






使用到的项目
https://github.com/xikong1995/node-crawler
因为项目使用的是nodejs,所以要先安装
nodejs和npm安装
进入官网查看最新版本
https://nodejs.org/en/
添加源
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash - //数字的地方换成官网上的最新版本
安装
sudo apt-get install -y nodejs
nodejs 和 npm 就安装好了,可以使用 node -v和 npm -v查看
妹子图爬取
克隆爬虫
git clone https://github.com/xikong1995/node-crawler.git //没安装git 可以先使用 apt install git 安装
进入爬虫
cd node-crawler
修改配置文件
微博
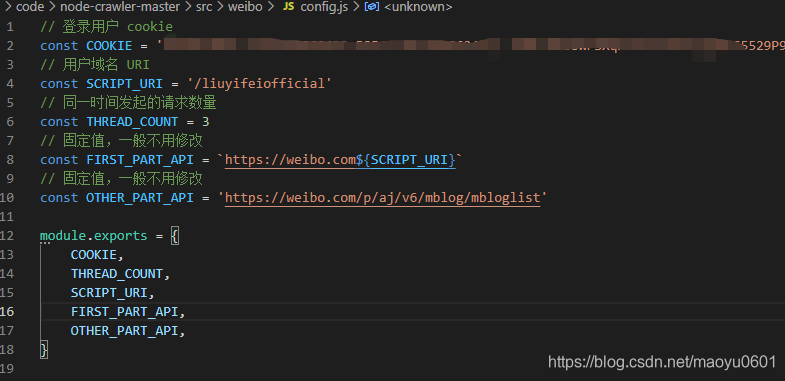
vim src/weibo/config.js //打开配置文件
const COOKIE = '这里填写获取到的cookie' //登录微博网页版,然后按 f12 打开调试面板,进入 Network ,刷新下网页,找个链接点开即可看到 cookie
const SCRIPT_URI = '/u/5141494199' 点开你要爬取数据的用户的主页,然后查看浏览器地址栏的域名
或
const SCRIPT_URI = '/liuyifeiofficial'
vim src/instagram/config.js //打开配置文件
const COOKIE = '这里填写获取到的cookie' //登录instagram网页版然后按照上面微博的方式获取获取
const PROXY = '这里填写代理地址' //咱们如果是在国内服务器运行爬虫的话,爬取instagram需要添加代理才行
const USERNAME = 'riku_riku_99' //这里填写用户名

安装项目依赖
npm i //如果太慢可以使用国内源安装,比如淘宝源 npm i --registry https://registry.npm.taobao.org
开始爬取
npm run dev weibo //爬取微博
npm run dev instagram //爬取instagram
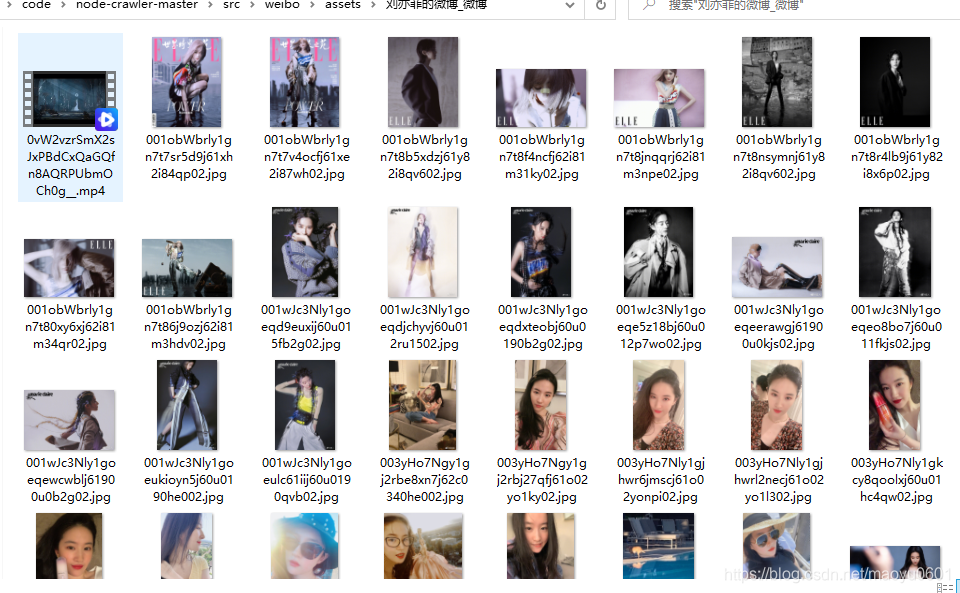
会在项目src目录下生成对应文件夹 src/weibo/assets/和 src/instagram/assets/
成品

















 5223
5223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









