







目录
1. 前言概述
Grafana 支持时序数据(数据源)的许多不同的存储后端,如prometheus、Alertmanager、Elasticsearch、mysql等,每个数据源都有一个特定的查询编辑器,每个数据源的查询语言也不同,单个Dashboard可以存在多个数据源,每个面板可以绑定特定数据源。
grafana每个版本的查询语句、变量引用等均有差异,注意确认各个版本是否适用。
关于各种类型的datasource,查询语句可以参考官方文档:Data sources | Grafana documentation
2. Data Source & Explore
2.1 添加 datasource
http://127.0.0.1:3000/datasources -> Add data source
2.2 查询器 Explore
地址:http://127.0.0.1:3000/explore
查询器 Explore,可以快速上手不同data soure查询语法的一个工具,上面说到,不同的data source,使用的查询语法都不同,为了构建用于可视化的仪表板,通过查询器进行查询,然后构建对应的仪表板
如数据源为prometheus的 explore
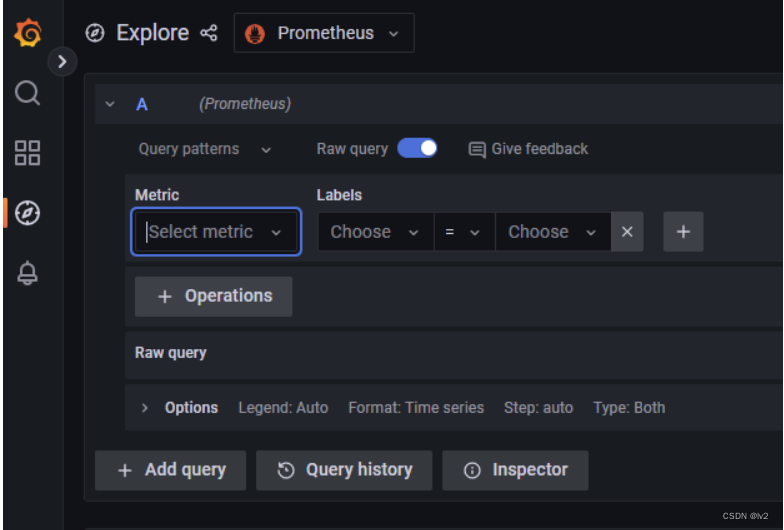
下面,以prometheus为例,通过expolre快速上手prometheus查询语法,并创建自定义查询面板
参考文档:Prometheus | Grafana documentation
3. Prometheus查询语法
3.1 prometheus查询编辑器
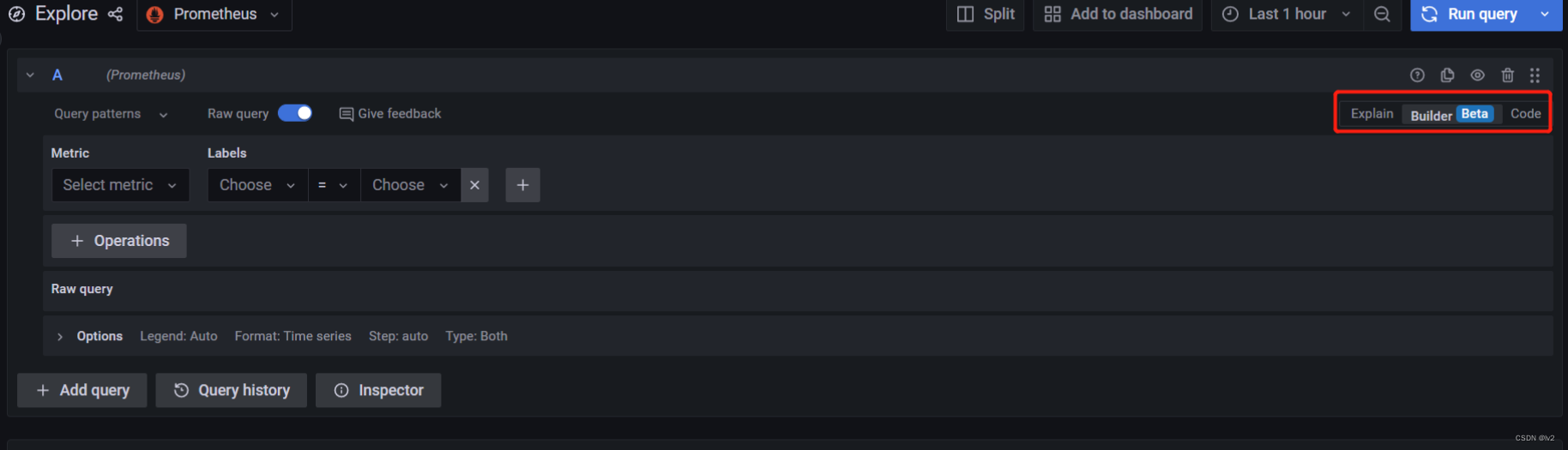
Prometheus查询编辑器有3种不同的模式:Explain、Builder和Code,可以在这些模式之间切换且不会丢失查询配置,这3种不同的模式,区别在哪?
3.2 Code模式
code模式就是使用promsetheus查询语法,可以自动完成功能和语法突出显示,以帮助编写复杂的查询。此外,还包含进一步帮助编写查询,可以参阅Querying basics | Prometheus
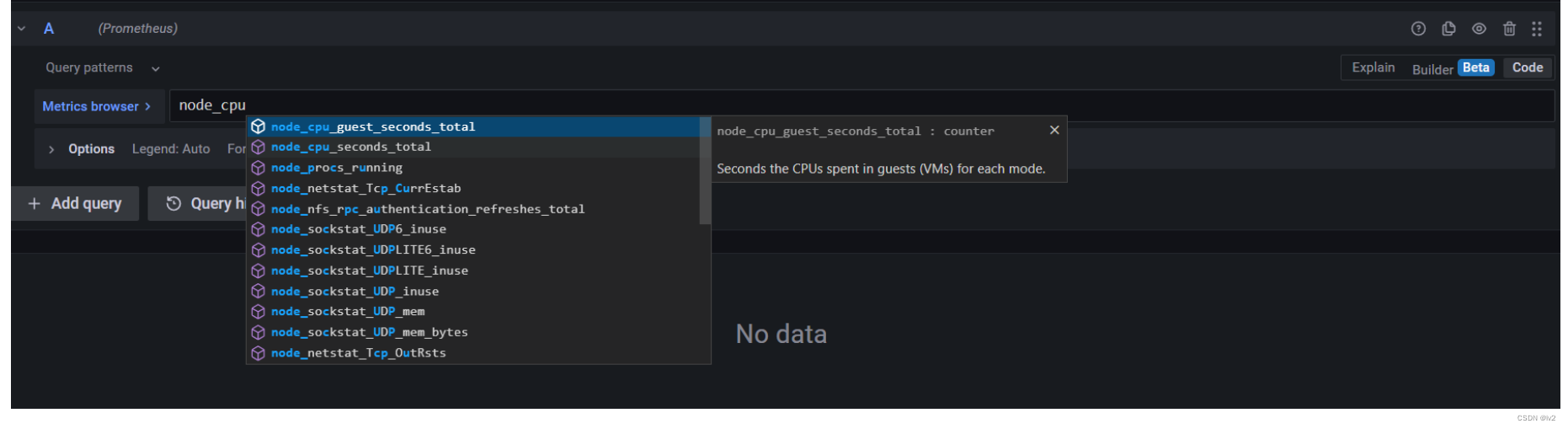
code模式除了手动输入查询语句外,还有一个metric browser,可以通过手动选择一个或多个相关标签来生成基本的查询语句,非常方便实用
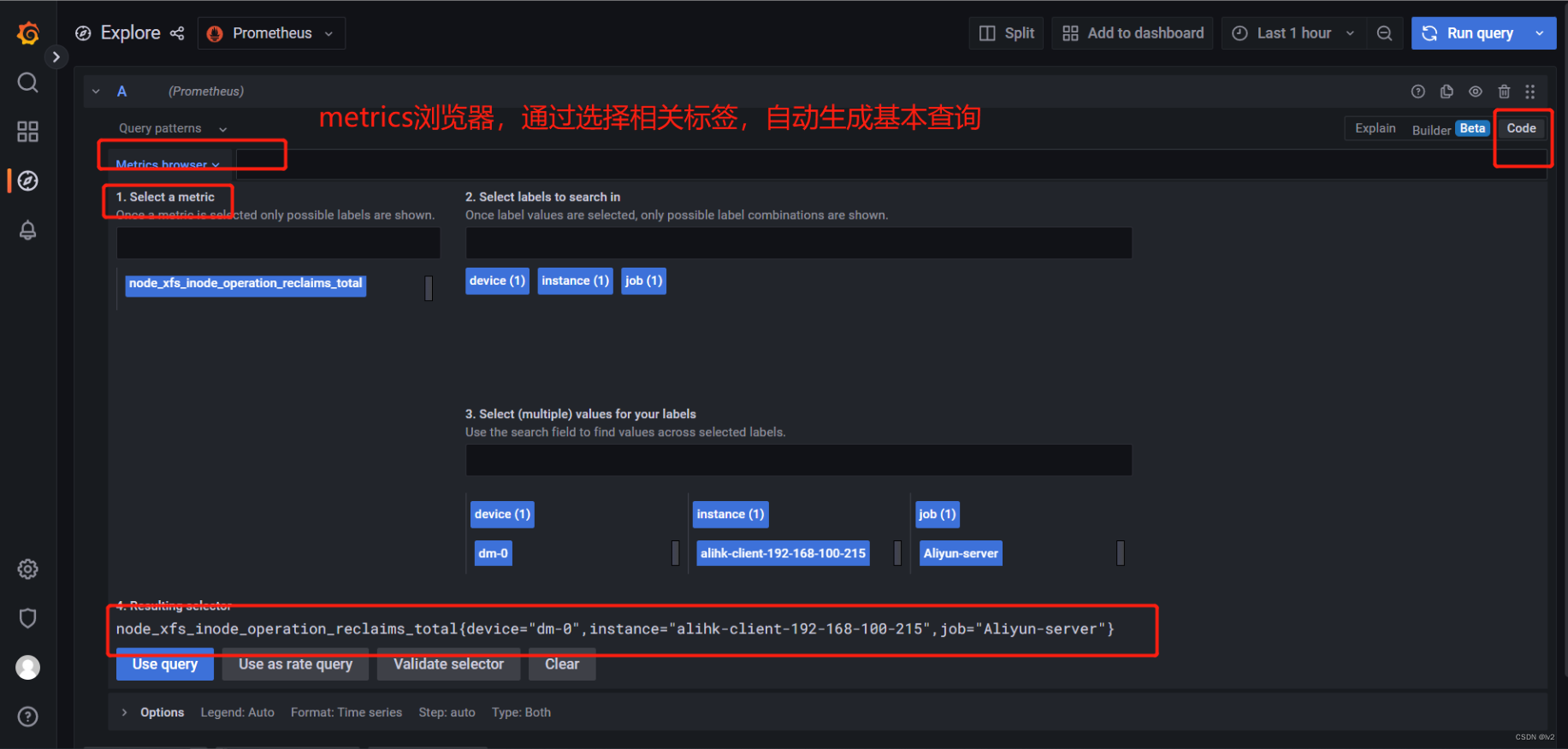
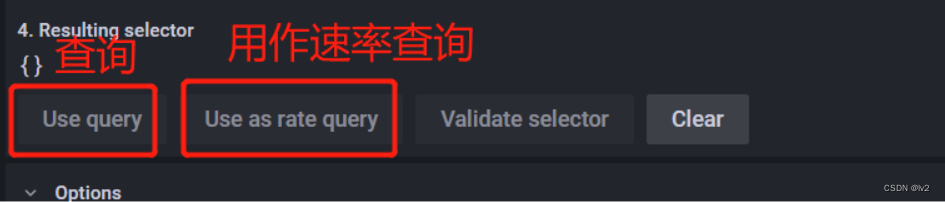
默认是使用查询的方式来运行查询,也可以选择速率查询(比如CPU用量的查询)
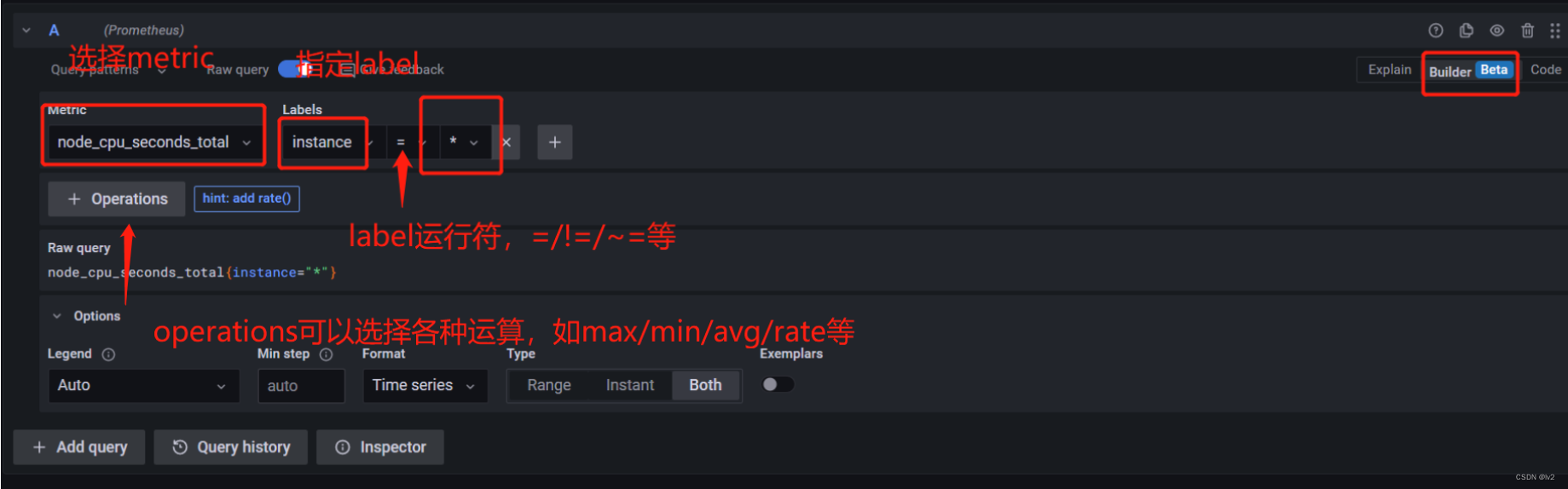
3.3 builder模式
builder模式,也称为生成器模式,从下拉列表中选择指标可用指标列表根据选定的时间范围从Prometheus服务器获取。当下拉列表打开时写入选择以搜索和筛选列表。
从下拉列表中选择所需的标签及其值。选择指标后,将从服务器获取可用的标签及其值
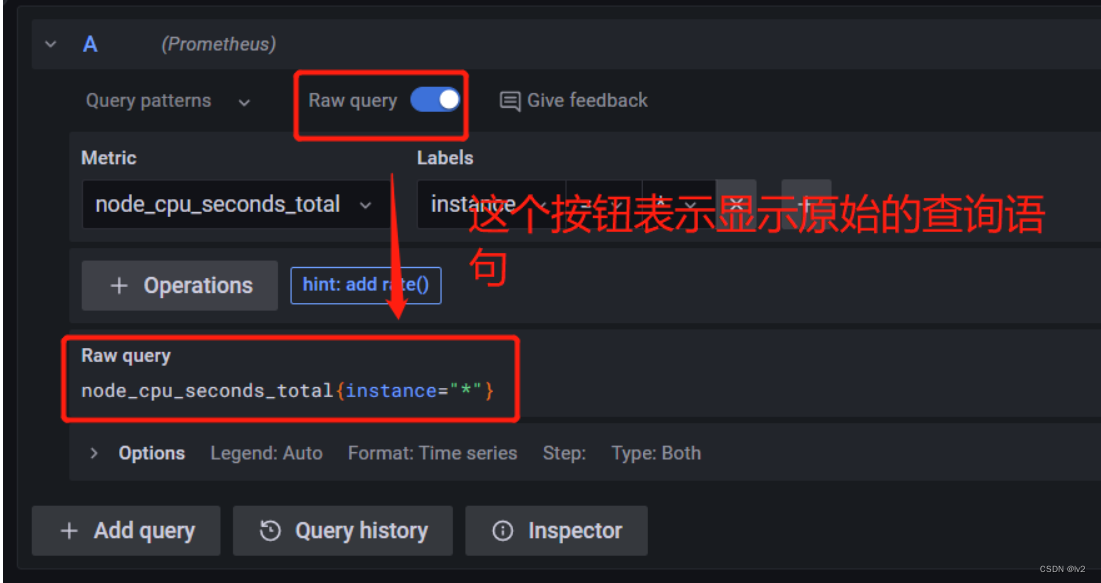
3.4 Explain模式
explain模式,字面意思,就是解释查询语句的作用是什么

3.5 查询变量
支持在查询中使用变量,grafana默认全局变量参考:全局变量|格拉法纳文档 (grafana.com),也可自定义变量
在查询中使用变量有两种语法:
$<varname>示例:rate(http_requests_total{job=~“$job”}[5m])
[[varname]]示例:rate(http_requests_total{job=~“[[job]]”}[5m])3.6 小结
以上三种模式,一般常用的方式是builder或code模式,具体还要看个人对查询语句熟悉程度,通过explore可以快速生成查询语句,并一键生成对应的panel面板
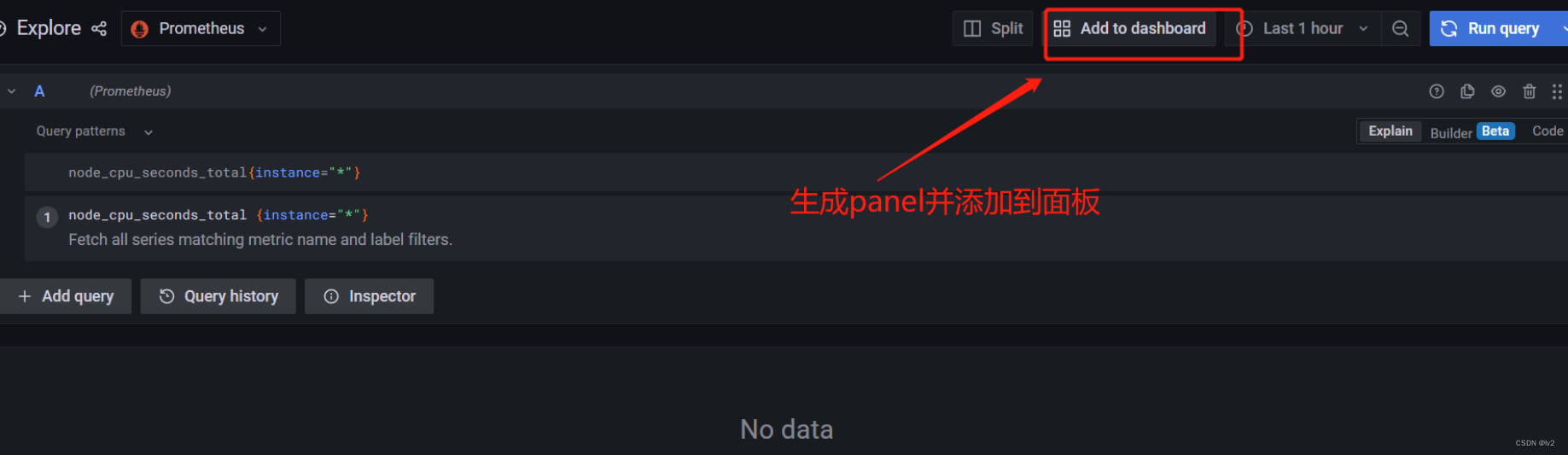
可以通过需求自定义生成相关面板
4. 自定义Dashboard
前提:
- 熟悉对应数据源查询语法
- 熟悉各项指标数值(如promtheus metric、mysql表结构)
以prometheus为例,创建自定义主机资源聚合面板,包含整体CPU、内存、磁盘利用率及IO等待等,完全效果如下
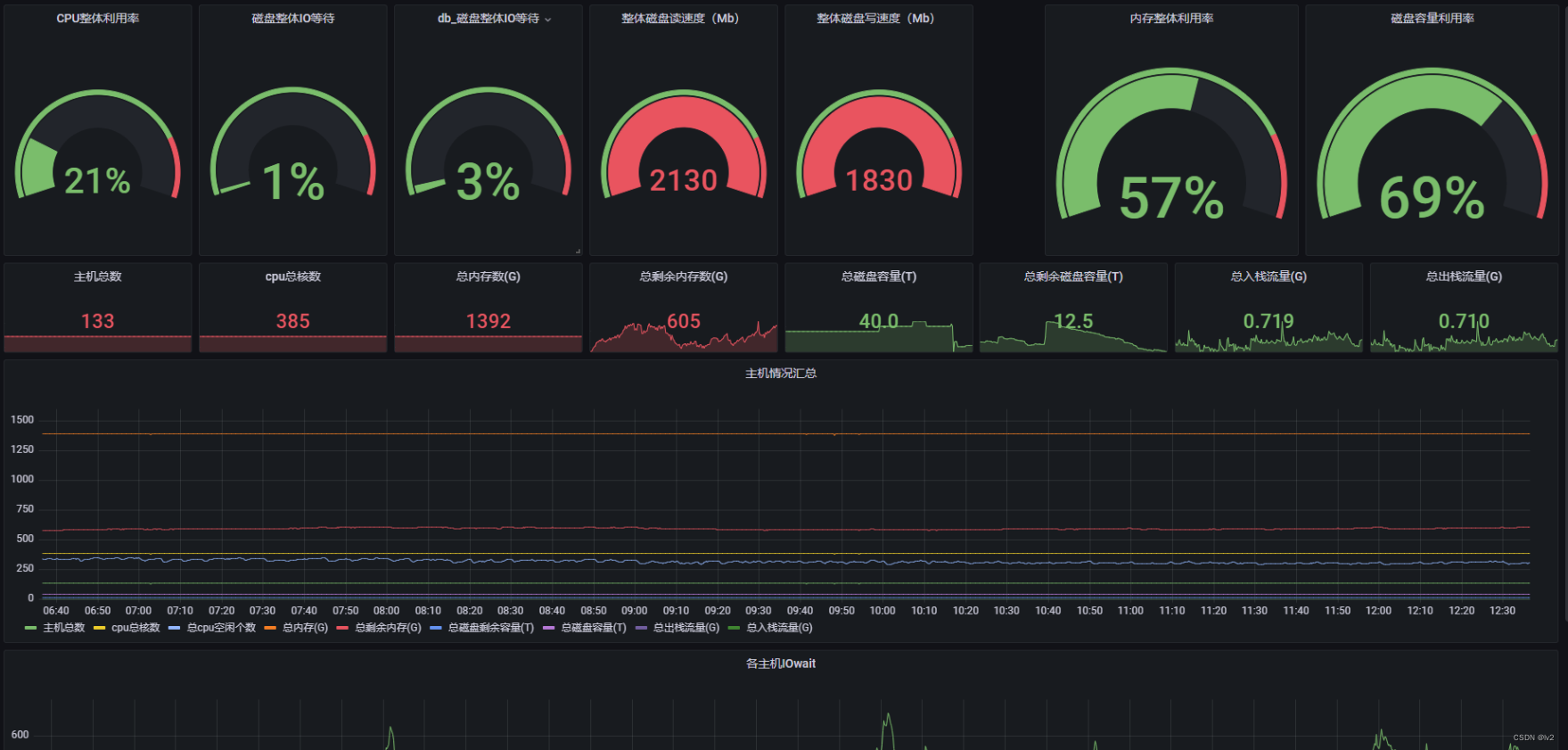
4.1 自定义主机查询面板
CPU整体利用
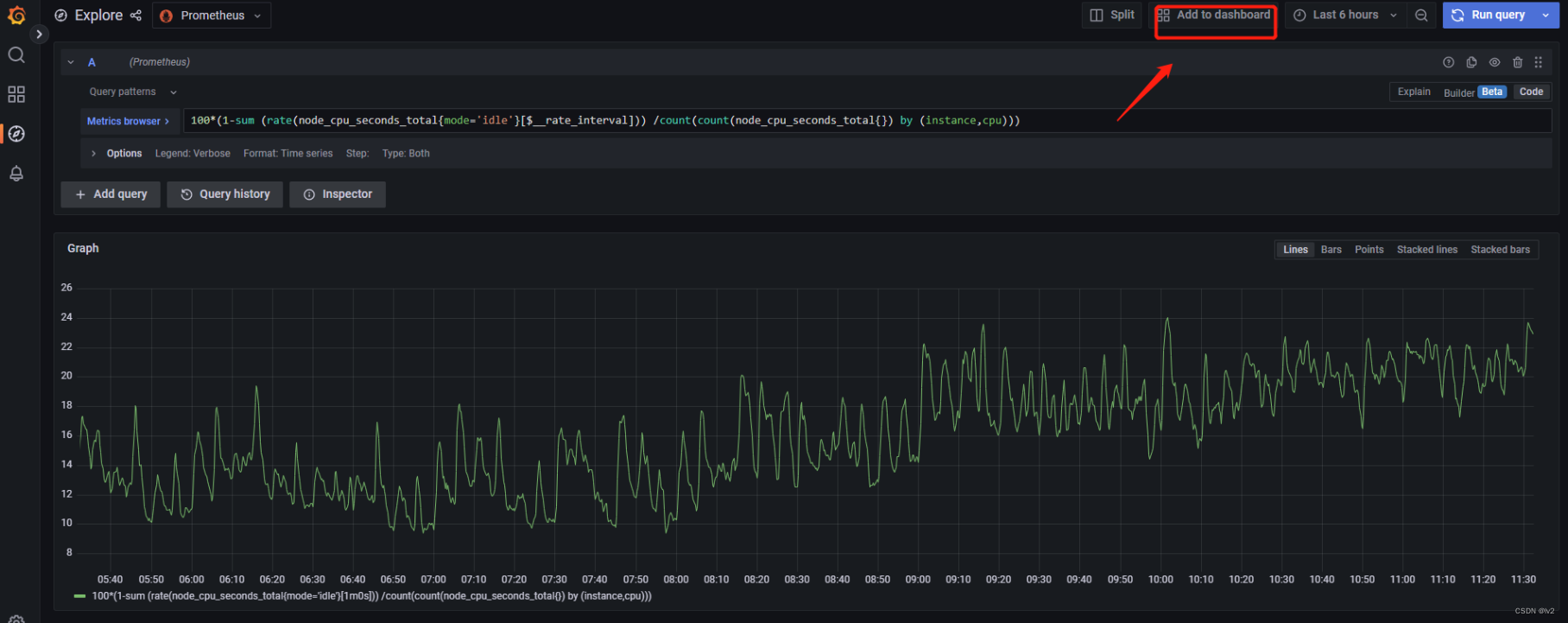
100*(1-sum (rate(node_cpu_seconds_total{mode='idle'}[$__rate_interval])) /count(count(node_cpu_seconds_total{}) by (instance,cpu)))说明:
[$__rate_interval]:速率函数,仅限proetheus数据源使用,适合曲线图展示的 rate(),值不固定,且一定大于$__interval,适用于>= grafana 7.2版本,官方的说明是比固定时间间隔更好用,如[5m]每5分钟间隔,
OK: rate(http_requests_total[5m])
Better: rate(http_requests_total[$__rate_interval])将查询添加到Dashboard
可视化 -> Gauge
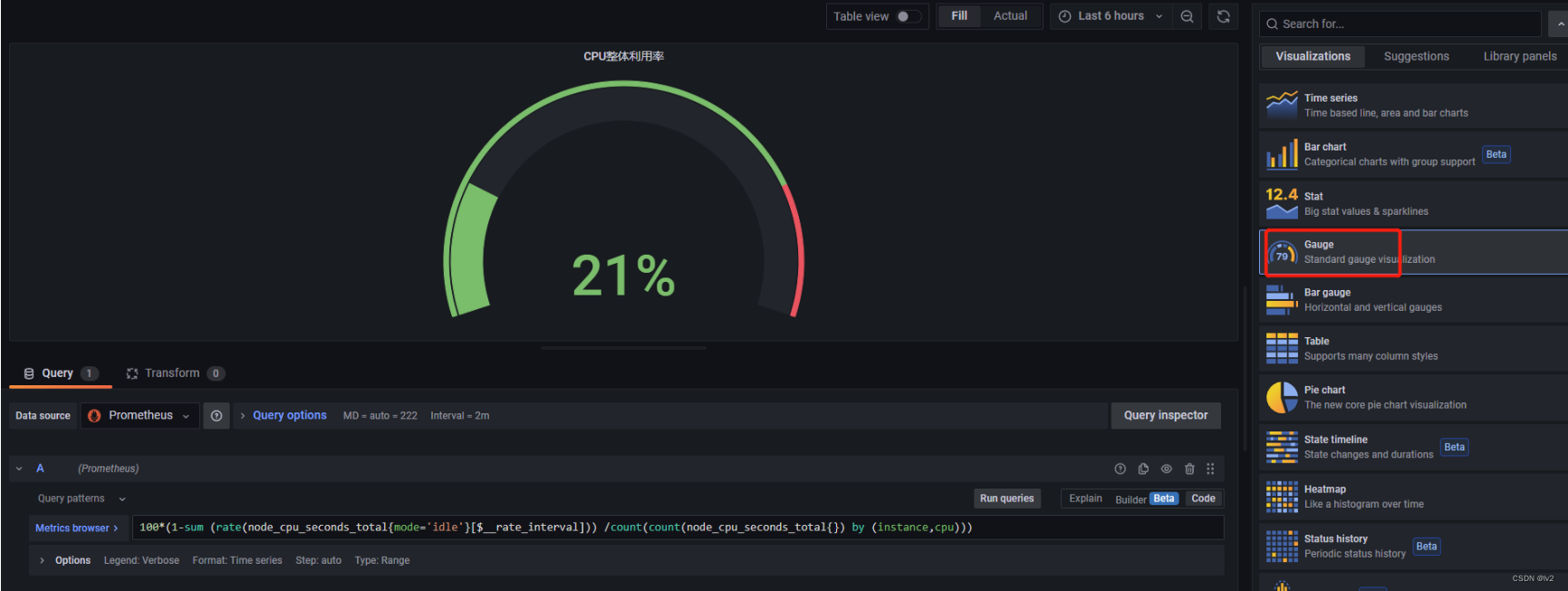
其它的面板大同小异,区别在于可视化类型不同
磁盘整体IO等待
(sum (rate(node_cpu_seconds_total{mode='iowait'}[$__rate_interval]))*100) /count(count(node_cpu_seconds_total{}) by (instance,cpu))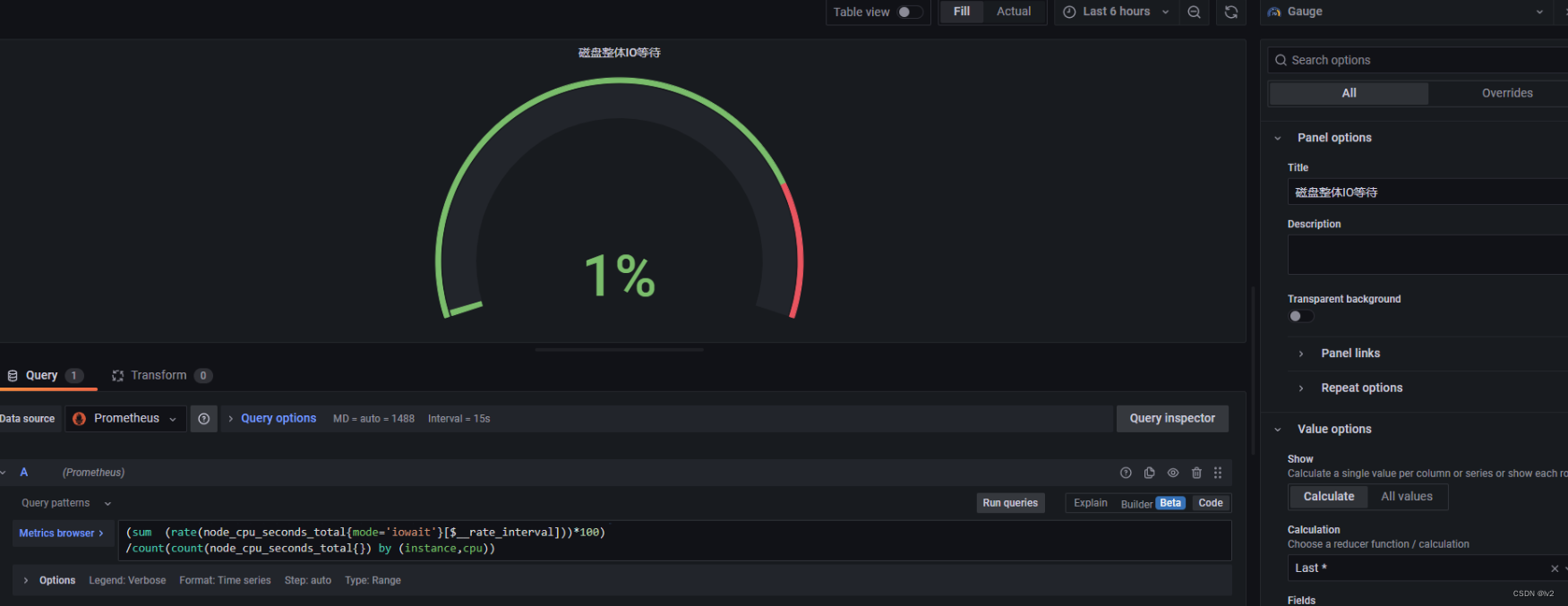
整体磁盘读/写速度
读
sum(rate(node_disk_read_bytes_total{}[$__rate_interval]))/1024.0/1024.0*8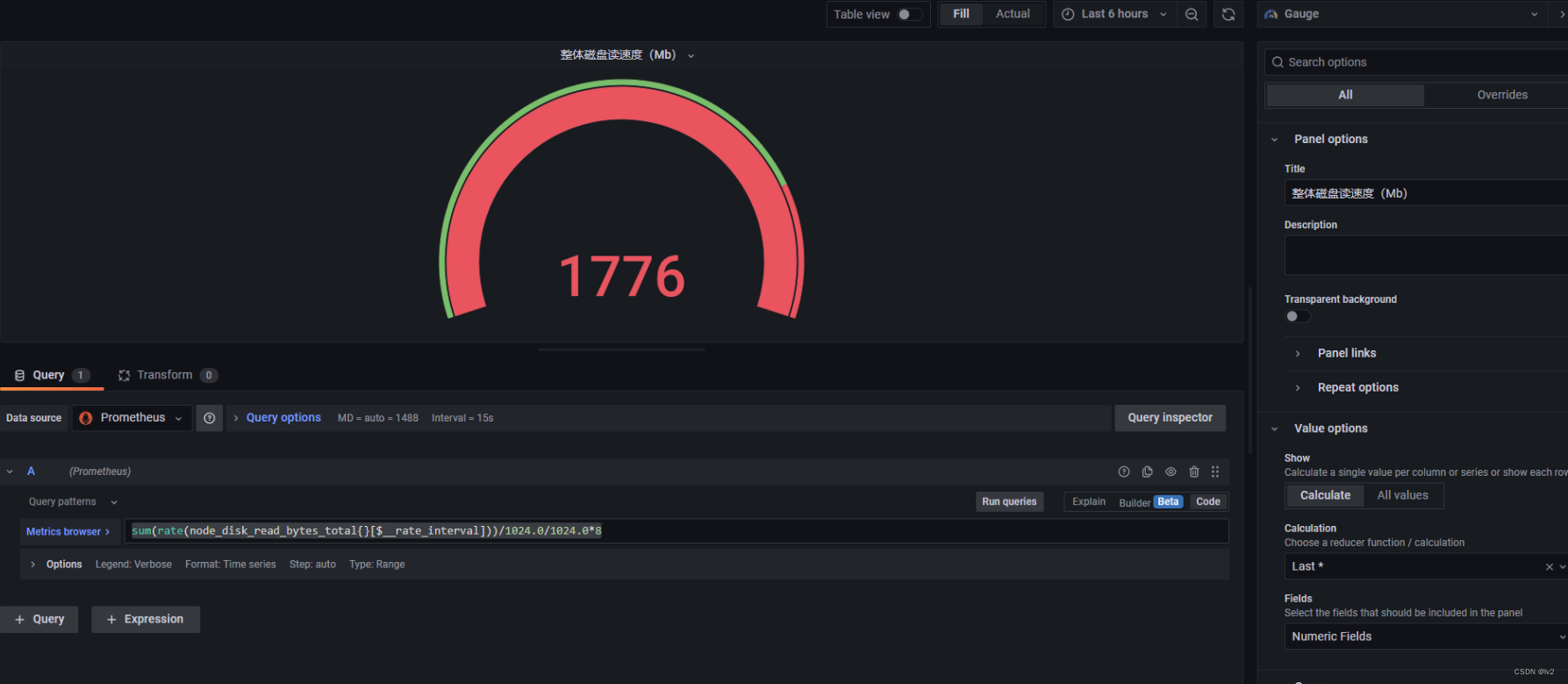
写
sum(rate(node_disk_written_bytes_total{}[$__rate_interval]))/1024.0/1024.0*8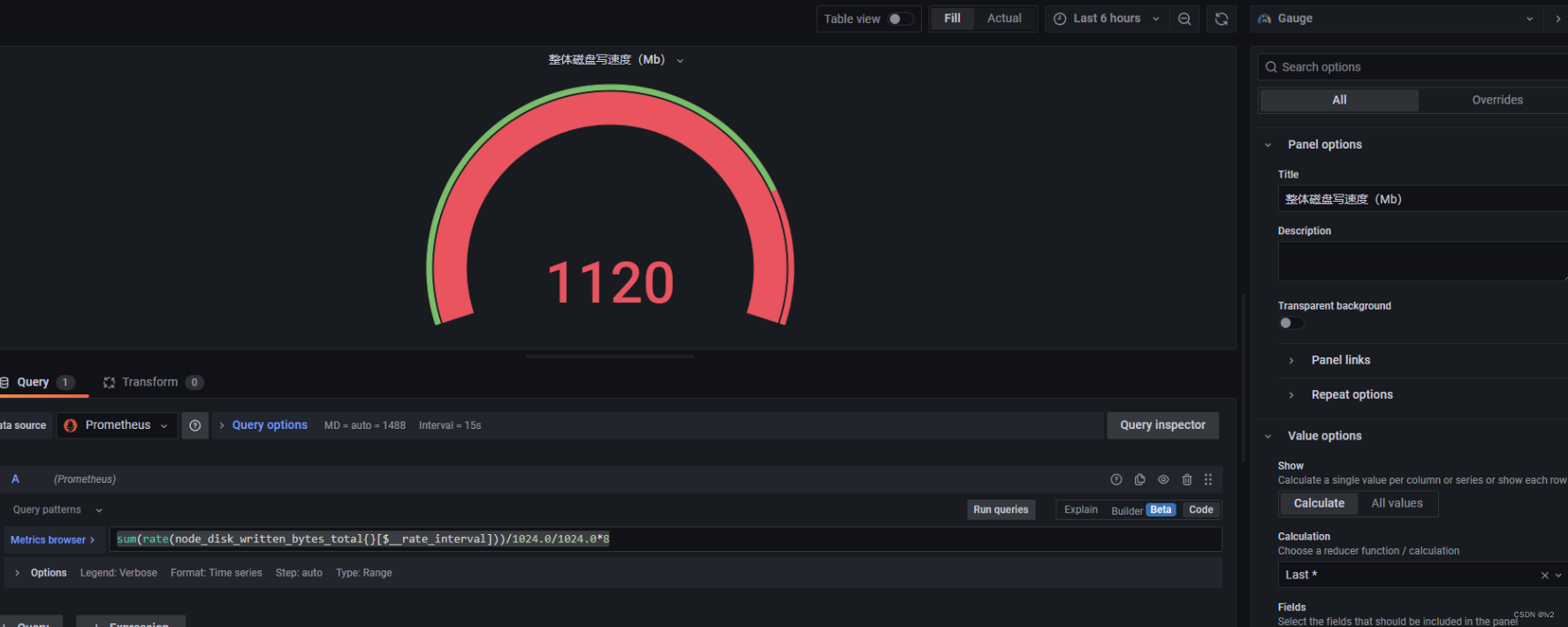
内存利用率
100*(1- (sum(node_memory_MemFree_bytes{}+node_memory_Cached_bytes{} + node_memory_Buffers_bytes{} + node_memory_SReclaimable_bytes{})/1024/1024/1024) / (sum(node_memory_MemTotal_bytes{}) /1024/1024/1024) )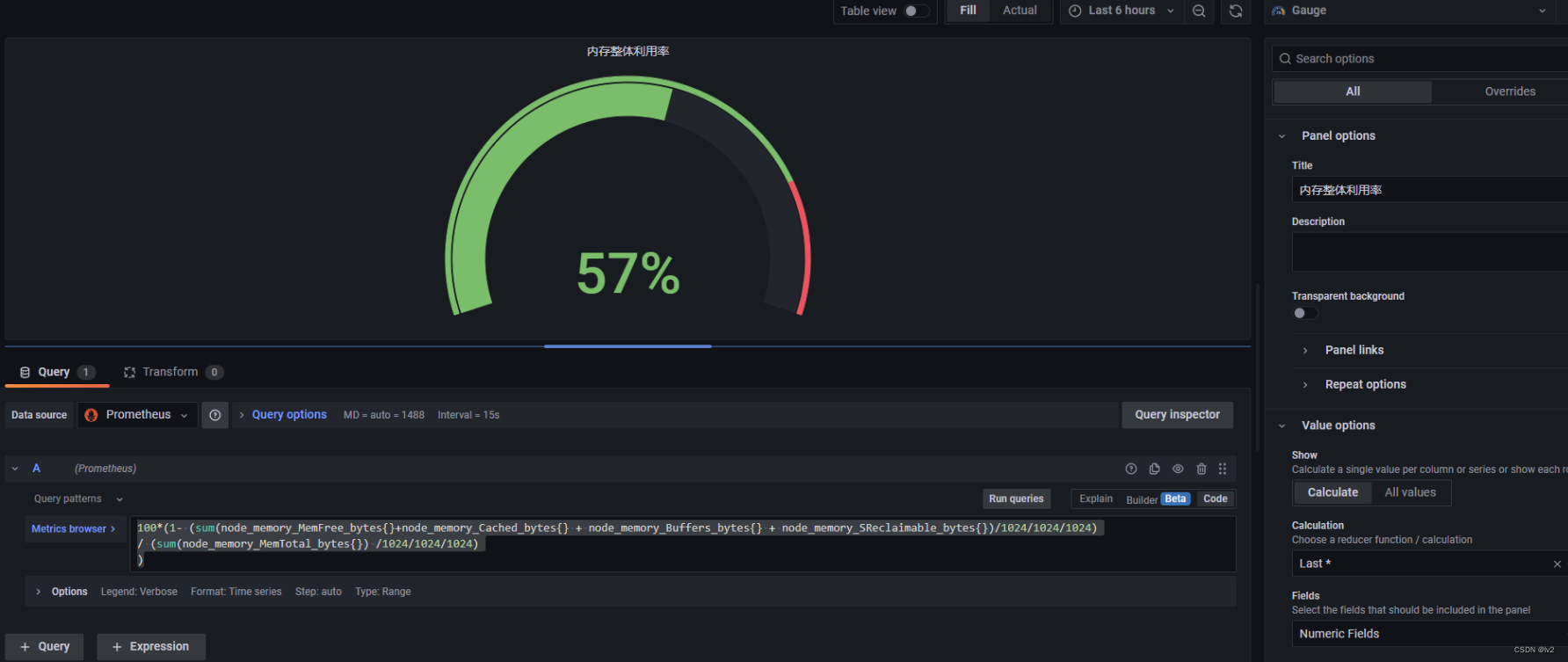
磁盘容量利用率
100*(1- (sum(node_filesystem_avail_bytes{device!~'rootfs',fstype!='nfs'}) /1024/1024/1024/1024) / (sum(node_filesystem_size_bytes{device!~'rootfs',fstype!='nfs'}) /1024/1024/1024/1024) )主机总数
count(node_uname_info{})cpu总核数
count(count(node_cpu_seconds_total{}) by (instance,cpu))总磁盘容量(T)
sum(node_filesystem_size_bytes{device!~'rootfs',fstype!='nfs'}) /1024/1024/1024/10245. 总结&promtheus查询语法
不管使用哪种数据源,都需要了解熟悉对应数据源的查询语法,才能通过查询语法自定义各种各样功能的Dashboard,这里初略总结了prometheus的查询语法
即时矢量选择器,即直接指定metric指标名称,如
node_cpu_seconds_total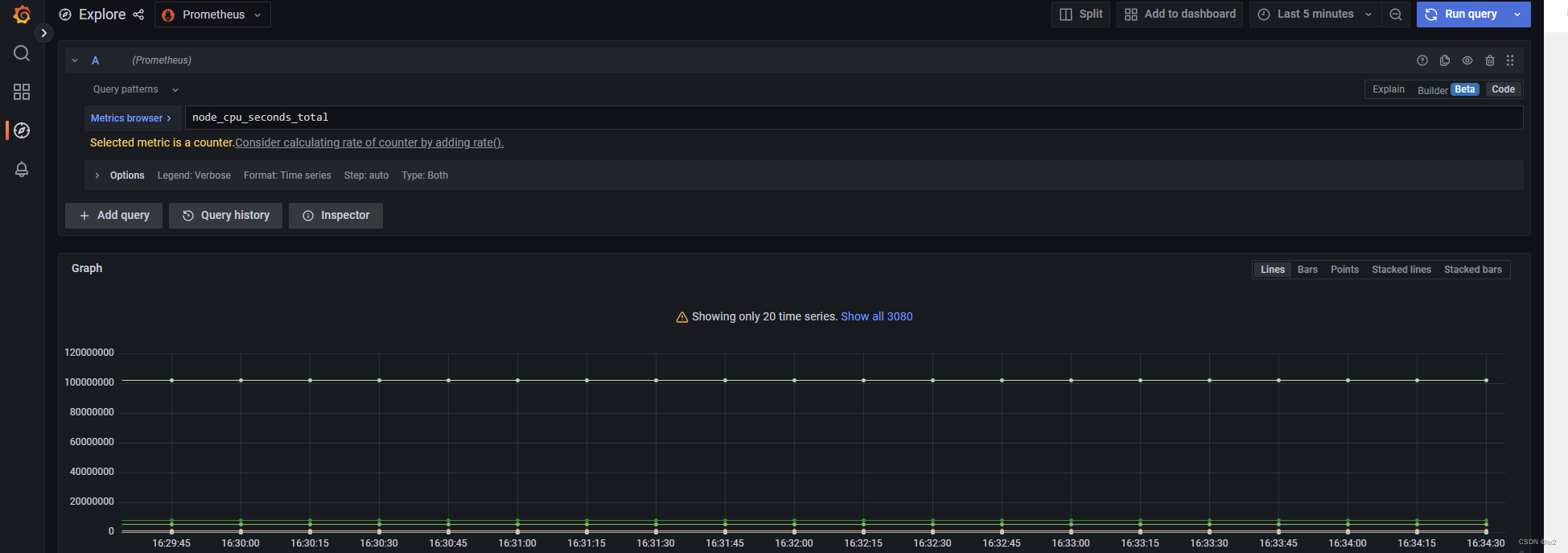
选择指标名称的同时指定标签匹配(可以指定实例、job等)
node_cpu_seconds_total{job="Aliyun-server", mode="idle"}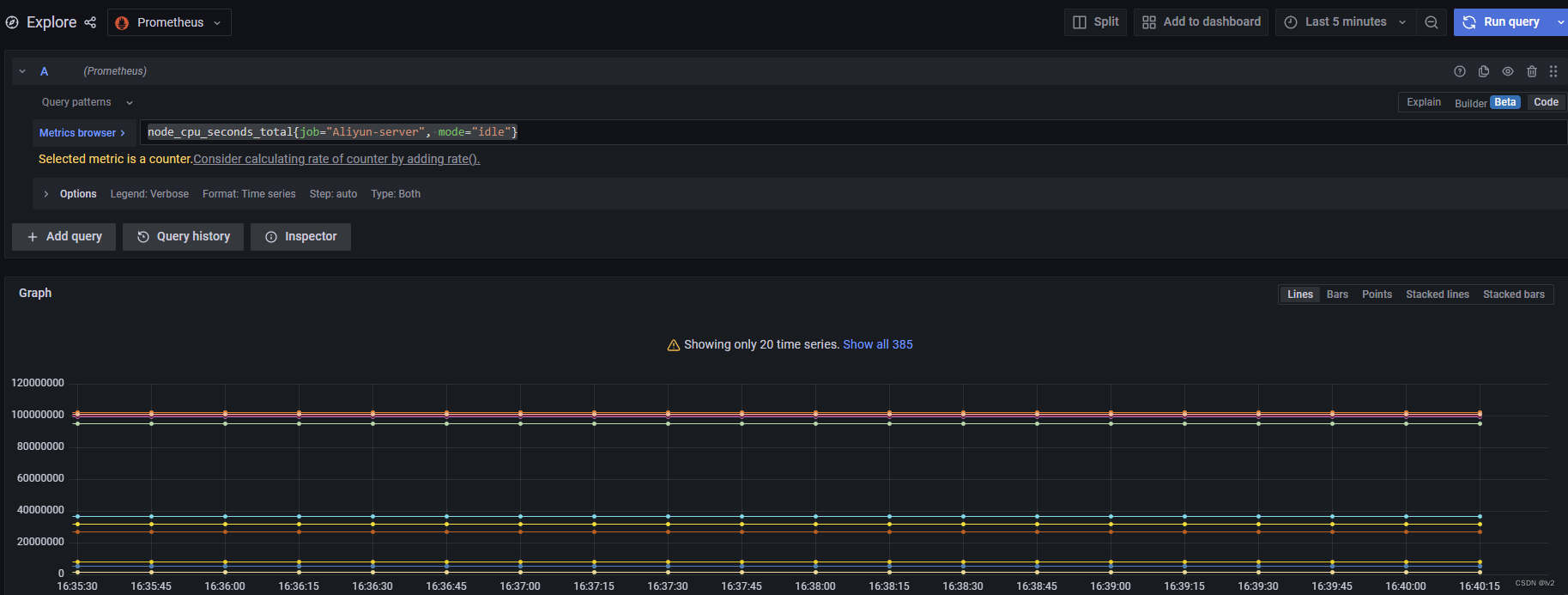
标签匹配运算符:
- =:选择与提供的字符串完全相等的标签。
- !=:选择不等于所提供字符串的标签。
- =~:选择与提供的字符串匹配的正则表达式的标签。
- !~:选择与提供的字符串不匹配的正则表达式的标签。
范围矢量选择器
统计指定时间段内的数据,如统计最近5分钟的cpu的空闲速率
rate(node_cpu_seconds_total{job="Aliyun-server", mode="idle"}[5m])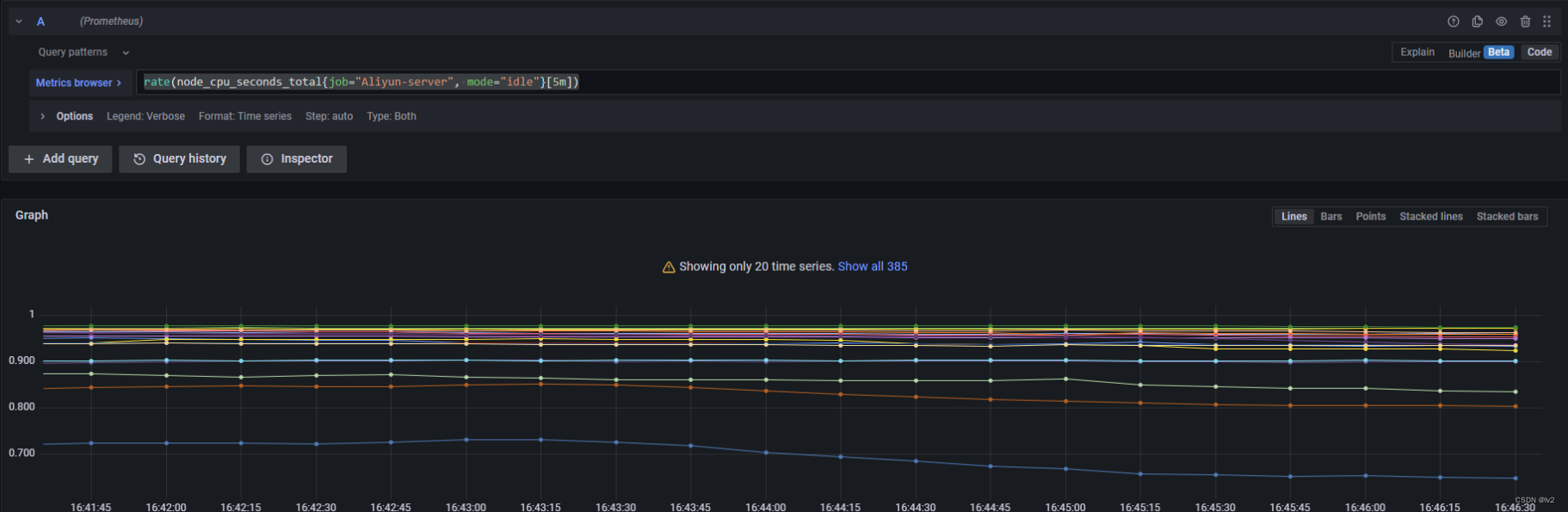
另外还有rate、sum、avg、min、count等各种功能函数,具体请查阅官方文档
觉得有用点个关注和收藏吧~


















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









