






该博文为2015年发布,已经有些过时,但是了解的话,能更好的理解spark以及发展的趋势。
Spark SQL是Spark最新,技术最复杂的组件之一。它为SQL查询和新的DataFrame API提供支持。Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言功能(例如Scala的模式匹配和quasiquotes)来构建可扩展的查询优化器。
我们最近发表了一篇关于Spark SQL 的论文,该论文将出现在SIGMOD 2015中(与Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan,Michael J. Franklin和Ali Ghodsi共同撰写)。在这篇博文中,我们将重新发布论文中的一个部分,该部分解释了Catalyst优化器的内部结构,以便更广泛地使用。
为了实现Spark SQL,我们基于Scala中的函数编程构造设计了一个新的可扩展优化器Catalyst。Catalyst的可扩展设计有两个目的。首先,我们希望能够轻松地为Spark SQL添加新的优化技术和功能,特别是为了解决我们在大数据(例如,半结构化数据和高级分析)中遇到的各种问题。其次,我们希望允许外部开发人员扩展优化器 - 例如,通过添加可以将过滤或聚合推送到外部存储系统的数据源特定规则,或支持新数据类型。Catalyst支持基于规则和基于成本的优化。
Catalyst的核心是一个通用库,用于表示树和应用规则来操纵它们。在此框架之上,我们构建了特定于关系查询处理的库(例如,表达式,逻辑查询计划),以及处理查询执行的不同阶段的几组规则:分析,逻辑优化,物理规划和代码生成将部分查询编译为Java字节码。对于后者,我们使用另一个Scala特性quasiquotes,这使得在运行时从可组合表达式生成代码变得容易。最后,Catalyst提供了几个公共扩展点,包括外部数据源和用户定义类型。
树
Catalyst中的主要数据类型是由节点对象组成的树。每个节点都有一个节点类型和零个或多个子节点。新节点类型在Scala中定义为TreeNode类的子类。这些对象是不可变的,可以使用功能转换进行操作,如下一小节中所述。
举个简单的例子,假设我们有一个非常简单的表达式语言的以下三个节点类:
Literal(value: Int):一个恒定的价值Attribute(name: String):来自输入行的属性,例如“x”Add(left: TreeNode, right: TreeNode):两个表达式的总和。
这些类可用于构建树; 例如,表达式的树 x+(1+2)将在Scala代码中表示如下:
Add(Attribute(x), Add(Literal(1), Literal(2)))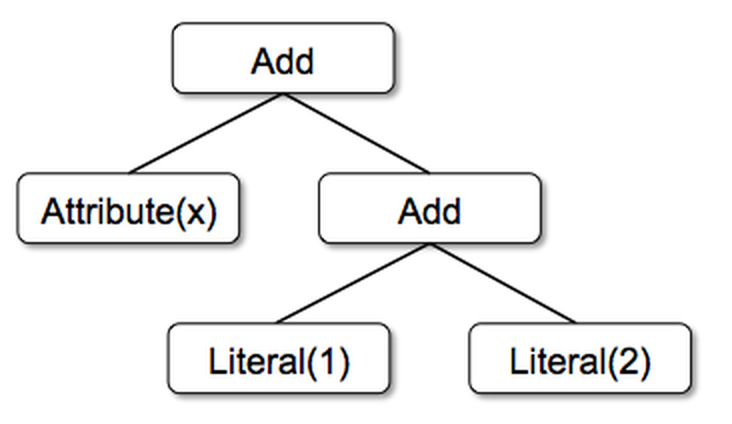
规则
树可以使用规则来操纵,规则是从树到另一棵树的功能。虽然规则可以在其输入树上运行任意代码(假设此树只是Scala对象),但最常用的方法是使用一组模式匹配函数来查找和替换具有特定结构的子树。
模式匹配是许多函数语言的一个特性,它允许从代数数据类型的潜在嵌套结构中提取值。在Catalyst中,树提供了一种转换方法,该方法在树的所有节点上递归地应用模式匹配函数,将匹配每个模式的模式转换为结果。例如,我们可以实现一个在常量之间折叠Add操作的规则,如下所示:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}将其应用于树x+(1+2)将产生新树x+3。case这里的关键字是Scala的标准模式匹配语法,可用于匹配对象的类型,也可以为提取的值(c1以及c2此处)指定名称。
传递给transform的模式匹配表达式是一个部分函数,这意味着它只需要匹配所有可能的输入树的子集。Catalyst将测试给定规则适用的树的哪些部分,自动跳过并降级到不匹配的子树。这种能力意味着规则只需要推理给定优化适用的树而不是那些不匹配的树。因此,随着新类型的运算符被添加到系统中,不需要修改规则。
规则(以及一般的Scala模式匹配)可以匹配同一转换调用中的多个模式,使得一次实现多个转换非常简洁:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}实际上,规则可能需要多次执行才能完全转换树。Catalyst将规则分组为批处理,并执行每个批处理直到达到固定点,即,在应用其规则后树停止更改。将规则运行到固定点意味着每个规则可以是简单且自包含的,但最终仍然会对树具有更大的全局效果。在上面的例子中,重复的应用程序会不断折叠较大的树,例如(x+0)+(3+3)。作为另一个示例,第一批可以分析表达式以将类型分配给所有属性,而第二批可以使用这些类型来进行常量折叠。在每个批处理之后,开发人员还可以对新树进行健全性检查(例如,查看所有属性都已分配类型),通常也通过递归匹配编写。
最后,规则条件及其实体可以包含任意Scala代码。这为Catalyst提供了比优化器领域特定语言更强大的功能,同时保持简洁规则的简洁性。
根据我们的经验,对不可变树进行的功能转换使得整个优化器非常容易推理和调试。它们还在优化器中启用了并行化,尽管我们还没有利用它。
在Spark SQL中使用Catalyst
我们分四个阶段使用Catalyst的通用树转换框架,如下所示:(1)分析解析引用的逻辑计划,(2)逻辑计划优化,(3)物理规划,以及(4)编译部分的代码生成查询Java字节码。在物理规划阶段,Catalyst可以生成多个计划并根据成本进行比较。所有其他阶段纯粹基于规则。每个阶段使用不同类型的树节点; Catalyst包括表达式,数据类型以及逻辑和物理运算符的节点库。我们现在描述这些阶段中的每一个。
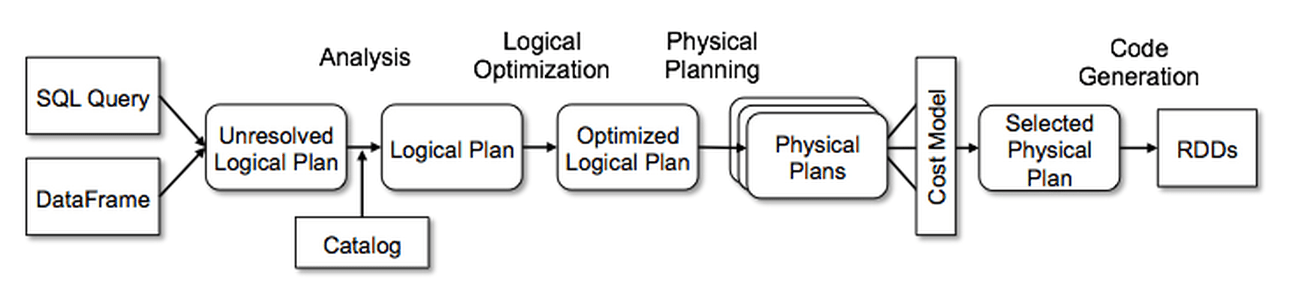
分析
Spark SQL以要计算的关系开始,要么是从SQL解析器返回的抽象语法树(AST),要么是使用API构造的DataFrame对象。在这两种情况下,关系可能包含未解析的属性引用或关系:例如,在SQL查询中SELECT col FROM sales,col的类型,甚至是否是有效的列名称,在我们查找表sales之前都不知道。如果我们不知道其类型或未将其与输入表(或别名)匹配,则称该属性为未解析。Spark SQL使用Catalyst规则和跟踪所有数据源中的表的Catalog对象来解析这些属性。它首先构建一个包含未绑定属性和数据类型的“未解析的逻辑计划”树,然后应用执行以下操作的规则:
- 从目录中按名称查找关系。
- 将命名属性(例如col)映射到为给定运算符的子项提供的输入。
- 确定哪些属性引用相同的值以为它们提供唯一ID(稍后允许优化表达式等
col = col)。 - 通过表达式传播和强制类型:例如,
1 + col在我们解析col并且可能将其子表达式转换为兼容类型之前,我们无法知道返回类型。
总的来说,分析器的规则大约是1000行代码。
逻辑优化
逻辑优化阶段将基于规则的标准优化应用于逻辑计划。(基于成本的优化是通过使用规则生成多个计划,然后计算它们的成本来执行的。)这些包括常量折叠,谓词下推,投影修剪,空传播,布尔表达式简化和其他规则。总的来说,我们发现为各种情况添加规则非常简单。例如,当我们将固定精度DECIMAL类型添加到Spark SQL时,我们希望优化聚合,例如DECIMAL上的总和和平均值,精度较小; 我需要12行代码来编写一个在SUM和AVG表达式中找到这种小数的规则,并将它们转换为未缩放的64位LONG,对其进行聚合,然后将结果转换回来。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec, scale))
if prec + 10 <= MAX_LONG_DIGITS =>
MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) }
}另一个例子是,12行规则使用简单的正则表达式将LIKE表达式优化为String.startsWith或String.contains调用。在规则中使用任意Scala代码的自由进行了这些优化,这些优化超出了对子树结构的模式匹配,易于表达。
总的来说,逻辑优化规则是800行代码。
物理规划
在物理规划阶段,Spark SQL采用逻辑计划并使用与Spark执行引擎匹配的物理运算符生成一个或多个物理计划。然后,它使用成本模型选择计划。目前,基于成本的优化仅用于选择连接算法:对于已知较小的关系,Spark SQL使用广播连接,使用Spark中提供的对等广播设施。然而,该框架支持更广泛地使用基于成本的优化,因为可以使用规则递归地估计整棵树的成本。因此,我们打算在未来实施更丰富的基于成本的优化。
物理规划器还执行基于规则的物理优化,例如将投影或过滤器流水线化为一个Spark映射操作。此外,它可以将操作从逻辑计划推送到支持谓词或投影下推的数据源。我们将在后面的部分中介绍这些数据源的API。
总的来说,物理规划规则大约是500行代码。
代码生成
查询优化的最后阶段涉及生成在每台机器上运行的Java字节码。由于Spark SQL通常在内存数据集上运行,其中处理受CPU限制,因此我们希望支持代码生成以加快执行速度。尽管如此,代码生成引擎通常很难构建,基本上相当于编译器。Catalyst依赖于Scala语言的一个特殊功能,即quasiquotes,使代码生成更简单。Quasiquotes允许在Scala语言中编程构造抽象语法树(AST),然后可以在运行时将其提供给Scala编译器以生成字节码。我们使用Catalyst将表示SQL中表达式的树转换为AST,以便Scala代码评估该表达式,然后编译并运行生成的代码。
作为一个简单的例子,考虑4.2节中介绍的Add,Attribute和Literal树节点,它允许我们编写表达式,如(x+y)+1。在没有代码生成的情况下,通过沿着Add,Attribute和Literal节点的树向下走,必须为每行数据解释这样的表达式。这会引入大量分支和虚函数调用,从而减慢执行速度。通过代码生成,我们可以编写一个函数将特定的表达式树转换为Scala AST,如下所示:
def compile(node: Node): AST = node match {
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) => q"${compile(left)} + ${compile(right)}"
}开头的字符串q是quasiquotes,这意味着虽然它们看起来像字符串,但它们在编译时由Scala编译器解析,并代表其中的代码的AST。Quasiquotes可以将变量或其他AST拼接到其中,使用$符号表示。例如,Literal(1)将成为scala AST为1,而Attribute("x")成为row.get("x")。最后,像树一样的树Add(Literal(1), Attribute("x"))成为Scala表达式的AST 1+row.get("x")。
Quasiquotes在编译时进行类型检查,以确保只替换适当的AST或文字,使它们比字符串连接更有用,并且它们直接导致Scala AST,而不是在运行时运行Scala解析器。而且,它们是高度可组合的,因为每个节点的代码生成规则不需要知道如何构造其子节点返回的树。最后,如果存在Catalyst错过的表达式级优化,则Scala编译器会进一步优化生成的代码。下图显示quasiquotes让我们生成的代码具有与手动调优程序类似的性能。
我们发现quasiquotes非常直接用于代码生成,我们观察到即使是Spark SQL的新贡献者也可以快速为新类型的表达式添加规则。Quasiquotes也适用于我们在本机Java对象上运行的目标:当从这些对象访问字段时,我们可以代码生成对所需字段的直接访问,而不必将对象复制到Spark SQL行并使用Row的存取方法。最后,将代码生成的评估与我们尚未生成代码的表达式的解释评估相结合是很简单的,因为我们编译的Scala代码可以直接调用我们的表达式解释器。
总的来说,Catalyst的代码生成器大约有700行代码。
这篇博客文章介绍了Spark SQL的Catalyst优化器的内部结构。它新颖,简单的设计使Spark社区能够快速构建,实现和扩展引擎。您可以在此处阅读本文的其余部分。如果您今年参加SIGMOD,请参加我们的会议!
您还可以从以下位置找到有关Spark SQL的更多信息:
- Apache Spark的Spark SQL和DataFrame编程指南
- Yin Huai 在Spark演示中的数据源API
- Reynold Xin 在Spark中为大规模数据科学引入DataFrame
- 超越SQL:使用 Michael Armbrust的DataFrame加速Spark















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









