







文章太多了就需要有一个像文件夹一样的东西进行分类,方便管理,CSDN中设置了专栏来进行文章的分类管理。
下面介绍专栏的创建和管理,以及文章的创建和管理。
1.专栏的创建
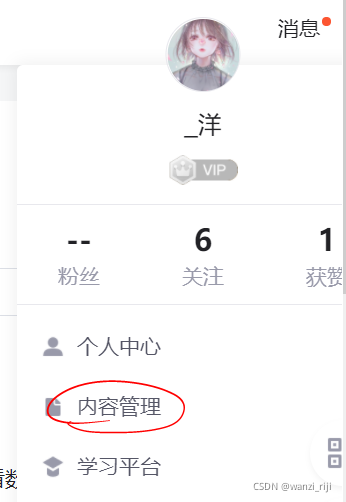
(1)悬浮到头像->点击内容管理
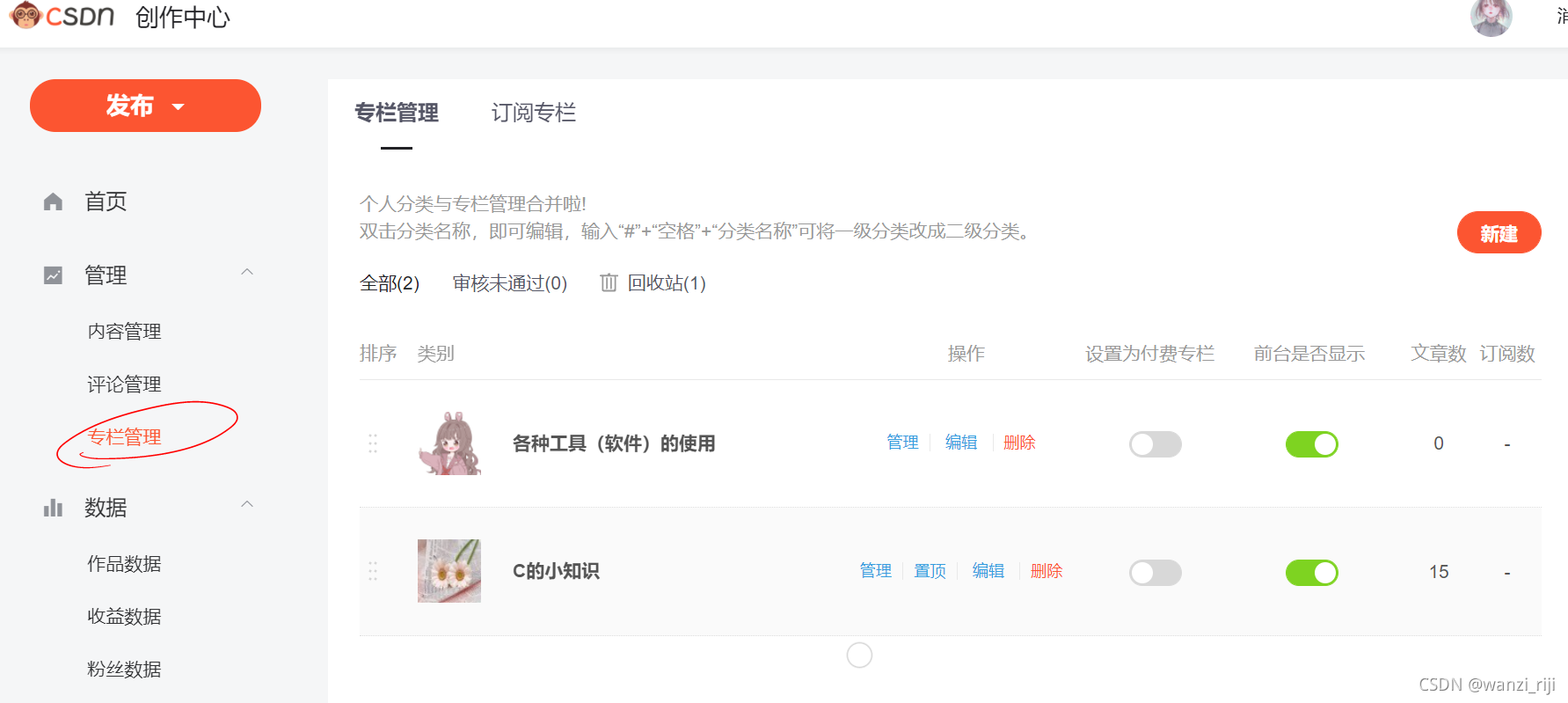
(2)选择 管理->专栏管理
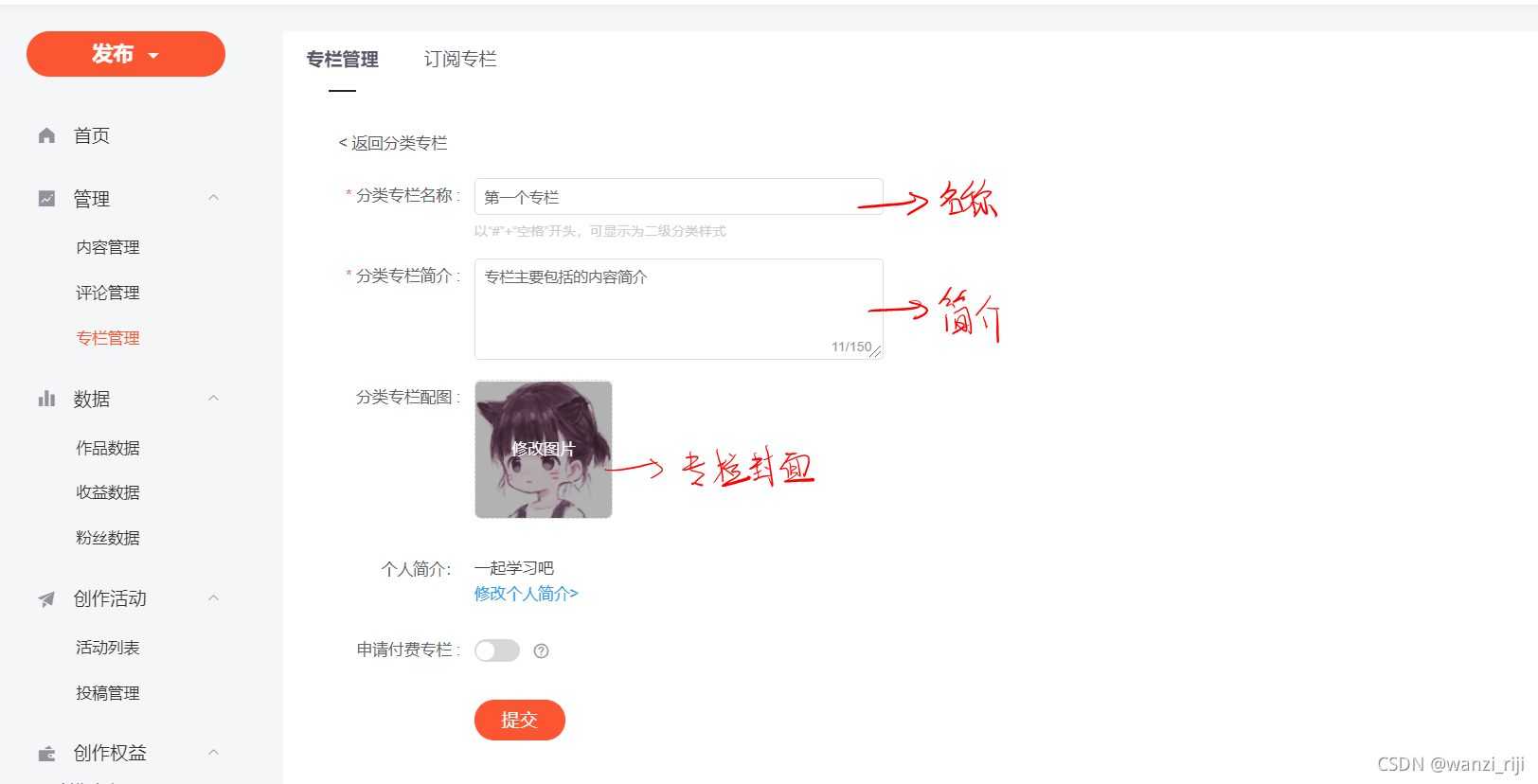
(3)选择右侧创建,进行如下内容的设置
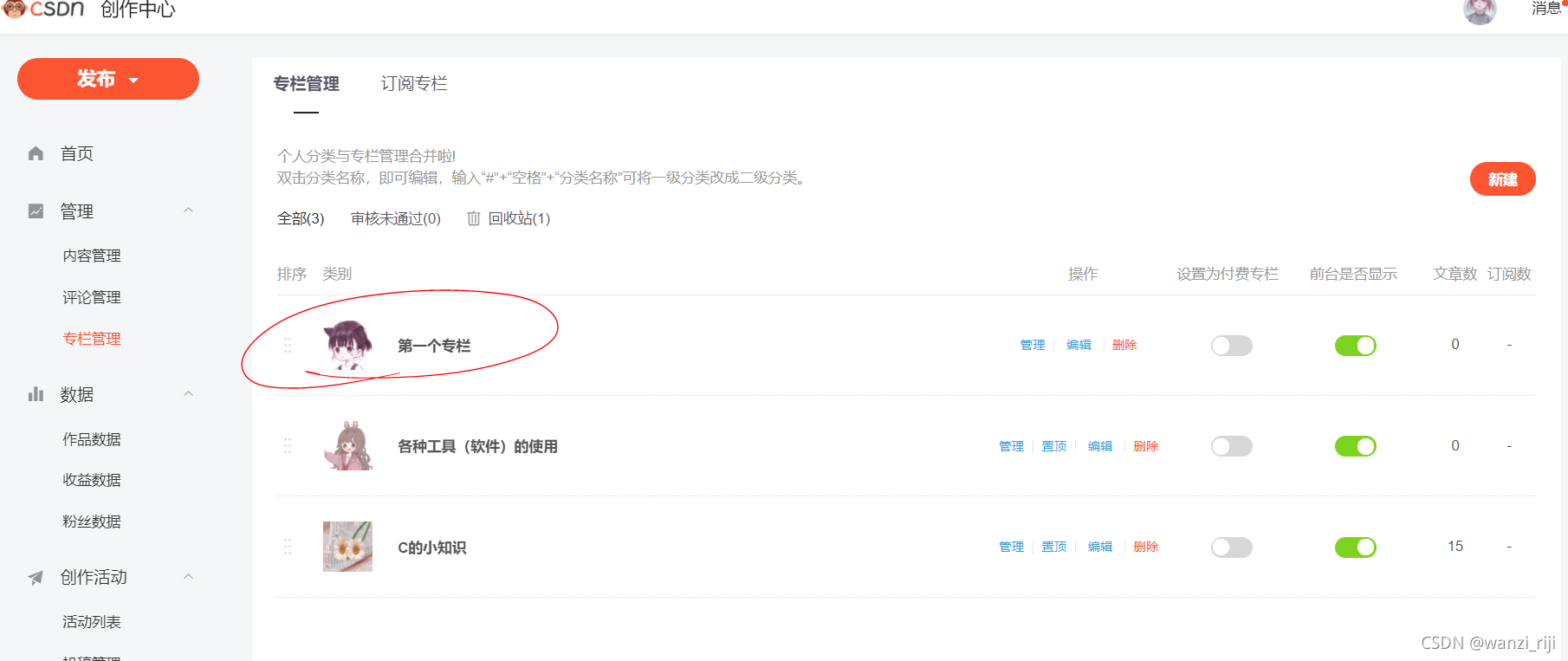
 (4)点击提交即可创建成功
(4)点击提交即可创建成功
2.文章的创建
(1)选择 发布->文章,即可进入文章的创作界面
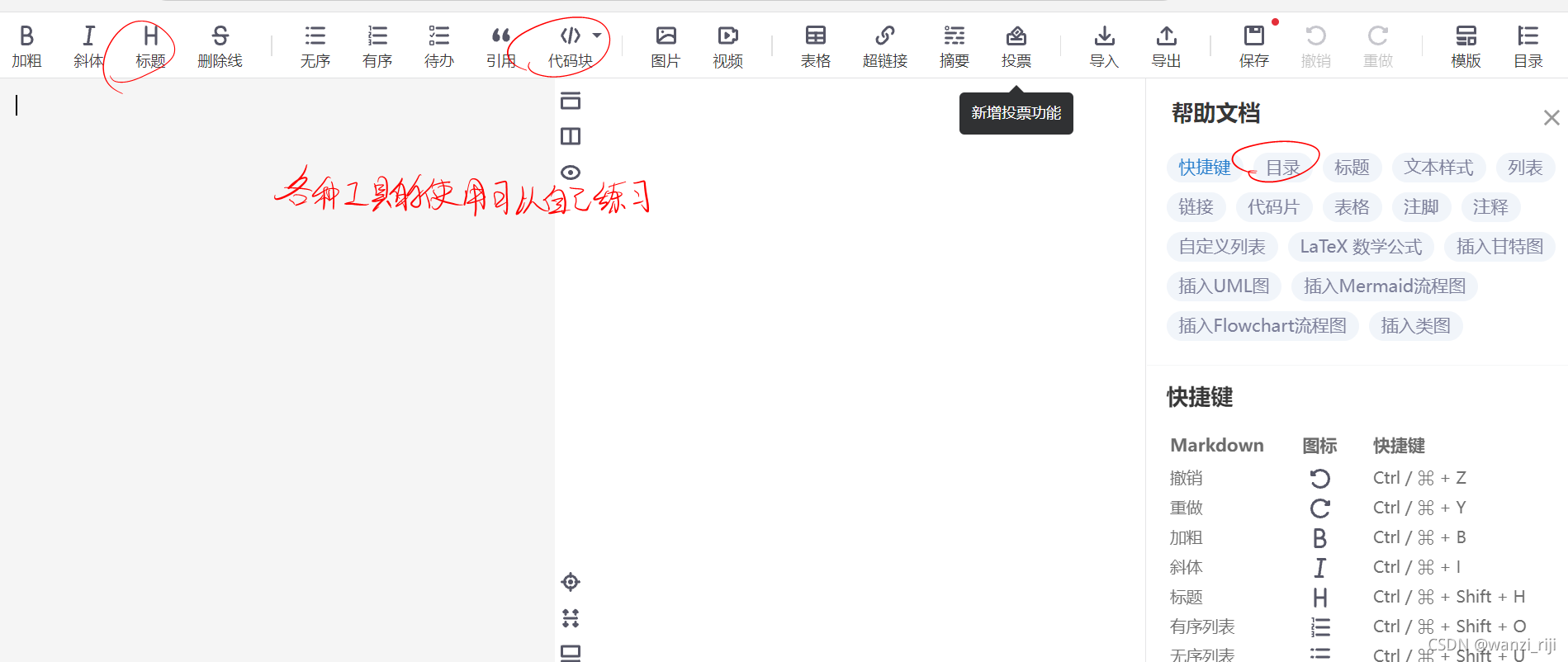
(2)写文章
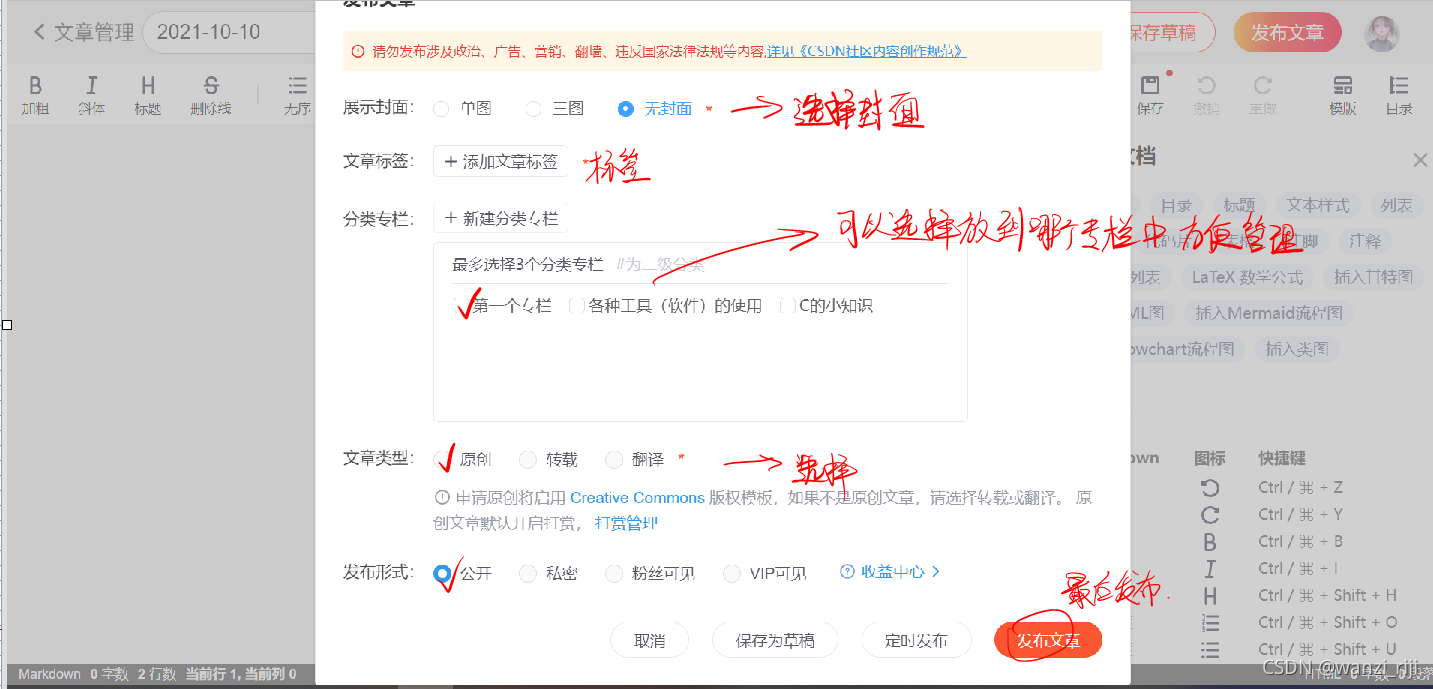
3.右上角点击发布文章,选择如下内容,即可进行发布
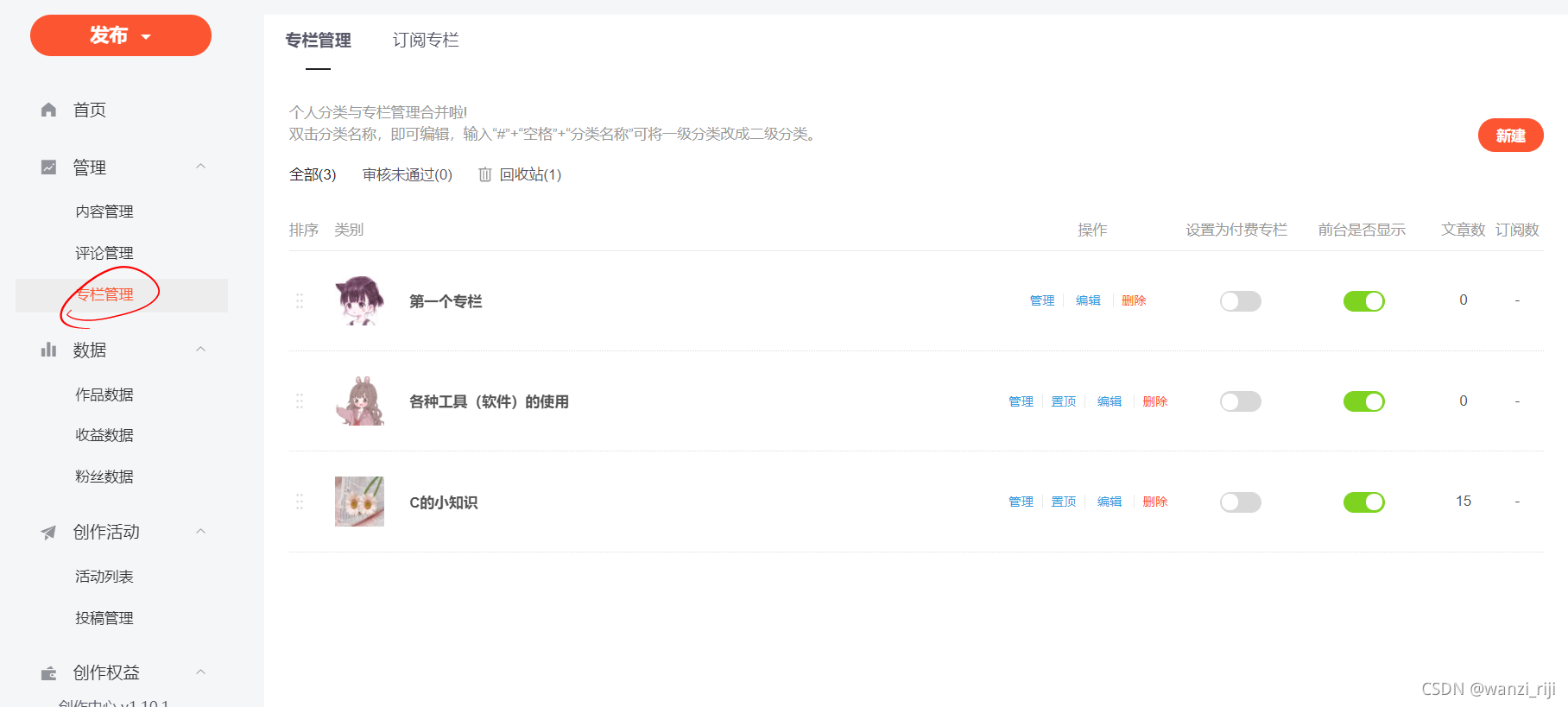
3.专栏的管理
(1)点击 管理->专栏管理
(2)修改专栏信息
选择专栏上的->编辑 可以进行专栏基本信息的修改
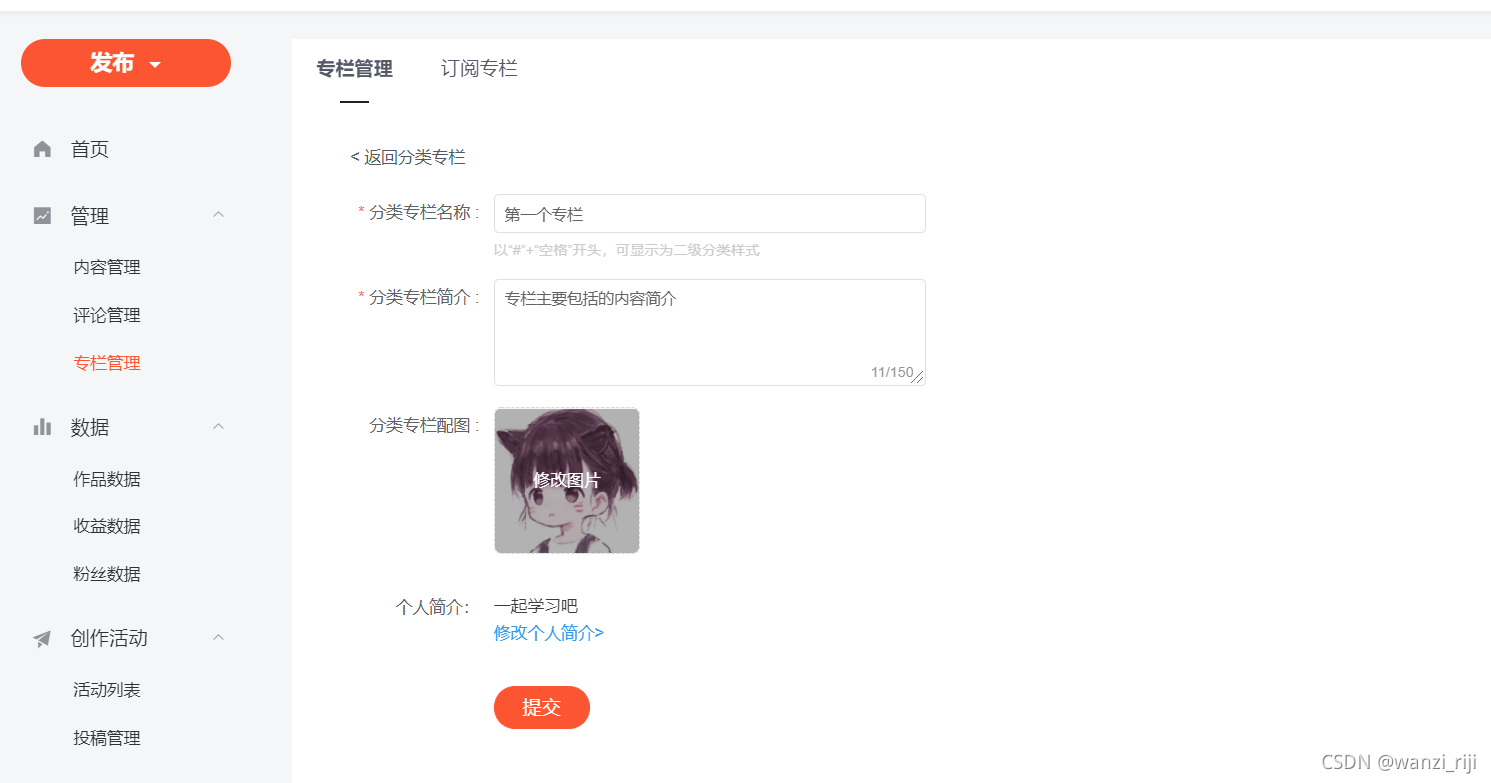
(3)选择管理,可以进行对专栏里面文章的修改
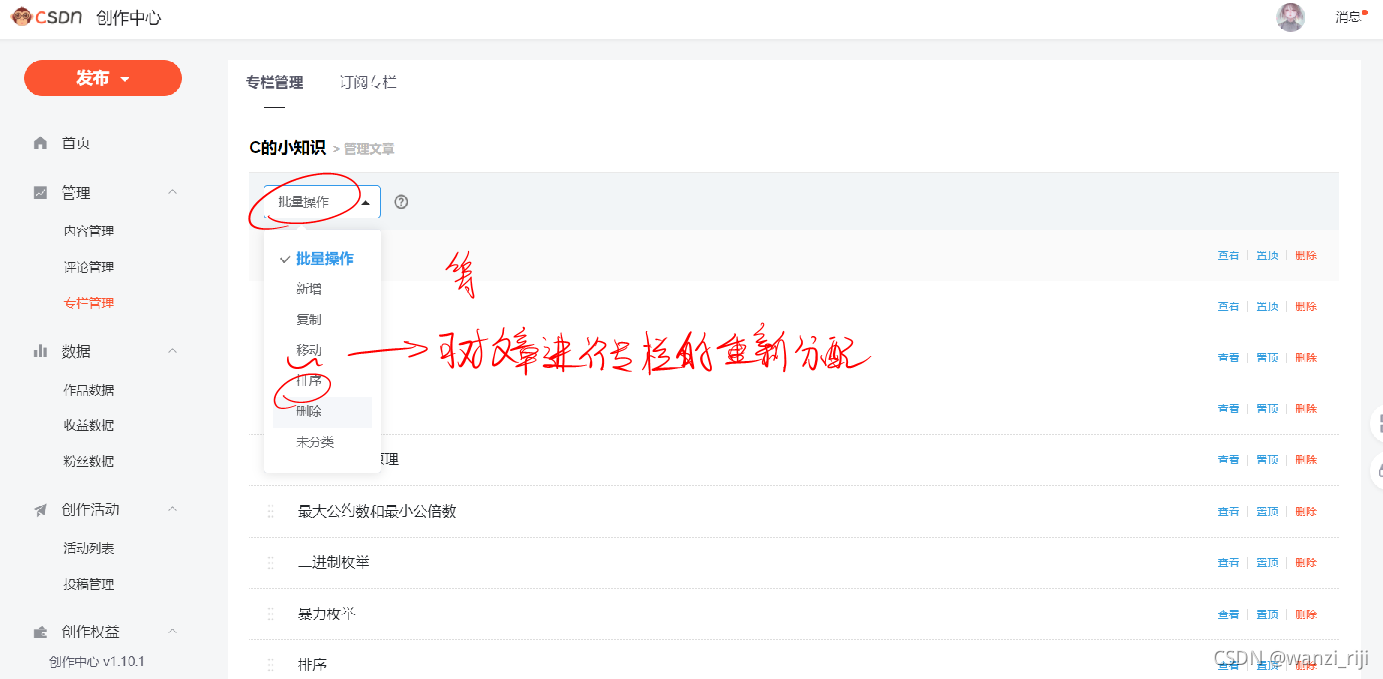
4.文章的管理
(1)对于已经发布的文章,点击变价可以进行重新修改
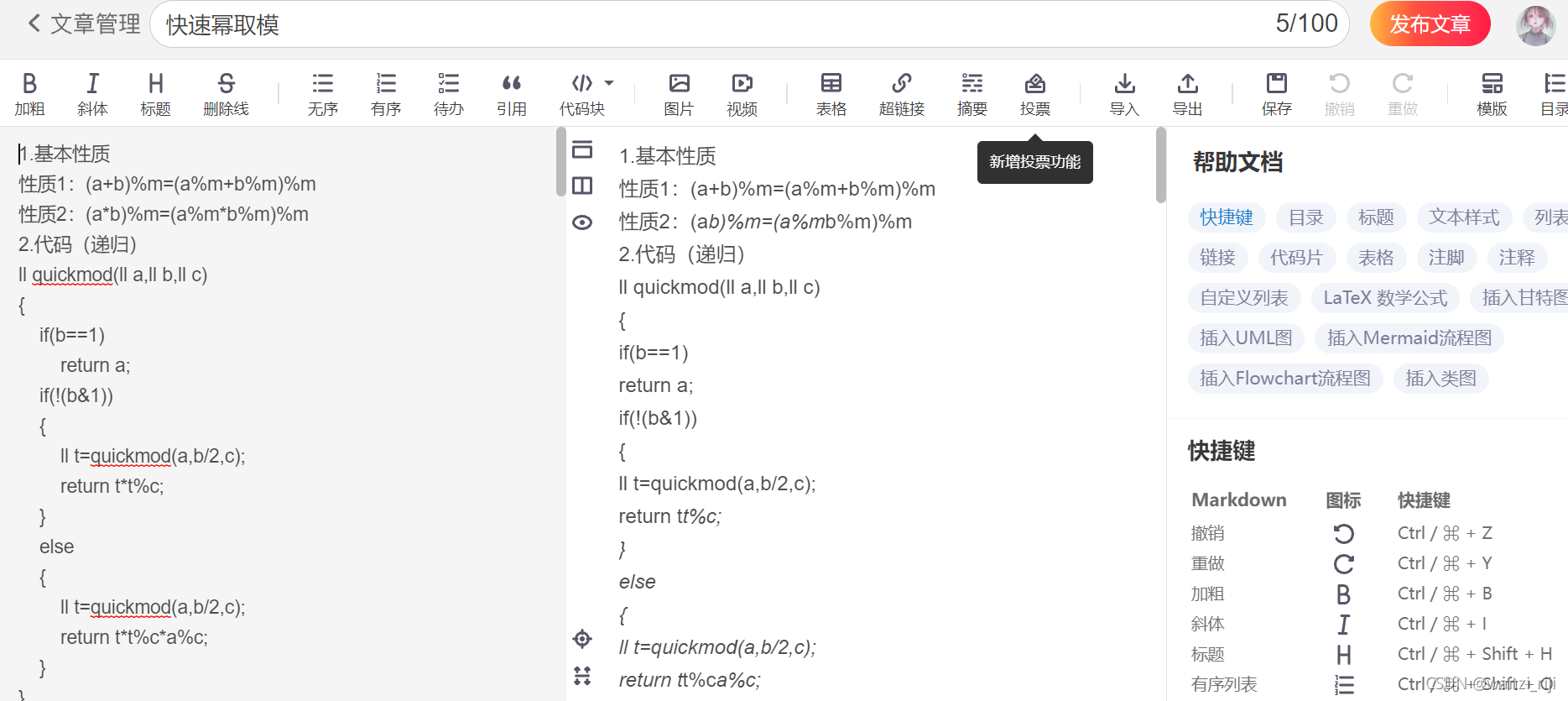
(2)如果想将已发布的文章放入某一专栏,需要对文章进行编辑,然后重新发布,发布的时候选择对应的专栏即可。(不知道还有没有更好的办法)
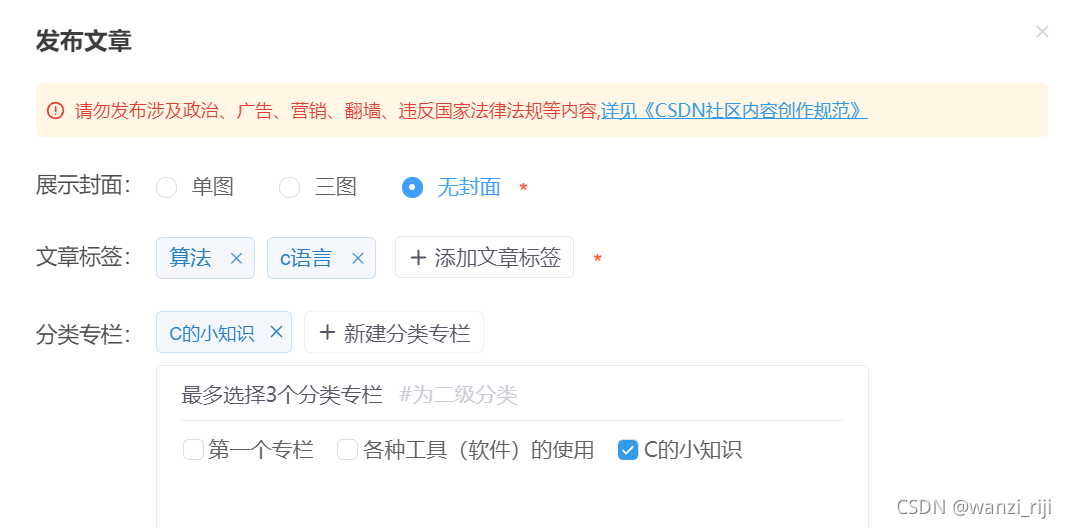
今天的分享就结束啦!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









