







 该博客介绍了基于协同过滤算法的智能推荐系统在校园兼职招聘平台的实现。主要探讨了基于用户的协同过滤和基于物品的协同过滤算法,重点讲述了基于物品的协同过滤算法的实施,包括计算物品相似度和推荐度的详细步骤。系统设计分为学生用户端、企业用户端、系统管理员端和智能推荐模块四大功能。
该博客介绍了基于协同过滤算法的智能推荐系统在校园兼职招聘平台的实现。主要探讨了基于用户的协同过滤和基于物品的协同过滤算法,重点讲述了基于物品的协同过滤算法的实施,包括计算物品相似度和推荐度的详细步骤。系统设计分为学生用户端、企业用户端、系统管理员端和智能推荐模块四大功能。
3协同过滤算法简介
目前,推荐算法有很多种,可以应用于日常生活的许多领域,对大量数据进行处理和分析,然后进行分类。它将显示用户可能感兴趣的内容,这是推荐算法的主要功能之一[1]。
协同过滤算法通常包括两类:一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法[2]。
3.1.1基于用户的协同过滤算法
根据用户的协同过滤算法的主要实现方式是,根据获取使用者的历史的一些活动统计(如使用者对职位的收集),并由此分析出使用者对某个工作类别的偏好,再根据判断用户偏好的重要程度,甚至是对某个工作类型的评价,把这种统计加以数字化,从而形成了使用者喜好的二维矩阵,同样的方法也可以用于其他应用,因此可以方便地使用找到相同的用户组,然后通过统计相似率计算用户之间的相似度,从而筛选出最相似的用户,类似用户首选且用户未收集的职位也推荐给用户[3]。然而⽤户有新⾏为,不⼀定会导致推荐结果的实时变化.
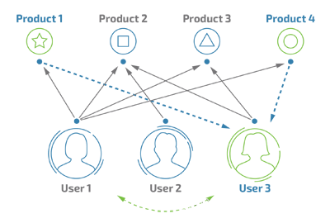
图3-1 基于用户的协同过滤原理
3.1.2基于物品的协同过滤算法
一个商品的协同过滤算法(ItemCF)是目前在业内运用得最为普遍的方法之一,在亚马逊、Netflix、以及YouTube的推荐方法的基本上都是采用ItemCF。它可以向客户介绍一个与他之前所感兴趣的东西类似的商品。比如:该方法会因你选择了《数据挖掘导论》而给你选择《机器学习》[4]。但是,ItemCF方法并不使用物体的内容属性统计物体内部的相似度,而主要是根据研究客户的行动记录统计物体内部的相似度。该方法还指出,商品A与商品B相互之间存在着较大相似度的原因,在于喜爱商品A的客户大都也喜爱商品B。
3.2 基于用户收藏的协同过滤算法实现
因为该课题是为了实现具有个性化推荐功能的校园兼职招聘平台,也因为利⽤用该⽤户的历史经验⾏为给⽤户提供了有理有据的推荐解释,如此才能够使⽤户⽐比较信服,所以本系统使用了基于物品的协同过滤算法,⽤户有新⾏为,它将导致用户的推荐结果发生实时变化[5]。基于物品的协同过滤算法的基础过程包括:
- 计算物品之间的相似度
基于余弦(Cosine-based)的计算方法,利用求二矢量间的角度余弦值来表达事物间的相似之处,方法为:其中分子是二矢量的内积,即二矢量相同距离的数字相乘。
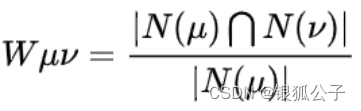
公式 3-1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









