






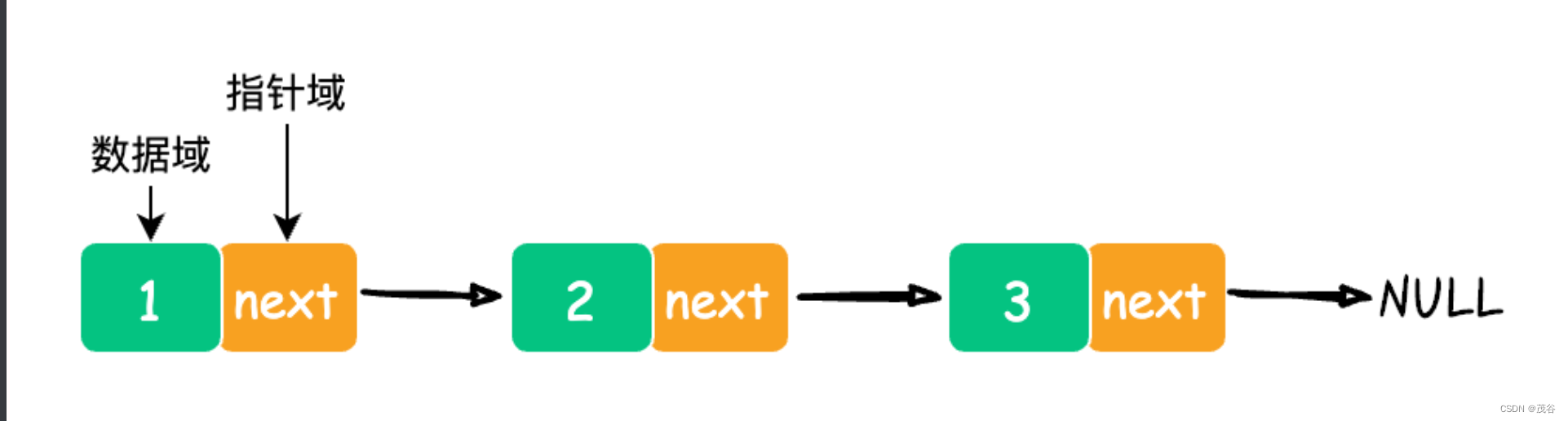
链表是一种常见的数据结构 是一种线性表 但是不会按线性的顺序存储数据 而是每一个节点在数据域中存储下一个节点的指针
优点
-
链表能灵活地分配内存空间 不连续分配空间灵活
-
能在 O(1) 时间内删除或者添加元素 动指针就好了
缺点
-
不像数组能通过下标迅速读取元素,每次都要从链表头开始一个一个读取 查找需要遍历一整条可能
-
查询第 k 个元素需要 O(k) 时间
基本操作
-
insertAtEnd:在链表结尾插入元素
-
insertAtHead:在链表开头插入元素
-
delete :删除链表的指定元素
-
deleteAtHead :删除链表第一个元素
-
search:在链表中查询指定元素
-
isEmpty:查询链表是否为空
应用场景
-
如果要解决的问题里面需要很多快速查询,链表可能并不适合 可以从中间开始查找
-
如果遇到的问题中,数据的元素个数不确定,而且需要经常进行数据的添加和删除,那么链表会比较合适
-
如果数据元素大小确定,删除和插入的操作并不多,那么数组可能更适合
链表实现数据结构 队列 排队先进先出 栈 放盘子先进后出
链表翻转算法
① 递归翻转
/**
* 链表递归翻转模板
*/
public Node reverseLinkedList(参数0) {
// Step1:终止条件
if (终止条件) {
return;
}
// Step2:逻辑处理:可能有,也可能没有,具体问题具体分析
// Step3:递归调用
Node reverse = reverseLinkedList(参数1);
// Step4:逻辑处理:可能有,也可能没有,具体问题具体分析
}
/**
* 链表递归翻转算法
*/
public Node reverseLinkedList(Node head) {
// Step1:终止条件
if (head == null || head.next == null) {
return head;
}
// Step2:保存当前节点的下一个结点
Node next = head.next;
// Step3:从当前节点的下一个结点开始递归调用
Node reverse = reverseLinkedList(next);
// Step4:head挂到next节点的后面就完成了链表的反转
next.next = head;
// 这里head相当于变成了尾结点,尾结点都是为空的,否则会构成环
head.next = null;
return reverse;
}② 三指针翻转
public static Node reverseLinkedList(Node head) {
// 单链表为空或只有一个节点,直接返回原单链表
if (head == null || head.getNext() == null) {
return head;
}
// 前一个节点指针
Node preNode = null;
// 当前节点指针
Node curNode = head;
// 下一个节点指针
Node nextNode = null;
while (curNode != null) {
// nextNode 指向下一个节点
nextNode = curNode.getNext();
// 将当前节点next域指向前一个节点
curNode.setNext(preNode);
// preNode 指针向后移动
preNode = curNode;
// curNode指针向后移动
curNode = nextNode;
}
return preNode;
}③ 利用栈翻转
public Node reverseLinkedList(Node node) {
Stack<Node> nodeStack = new Stack<>();
// 存入栈中,模拟递归开始的栈状态
while (node != null) {
nodeStack.push(node);
node = node.getNode();
}
// 特殊处理第一个栈顶元素:反转前的最后一个元素,因为它位于最后,不需要反转
Node head = null;
if ((!nodeStack.isEmpty())) {
head = nodeStack.pop();
}
// 排除以后就可以快乐的循环
while (!nodeStack.isEmpty()) {
Node tempNode = nodeStack.pop();
tempNode.getNode().setNode(tempNode);
tempNode.setNode(null);
}
return head;
}














 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









