






【学习笔记】非阻塞式Cache
前言
当存储访问请求未命中L1 cache,该请求将被转发到存储结构的更高层次。未命中的cache访问直至请求数据被返回时才能被完成。一个阻塞的cache在处理未命中情况时会将处理器拖住无法运行。尽管这种处理方式的实现复杂度低,但是cache缺失所造成的处理器暂停会严重降低性能。
另一种方法是在未命中的情况下继续执行指令,该方案需要具备以下两点:
a)要求处理器实现依赖跟踪机制(例如记分板)。允许与cache缺失的指令没有依赖关系的指令能够继续执行,同时阻塞依赖指令,等待cache访问缺失被处理完成。这种机制已经存在于乱序执行处理器中;
b)要求cache是非阻塞或免锁定的。
非阻塞式cache是一种允许处理器在cache未命中时也能发射新的 load/store 指令的 Cache。
一、非阻塞式Cache的结构
- 用 MSHR 寄存器存储 cache 的 miss 信息,有 n 个条目。
- 用 n 路比较器存储 cache 的hit 信息,这里的 n 与 MSHR 寄存器的条目相同。
- 用输入堆栈存储读取的读取的数据,此堆栈的大小等于以字为单位的块大小乘以 MSHR 寄存器的数量。
- MSHR 状态更新。
- 用控制单元增强1-4。
假设例子为组相联Cache,给出下图结构。
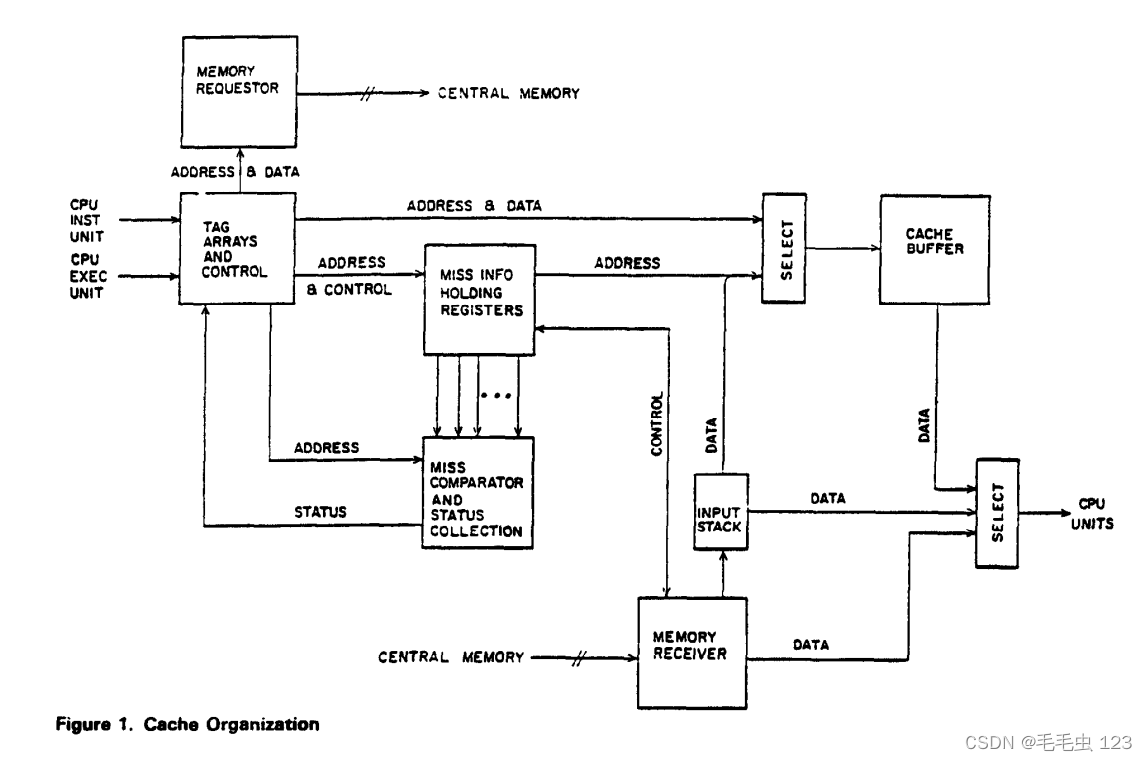
上图结构为组相联缓存(tag阵列和控制、缓存缓冲区)、中央内存接口块(内存请求器、内存接收器)和缓存增强块(未命中信息保持寄存器、未命中比较器和状态收集所需的块 ,输入堆栈)。 未命中信息保持寄存器保存所有必要信息,以 (1) 正确处理中央存储器接收到的数据,以及 (2) 通过未命中比较器和状态收集器通知主缓存控制所有命中和其他从存储器传输的数据状态 . 输入堆栈是必要的,以使主缓存缓冲区可用于重叠读取和写入。 请注意,这种组织允许刚从内存或输入堆栈中接收到的数据立即发送到请求的 CPU 单元
MSHR 寄存器的数量与组大小(即每个组中块的数目)相同,MSHR 寄存器的数量的增量值会随着寄存器数量的增加而迅速减小。因为成本随着寄存器数量的增加而显着增加。 平均延迟时间是由未完成的未命中锁定引起的。 当然,这个延迟时间也取决于缓存输入请求和命中率。 在退化的情况下,需要 1 个缩减大小的 MSHR 寄存器; 2 个 MSHR 寄存器允许在一个未命中未完成时重叠,但仍会在多个未命中未完成时锁定高速缓存输入。
二、MSHR的作用
可以用来跟踪和记录缺失的 cache 块的信息,一般包括:
- 缺失的 cache 块在内存的物理地址。
- 缺失块按特定的替换算法应该被存放到 cache 的什么地方。
- 所有访问这个 cache 块缺失的指令码。
- 同时使用该寄存器可以查看是否发生了二次缺失的情况, 即当前正在处理的缺失块是否有指令需要再次访问该 cache 块,如果发生则认为该 cache 块发生了二次缺失。
注:因此在指令访问 cache 发生缺失, 首先采用全相联的方式查找所有的 MSHR 入口,如果发现有匹配的 MSHR 入 口 ,则说明发生了二次缺 失,就不会给这个缺失的请求分配新的MSHR 入口,而是仅仅给它在 load miss queue 和 store miss queue 中分配一个入口。这样就达到了将多个缺失合并为一个缺失的目的, 而且这种做法对于提高 cache 的命中率和减少总线接口单元的带宽压力也有好处。 - 当所有的 MSHR 寄存器被使用完,cache 就会阻塞处理器。 随着 MSHR 寄存器的入口数目的增加,cache 的设计复杂度急速增加。
三、Implicitly Addressed MSHRs
该操作可以分为两个基本部分:内存接收器/输入堆栈操作和标签数组控制操作。
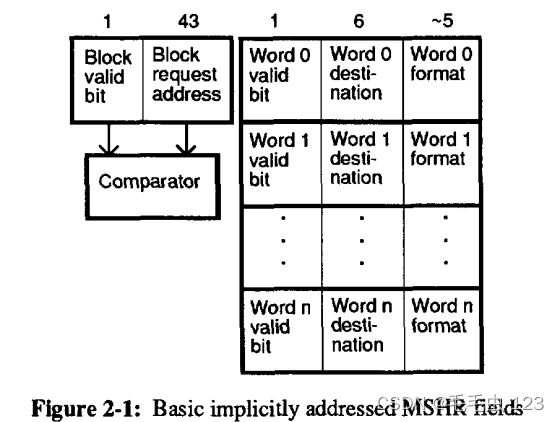
在未命中时,缓存请求一个字块。与每个字一起发送一个缓存标签。该标签指向特定分配的 MSHR 并指示块的字。请注意,缓存将请求单元的标识标签保存在 MSHR 中。此标记关闭了用于处理从内存返回的数据的剩余打开链接,并消除了对响应顺序的所有内存限制。
上图显示了与 Kroft 类似的典型基本 MSHR 的组织结构。 (每个字段的典型位宽列在每个字段的上方。)每个 MSHR 都包含一个有效位来表示它正在使用中。
具体操作
- 当Primary miss发生时,将设置空闲 MSHR 的有效位和块请求地址。 (如果没有空闲的 MSHR,处理器就会停止。)假设一个 64 位虚拟地址架构机器具有 48 位物理地址和 32 字节行大小意味着在 32 字节缓存块大小内需要 5 位来寻址,而只有 43 位需要存储为块请求地址。
- 每个 MSHR 都有自己的比较器,因此当发生新的未命中时,可以关联地搜索 MSHR 的组,以确定新的未命中是Primary、Structural-stall还是Secondary miss。对于块中的每个字(例如,32 字节高速缓存块中的四个 8 字节字),都存在一个目标地址、格式化信息和一个字有效位。
- 当特定字发生加载未命中时设置这些字段,以便当块从存储器层次结构中的下一个较低级别返回时,可以完成加载指令的操作。目标地址通常是一个完整的寄存器地址,包括一个指定它是定点寄存器还是浮点寄存器的位。格式信息给出了加载操作码提供的其他信息,可能还有完成加载指令所需的地址的低位。这些示例是加载的宽度(例如,1、2、4 或 8 个字节)、字节加载的字节地址位以及表示是否对返回的数据进行符号扩展的位。特定的指令集架构需要额外的信息。
例如,MIPS R4000 架构具有 load-wordleft 和 load-word-right 指令以支持未对齐的访问。指定这些加载操作码的信息也需要保存在 MSHR 中,以便在将数据放入寄存器时可以对数据进行适当的移位和屏蔽。
四、Explicitly AddressedMSHRs
1.Implicitly Addressed MSHRs的缺陷
尽管图 2-1 的基本 MSHR 相当大(上例中的 (4x12)+44=92 位,加上一个 44 位比较器和重要的控制逻辑),但它有两个限制:
- 对同一个字的多次访问而对它们的块的取指未完成将导致停顿,即不允许在具有字节加载和存储的机器中对同一个 32 位字进行多字节加载。
例如:即使在具有 64 位虚拟地址架构的机器中,也可能在未来许多年中加载和存储相当数量的 32 位数据。因此,与其在字区域中提供 64 位字粒度,不如通过将其粒度降低到 32 位,字记录的数量可能需要加倍。这种加倍会将我们示例的字部分中的位数增加到 8x12=96 位,使每个 MSHR 总共有 140 位宽。但是,这种增加仍然不允许在具有字节加载和存储的机器中对同一个 32 位字进行多字节加载。 - 多次加载到完全相同的地址也会导致停顿。因此,对于这种类型的 MSHR 结构,编译器将字节操作组合到字访问中并使用寄存器移动而不是从同一地址加载两次。
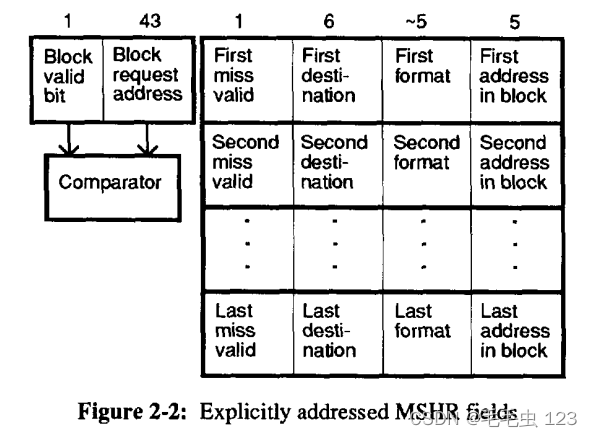
2.Explicitly AddressedMSHRs
图 2-1 中 MSHR 的字字段是按位置寻址的(即,它们的位置指定了它们在块内的字地址)。 另一个更复杂的 MSHR 如图 2-2 所示。 这个 MSHR 有许多通用字字段,它们明确地给出了它们的字地址。 具有 4 组字字段的明确寻址的 MSHR 可以处理四个未命中的完全相同的地址而不会停顿,或者一个字内的四个字节的四个未命中。 然而,即使需要位来在块内显式存储地址,一个可以容纳 4 次未命中的显式寻址 MSHR 也只有 (4~17)+44=112 位宽。 对于 32 字节行和 4 字节粒度,该 MSHR 小于隐式寻址的 MSHR。 当同一块只有有限数量的未命中并且这些引用重叠或指向相邻字节或半字时,显式寻址的 MSHR 效果最佳。
五、In-Cache MSHR Storage
实施大量 MSHR,每个都支持许多未命中可能需要大量存储。 Franklin 和 Sohi观察到等待在未完成被填充的缓存行可用于存储 MSHR 信息。这可以通过向每个高速缓存行添加一个transit bit来完成。该位表示该行正在被取指,缓存标记中的地址指定了正在取指的地址,并且缓存行中的数据本身给出了MSHR信息。使用这种技术,无论是隐式还是显式地处理 MSHR 字段,都可以支持许多 secondary misses。
但是,在直接映射缓存中,每个缓存组只能支持一次正在运行的 primary miss。使用此方法要记住的一件事是,应将MSHR信息的长度限制为可以在单个循环中读取的宽度。此外,即使每个高速缓存行仅添加一位,对于非常大的高速缓存,这可能需要比更简单的不同 MSHR 组需要更多的区域。
参考
- David Kroft. Lockup-Free Instruction Fetch or Prefetch Cache Organization.
- 孟锐. 处理器中非阻塞 cache 技术的研究.
- Keith I. Farh and Norman P. Jouppi. Complexity or Performance Tradeoffs with Non-Blocking Load.















 1921
1921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









