c351d853a7d3416da5a' # docker容器ID
tags: ["mysql"] # 收集多容器日志用tags区分
- type: docker # 配置docker类型
containers.ids:
- '111ff1f004d1042d2694cf41bd8572181afc3b081e8564892dea0273ac81738e'
tags: ["rabbitmq"]
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "docker-mysql-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "mysql" 时,使用这个>索引名规则
when.contains: # 当满足以下条件时
tags: "mysql" # 日志的标签包含 "mysql" 的创建到>一个索引中
- index: "docker-rabbitmq-%{[agent.version]}-%{+yyyy.MM.dd}" # 当标签包含 "rabbitmq" 时,使用这个索引名规则
when.contains: # 当满足以下条件时
tags: "rabbitmq" # 日志的标签包含 "rabbitmq" 的创建
到一个索引中
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "docker"
# 设置索引模板的匹配模式
setup.template.pattern: "docker*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 13)测试效果
filebeat -e -c filebeat.yml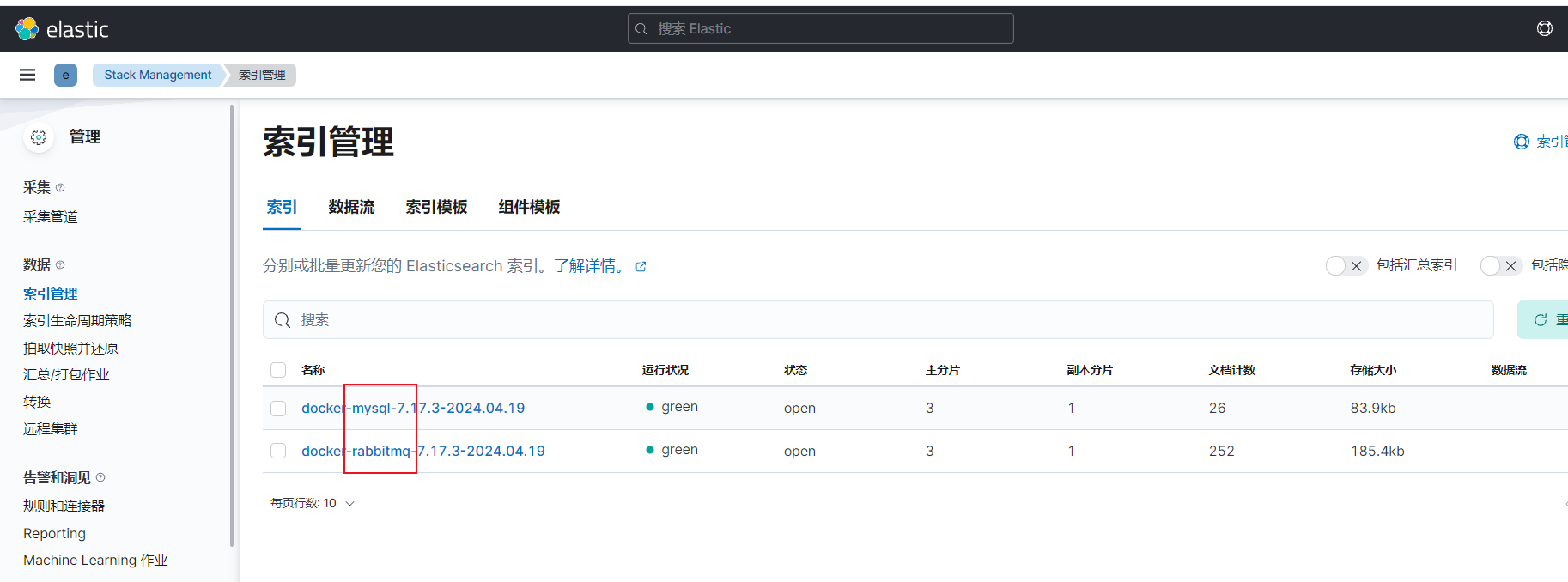
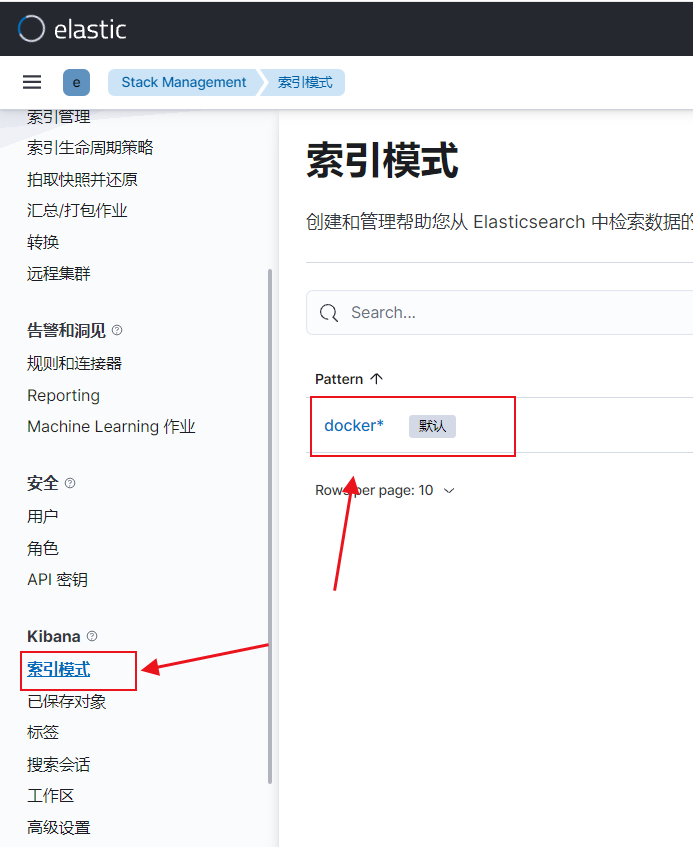
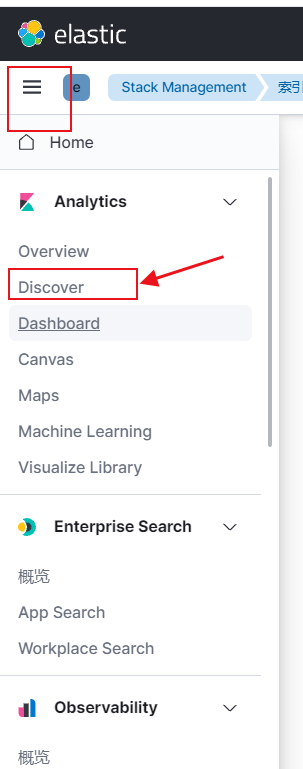
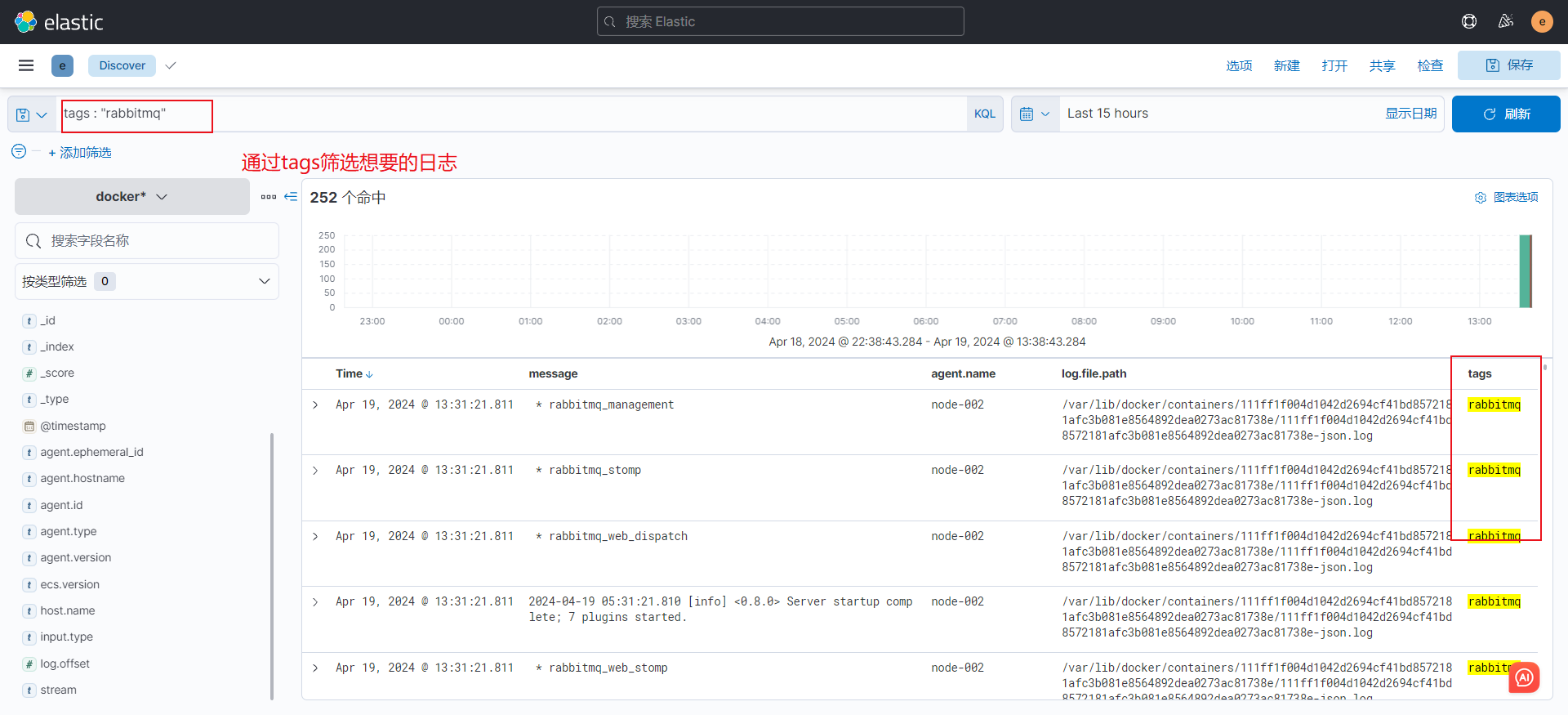
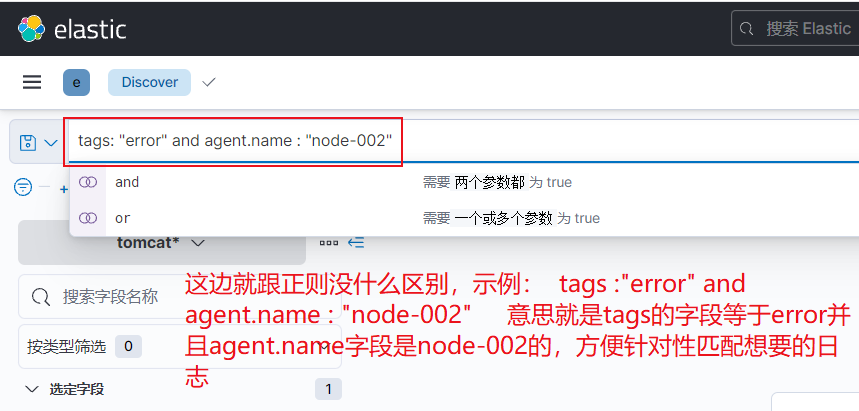
这边插一条,KQL搜索框的用法
4. 基于 mobules 插件采集nginx 日志文件
流程图
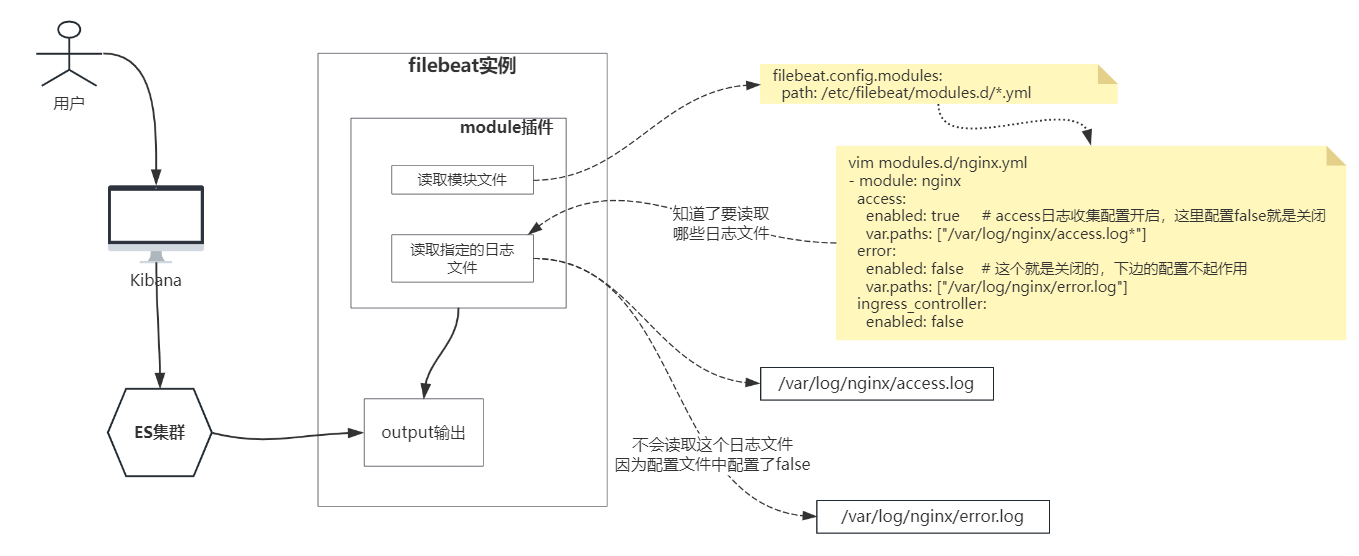
1)启用nginx插件
1) vim filebeat.yml # 把input类型换为modules类型
filebeat.config.modules:
path: /etc/filebeat/modules.d/*.yml # 这边配置 modules.d 文件位置,项目默认创建的
reload.enabled: true # 配置热加载,开不开都行
2) 保存之后开启需要的插件
filebeat modules list # 查看支持的插件列表
Enabled: # 开启的
Disabled: # 关闭的
...
...
...
3) 开启插件命令
filebeat modules enable nginx # 开启enable 管理 disable
Enabled nginx
filebeat modules list # 查看支持的插件列表
Enabled: # 开启的
nginxmodules 插件列表的开启和关闭其实就是把 modules.d/ 目录下的文件后缀改了
ls modules.d/tomcat.yml
modules.d/tomcat.yml.disabled # 这是关闭的,后缀多一个.disabled,其实手动修改一下也可以
ls modules.d/nginx.yml.disabled
modules.d/nginx.yml # 这是开启的,后缀没有.disabled2)filebeat.yml 文件
1) vim filebeat.yml
filebeat.config.modules:
path: /etc/filebeat/modules.d/*.yml # 这边配置 modules.d 文件位置,项目默认创建的
reload.enabled: true # 配置热加载开不开都行
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "nginx-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
2) 修改modules.d/nginx.yml
vim modules.d/nginx.yml
- module: nginx
access:
enabled: true # access日志收集配置开启,这里配置false就是关闭
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: false # 这个就是关闭的,下边的配置不起作用
var.paths: ["/var/log/nginx/error.log"]
ingress_controller:
enabled: false
3)测试效果
filebeat -e -c filebeat.yml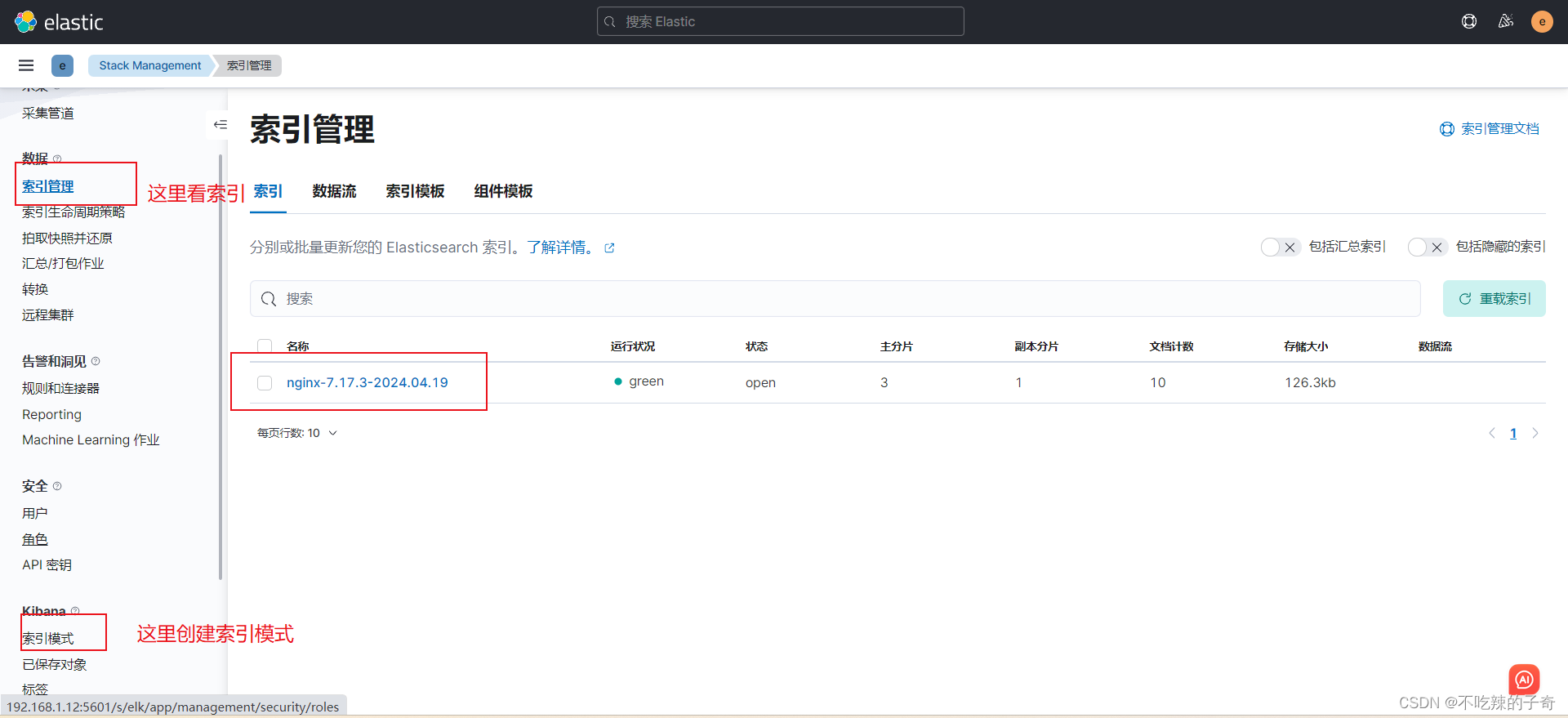
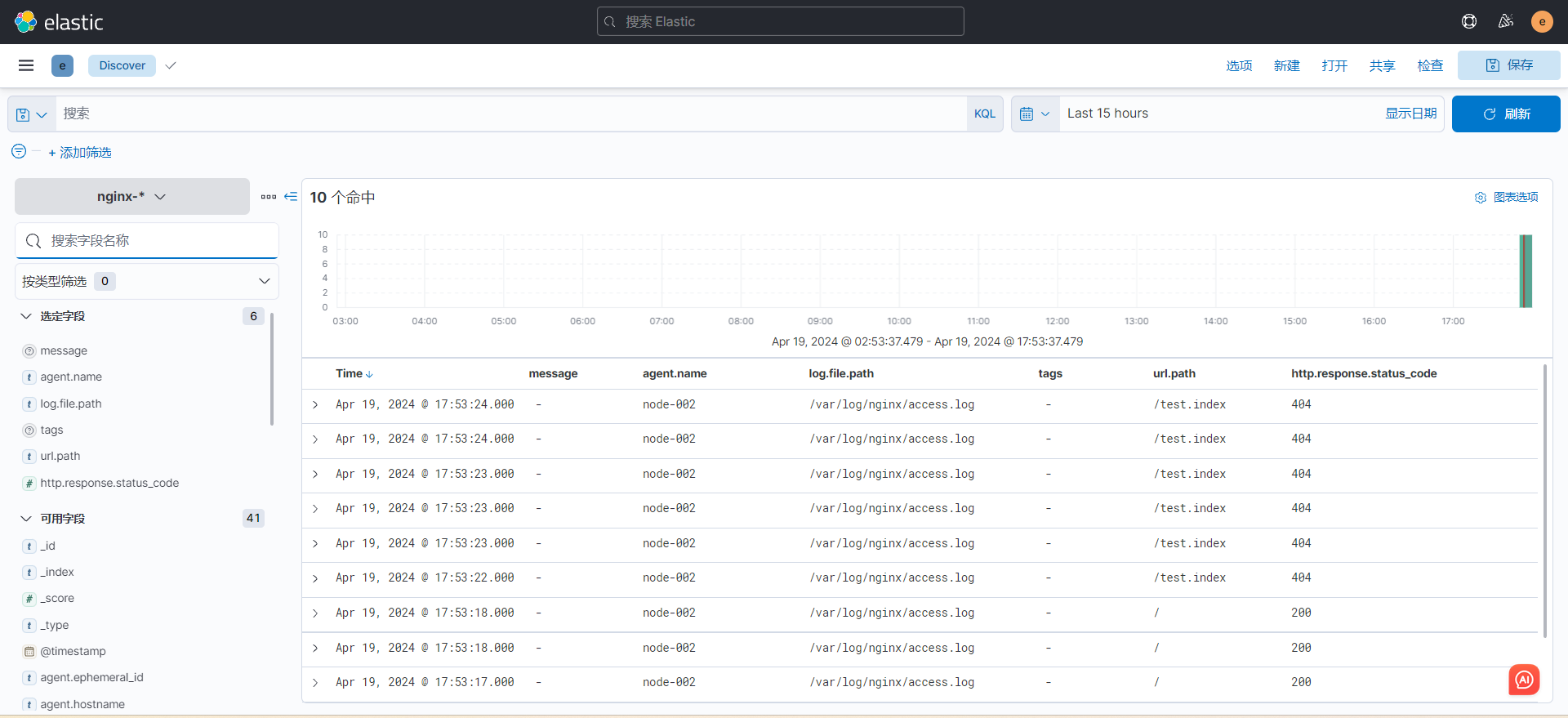
5. 收集采集 tomcat 日志文件(modules,json)
流程图
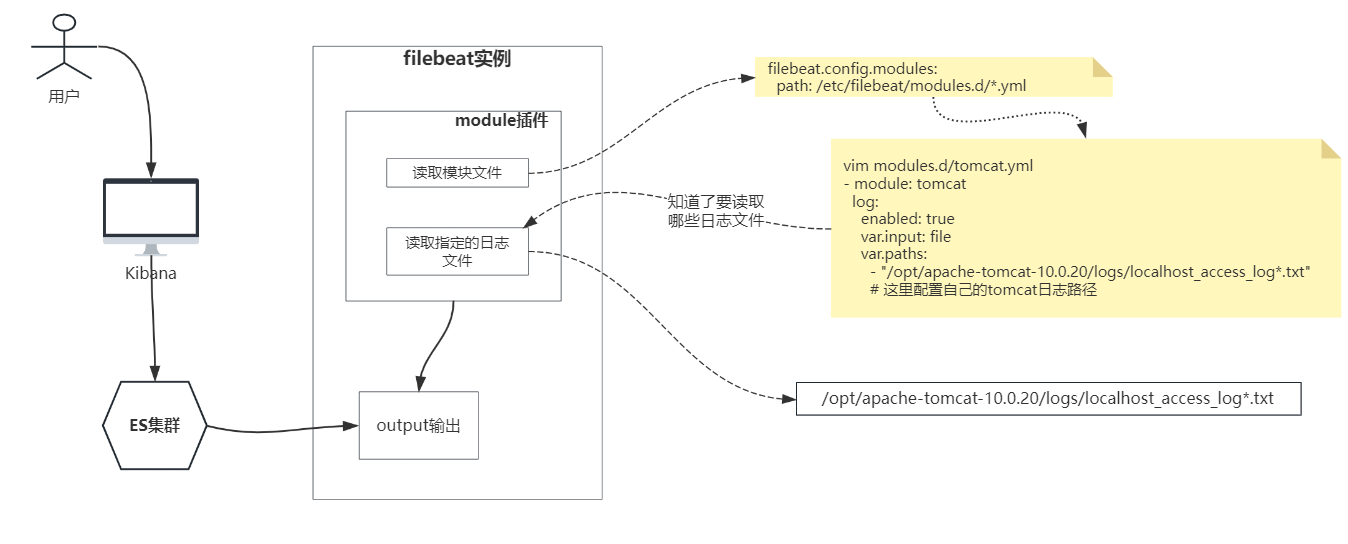
1)modules类型,启动tomcat插件
1) vim filebeat.yml # 把input类型换为modules类型
filebeat.config.modules:
path: /etc/filebeat/modules.d/tomcat.yml # 这边配置 modules.d 文件位置,项目默认创建的
reload.enabled: true # 配置热加载,开不开都行
2) 保存之后开启需要的插件
filebeat modules list # 查看支持的插件列表
Enabled: # 开启的
Disabled: # 关闭的
...
...
...
3) 开启插件命令
filebeat modules enable tomcat # 开启enable 管理 disable
Enabled tomcat
filebeat modules list # 查看支持的插件列表
Enabled: # 开启的
tomcat2)修改filebeat配置文件
1) vim filebeat.yml
filebeat.config.modules:
path: /etc/filebeat/modules.d/*.yml # 这边配置 modules.d 文件位置,项目默认创建的
reload.enabled: true # 配置热加载开不开都行
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "tomcat-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "tomcat"
# 设置索引模板的匹配模式
setup.template.pattern: "tomcat*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
2) 修改modules.d/tomcat.yml
vim modules.d/tomcat.yml
- module: tomcat
log:
enabled: true
var.input: file
var.paths:
- "/opt/apache-tomcat-10.0.20/logs/localhost_access_log*.txt" # 配置自己的tomcat日志路径3)测试效果
filebeat -e -c filebeat.yml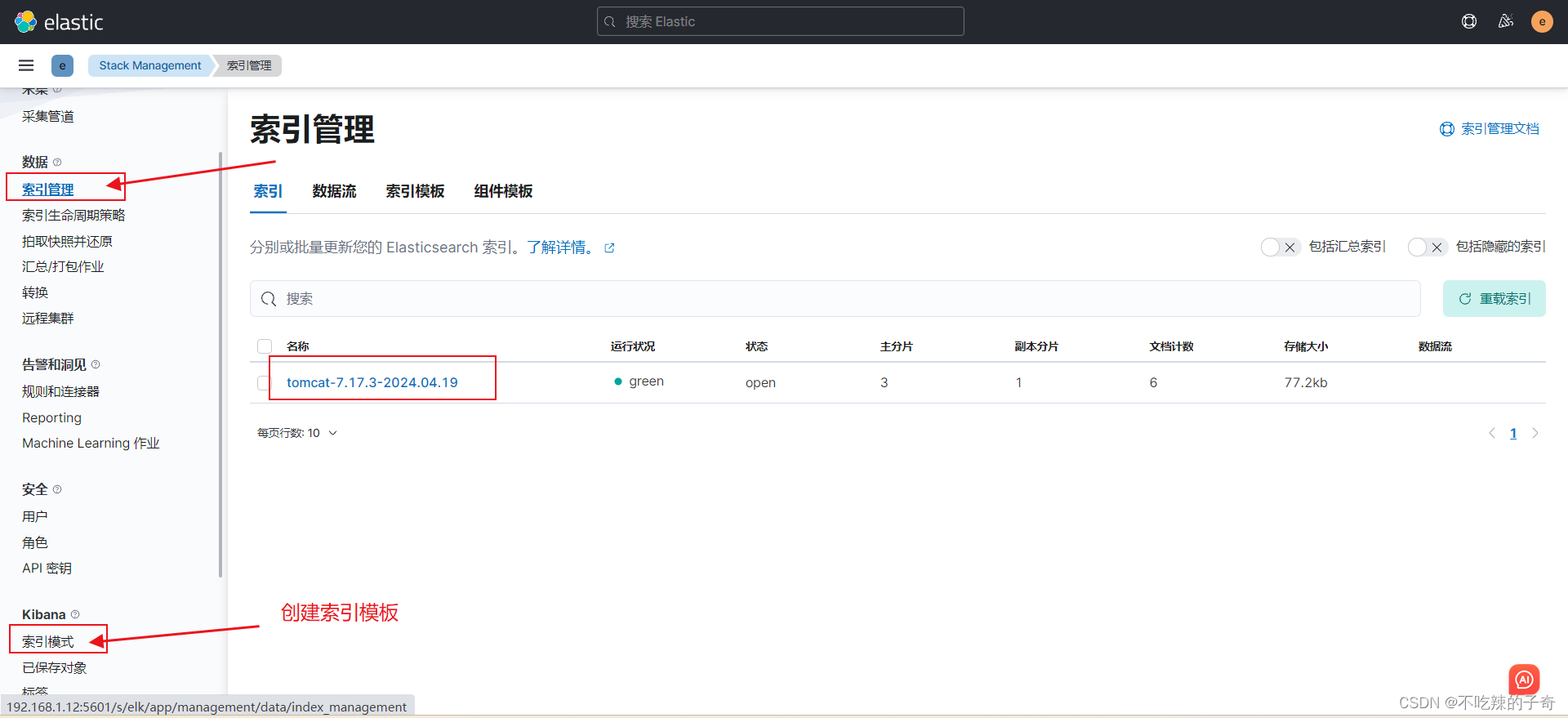
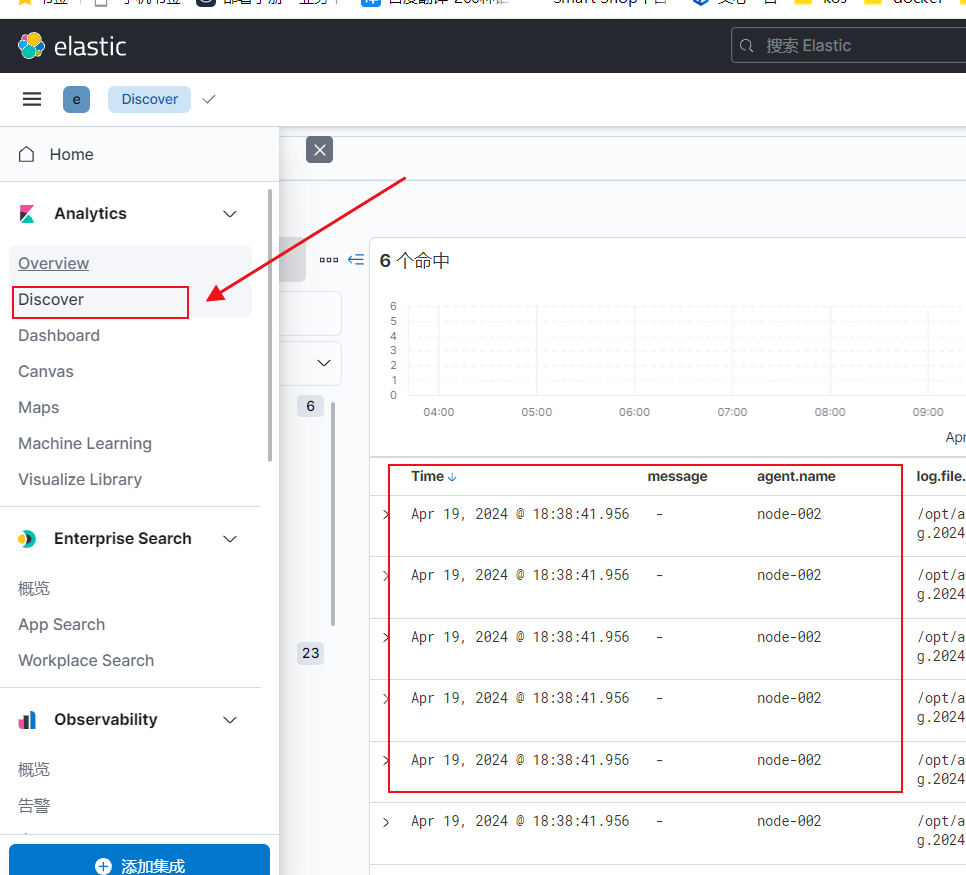
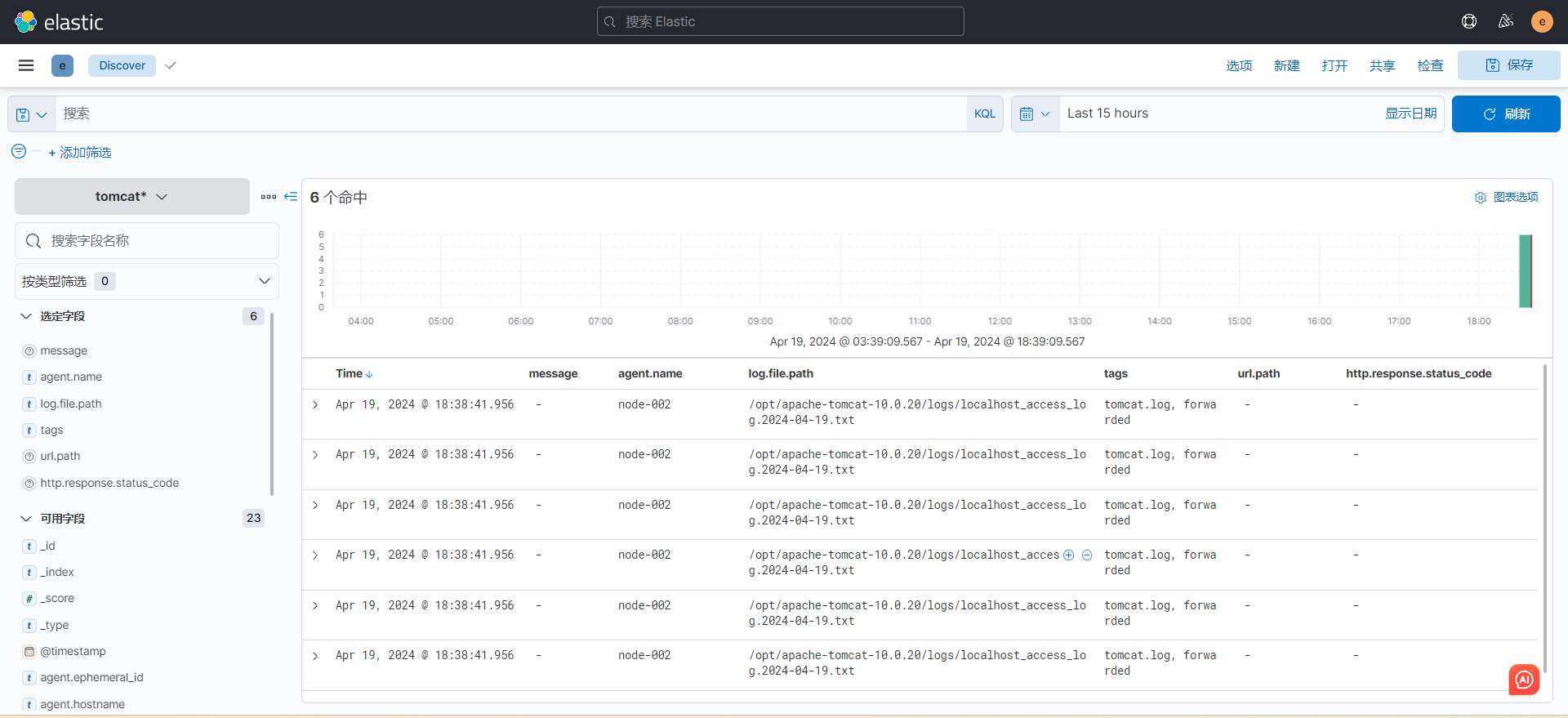
4)收集tomcat的json格式日志

1) 先备份一下配置文件
cd /opt/apache-tomcat-10.0.20 && cp conf/server.xml conf/server-bak5)修改配置文件
1)
tomcat配置文件中修改log格式 /opt/apache-tomcat-10.0.20/conf/server.xml
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":"%t","request":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partner":"%{Referer}i","AgentVersion":"%{User-Agent}i"}"/>
</Host>
2)
修改filebeat配置文件
vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/apache-tomcat-10.0.20/logs/localhost_access_log*.txt # 定义自己的日志文件路径
json.keys_under_root: true # 解析message字段的json格式,并放在顶级字段中
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "tomcat-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "tomcat"
# 设置索引模板的匹配模式
setup.template.pattern: "tomcat*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
6)测试效果
filebeat -e -c filebeat.yml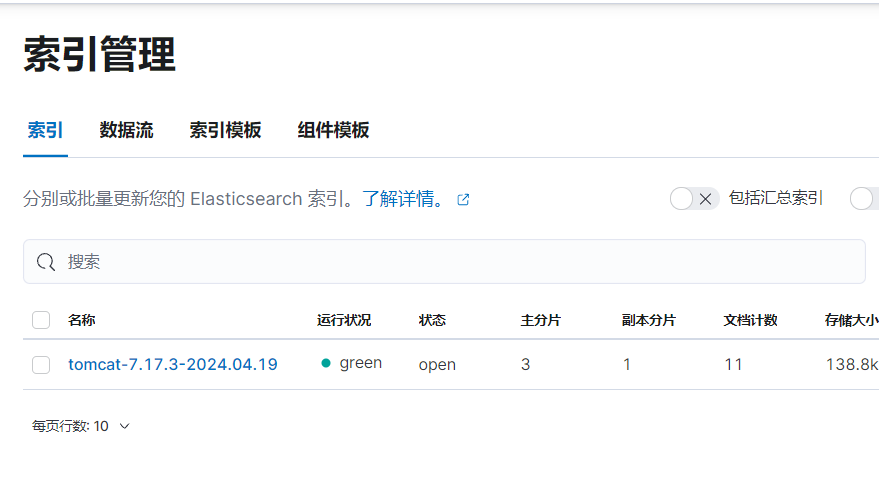
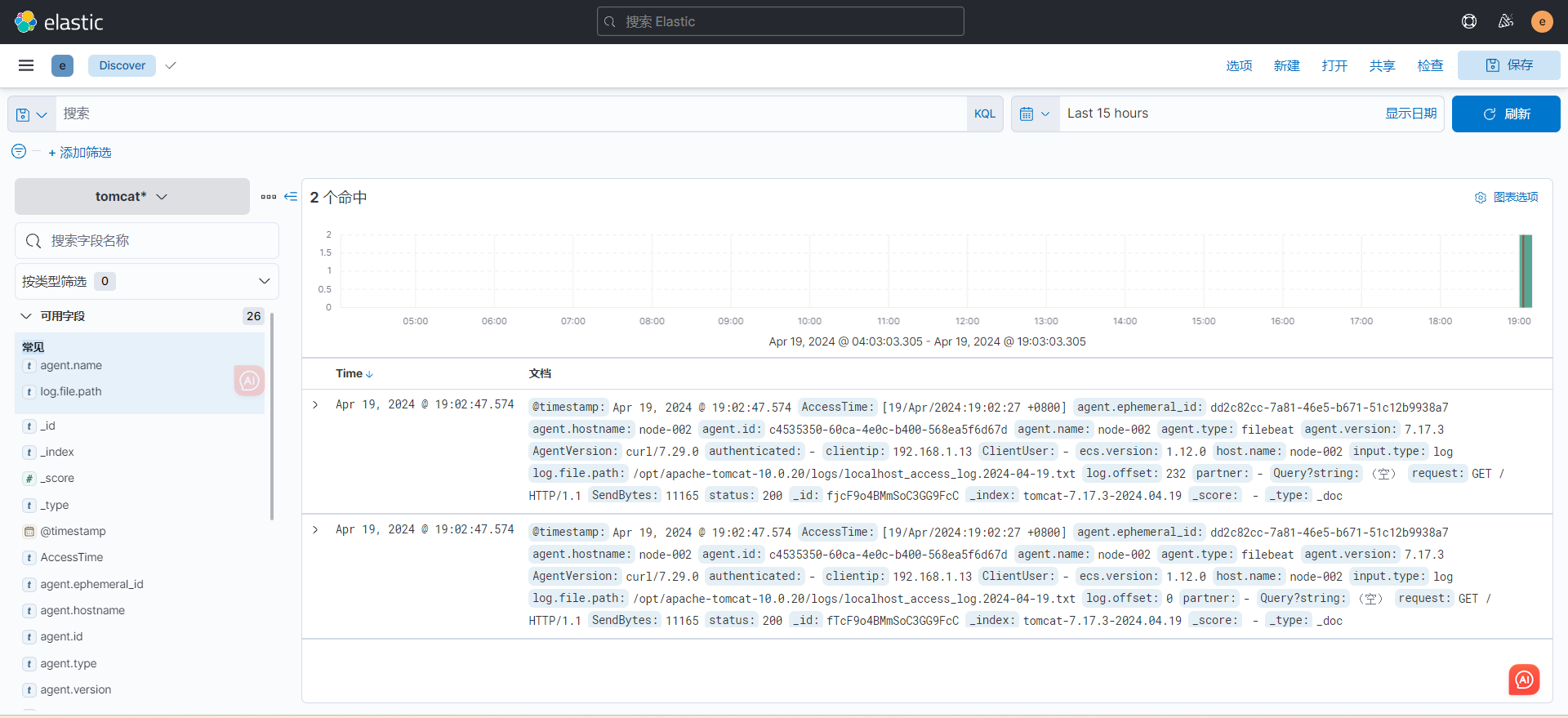
6. 多行匹配日志(拼接日志行)
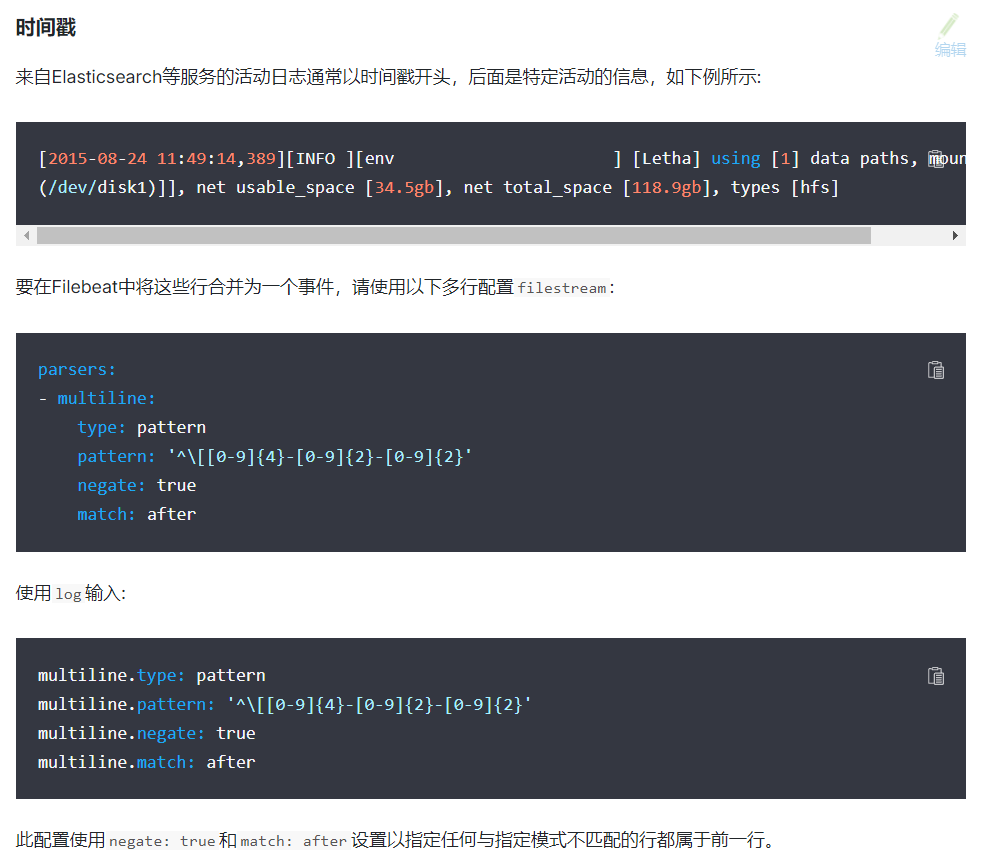
官方文档:Manage multiline messages | Filebeat Reference [7.17] | Elastic
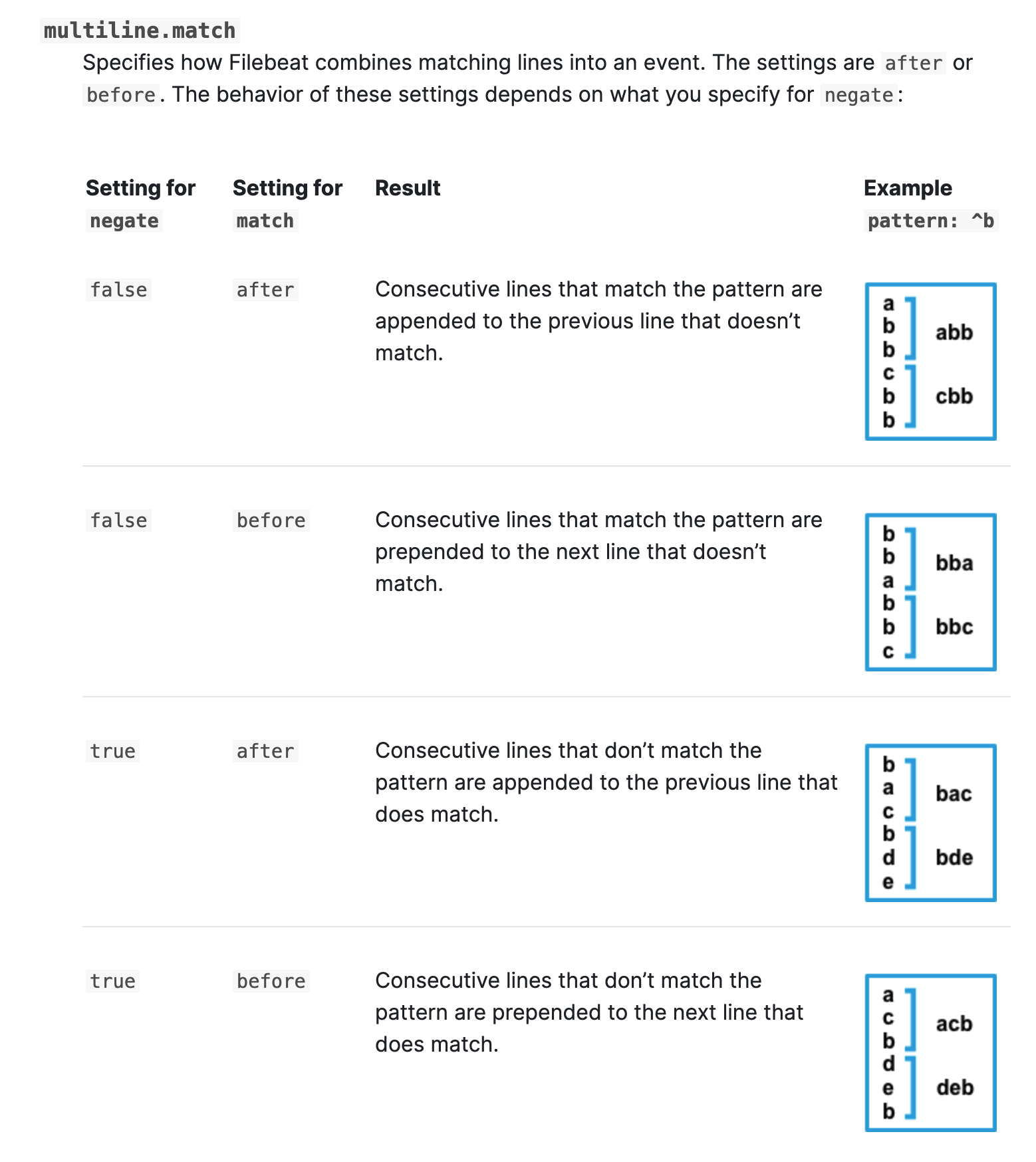
流程图
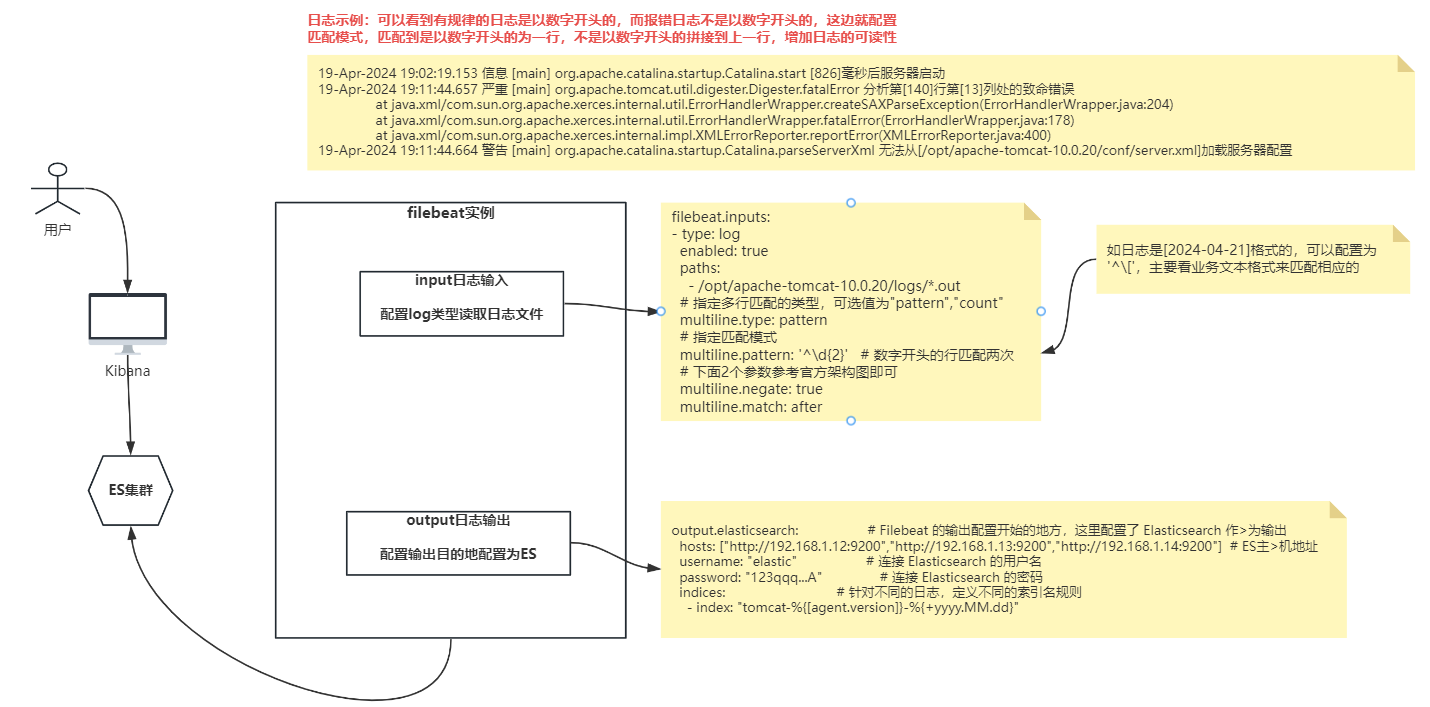
1)日志示例
下边可以看到有规律的日志是以数字开头的,而报错日志不是以数字开头的,这边就配置匹配模式,匹配到是以数字开头的为一行,不是以数字开头的拼接到上一行
19-Apr-2024 19:02:19.065 信息 [main] org.apache.catalina.startup.HostConfig.deployDirectory 把web 应用程序部署到目录 [/opt/apache-tomcat-10.0.20/webapps/host-manager]
19-Apr-2024 19:02:19.094 信息 [main] org.apache.catalina.startup.HostConfig.deployDirectory Web应用程序目录[/opt/apache-tomcat-10.0.20/webapps/host-manager]的部署已在[30]毫秒内完成
19-Apr-2024 19:02:19.095 信息 [main] org.apache.catalina.startup.HostConfig.deployDirectory 把web 应用程序部署到目录 [/opt/apache-tomcat-10.0.20/webapps/manager]
19-Apr-2024 19:02:19.118 信息 [main] org.apache.catalina.startup.HostConfig.deployDirectory Web应用程序目录[/opt/apache-tomcat-10.0.20/webapps/manager]的部署已在[23]毫秒内完成
19-Apr-2024 19:02:19.122 信息 [main] org.apache.coyote.AbstractProtocol.start 开始协议处理句柄["http-nio-8080"]
19-Apr-2024 19:02:19.153 信息 [main] org.apache.catalina.startup.Catalina.start [826]毫秒后服务器启动
NOTE: Picked up JDK_JAVA_OPTIONS: --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.rmi/sun.rmi.transport=ALL-UNNAMED
19-Apr-2024 19:11:44.657 严重 [main] org.apache.tomcat.util.digester.Digester.fatalError 分析第[140]行第[13]列处的致命错误
org.xml.sax.SAXParseException; systemId: file:/opt/apache-tomcat-10.0.20/conf/server.xml; lineNumber: 140; columnNumber: 13; 元素类型 "Host" 的结束标记必须以 '>' 分隔符结束。
at java.xml/com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(ErrorHandlerWrapper.java:204)
at java.xml/com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.fatalError(ErrorHandlerWrapper.java:178)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(XMLErrorReporter.java:400)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(XMLErrorReporter.java:327)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLScanner.reportFatalError(XMLScanner.java:1465)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanEndElement(XMLDocumentFragmentScannerImpl.java:1701)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2899)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:605)
at java.xml/com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:542)
at java.xml/com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:889)
at java.xml/com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:825)
at java.xml/com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:141)
at java.xml/com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1224)
at java.xml/com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:637)
at org.apache.tomcat.util.digester.Digester.parse(Digester.java:1522)
at org.apache.catalina.startup.Catalina.parseServerXml(Catalina.java:642)
at org.apache.catalina.startup.Catalina.load(Catalina.java:732)
at org.apache.catalina.startup.Catalina.load(Catalina.java:769)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:104)
at java.base/java.lang.reflect.Method.invoke(Method.java:577)
at org.apache.catalina.startup.Bootstrap.load(Bootstrap.java:305)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:475)
19-Apr-2024 19:11:44.664 警告 [main] org.apache.catalina.startup.Catalina.parseServerXml 无法从[/opt/apache-tomcat-10.0.20/conf/server.xml]加载服务器配置
org.xml.sax.SAXParseException; systemId: file:/opt/apache-tomcat-10.0.20/conf/server.xml; lineNumber: 140; columnNumber: 13; 元素类型 "Host" 的结束标记必须以 '>' 分隔符结束。
at java.xml/com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1251)
at java.xml/com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:637)
at org.apache.tomcat.util.digester.Digester.parse(Digester.java:1522)
at org.apache.catalina.startup.Catalina.parseServerXml(Catalina.java:642)
at org.apache.catalina.startup.Catalina.load(Catalina.java:732)
at org.apache.catalina.startup.Catalina.load(Catalina.java:769)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:104)
at java.base/java.lang.reflect.Method.invoke(Method.java:577)
at org.apache.catalina.startup.Bootstrap.load(Bootstrap.java:305)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:475)
19-Apr-2024 19:11:44.666 严重 [main] org.apache.catalina.startup.Catalina.start 无法启动服务器,服务器实例未配置
2)修改filebeat配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/apache-tomcat-10.0.20/logs/*.out
# 指定多行匹配的类型,可选值为"pattern","count"
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\d{2}' # 数字开头的行匹配两次
# 下面2个参数参考官方架构图即可,如上图所示。
multiline.negate: true
multiline.match: after
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "tomcat-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "tomcat"
# 设置索引模板的匹配模式
setup.template.pattern: "tomcat*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
3)查看效果
filebeat -e -c filebeat.yml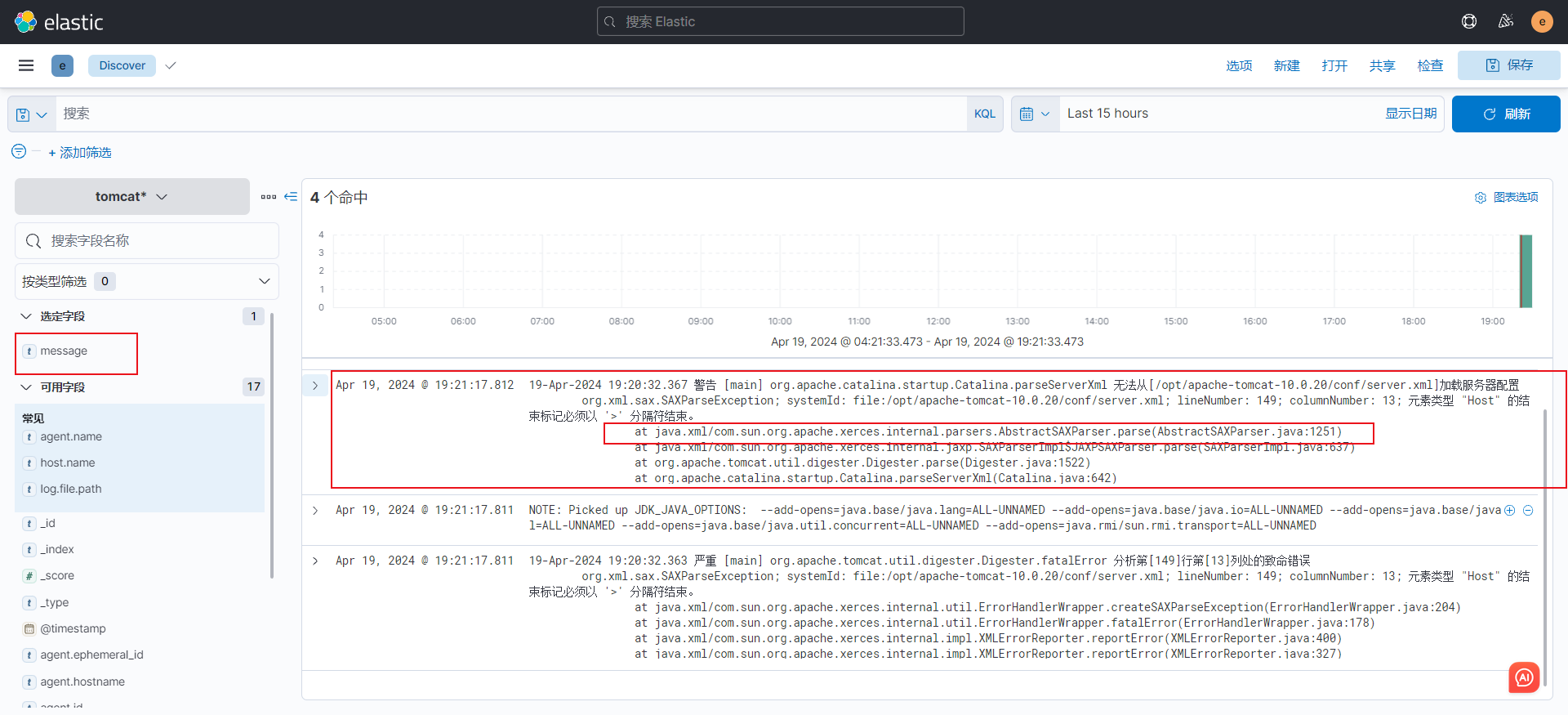
4)es多行匹配日志收集示例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/elasticsearch/elk.log* # 修改为自己的日志文件路径
# 指定多行匹配的类型,可选值为"pattern","count"
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\['
# 下面2个参数参考官方架构图即可,如上图所示。
multiline.negate: true
multiline.match: after
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "elasticsearch-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "elasticsearch"
# 设置索引模板的匹配模式
setup.template.pattern: "elasticsearch*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
5)nginx日志过滤示例(包含error的行单独输出到一个索引)
流程图
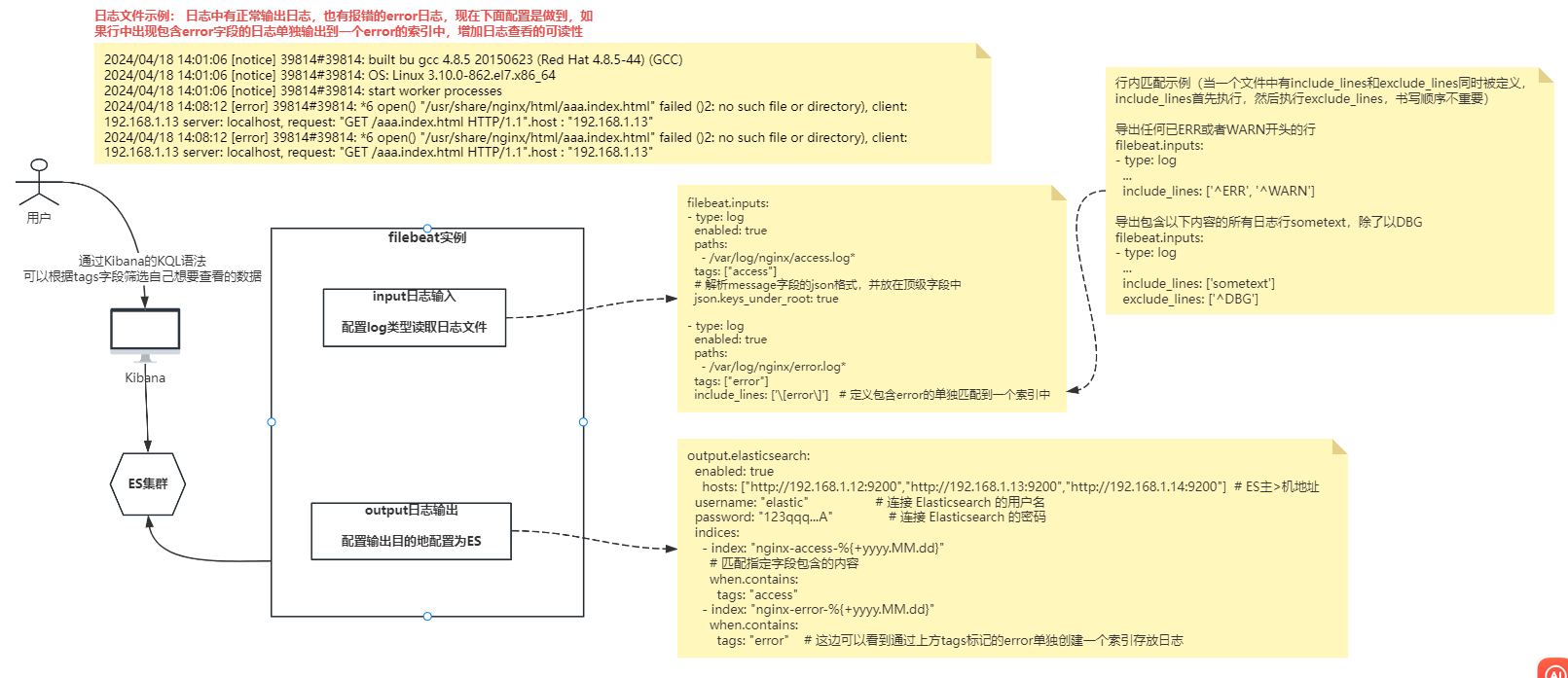
行内匹配示例(当一个文件中有include_lines和exclude_lines同时被定义,include_lines首先执行,然后执行exclude_lines,书写顺序不重要)
导出任何已ERR或者WARN开头的行
filebeat.inputs:
- type: log
...
include_lines: ['^ERR', '^WARN']
导出包含以下内容的所有日志行sometext,除了以DBG
filebeat.inputs:
- type: log
...
include_lines: ['sometext']
exclude_lines: ['^DBG']filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 解析message字段的json格式,并放在顶级字段中
json.keys_under_root: true
- type: log
enabled: true
paths:
- /var/log/nginx/error.log*
tags: ["error"]
include_lines: ['\[error\]'] # 定义包含error的单独匹配到一个索引中
output.elasticsearch:
enabled: true
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices:
- index: "nginx-access-%{+yyyy.MM.dd}"
# 匹配指定字段包含的内容
when.contains:
tags: "access"
- index: "nginx-error-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
# 覆盖已有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量,要求小于集群的数量
index.number_of_replicas: 07. log类型切换filestream类型示例
1)介绍
在新版本中 log 类型被弃用,更换为了filestream,用法也有了一些小改变2)filestream类型json解析配置
流程图
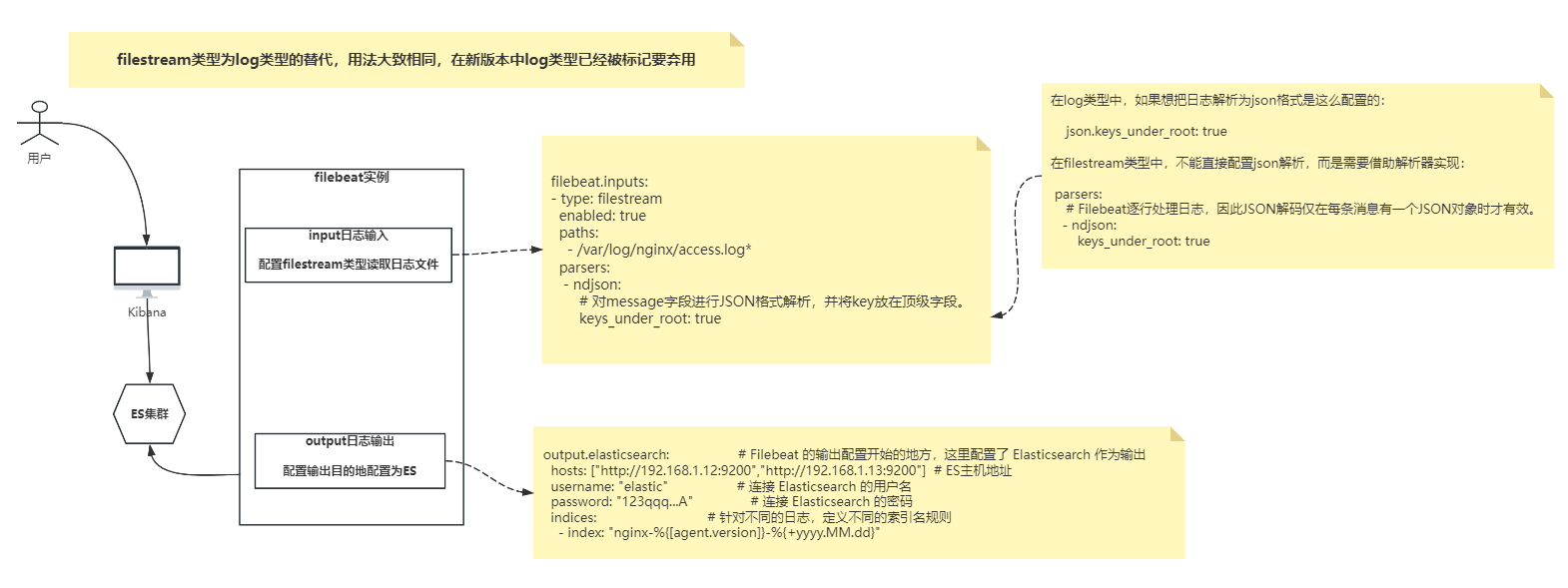
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 对于filestream类型而言,不能直接配置json解析,而是需要借助解析器实现
# json.keys_under_root: true
# 综上所述,我们就需要使用以下的写法实现.
parsers:
# 使 Filebeat能够解码结构化为JSON消息的日志。
# Filebeat逐行处理日志,因此JSON解码仅在每条消息有一个JSON对象时才有效。
- ndjson:
# 对message字段进行JSON格式解析,并将key放在顶级字段。
keys_under_root: true
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "nginx-%{[agent.version]}-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "nginx"
# 设置索引模板的匹配模式
setup.template.pattern: "nginx*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 13)filestream类型多行匹配拼接日志解析配置
流程图
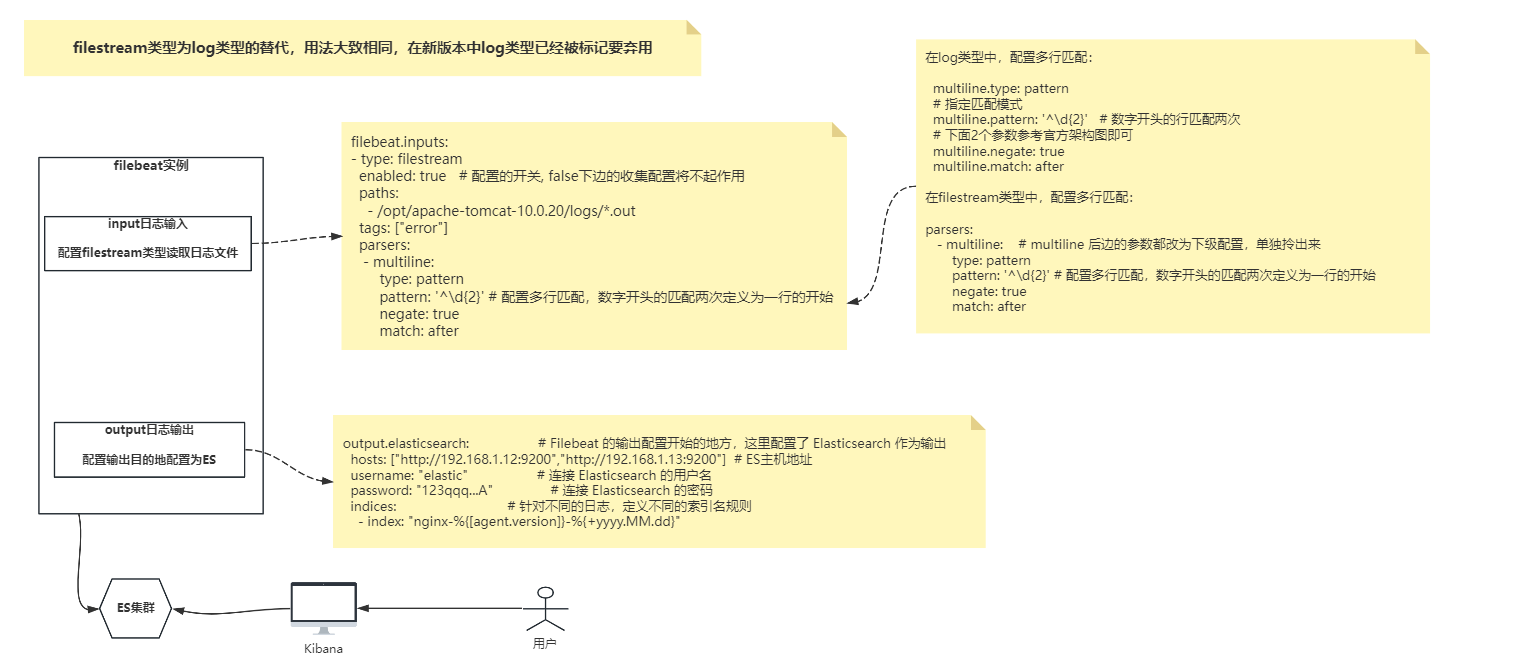
filebeat.inputs:
- type: filestream # 修改为新的 filestream 类型
enabled: true # 配置的开关, false下边的收集配置将不起作用
paths:
- /opt/apache-tomcat-10.0.20/logs/*.txt # 定义日志文件
tags: ["access"] # 定义tag不同的日志输出到不同的索引中
parsers:
- ndjson: # 定义已json格式输出日志
keys_under_root: true
- type: filestream
enabled: true # 配置的开关, false下边的收集配置将不起作用
paths:
- /opt/apache-tomcat-10.0.20/logs/*.out
tags: ["error"]
parsers:
- multiline:
type: pattern
pattern: '^\d{2}' # 配置多行匹配,数字开头的匹配两次定义为一行的开始
negate: true
match: after
output.elasticsearch: # Filebeat 的输出配置开始的地方,这里配置了 Elasticsearch 作>为输出
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"] # ES主>机地址
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices: # 针对不同的日志,定义不同的索引名规则
- index: "tomcat-access-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "access"
- index: "tomcat-error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的匹配模式
setup.template.name: "tomcat"
# 设置索引模板的匹配模式
setup.template.pattern: "tomcat*"
#覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板,分片和副本
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
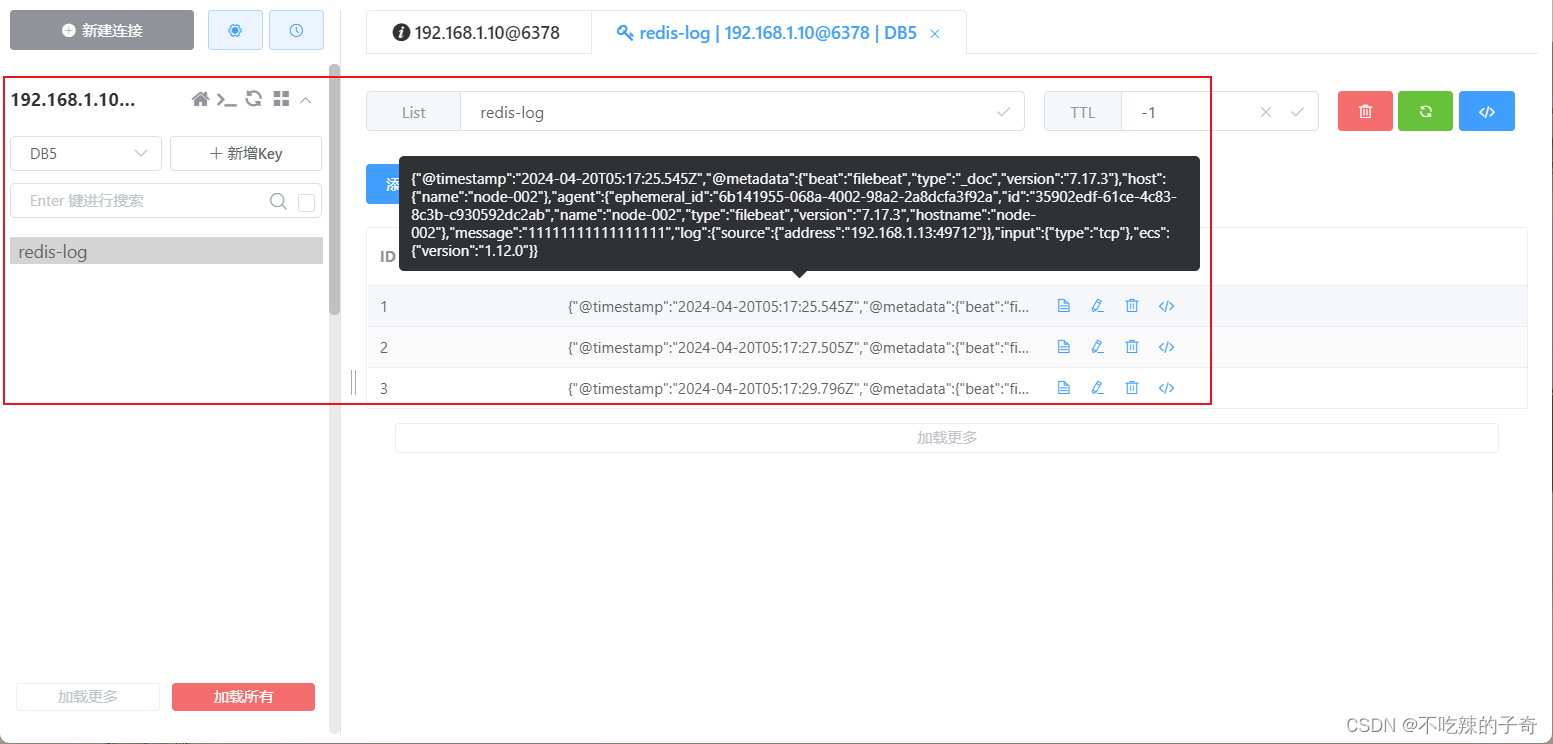
8. 监听TCP端口,收集日志写入到Redis
官网文档地址:TCP input | Filebeat Reference [7.17] | Elastic
流程图
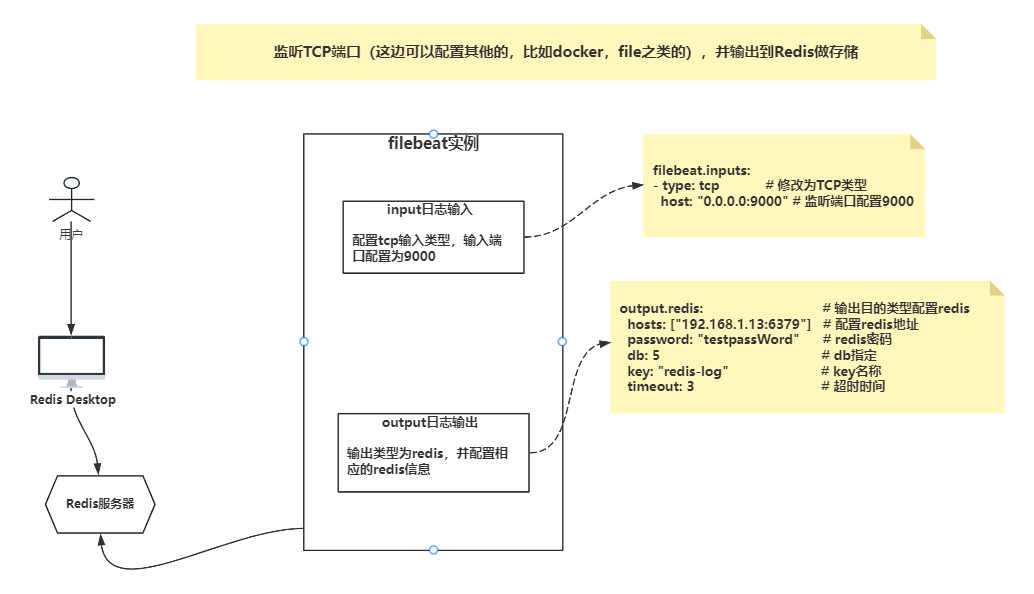
1)修改配置文件
filebeat.inputs:
- type: tcp # 修改为TCP类型
host: "0.0.0.0:9000" # 监听端口配置9000
output.redis: # 输出目的类型配置redis
hosts: ["192.168.1.13:6379"] # 配置redis地址
password: "testpassWord" # redis密码
db: 5 # db指定
key: "redis-log" # key名称
timeout: 3 # 超时时间补充:匹配message中包含的字段来判断写入哪个键值
keys:
- key: "info_list" # send to info_list if `message` field contains INFO
when.contains:
message: "INFO"
- key: "debug_list" # send to debug_list if `message` field contains DEBUG
when.contains:
message: "DEBUG"2)启动服务
filebeat -e -c filebeat.yml3)查看效果
这边可以看到输出日志显示监听了9000端口
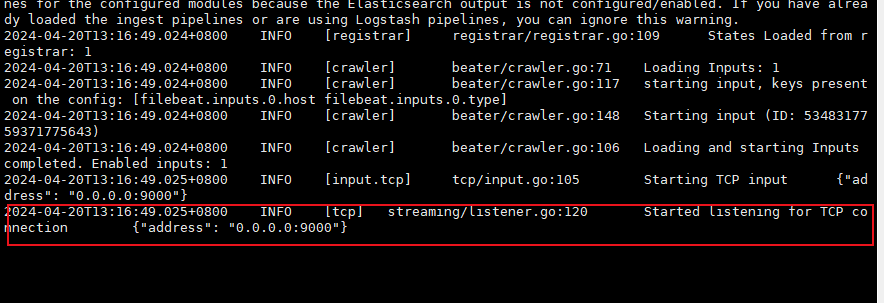
telnet 连接这个端口测试日志收集效果

9. 日志收集到本地文件存储
官网文档地址:Configure the File output | Filebeat Reference [7.17] | Elastic
流程图
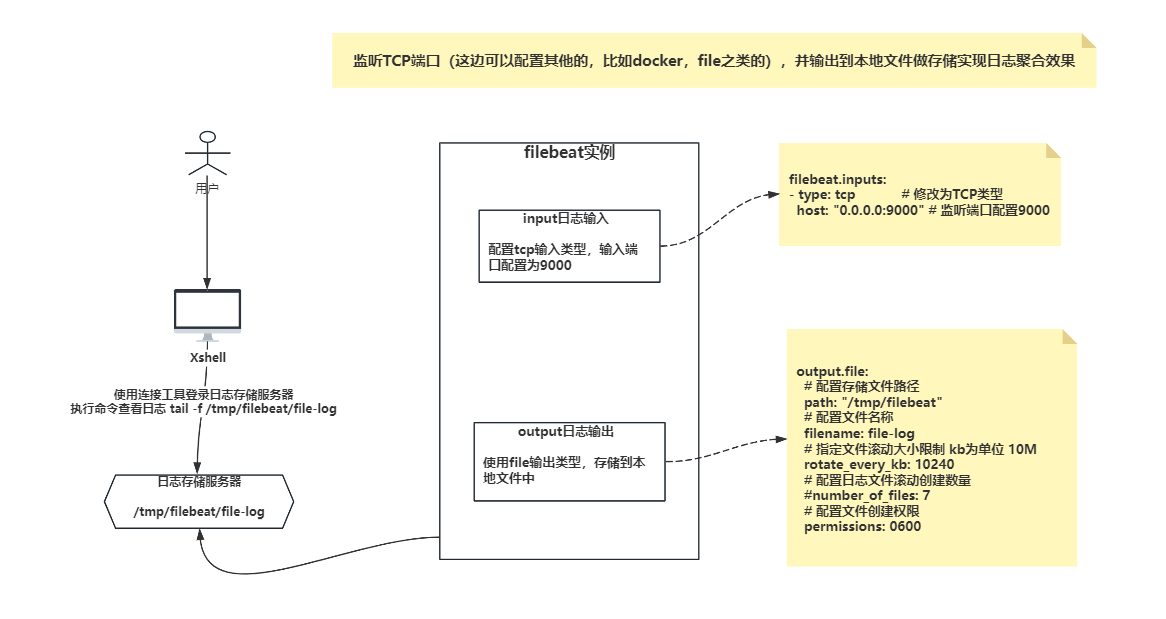
1)修改配置文件
filebeat.inputs:
- type: tcp # 修改为tcp类型测试,这边配置为自己的输入类型即可
host: "0.0.0.0:9000"
output.file:
# 配置存储文件路径
path: "/tmp/filebeat"
# 配置文件名称
filename: file-log
# 指定文件滚动大小限制 kb为单位 10M
rotate_every_kb: 10240
# 配置日志文件滚动创建数量
#number_of_files: 7
# 配置文件创建权限
permissions: 0600
2)启动服务
# 先看一下指定目录下,确认为空
ls /tmp/filebeat/
# 启动服务
filebeat -e -c filebeat.yml3)测试效果
1) 生成几条数据测试下效果
telnet 192.168.1.13 9000
Trying 192.168.1.13...
Connected to 192.168.1.13.
Escape character is '^]'.
1111111aaaaaa
test file log
test file logs
2) 查看下定义的/tmp/filebeat/下是否有日志文件创建
ls /tmp/filebeat/
file-log
3) 看下日志文件内容
cat /tmp/filebeat/file-log
{"@timestamp":"2024-04-20T05:36:31.592Z","@metadata":
看到message字段跟上边telnet测试的一致
{"beat":"filebeat","type":"_doc","version":"7.17.3"},"message":"1111111aaaaaa","log":{"source":{"address":"192.168.1.13:49716"}},"input":{"type":"tcp"},"ecs":{"version":"1.12.0"},"host":{"name":"node-002"},"agent":{"ephemeral_id":"d050fa67-eb99-4ae3-9ee0-8078ec297556","id":"35902edf-61ce-4c83-8c3b-c930592dc2ab","name":"node-002","type":"filebeat","version":"7.17.3","hostname":"node-002"}}
{"@timestamp":"2024-04-20T05:36:35.770Z","@metadata":
看到message字段跟上边telnet测试的一致
{"beat":"filebeat","type":"_doc","version":"7.17.3"},"message":"test file log","input":{"type":"tcp"},"host":{"name":"node-002"},"agent":{"id":"35902edf-61ce-4c83-8c3b-c930592dc2ab","name":"node-002","type":"filebeat","version":"7.17.3","hostname":"node-002","ephemeral_id":"d050fa67-eb99-4ae3-9ee0-8078ec297556"},"ecs":{"version":"1.12.0"},"log":{"source":{"address":"192.168.1.13:49716"}}}
{"@timestamp":"2024-04-20T05:36:40.066Z","@metadata":
看到message字段跟上边telnet测试的一致
{"beat":"filebeat","type":"_doc","version":"7.17.3"},"message":"test file logs","log":{"source":{"address":"192.168.1.13:49716"}},"input":{"type":"tcp"},"ecs":{"version":"1.12.0"},"host":{"name":"node-002"},"agent":{"ephemeral_id":"d050fa67-eb99-4ae3-9ee0-8078ec297556","id":"35902edf-61ce-4c83-8c3b-c930592dc2ab","name":"node-002","type":"filebeat","version":"7.17.3","hostname":"node-002"}}10. rsyslog日志聚合
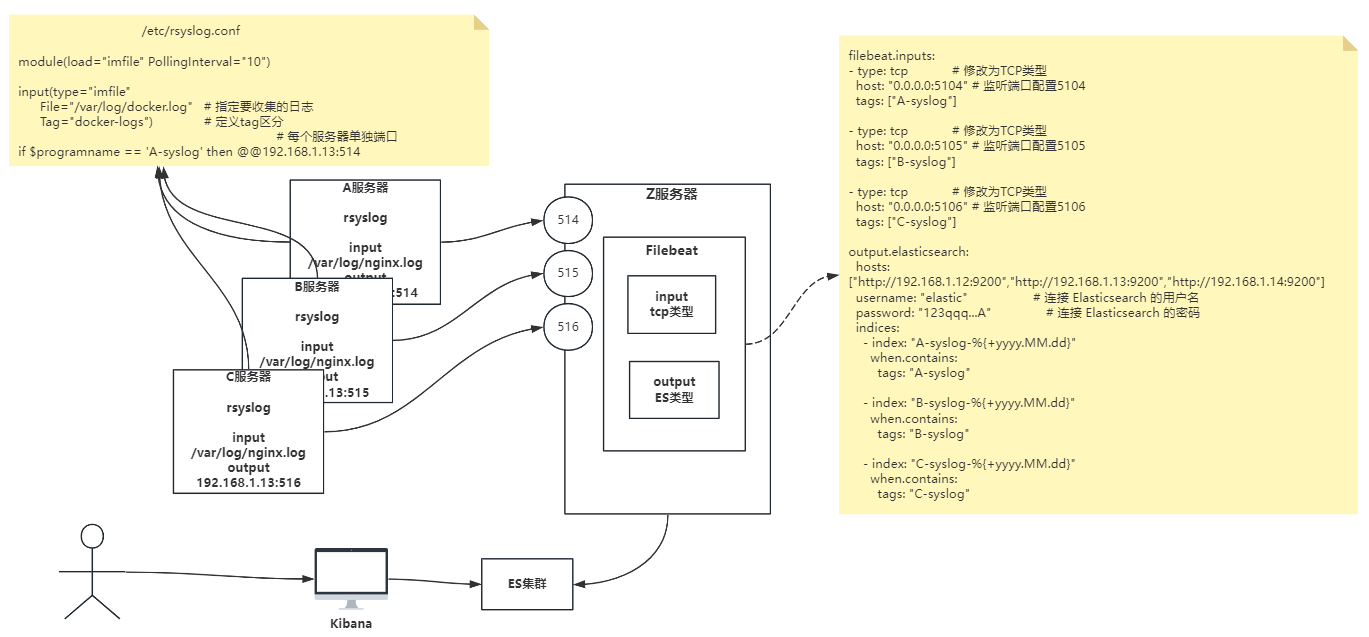
场景:多台服务器不想每台服务器上都去部署filebeat或logstash,这样不便于管理,也占资源,这边就可以使用rsyslog服务来搭建一套日志聚合流程,rsyslog功能也有很多官网文档:https://www.rsyslog.con/docs
1)配置并启动filebeat
1) vim filebeat.yml
filebeat.inputs:
- type: tcp # 修改为TCP类型
host: "0.0.0.0:5104" # 监听端口配置5104
tags: ["A-syslog"]
- type: tcp # 修改为TCP类型
host: "0.0.0.0:5105" # 监听端口配置5105
tags: ["B-syslog"]
- type: tcp # 修改为TCP类型
host: "0.0.0.0:5106" # 监听端口配置5106
tags: ["C-syslog"]
output.elasticsearch:
hosts: ["http://192.168.1.12:9200","http://192.168.1.13:9200","http://192.168.1.14:9200"]
username: "elastic" # 连接 Elasticsearch 的用户名
password: "123qqq...A" # 连接 Elasticsearch 的密码
indices:
- index: "A-syslog-%{+yyyy.MM.dd}"
when.contains:
tags: "A-syslog"
- index: "B-syslog-%{+yyyy.MM.dd}"
when.contains:
tags: "B-syslog"
- index: "C-syslog-%{+yyyy.MM.dd}"
when.contains:
tags: "C-syslog"
2) 启动服务
filebeat -e -c filebeat.yml2) 需要收集日志的服务器安装rsyslog
# 需要收集日志的服务器都需要执行以下操作,端口跟tag记得修改成唯一的,以免日志混乱
yum -y install rsyslog # 安装服务
vim /etc/rsyslog.conf # 修改配置文件,添加这几行配置
module(load="imfile" PollingInterval="10")
input(type="imfile" # 使用imfile插件
File="/var/log/docker.log" # 定义日志文件路径
Tag="A-syslog") # 配置tag
if $programname == 'A-syslog' then @@192.168.1.13:5104 # 指定filebeat的input配置端口
systemctl start rsyslog # 启动服务3)测试效果
我写了个简单的for循环脚本来测试
#!/bin/bash
for i in {1..10000}
do
openssl rand -base64 50 | tr -d '\n' >> /var/log/docker.log
echo "" >> /var/log/docker.log
done两节点测了一个小时,Kibana看效果,两条索引插入了35w条数据
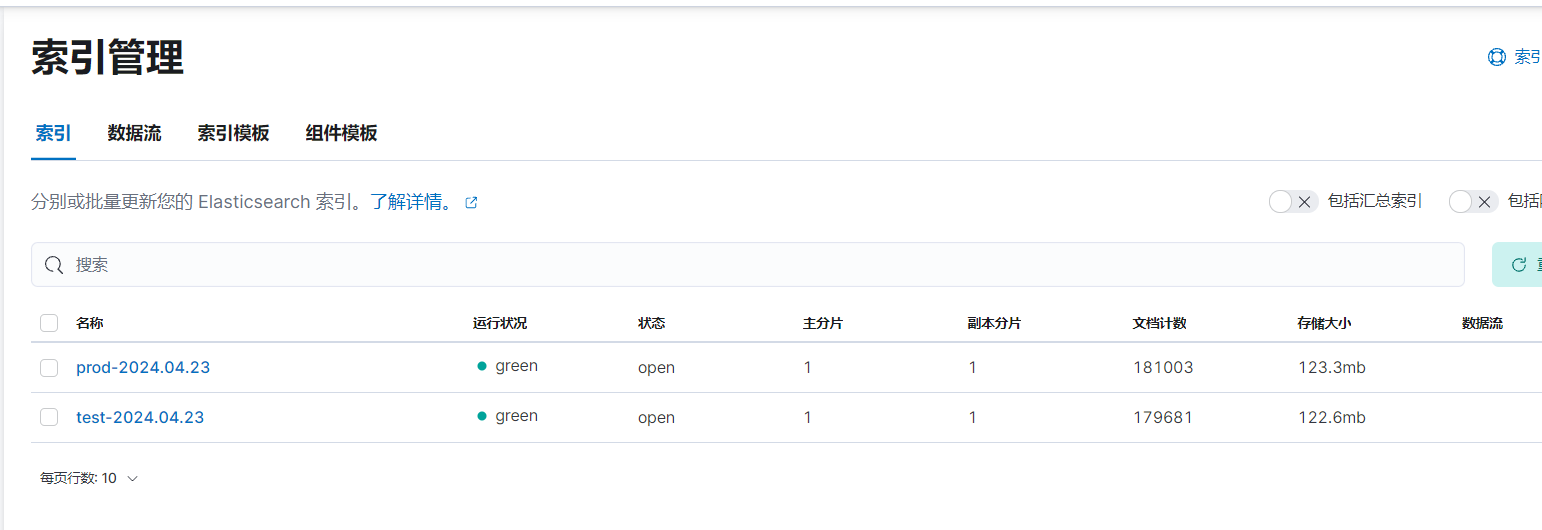
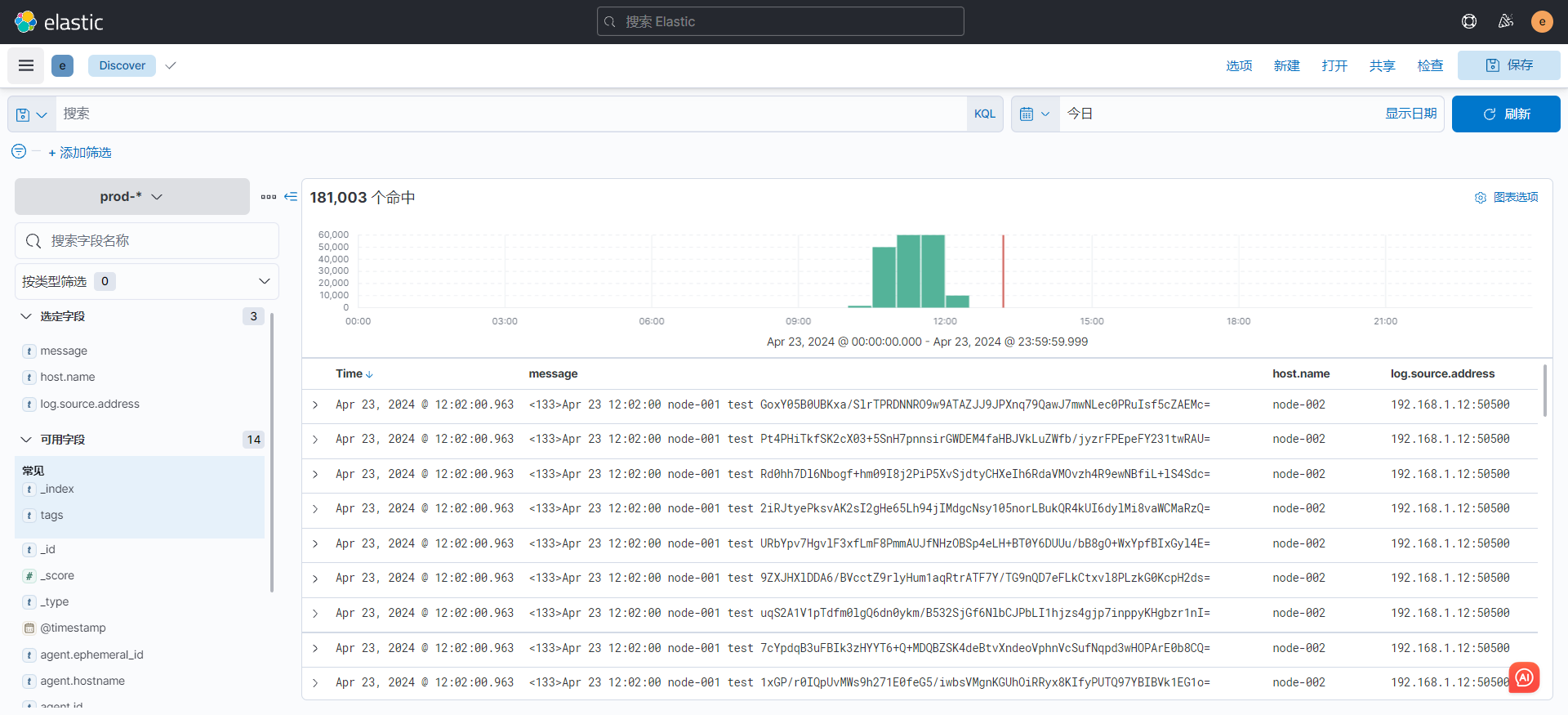

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









