







 本文介绍了使用Hadoop MapReduce进行数据清洗和汽车销售数据分析的多个实例,包括车辆用途分布、山西省2013年汽车销售比例、各市、区县销售数量、男女购车比例、所有权、车辆类型和品牌分布、品牌每月销售量以及发动机型号和燃油种类统计。通过这些实例展示了MapReduce在大数据处理中的应用。
本文介绍了使用Hadoop MapReduce进行数据清洗和汽车销售数据分析的多个实例,包括车辆用途分布、山西省2013年汽车销售比例、各市、区县销售数量、男女购车比例、所有权、车辆类型和品牌分布、品牌每月销售量以及发动机型号和燃油种类统计。通过这些实例展示了MapReduce在大数据处理中的应用。
首先还是看下我们的需求  然后拿到我们的数据
然后拿到我们的数据 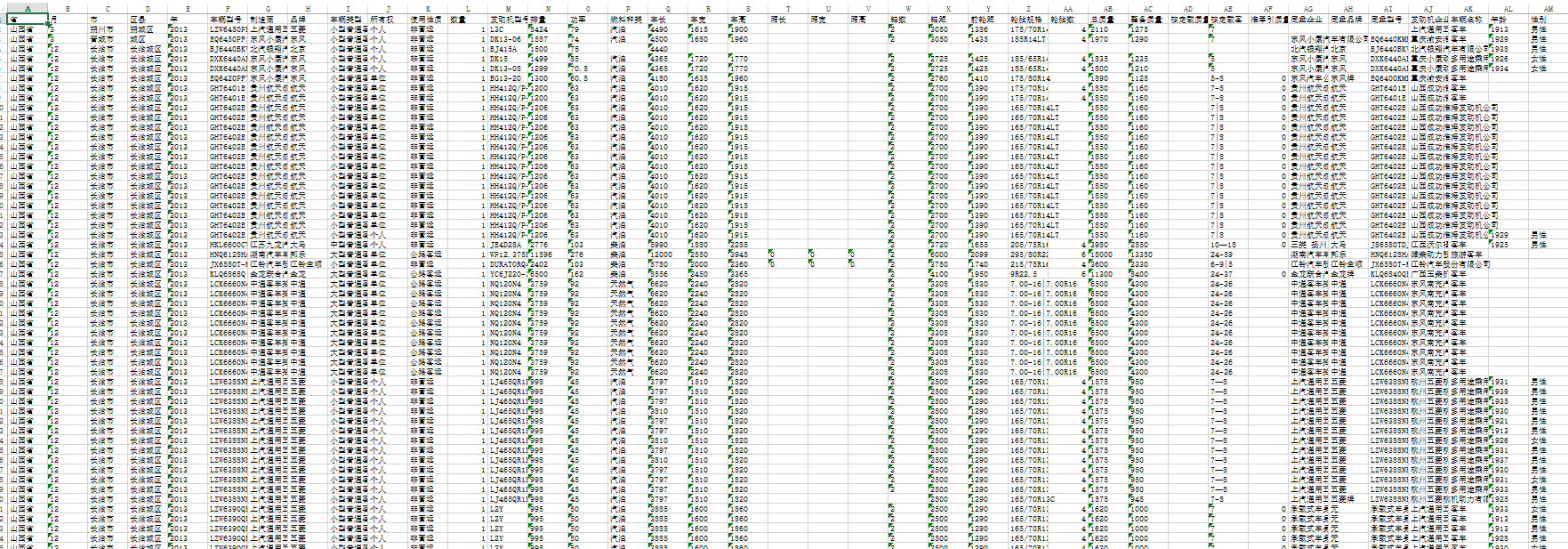 可以看到我们的数据里面还有很多空值,是还没清洗的脏数据,一会我们处理的时候需要将其处理掉.
可以看到我们的数据里面还有很多空值,是还没清洗的脏数据,一会我们处理的时候需要将其处理掉.
一.统计车辆不同用途的数量分布
package hadoop.MapReduce.car.Use;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class usecount {
public static class UseMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 10 && !lines[10].isEmpty()) {
context.write(new Text(lines[10]), new IntWritable(1));
}
}
}
public static class UseReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws
IOException, InterruptedException {
int count = 0;
for (IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
public static class UseDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(UseDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(UseMapper.class);
job.setReducerClass(UseReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a1\\1"));
job.waitForCompletion(true);
}
}
}
可以看到我们这边用lines[10].isEmpty()去清洗了空格,若不想用这种方法还可以用try/catch将其抛出异常, 一开始我们用的line[10] != null,后来发现不行,还是会将空格输出出来.
二.统计山西省2013年每个月的汽车销售数量的比例
package hadoop.MapReduce.car.BiLi;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class bilicount {
// static int all = 0;
public static class BiliMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 1&& !lines[0].isEmpty()) {
if (lines[0].equals("山西省") && lines[4].equals("2013")) {
context.write(new Text(lines[1]), new LongWritable(1));
// all++;
}
}
}
}
public static class BiliReduce extends Reducer<Text,LongWritable,Text, DoubleWritable> {
double all = 0;
Map<String,Long> maps = new HashMap<String,Long>();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws
IOException, InterruptedException {
long count = (long)0;
for (LongWritable value : values) {
count += value.get();
}
all += count;
maps.put(key.toString(),count);
// bili = count/all;
// context.write(key,new DoubleWritable(bili));
}
protected void cleanup(
org.apache.hadoop.mapreduce.Reducer<Text,LongWritable,Text, DoubleWritable>.Context context
) throws IOException, InterruptedException {
Set<String> keySet = maps.keySet();
for (String str : keySet) {
long value = maps.get(str);
double bili = value/all;
context.write(new Text(str),new DoubleWritable(bili));
}
}
}
public static class BiliDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(BiliDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
job.setMapperClass(BiliMapper.class);
job.setReducerClass(BiliReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a2\\1"));
job.waitForCompletion(true);
}
}
}
可以看到统计总数,我们这边用了cleanup来释放,其实在map端加入一个静态全局变量来计算也是一个好办法,比起这个更加简单.
三.统计山西省2013年各市、区县的汽车销售的数量分布
package hadoop.MapReduce.car.FenBu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class fenbu {
public static class FenbuMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 4 && lines[2] != null && lines[3] != null) {
if (lines[0].equals("山西省") && lines[4].equals("2013")) {
context.write(new Text(lines[2]+"\t"+lines[3]),new IntWritable(1));
}
}
}
}
public static class FenbuReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
public static class FenbuDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FenbuDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(FenbuMapper.class);
job.setReducerClass(FenbuReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a3"));
job.waitForCompletion(true);
}
}
}
可以看到这里用的lines[3] != null做得判断,这里还会输出空格,记得改为 !lines[3].isEmpty()
四.统计买车的男女比例
package hadoop.MapReduce.car.ManAndWoman;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class manwoman {
// static double people = 0;
public static class MWMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 38 && !lines[38].isEmpty()) {
context.write(new Text(lines[38]),new IntWritable(1));
// people++;
}
}
}
public static class MWReduce extends Reducer<Text,IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// double bili;
int count = 0;
for (IntWritable value:values){
count += value.get();
}
// bili = count/people;
context.write(key,new IntWritable(count));
}
}
public static class MWDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(MWDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MWMapper.class);
job.setReducerClass(MWReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a4\\3"));
job.waitForCompletion(true);
}
}
}
这边我是求的人数,题目求的比例,只要把注释的解开就行
五.统计车的所有权、车辆类型和品牌的数量分布
package hadoop.MapReduce.car.SuoYou;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class All {
public static class AMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 9 && lines[9] != null) {
context.write(new Text(lines[9]),new IntWritable(1));
}
}
}
public static class AReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
public static class ADriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(ADriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(AMapper.class);
job.setReducerClass(AReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a5\\4"));
job.waitForCompletion(true);
}
}
}
六.统计不同品牌的车在每个月的销售量分布
package hadoop.MapReduce.car.PinPai;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PP {
public static class PPMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 7 && lines[1] != null && lines[7] != null) {
context.write(new Text(lines[1]+"\t"+lines[7]),new IntWritable(1));
}
}
}
public static class PPReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
public static class PPDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(PPDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(PPMapper.class);
job.setReducerClass(PPReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a6"));
job.waitForCompletion(true);
}
}
}
七.通过不同种类(品牌)车辆销售情况,来统计发动机 型号和燃油种类
package hadoop.MapReduce.car.FaDong;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FA {
public static class FAMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
if (null != lines && lines.length > 15 && !lines[8].isEmpty() && !lines[12].isEmpty() && !lines[15].isEmpty()) {
context.write(new Text(lines[8] + "\t" + lines[12] + "\t" + lines[15]), new IntWritable(1));
}
}
}
public static class FAReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
public static class FADriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(FADriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(FAMapper.class);
job.setReducerClass(FAReduce.class);
FileInputFormat.addInputPath(job,new Path("D:\\a\\cars.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a\\a8"));
job.waitForCompletion(true);
}
}
}

















 6823
6823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









