







参考链接:
http://blog.csdn.net/u010620604/article/details/52464529
http://blog.csdn.net/guoyilin/article/details/44222087
这篇论文主要讨论如何针对CNN做一些GPU矩阵计算的优化。传统CNN计算主要开销是在convolutions, activation function, pooling.
首先,我们看convolution的操作过程:

参数表:

O是输出input feature map,F是filter, D0是input feature map. 从公式看到如果用循环操作,需要7次循环,n,k,p,q4次可独立循环,c,r,s是累加操作的循环。
其次,我们看convolution在GPU上如何实现,文中介绍了三种方法:
第一,最直观的方法是直接实现如上公式,但是这种实现呢需要处理许多的corner case。 文中介绍cuda-convnet2是实现了该种方法,该种方法在不同取值的卷积参数空间效率不一,比如batch size > 128,效率很高,但是如果batch size < 64, 效率比较低。
第二,采用快速傅里叶变换fft,具体怎么做,参见论文Fast training of convolutional networks through ffts(待读). 该种方法效率非常高,但是由于filter需要扩大到和input一样大小,占用了大量内存,特别是CNN的前几层filter 大小远小于input大小。第二,当striding 参数>1, fft效率也不高。facebook最近开源了fbfft的实现,参见论文fast convolutional nets with fbfft: a gpu performance evaluation(待读).
第三,也就是现在caffe实现的方法。将卷积操作转换为密集矩阵相乘。将input data组装成大小为CRS x NPQ的矩阵,这使得内存相对原始input data的大小扩大了之多RS倍,举个例子,对AlexNet的conv1:
Fm: 96 x 363
Dm: 363 x 387200(设double 类型, 需要临时分配内存1GB)
D: 128 x 3 x 227 x 227 = 19787136.
Dm 是D的内存大小的7倍。
具体卷积是如何转换为矩阵的呢?看如下图:

对照caffe的代码就是im2col_gpu, caffe_gpu_gemm, caffe_gpu_gemm 会调用cublasSgemm.
这种方法使用扩大临时内存方法换取密集矩阵计算的便利。
密集矩阵相乘为什么好呢,值得我们如此牺牲内存代价?因为 it has a high ratio of floating-point operations per byte of data transferred. 当矩阵越大,ratio越高,我们看到该方法的矩阵大小还是可以的,CRS乘机相对比较大。该方法的缺陷是: Dm太大,因此需要分片materiialize Dm,我们看caffe代码实现,在每次batch,遍历了N次的im2col_gpu, caffe_gpu_gem。但是这种循环方法使得要多次读写Dm和读取D, 相对第一种方案需要更多memory traffic. 因此,本文采用了另一种实现:
对A x B = C, 分块加载A和B从off-chip memory to on-chip caches, 同时计算C的一部分。这样减少了数据传输带来的延迟。对于Dm,我们是在on-chip上转换成Dm,而不是在off-chip上转换.
三种方法性能的比较:

1. caffe的卷积
首先,caffe的卷积操作是将卷积转化为矩阵乘法,然后就可以用已有的GPU矩阵乘法的优化 算法 进行计算。具体可以参见 这篇博文 。
这个方法由于需要将输入D和卷积核F进行转化,将D从四维数组转化为二维矩阵时数据规模变大,因而会占用过多显存。而且卷积核越大,stride越小,显存耗费越高。
2. FFT 计算卷积
还有一种使用FFT计算卷积。此时需要将卷积核扩大成和feature map一样的长宽尺寸,这在二者相差较大的时候也是很浪费的。另外,当stride大于1时,数据比较稀疏,采用FFT效果也并不理想。
3. NVIDIA的矩阵乘法
NVIDIA对矩阵乘法支持每次单独计算子矩阵。一边计算子矩阵的结果,一边准备下一组数据,最后合并得到结果。有点流水线的意思。
4. cuDNN convolution
论文采用的是将卷积转化为矩阵乘法的方法,利用NVIDIA的矩阵乘法的特点,做了一些改进。具体来说就是,计算F(卷积核)对D(输入的feature map)的卷积,并不是将D转化后的二维矩阵直接存到显存里面,而是lazily materialing的方式。就是说,当需要用到这部分数据的时候,直接到D中索引对应的数据,并加载到显存里面进行计算,这样就避免了占用额外显存这一弊端。因此该方法还需要一个快速从D中索引数据的算法。
本部分介绍Caffe中卷积的实现。
1 简介
- 使用im2col分别将featrue maps 以及卷积核转换成矩阵
- 调用GEMM(GEneralized Matrix Multiplication)对两矩阵内积。
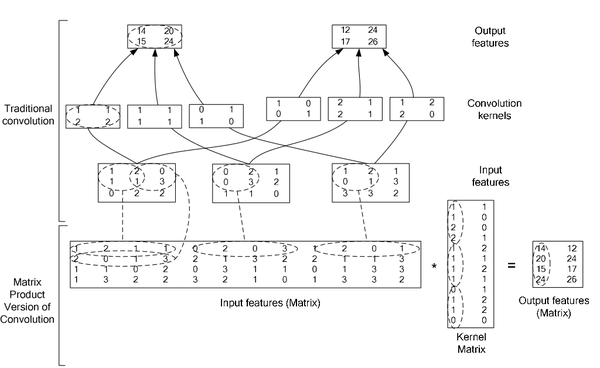
- 图来自引用论文[1]
2 详细介绍

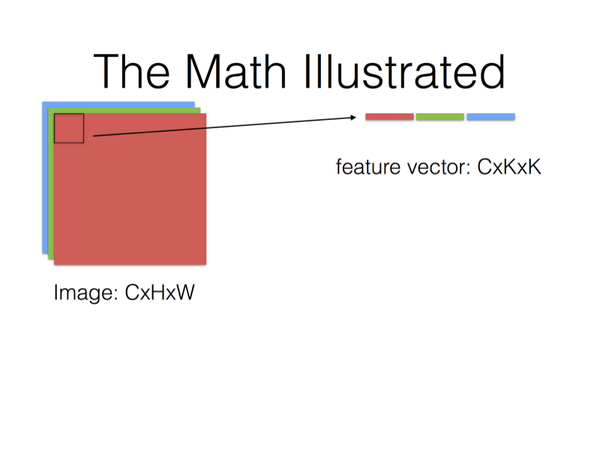
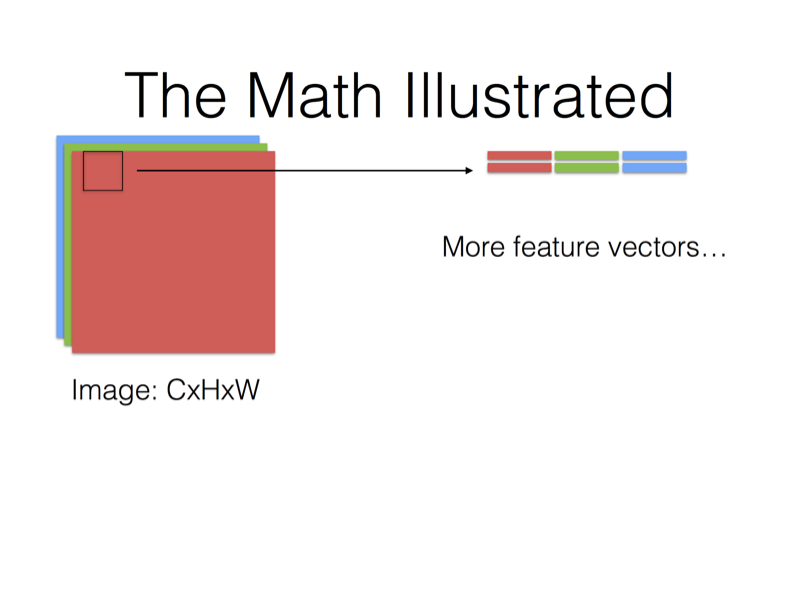
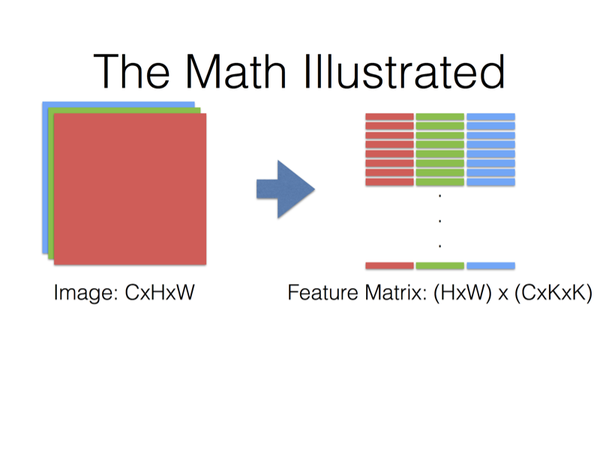
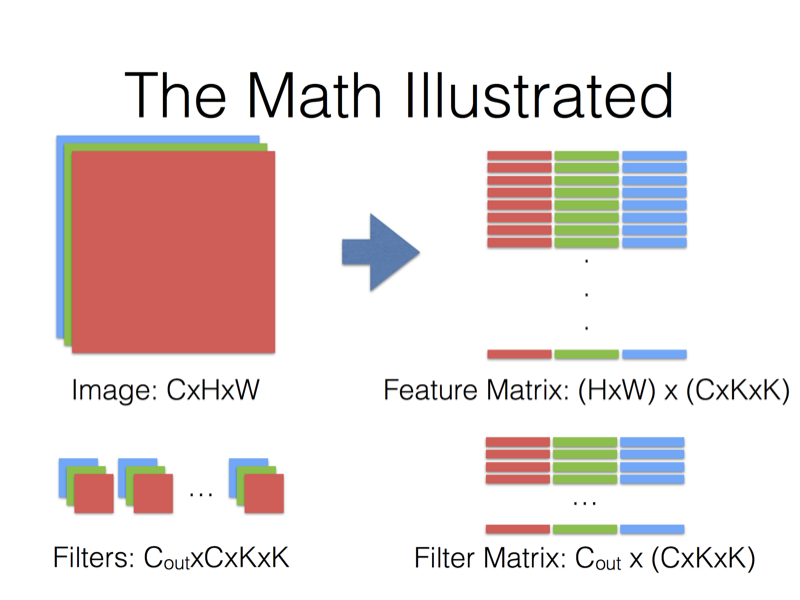
最后,Filter Matrix乘以Feature Matrix的转置,得到输出矩阵Cout x (H x W),就可以解释为输出的三维Blob(Cout x H x W)。
3 作者的说明
在引用[3]中,作者说明了为何这样做卷积。
大致是:优化CNN中的卷积不是一件简单的事。由于时间、成本上的种种原因,作者作用了这样一种temporary、lazy的方案。但是却发现这样一种方案取得的效果还比较好。
[1]. High Performance Convolutional Neural Networks for Document Processing
[2]. https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
[3]. https://www.zhihu.com/question/28385679















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









