







Linux 高并发服务器实战 - 5 项目实战
1. 阻塞/非阻塞、同步/异步(网络IO)
典型的一次IO的两个阶段是什么?数据就绪 和 数据读写
网络IO阶段1(在操作系统、TCP接收缓冲区)
数据就绪:根据系统IO操作的就绪状态
- 阻塞 (调用IO方法 线程进入阻塞状态)
- 非阻塞(不会改变线程的状态)
*ssize_t recv(int sockfd, void buf, size_t len, int flags);
int size = recv(sockf, buf, 1024, 0);
阻塞/非阻塞由文件描述符的属性决定,当设置为非阻塞时,注意观察返回值
size == -1 出错了 (除 EINTR, EAGAIN, EWOULDBLOCK之外)
size == 0 读取到数据的末尾,对方连接关闭了
size > 0 读取到了多少的数据
网络IO阶段2(应用程序)
数据读写:根据应用程序和内核的交互方式
-
同步
应用程序自己去读的(不是操作系统直接给你的),把TCP接收缓冲区里的数据装到buf里(从内核搬到buf里)
(花的是自己的时间)
char buf[1024] = {0}; int size = recv(sockfd, buf, 1024, 0); if(size > 0){buf ...} -
异步(一般和非阻塞配合使用)
(sockfd, buf, 通知方式)把这些都给操作系统,你就可以去干自己的事情了。当内核中(TCP接收缓冲区)有数据到达以后,它会帮你把数据放到buf当中, 给发sigio信号
陈硕:在处理 IO 的时候,阻塞和非阻塞都是同步 IO,只有使用了特殊的 API 才是异步 IO。
linux中的异步IO接口:aio_read()、aio_write()
就绪是就绪,读写是读写 他们两个不冲突啊,一前一后,得先就绪了(阻塞/不阻塞),然后我们的应用程序才去同步/异步读取。这说的是两个不同的状态!当然读取的时候肯定是在不阻塞的情况下读的

注意咯,IO多路复用是同步!因为数据到达了之后我们仍然用的是同步接口的read,我们没有用到特殊的异步API
同步阻塞
同步非阻塞
异步阻塞
异步非阻塞
2. Unix/Linux上的五种IO模型
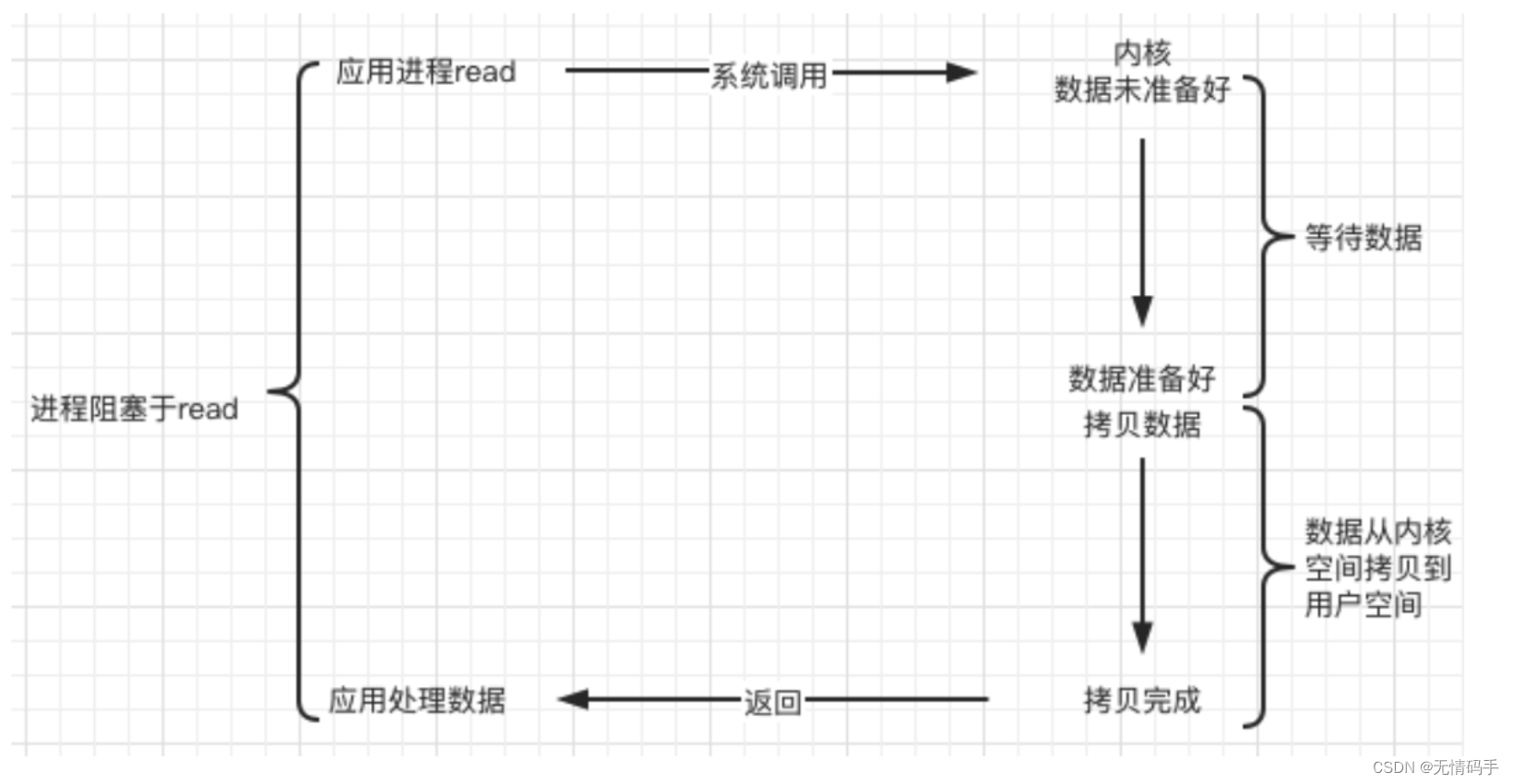
a.阻塞 blocking
调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作。
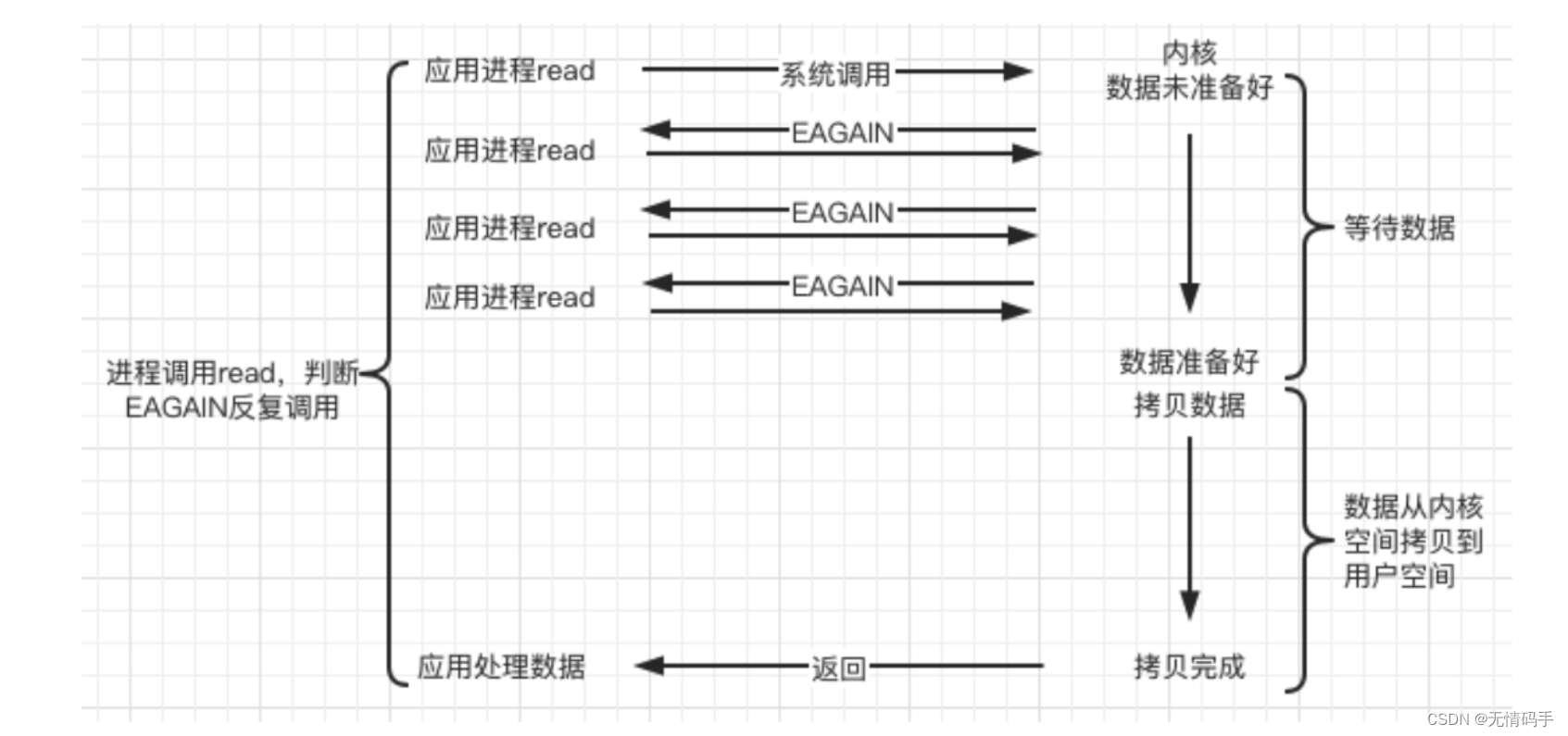
b.非阻塞 non-blocking(NIO)
非阻塞等待,每隔一段时间就去检测IO事件是否就绪。没有就绪就可以做其他事。非阻塞I/O执行系统调用总是立即返回,不管事件是否已经发生,若事件没有发生,则返回-1,此时可以根据 errno 区分这两种情况,对于accept,recv 和 send,事件未发生时,errno 通常被设置成 EAGAIN。
无论阻塞/非阻塞 单进程/线程 只能检测一个客户的情况
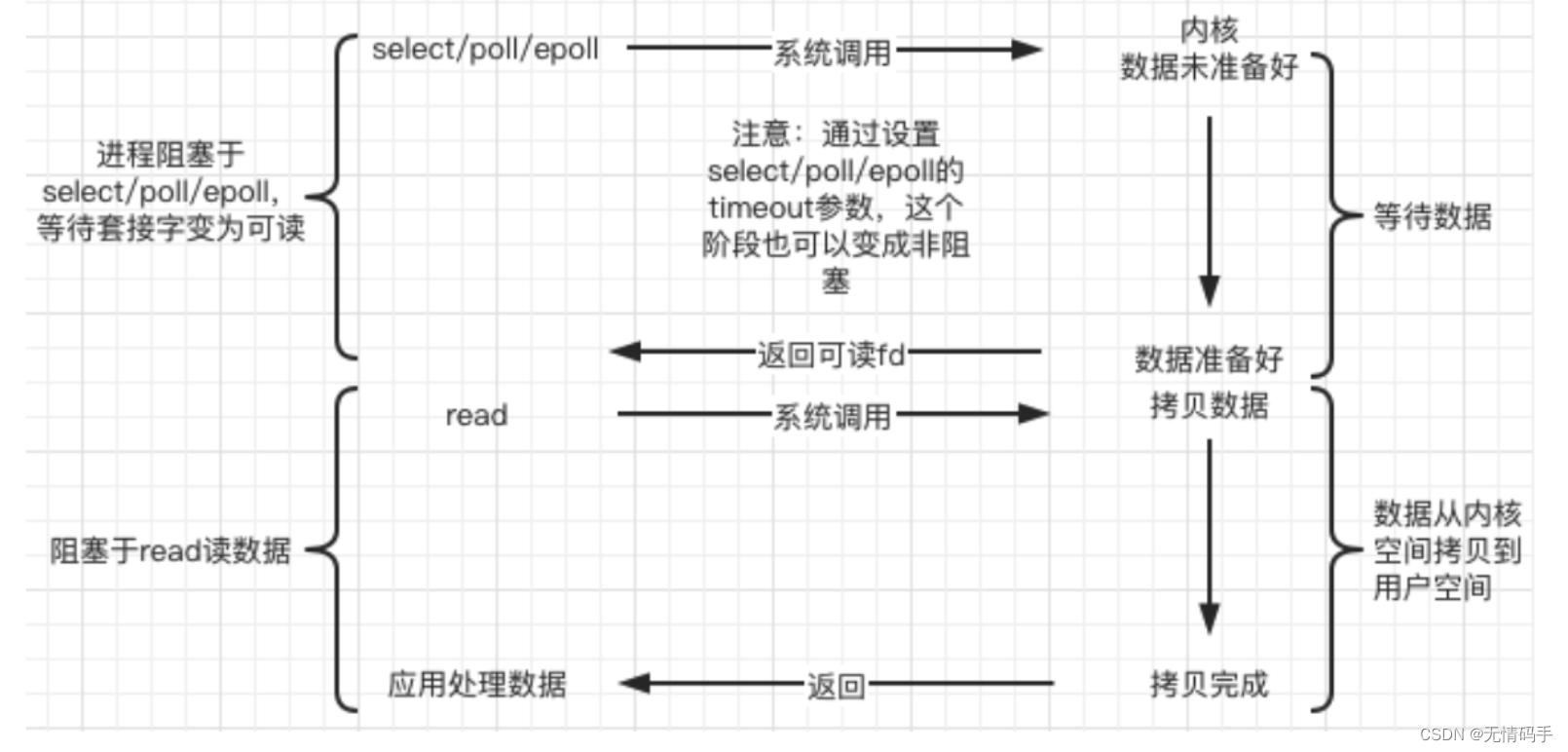
c. IO复用(IO multiplexing)
Linux 用 select/poll/epoll 函数实现 IO 复用模型,这些函数也会使进程阻塞,但是和阻塞IO所不同的是这些函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检测。直到有数据可读或可写时,才真正调用IO操作函数。单个进程/线程 一次可以检测多个客户端
d. 信号驱动(signal-driven)
Linux 用套接口进行信号驱动 IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO事件就绪,进程收到SIGIO 信号,然后处理 IO 事件。
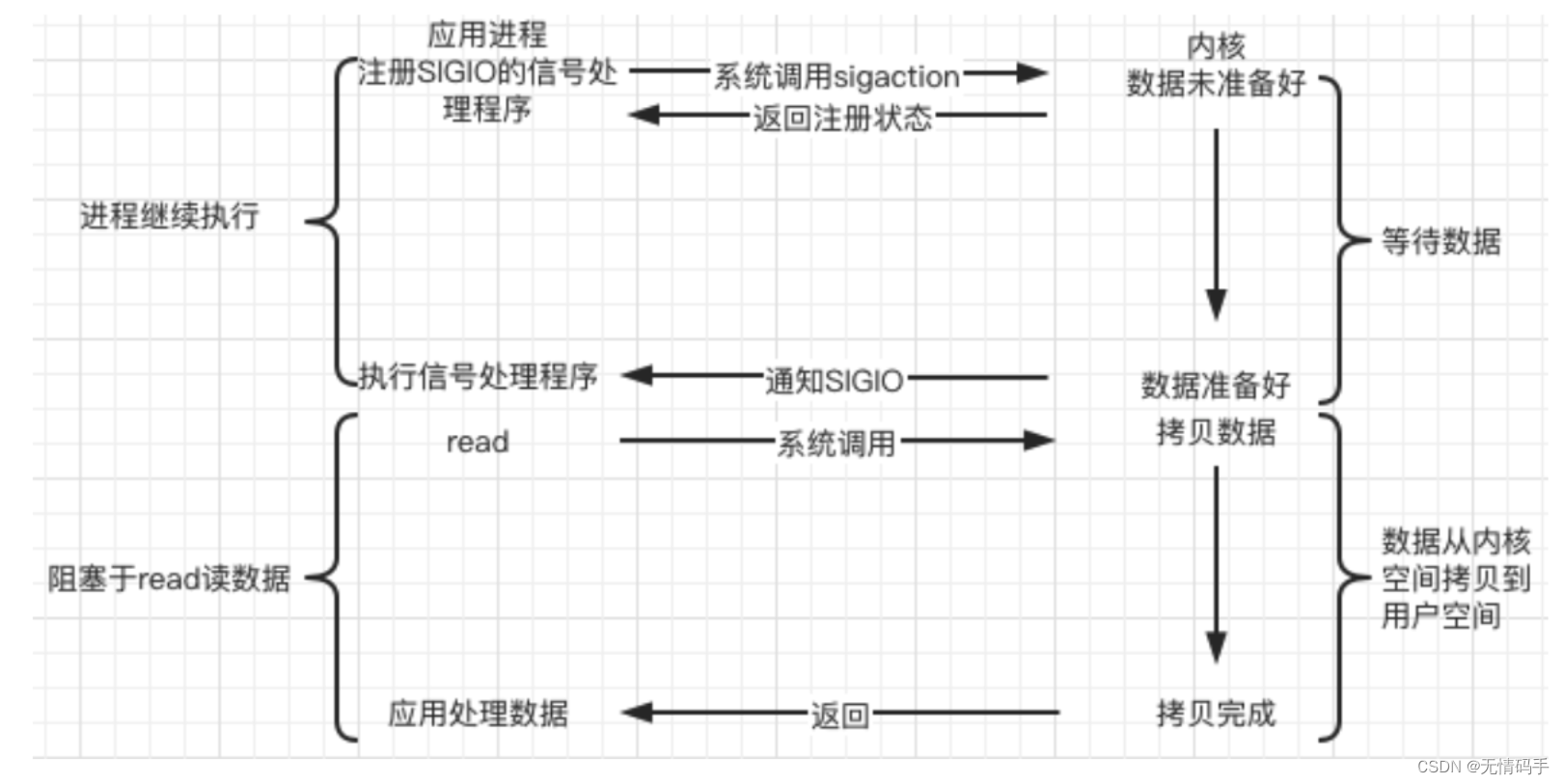
内核在第一个阶段是非阻塞,在第二个阶段是同步;与非阻塞IO的区别在于它提供了消息通知机制,不需要用户进程不断的轮询检查,减少了系统API的调用次数,提高了效率。
e. 异步(asynchronous)
Linux中,可以调用 aio_read 函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。
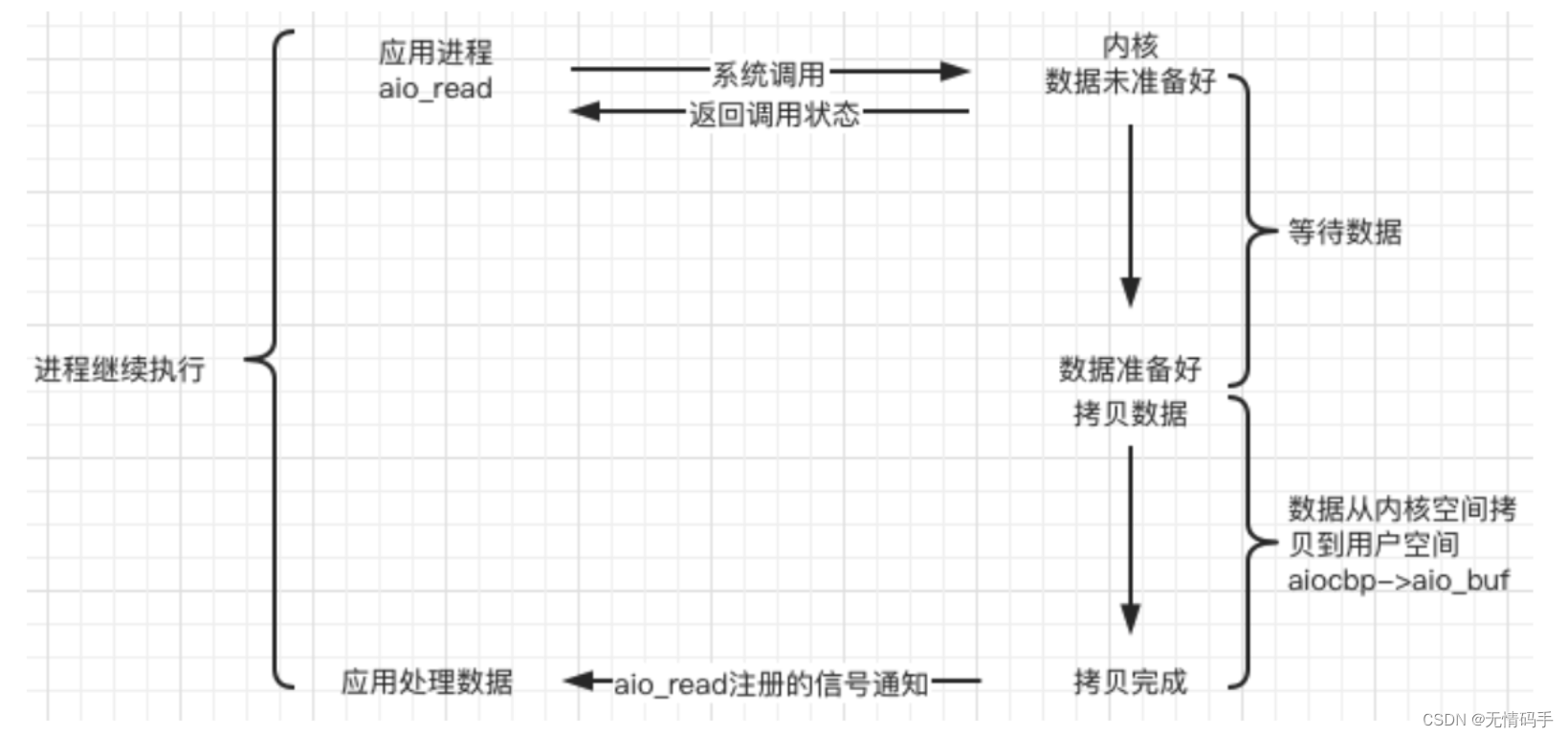
内核帮忙拷贝到用户空间的
/* Asynchronous I/O control block. */
struct aiocb
{
int aio_fildes; /* File desriptor. */
int aio_lio_opcode; /* Operation to be performed. */
int aio_reqprio; /* Request priority offset. */
volatile void *aio_buf; /* Location of buffer. */
size_t aio_nbytes; /* Length of transfer. */
struct sigevent aio_sigevent; /* Signal number and value. */
/* Internal members. */
struct aiocb *__next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */
#endif
char __glibc_reserved[32];
};
Web Server网页服务器
一个 Web Server 就是一个服务器软件(程序),或者是运行这个服务器软件的硬件(计算机)。其主要功能是通过 HTTP 协议与客户端(通常是浏览器(Browser))进行通信,来接收,存储,处理来自客户端的 HTTP 请求,并对其请求做出 HTTP 响应,返回给客户端其请求的内容(文件、网页等)或返回一个 Error 信息。

通常用户使用 Web 浏览器与相应服务器进行通信。在浏览器中键入“域名”或“IP地址:端口号”,浏览器则先将你的域名解析成相应的 IP 地址或者直接根据你的IP地址向对应的 Web 服务器发送一个 HTTP 请求。这一过程首先要通过 TCP 协议的三次握手建立与目标 Web 服务器的连接,然后 HTTP 协议生成针对目标 Web 服务器的 HTTP 请求报文,通过 TCP、IP 等协议发送到目标 Web 服务器上。
TCP协议:传输层协议
HTTP协议:应用层协议,底层基于TCP协议
4. HTTP(应用层协议)
简介
超文本传输协议(Hypertext Transfer Protocol,HTTP)是一个简单的请求 - 响应协议,它通常运行在
TCP 之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的
头以 ASCII 形式给出;而消息内容则具有一个类似 MIME 的格式。HTTP是万维网的数据通信的基础。
HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万
维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task
Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的 RFC 2616,定
义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1。
概述
HTTP 是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如 HTML 文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管 TCP/IP 协议是互联网上最流行的应用,HTTP 协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP 假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在 TCP/IP 协议族使用 TCP 作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的 TCP 连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
工作原理
HTTP 协议定义 Web 客户端如何从 Web 服务器请求 Web 页面,以及服务器如何把 Web 页面传送给客户端。HTTP 协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
- 客户端连接到 Web 服务器
一个HTTP客户端,通常是浏览器,与 Web 服务器的 HTTP 端口(默认为 80 )建立一个 TCP 套接
字连接。例如,http://www.baidu.com。(URL) - 发送 HTTP 请求
通过 TCP 套接字,客户端向 Web 服务器发送一个文本的请求报文,一个请求报文由请求行、请求
头部、空行和请求数据 4 部分组成。 - 服务器接受请求并返回 HTTP 响应
Web 服务器解析请求,定位请求资源。服务器将资源复本写到 TCP 套接字,由客户端读取。一个
响应由状态行、响应头部、空行和响应数据 4 部分组成。 - 释放连接 TCP 连接
若 connection 模式为 close,则服务器主动关闭 TCP连接,客户端被动关闭连接,释放 TCP 连
接;若connection 模式为 keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求; - 客户端浏览器解析 HTML 内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应
头告知以下为若干字节的 HTML 文档和文档的字符集。客户端浏览器读取响应数据 HTML,根据
HTML 的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立 TCP 连接;
- 浏览器发出读取文件( URL 中域名后面部分对应的文件)的 HTTP 请求,该请求报文作为 TCP 三
次握手的第三个报文的数据发送给服务器; - 服务器对浏览器请求作出响应,并把对应的 HTML 文本发送给浏览器;
- 释放 TCP 连接;
- 浏览器将该 HTML 文本并显示内容。

HTTP 协议是基于 TCP/IP 协议之上的应用层协议,基于 请求-响应 的模式。HTTP 协议规定,请求从客
户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端
在没有接收到请求之前不会发送响应。
HTTP请求报文格式
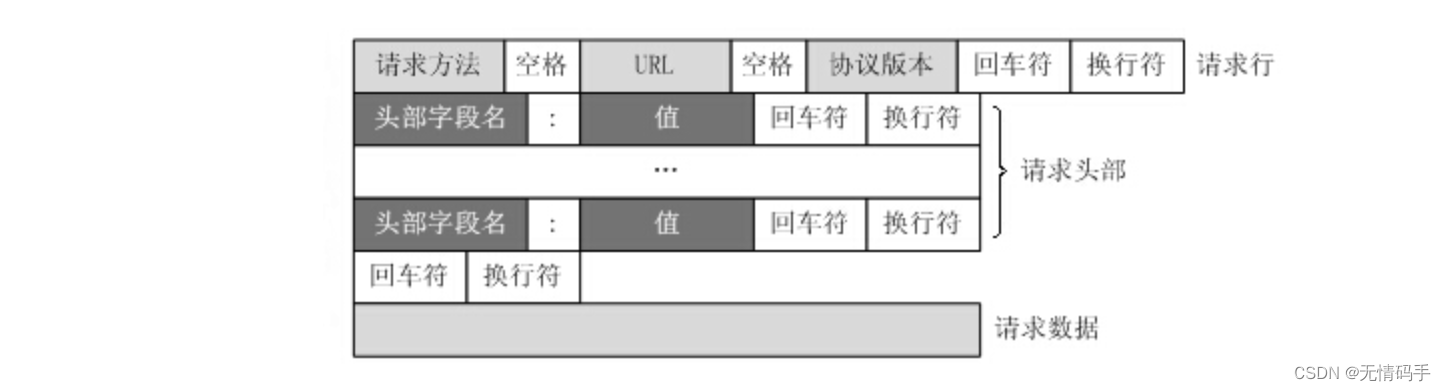
GET / HTTP/1.1 (请求行)
//下面都是请求头部,一个键:一个值
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFE015A8099199557E; PSTM=1614320692; BD_UPN=13314752;
BDORZ=FFFB88E999055A3F8A630C64834BD6D0;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782; BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alag0lag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
HTTP响应报文格式
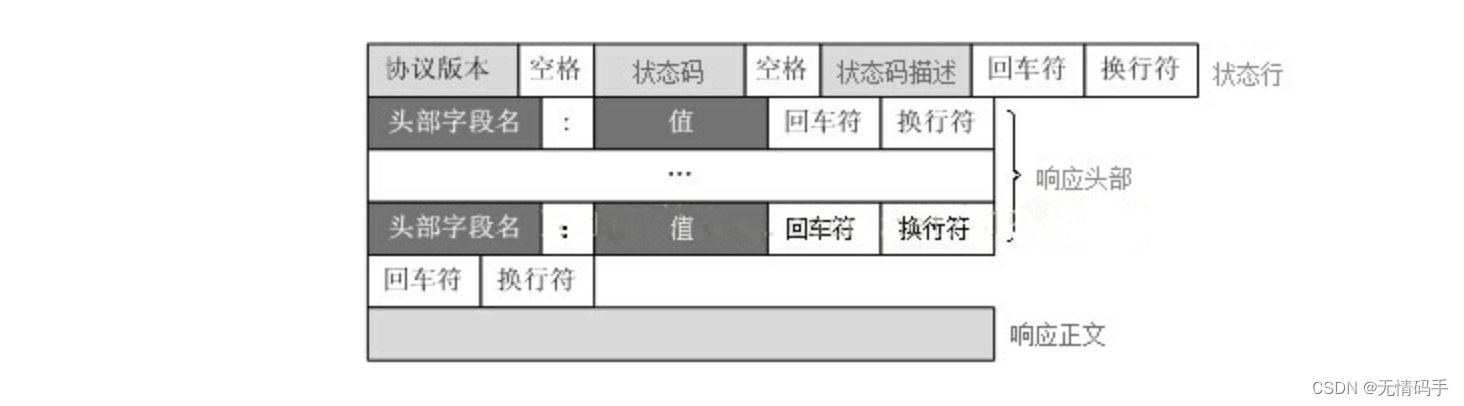
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0xf3c9743300024ee4
Cache-Control: private
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Fri, 26 Feb 2021 08:44:35 GMT
Expires: Fri, 26 Feb 2021 08:44:35 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=13; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=33514_33257_33273_31660_33570_26350; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 1614329075128412289017566699583927635684
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
(注意这里还有一个回车换行)
(然后可以跟响应正文)
(把别人请求的信息响应后封装起来发回去)
HTTP请求方法
HTTP/1.1 协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
- GET:向指定的资源发出“显示”请求。使用 GET 方法应该只用在读取数据,而不应当被用于产生“副
作用”的操作中,例如在 Web Application 中。其中一个原因是 GET 可能会被网络蜘蛛等随意访
问。 - HEAD:与 GET 方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文
部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该
资源的信息”(元信息或称元数据)。 - POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含
在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。 - PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- OPTIONS:这个方法可使服务器传回该资源所支持的所有 HTTP 请求方法。用’*'来代替资源名称,
向 Web 服务器发送 OPTIONS 请求,可以测试服务器功能是否正常运作。 - CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服
务器的链接(经由非加密的 HTTP 代理服务器)。
5.服务器编程基本框架
虽然服务器程序种类繁多,但其基本框架都一样,不同之处在于逻辑处理。
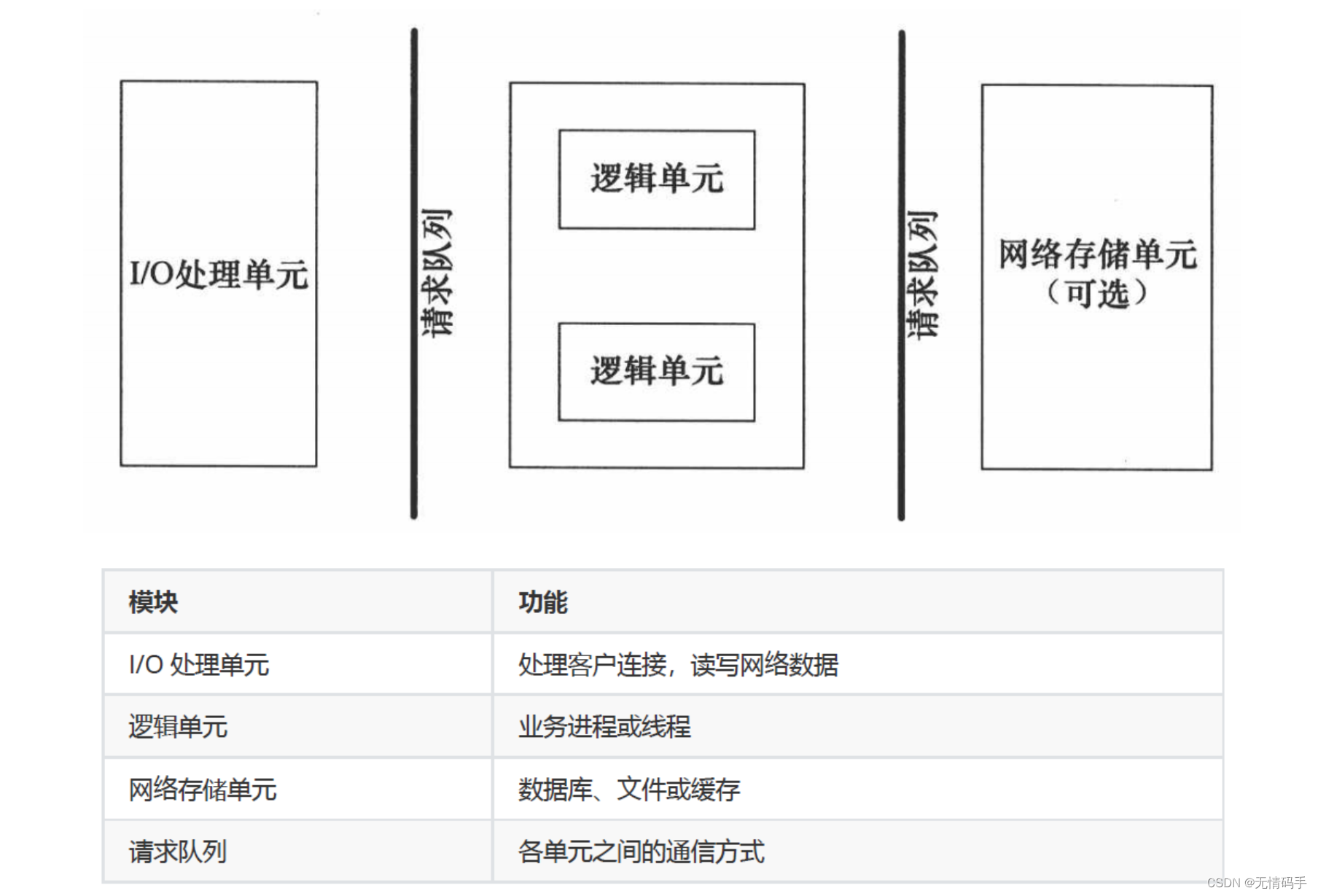
I/O 处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但是数据的收发不一定在 I/O 处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。
一个逻辑单元通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给 I/O 处理单元或者直接发送给客户端(具体使用哪种方式取决于事件处理模式)。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并发处理。高并发:多线程/进程
网络存储单元可以是数据库、缓存和文件,但不是必须的。
请求队列是各单元之间的通信方式的抽象。I/O 处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竞态条件。请求队列通常被实现为池的一部分。
6. 两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor和 Proactor,同步 I/O 模型通常用于实现 Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
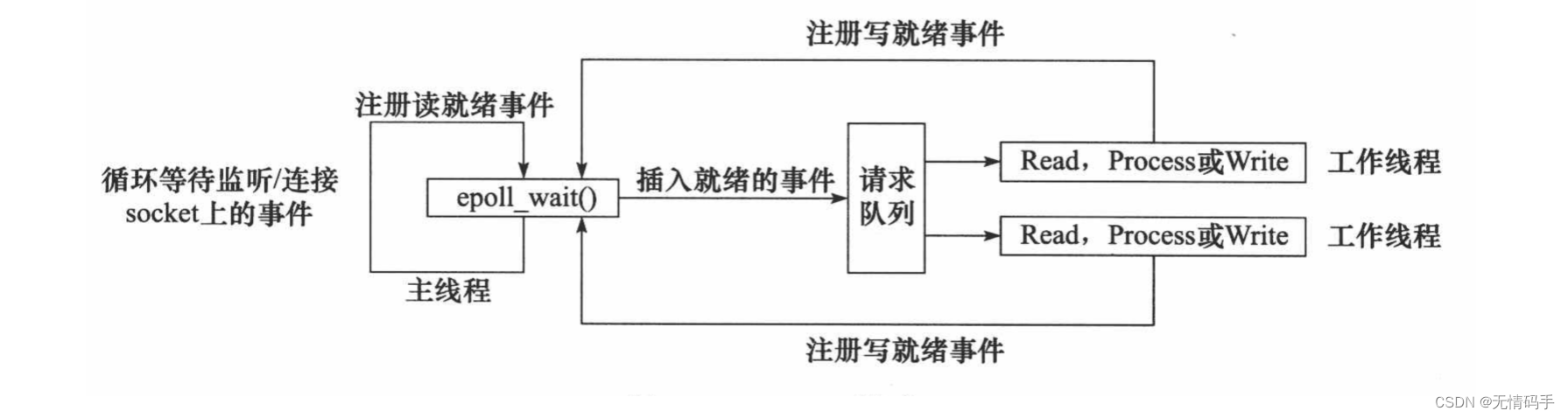
Reactor模式
要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。主线程只负责监听
使用同步 I/O(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:
-
主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
-
主线程调用 epoll_wait 等待 socket 上有数据可读。
-
当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
-
睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll
内核事件表中注册该 socket 上的写就绪事件。 -
当主线程调用 epoll_wait 等待 socket 可写。
-
当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
-
睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
Proactor模式
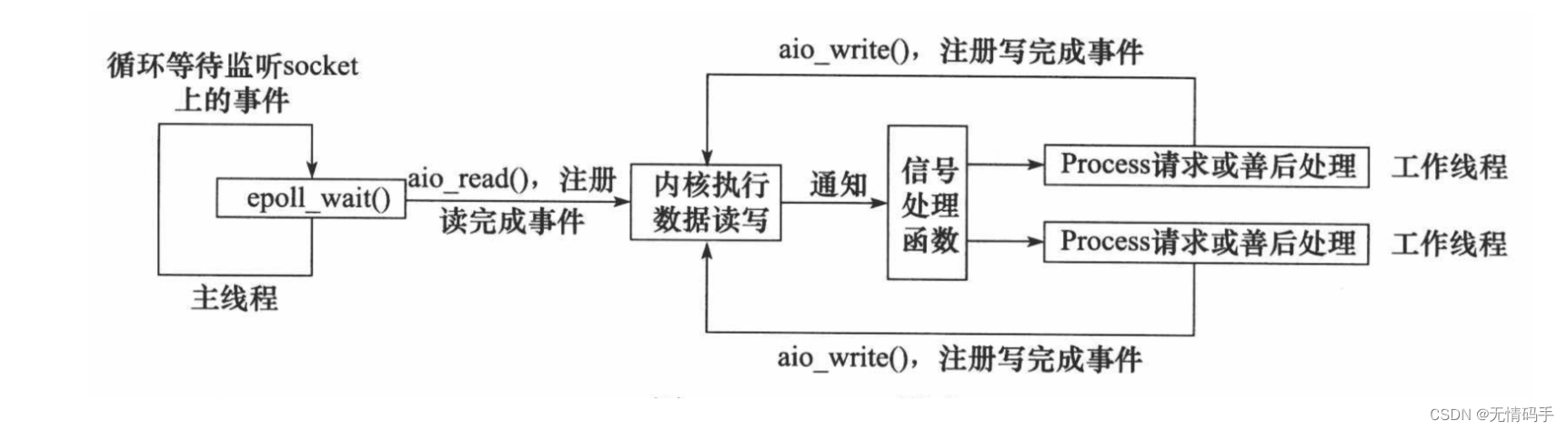
IO都是在主线程中做完的,工作线程并没有参与
Proactor 模式将所有 I/O 操作都交给主线程和内核来处理(进行读、写),工作线程仅仅负责业务逻辑。使用异步 I/O 模型(以 aio_read 和 aio_write 为例)实现的 Proactor 模式的工作流程是:
- 主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置,
以及读操作完成时如何通知应用程序(这里以信号为例)。 - 主线程继续处理其他逻辑。
- 当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据
已经可用。 - 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求
后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以
及写操作完成时如何通知应用程序。 - 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据
已经发送完毕。 - 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
模拟 Proactor 模式
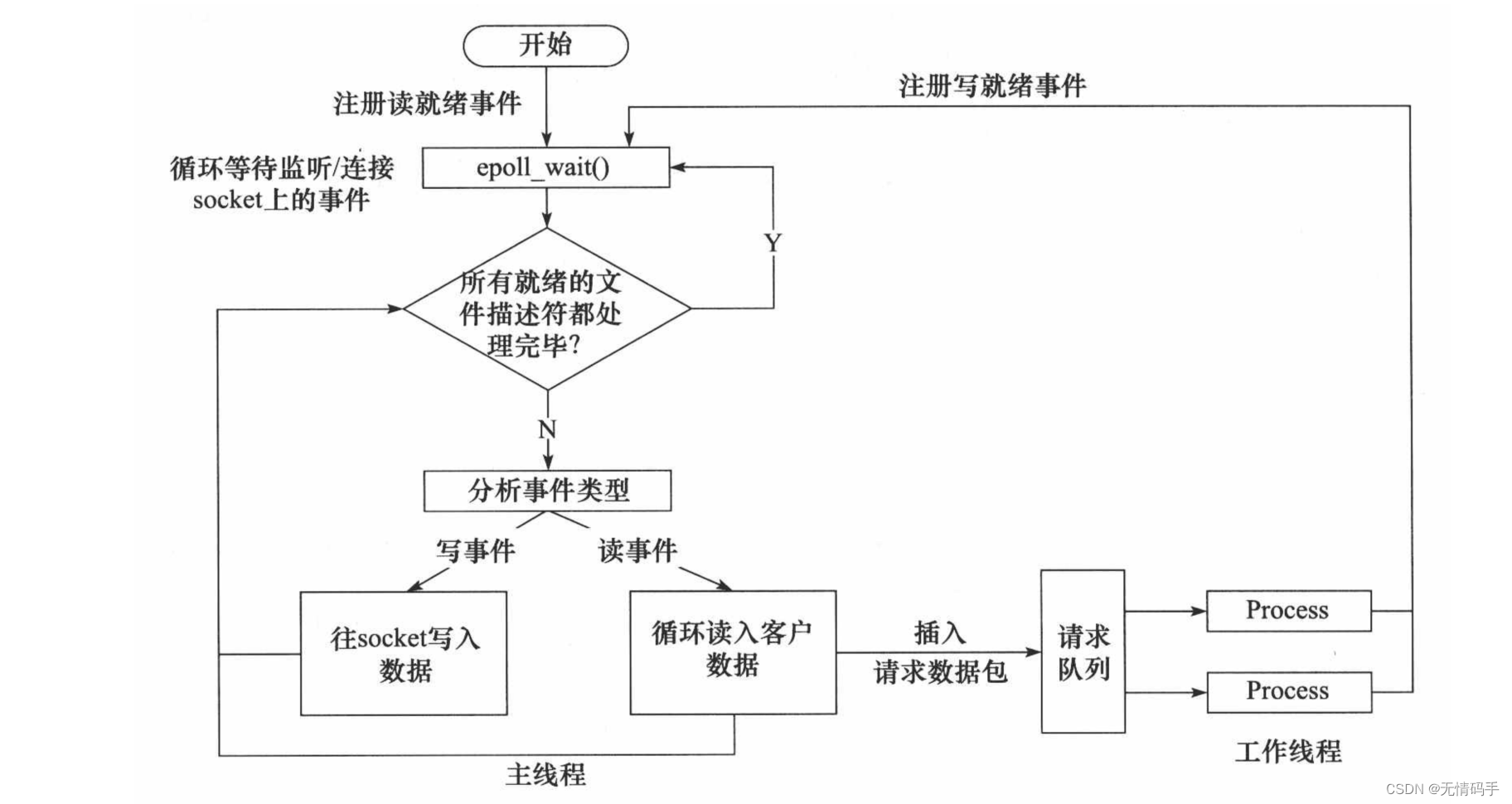
使用同步 I/O 方式模拟出 Proactor 模式。原理是:主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一”完成事件“。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
使用同步 I/O 模型(以 epoll_wait为例)模拟出的 Proactor 模式的工作流程如下:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更
多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。 - 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事
件表中注册 socket 上的写就绪事件。 - 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
工作线程只做任务处理,在主线程中已经把需要用的数据已经读到了,然后去处理任务
处理完之后,注册写就绪事件,已经把要写的数据准备好了,下一轮在主线程里往socket写
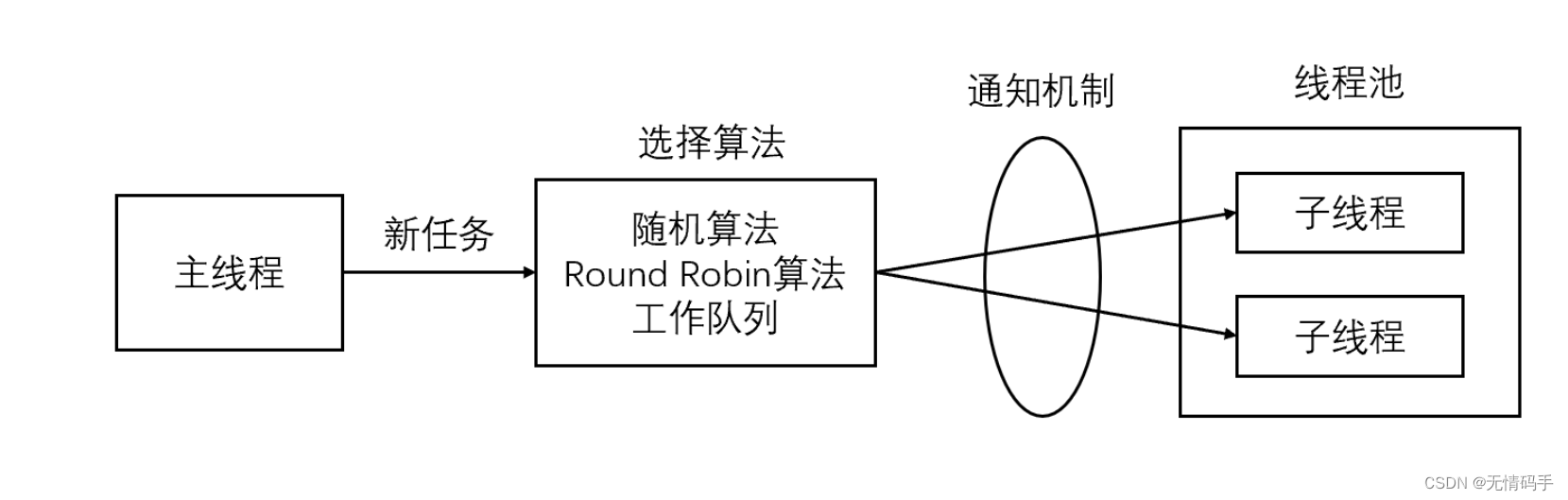
7.线程池
线程池是由服务器预先创建的一组子线程,线程池中的线程数量应该和 CPU 数量差不多。线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程,选择一个已经存在的子线程的代价显然要小得多。至于主线程选择哪个子线程来为新任务服务,则有多种方式:
- 主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round Robin(轮流选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。
- 主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的”接管权“,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在工作队列上。
有一万个客户端连接,创建一万个线程,用完了再销毁,这是非常浪费计算机资源的,所以我们改用线程池
线程池中的线程数量最直接的限制因素是中央处理器(CPU)的处理器(processors/cores)的数量N :如果你的CPU是4-cores的,对于CPU密集型的任务(如视频剪辑等消耗CPU计算资源的任务)来说,那线程池中的线程数量最好也设置为4(或者+1防止其他因素造成的线程阻塞);对于IO密集型的任务,一般要多于CPU的核数,因为线程间竞争的不是CPU的计算资源而是IO,IO的处理一般较慢,多于cores数的线程将为CPU争取更多的任务,不至在线程处理IO的过程造成CPU空闲导致资源浪费。
- 空间换时间,浪费服务器的硬件资源,换取运行效率。
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
- 当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中
获取,无需动态分配。 - 当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
任务队列被多个线程共享,线程同步
条件变量wait、signal函数是在加锁解锁里面
信号量的操作是在加锁解锁外面
条件变量
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
// 创建一个互斥量
pthread_mutex_t mutex;
// 创建条件变量
pthread_cond_t cond;
struct Node{
int num;
struct Node *next;
};
// 头结点
struct Node * head = NULL;
void * producer(void * arg) {
// 不断的创建新的节点,添加到链表中
while(1) {
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->next = head;
head = newNode;
newNode->num = rand() % 1000;
printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());
// 只要生产了一个,就通知消费者消费
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
usleep(100);
}
return NULL;
}
void * customer(void * arg) {
while(1) {
pthread_mutex_lock(&mutex);
// 保存头结点的指针
struct Node * tmp = head;
// 判断是否有数据
if(head != NULL) {
// 有数据
head = head->next;
printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());
free(tmp);
pthread_mutex_unlock(&mutex);
usleep(100);
} else {
// 没有数据,需要等待
// 当这个函数调用阻塞的时候,会对互斥锁进行解锁,当不阻塞的,继续向下执行,会重新加锁。
pthread_cond_wait(&cond, &mutex);
pthread_mutex_unlock(&mutex);
}
}
return NULL;
}
int main() {
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
// 创建5个生产者线程,和5个消费者线程
pthread_t ptids[5], ctids[5];
for(int i = 0; i < 5; i++) {
pthread_create(&ptids[i], NULL, producer, NULL);
pthread_create(&ctids[i], NULL, customer, NULL);
}
for(int i = 0; i < 5; i++) {
pthread_detach(ptids[i]);
pthread_detach(ctids[i]);
}
while(1) {
sleep(10);
}
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
pthread_exit(NULL);
return 0;
}
信号量
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#include <semaphore.h>
// 创建一个互斥量
pthread_mutex_t mutex;
// 创建两个信号量
sem_t psem;
sem_t csem;
struct Node{
int num;
struct Node *next;
};
// 头结点
struct Node * head = NULL;
void * producer(void * arg) {
// 不断的创建新的节点,添加到链表中
while(1) {
sem_wait(&psem);
pthread_mutex_lock(&mutex);
struct Node * newNode = (struct Node *)malloc(sizeof(struct Node));
newNode->next = head;
head = newNode;
newNode->num = rand() % 1000;
printf("add node, num : %d, tid : %ld\n", newNode->num, pthread_self());
pthread_mutex_unlock(&mutex);
sem_post(&csem);
}
return NULL;
}
void * customer(void * arg) {
while(1) {
sem_wait(&csem);
pthread_mutex_lock(&mutex);
// 保存头结点的指针
struct Node * tmp = head;
head = head->next;
printf("del node, num : %d, tid : %ld\n", tmp->num, pthread_self());
free(tmp);
pthread_mutex_unlock(&mutex);
sem_post(&psem);
}
return NULL;
}
int main() {
pthread_mutex_init(&mutex, NULL);
sem_init(&psem, 0, 8);
sem_init(&csem, 0, 0);
// 创建5个生产者线程,和5个消费者线程
pthread_t ptids[5], ctids[5];
for(int i = 0; i < 5; i++) {
pthread_create(&ptids[i], NULL, producer, NULL);
pthread_create(&ctids[i], NULL, customer, NULL);
}
for(int i = 0; i < 5; i++) {
pthread_detach(ptids[i]);
pthread_detach(ctids[i]);
}
while(1) {
sleep(10);
}
pthread_mutex_destroy(&mutex);
pthread_exit(NULL);
return 0;
}
Proactor:
主线程一次性读出数据后,封装成任务对象再交给工作线程
软中断
收到信号中断了,等再回来之后accept就不阻塞了,目前没新的客户端连接,它就报错了,所以我们处理一下
如果中断了(errno是 EINTR,那么就continue)
int cfd = accept(lfd, (struct sockaddr*)&cliaddr, &len);
if(cfd == -1) {
if(errno == EINTR) {
continue;
}
perror("accept");
exit(-1);
}
(它曾经用在过通过进程实现TCP多个客户端和服务器通信中,父进程要回收子进程的资源)
#### 回忆(见笔记4):
不能再while循环里进行父进程对子进程的回收,一有wait,整个阻塞在那了,不能接收另一个客户端
用waitpid也不太好,所以我们用信号来完成释放
注意处理信号的handler函数要用while循环起来,搭配waitpid使用,有可能死了三个子进程,但是未决信号只有一个,我们用waitpid 一次是处理不完三个的
LT是不需要把read/recv搭配上while使用的,且不需要设置非阻塞(设不设都可以),就一次读就好,如果没读完,epoll_wait还会再次告知,完了你下面再接着读
ET就说一次,read/recv需要设置成非阻塞,循环地在一次通知下把数据都读完
9.EPOLLONESHOT事件
即使可以使用 ET 模式,一个socket 上的某个事件还是可能被触发多次。这在并发程序中就会引起一个问题。比如一个线程在读取完某个 socket 上的数据后开始处理这些数据,而在数据的处理过程中该socket 上又有新数据可读(EPOLLIN 再次被触发),此时另外一个线程被唤醒来读取这些新的数据。于是就出现了两个线程同时操作一个 socket 的局面。一个socket连接在任一时刻都只被一个线程处理,可以使用 epoll 的 EPOLLONESHOT 事件实现。 **对于注册了 EPOLLONESHOT 事件的文件描述符,操作系统最多触发其上注册的一个可读、可写或者异常事件,且只触发一次,除非我们使用 epoll_ctl 函数重置该文件描述符上注册的 EPOLLONESHOT 事件。**这样,当一个线程在处理某个 socket 时,其他线程是不可能有机会操作该 socket 的。但反过来思考,注册EPOLLONESHOT 事件的 socket 一旦被某个线程处理完毕, 该线程就应该立即重置这个socket 上的 EPOLLONESHOT 事件,以确保这个 socket 下一次可读时,其 EPOLLIN 事件能被触发,进而让其他工作线程有机会继续处理这个 socket。
10. 有限状态机
逻辑单元内部的一种高效编程方法:有限状态机(finite state machine)。
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑。如下是一种状态独立的有限状态机:
//根据不同状态执行不同的业务逻辑
STATE_MACHINE( Package _pack )
{
PackageType _type = _pack.GetType();
switch( _type )
{
case type_A:
process_package_A( _pack );
break;
case type_B:
process_package_B( _pack );
break;
}
}
这是一个简单的有限状态机,只不过该状态机的每个状态都是相互独立的,即状态之间没有相互转移。
状态之间的转移是需要状态机内部驱动,如下代码:
STATE_MACHINE()
{
State cur_State = type_A;
while( cur_State != type_C )
{
Package _pack = getNewPackage();
switch( cur_State )
{
case type_A:
process_package_state_A( _pack );
cur_State = type_B;
break;
case type_B:
process_package_state_B( _pack );
cur_State = type_C;
break;
}
}
}
该状态机包含三种状态:type_A、type_B 和 type_C,其中 type_A 是状态机的开始状态,type_C 是状态机的结束状态。状态机的当前状态记录在 cur_State 变量中。在一趟循环过程中,状态机先通过getNewPackage 方法获得一个新的数据包,然后根据 cur_State 变量的值判断如何处理该数据包。数据包处理完之后,状态机通过给 cur_State 变量传递目标状态值来实现状态转移。那么当状态机进入下一趟循环时,它将执行新的状态对应的逻辑。
解析的时候一行一行的解析 \r\n
根据不同的状态处理不同的事情
具体流程:
检测到读事件,一下子把数据读完,添加到线程池的队列当中,线程池队列取出一个任务去执行process(主要业务逻辑)。先是解析,解析完之后生成响应(两块数据,一块:响应首行、响应头、空行。另一块:真正的要请求的文件的数据)。我们用分散写的形式写出去,(当它检测到可以写的时候)
优化
定义定时器(给客户端),超时了没有进行数据的交互就断掉了,用升序双向链表,探测到一个超时了后面都是超时的
服务器压力测试
Webbench 是 Linux 上一款知名的、优秀的 web 性能压力测试工具。它是由Lionbridge公司开发。
- 测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。
- 展示服务器的两项内容:每秒钟响应请求数和每秒钟传输数据量。
基本原理:Webbench 首先 fork 出多个子进程,每个子进程都循环做 web 访问测试。子进程把访问的结果通过pipe 告诉父进程,父进程做最终的统计结果。
示例:
webbench -c 1000 -t 30 http://192.168.110.129:10000/index.html
参数:
-c 表示客户端数
-t 表示时间
优化:支持POST、数据库、改成Reactor模式、Proactor模式、LT->ET
代码解析:
互斥锁类:locker.h
(里面定义了互斥锁类、条件变量类、信号量类)
#ifndef LOCKER_H
#define LOCKER_H
#include <exception>
#include <pthread.h>
#include <semaphore.h>
// 线程同步机制封装类
// 互斥锁类
class locker {
public:
locker() {
if(pthread_mutex_init(&m_mutex, NULL) != 0) {
throw std::exception();
}
}
~locker() {
pthread_mutex_destroy(&m_mutex);
}
bool lock() {
return pthread_mutex_lock(&m_mutex) == 0;
}
bool unlock() {
return pthread_mutex_unlock(&m_mutex) == 0;
}
pthread_mutex_t *get()
{
return &m_mutex;
}
private:
pthread_mutex_t m_mutex;
};
// 条件变量类
class cond {
public:
cond(){
if (pthread_cond_init(&m_cond, NULL) != 0) {
throw std::exception();
}
}
~cond() {
pthread_cond_destroy(&m_cond);
}
bool wait(pthread_mutex_t *m_mutex) {
int ret = 0;
ret = pthread_cond_wait(&m_cond, m_mutex);
return ret == 0;
}
bool timewait(pthread_mutex_t *m_mutex, struct timespec t) {
int ret = 0;
ret = pthread_cond_timedwait(&m_cond, m_mutex, &t);
return ret == 0;
}
//唤醒一个/多个等待的线程
bool signal() {
return pthread_cond_signal(&m_cond) == 0;
}
//唤醒所有等待的线程
bool broadcast() {
return pthread_cond_broadcast(&m_cond) == 0;
}
private:
pthread_cond_t m_cond;
};
// 信号量类
class sem {
public:
sem() {
if( sem_init( &m_sem, 0, 0 ) != 0 ) {
throw std::exception();
}
}
sem(int num) {
if( sem_init( &m_sem, 0, num ) != 0 ) {
throw std::exception();
}
}
~sem() {
sem_destroy( &m_sem );
}
// 等待信号量
bool wait() {
return sem_wait( &m_sem ) == 0;
}
// 增加信号量
bool post() {
return sem_post( &m_sem ) == 0;
}
private:
sem_t m_sem;
};
#endif
线程池类:threadpool.h
成员变量定义了:
- 线程的数量
- 线程池数组
- 最大请求数量
- 请求队列 (存放要请求的任务指针类型)
- 互斥锁
- 信号量
- 线程池是否结束
成员函数定义了:
-
构造函数
初始化线程数量、请求数量、new出线程池数组、创建出对应的线程,并为他们设置detach,如果出现了错误,要delete [] 线程池数组
-
析构函数
delete [] 线程池数组 并且给线程池是否结束变量设置为true
-
创建线程时所需的回调函数work(void*返回值 同时是static类型的)
因为要调用类内非静态成员,因此要注意把this指针传进去,里面调用run函数()
-
run函数
对变量进行同步操作,利用信号量、互斥锁。取出待处理的任务request,取出后即可取锁,然后其他线程就可以继续对变量进行同步操作。此线程继续对requset完成process操作。操作完成后,此线程继续循环去争取新的任务
-
append 函数
任务变量在消耗,我们还需要对其进行append添加,并放入容器中,同时要对信号量进行增加
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <list>
#include <cstdio>
#include <exception>
#include <pthread.h>
#include "locker.h"
// 线程池类,将它定义为模板类是为了代码复用,模板参数T是任务类
template<typename T>
class threadpool {
public:
/*thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量*/
threadpool(int thread_number = 8, int max_requests = 10000);
~threadpool();
bool append(T* request);
private:
/*工作线程运行的函数,它不断从工作队列中取出任务并执行之*/
//注意这里是静态函数
static void* worker(void* arg);
void run();
private:
// 线程的数量
int m_thread_number;
// 描述线程池的数组,大小为m_thread_number
pthread_t * m_threads;
// 请求队列中最多允许的、等待处理的请求的数量
int m_max_requests;
// 请求队列
std::list< T* > m_workqueue;
// 保护请求队列的互斥锁
locker m_queuelocker;
// 是否有任务需要处理
sem m_queuestat;
// 是否结束线程
bool m_stop;
};
template< typename T >
threadpool< T >::threadpool(int thread_number, int max_requests) :
m_thread_number(thread_number), m_max_requests(max_requests),
m_stop(false), m_threads(NULL) {
if((thread_number <= 0) || (max_requests <= 0) ) {
throw std::exception();
}
m_threads = new pthread_t[m_thread_number];
if(!m_threads) {
throw std::exception();
}
// 创建thread_number 个线程,并将他们设置为脱离线程。
for ( int i = 0; i < thread_number; ++i ) {
printf( "create the %dth thread\n", i);
if(pthread_create(m_threads + i, NULL, worker, this ) != 0) {
delete [] m_threads;
throw std::exception();
}
if( pthread_detach( m_threads[i] ) ) {
delete [] m_threads;
throw std::exception();
}
}
}
template< typename T >
threadpool< T >::~threadpool() {
delete [] m_threads;
m_stop = true;
}
//给需要同步操作的变量增加值(就是request)
template< typename T >
bool threadpool< T >::append( T* request )
{
// 操作工作队列时一定要加锁,因为它被所有线程共享。
m_queuelocker.lock();
if ( m_workqueue.size() > m_max_requests ) {
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlock();
m_queuestat.post();
return true;
}
//因为worker是一个静态函数,他要访问非静态的成员,需要把this指针传进来
template< typename T >
void* threadpool< T >::worker( void* arg )
{
threadpool* pool = ( threadpool* )arg;
pool->run();
return pool;
}
template< typename T >
void threadpool< T >::run() {
while (!m_stop) {
//信号量在锁前面
m_queuestat.wait();//有值,不阻塞 -1
m_queuelocker.lock();
if ( m_workqueue.empty() ) {
m_queuelocker.unlock();
continue;
}
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlock();
//拿出来这个任务后就可以放掉锁了
//这个线程处理这个request、其他线程可以去处理其他request了
if ( !request ) {
continue;
}
//线程调用处理request
request->process();
}
//这个线程处理完一个request就可以去循环处理其他request了
}
#endif
main函数
(1)进入之后获取端口号
并调用addsig函数(一端断开,另一端还在写会产生SIGPIPE信号,我们将它默认终止改为忽略)
(2)定义线程池并new出这个线程池对象
(3)创建出http_conn数组,存放将会来的连接
(在线程池中的任务列表中存放的也是将来要连接的对象,并对他们处理)
(4)创建监听套接字、实现端口复用(在前)及绑定
(5)创建epoll对象,事件数组,将listenfd添加到epoll对象中
(6)给http_conn对象的static变量epoll_fd赋值
(7)循环调用epoll_wait函数,监听添加到里面的对象,并且对listenfd和其他的fd进行处理
(8)对于listenfd,accept新的fd,判断它们有没有超出最大连接fd数量,并对它进行init(初始化sockfd, addr, 设置端口复用,将fd添加到epoll中并设置事件(如果是ET,要设置非阻塞),并且init其他杂项(读写缓冲区、文件缓冲区、连接方式、URL、读写指针等等)) listenfd得到连接fd后,就要立刻初始化http_conn对象,并且把它的fd添加到epoll中,当这个fd被判断为读事件时,读完找到这个对应的对象的指针,append到任务队列里
fd和http_conn是绑定连接的,拿到fd后要去初始化users[connfd]
(9)对于其他fd,判断它们的事件类型:
如果是出错(异常断开或者错误发生,直接关闭连接)
如果是读事件,将数据一次性全部读入到http_conn对象(users[sockfd])中,从http_conn的sockfd中读,记得之前的笔记,它是服务端这边伸出来的一个sockfd,但是数据是从客户端那边流入的紧接着把http_conn*对象append到线程池中(线程池中的线程拿到数据就会去调用process处理了)
如果是写事件,将数据一次性写入写入http_conn的sockfd(是分散写的两部分),如果写完了,就关闭连接
tips:
events对象的大小是最大连接数 10000,epoll_wait得到number的最大大小也是10000
但是从listenfd得到的最大fd数是65536
(10)关闭epollfd,关闭listenfd,delete [] users , delete poll
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include "locker.h"
#include "threadpool.h"
#include "http_conn.h"
#define MAX_FD 65536 // 最大的文件描述符个数
#define MAX_EVENT_NUMBER 10000 // 监听的最大的事件数量
// 添加文件描述符
extern void addfd( int epollfd, int fd, bool one_shot );
extern void removefd( int epollfd, int fd );
void addsig(int sig, void( handler )(int)){
struct sigaction sa;
memset( &sa, '\0', sizeof( sa ) );
sa.sa_handler = handler;
//信号集 sa_mask 是在执行信号处理程序时被阻塞的信号集。把阻塞信号集都置为了1
//只有通过sigprocmask才能改变内核当中的信号集
//临时阻塞信号集,在信号捕捉函数执行过程中,临时阻塞某些信号。执行完了就不阻塞了
sigfillset( &sa.sa_mask );
//sigaction 信号捕捉函数
assert( sigaction( sig, &sa, NULL ) != -1 );
}
int main( int argc, char* argv[] ) {
if( argc <= 1 ) {
printf( "usage: %s port_number\n", basename(argv[0]));
return 1;
}
int port = atoi( argv[1] );
//一端断开连接了,另一方还在写,会产生信号SIGPIPE
//对SIGPIPE进行处理
//遇到SIGPIPE忽略(默认是终止的)
addsig( SIGPIPE, SIG_IGN );
threadpool< http_conn >* pool = NULL;
try {
pool = new threadpool<http_conn>;
} catch( ... ) {
return 1;
}
http_conn* users = new http_conn[ MAX_FD ];
int listenfd = socket( PF_INET, SOCK_STREAM, 0 );
int ret = 0;
struct sockaddr_in address;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_family = AF_INET;
address.sin_port = htons( port );
// 端口复用
//在!!绑定前!!设置端口复用
//socket端口复用
//主要用于服务端绑定固定端口,防止端口被占用或者没有释放时绑定失败。
//端口仍被占用(因端口上有处于TIME_WAIT的连接)。
int reuse = 1;
setsockopt( listenfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof( reuse ) );
ret = bind( listenfd, ( struct sockaddr* )&address, sizeof( address ) );
ret = listen( listenfd, 5 );
// 创建epoll对象,和事件数组,添加
epoll_event events[ MAX_EVENT_NUMBER ];
int epollfd = epoll_create( 5 );
// 添加到epoll对象中
//listenfd不需要添加oneshot事件,因为它是监听的文件描述符
addfd( epollfd, listenfd, false );
http_conn::m_epollfd = epollfd;
while(true) {
int number = epoll_wait( epollfd, events, MAX_EVENT_NUMBER, -1 );
//为什么判断EINTR?产生信号以后它就中断,回来后不阻塞了,所以它返回的-1
//在这种情况下是没有错误的
if ( ( number < 0 ) && ( errno != EINTR ) ) {
printf( "epoll failure\n" );
break;
}
for ( int i = 0; i < number; i++ ) {
int sockfd = events[i].data.fd;
if( sockfd == listenfd ) {
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof( client_address );
int connfd = accept( listenfd, ( struct sockaddr* )&client_address, &client_addrlength );
if ( connfd < 0 ) {
printf( "errno is: %d\n", errno );
continue;
}
if( http_conn::m_user_count >= MAX_FD ) {
//目前连接数满了, 回写数据给客户端(服务器内部正忙)
close(connfd);
continue;
}
users[connfd].init( connfd, client_address);
} else if( events[i].events & ( EPOLLRDHUP | EPOLLHUP | EPOLLERR ) ) {
//对方异常断开或者错误等事件发生
//关闭连接
users[sockfd].close_conn();
} else if(events[i].events & EPOLLIN) {
if(users[sockfd].read()) {
pool->append(users + sockfd);
} else {
users[sockfd].close_conn();
}
} else if( events[i].events & EPOLLOUT ) {
if( !users[sockfd].write() ) {
users[sockfd].close_conn();
}
}
}
}
close( epollfd );
close( listenfd );
delete [] users;
delete pool;
return 0;
}
http_conn类:
成员变量:
static: epoll_fd、user_count
读写缓冲区
读写缓冲区已经读入/写入最后一个字节的下一个位置
当前正在解析的读/写缓冲区的位置
当前解析行起始位置
请求文件完整路径名
http请求的一些信息
写缓冲区内存映射的起始位置
分散写的结构体
主状态机的状态
请求方法
一些枚举类型的HTTP请求方法、主状态机状态、HTTP请求结果、从状态机的三种状态
成员函数:
构造析构、关闭连接、处理客户端请求、非阻塞读写、初始化连接、解析http请求、填充http应答、一系列分析http请求、一系列填充http应答
#ifndef HTTPCONNECTION_H
#define HTTPCONNECTION_H
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include "locker.h"
#include <sys/uio.h>
class http_conn
{
public:
static const int FILENAME_LEN = 200; // 文件名的最大长度
static const int READ_BUFFER_SIZE = 2048; // 读缓冲区的大小
static const int WRITE_BUFFER_SIZE = 1024; // 写缓冲区的大小
// HTTP请求方法,这里只支持GET
enum METHOD {GET = 0, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT};
/*
解析客户端请求时,主状态机的状态
CHECK_STATE_REQUESTLINE:当前正在分析请求行
CHECK_STATE_HEADER:当前正在分析头部字段
CHECK_STATE_CONTENT:当前正在解析请求体
*/
enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT };
/*
服务器处理HTTP请求的可能结果,报文解析的结果
NO_REQUEST : 请求不完整,需要继续读取客户数据
GET_REQUEST : 表示获得了一个完成的客户请求
BAD_REQUEST : 表示客户请求语法错误
NO_RESOURCE : 表示服务器没有资源
FORBIDDEN_REQUEST : 表示客户对资源没有足够的访问权限
FILE_REQUEST : 文件请求,获取文件成功
INTERNAL_ERROR : 表示服务器内部错误
CLOSED_CONNECTION : 表示客户端已经关闭连接了
*/
enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };
// 从状态机的三种可能状态,即行的读取状态,分别表示
// 1.读取到一个完整的行 2.行出错 3.行数据尚且不完整
enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };
public:
http_conn(){}
~http_conn(){}
public:
void init(int sockfd, const sockaddr_in& addr); // 初始化新接受的连接
void close_conn(); // 关闭连接
void process(); // 处理客户端请求
bool read();// 非阻塞读
bool write();// 非阻塞写
private:
void init(); // 初始化连接
HTTP_CODE process_read(); // 解析HTTP请求
bool process_write( HTTP_CODE ret ); // 填充HTTP应答
// 下面这一组函数被process_read调用以分析HTTP请求
HTTP_CODE parse_request_line( char* text );
HTTP_CODE parse_headers( char* text );
HTTP_CODE parse_content( char* text );
HTTP_CODE do_request();
char* get_line() { return m_read_buf + m_start_line; }
LINE_STATUS parse_line();
// 这一组函数被process_write调用以填充HTTP应答。
void unmap();
bool add_response( const char* format, ... );
bool add_content( const char* content );
bool add_content_type();
bool add_status_line( int status, const char* title );
bool add_headers( int content_length );
bool add_content_length( int content_length );
bool add_linger();
bool add_blank_line();
public:
static int m_epollfd; // 所有socket上的事件都被注册到同一个epoll内核事件中,所以设置成静态的
static int m_user_count; // 统计用户的数量
private:
int m_sockfd; // 该HTTP连接的socket和对方的socket地址
sockaddr_in m_address;
char m_read_buf[ READ_BUFFER_SIZE ]; // 读缓冲区
int m_read_idx; // 标识读缓冲区中已经读入的客户端数据的最后一个字节的下一个位置
int m_checked_idx; // 当前正在分析的字符在读缓冲区中的位置
int m_start_line; // 当前正在解析的行的起始位置
CHECK_STATE m_check_state; // 主状态机当前所处的状态
METHOD m_method; // 请求方法
char m_real_file[ FILENAME_LEN ]; // 客户请求的目标文件的完整路径,其内容等于 doc_root + m_url, doc_root是网站根目录
char* m_url; // 客户请求的目标文件的文件名
char* m_version; // HTTP协议版本号,我们仅支持HTTP1.1
char* m_host; // 主机名
int m_content_length; // HTTP请求的消息总长度
bool m_linger; // HTTP请求是否要求保持连接
char m_write_buf[ WRITE_BUFFER_SIZE ]; // 写缓冲区
int m_write_idx; // 写缓冲区中待发送的字节数
char* m_file_address; // 客户请求的目标文件被mmap到内存中的起始位置
struct stat m_file_stat; // 目标文件的状态。通过它我们可以判断文件是否存在、是否为目录、是否可读,并获取文件大小等信息
struct iovec m_iv[2]; // 我们将采用writev来执行写操作,所以定义下面两个成员,其中m_iv_count表示被写内存块的数量。
int m_iv_count;
int bytes_to_send; // 将要发送的数据的字节数
int bytes_have_send; // 已经发送的字节数
};
#endif
process()里包括:
-
process_read()
-
process_write()
读操作的处理:(一次性读完之后,将请求中的数据封装到对象中,并且把请求资源封装到m_file_address)
对于process函数,里面先调用了read_process()函数,把read到buf里的通过一行一行的分析,根据主/从状态机的状态,把请求行、请求头里的数据都封装到了http_conn对象当中。并且完成对请求头/请求体的分析后,调用了do_request函数,将客户端访问的URL的文件资源通过内存映射存储到对象的m_file_address变量中,操作完之后要再用unmap()写操作write()完了之后调用的
process_write()也是在process里,它是根据 process_read() 返回的响应来写的,根据结果响应来写
注意写操作write() 是将 buf 和 m_file_address 两部分 分散写入 sockfd 中,
往 buf 和 mfile_address 两部分写内容是在process_write()里写的
读写流程:
- 先整体read(),从sockfd里读内容到buf
- process_read(),从buf里解析内容到对象中
- process_write(), 从对象里解析内容到 buf 和 m_file_address中(分段)整个process_write是根据响应值来写的,是写到了m_iv里
(2、3统称process)
-
write() , 从两个分段内容再写到sockfd里 (真正的给HTTP响应)
(write往socket里写是通过m_iv)
与计时器结合,十五秒之后断开客户端连接
遇到的问题:
(1)两个类有交叉引用时,除了要定义头文件之外,还要定义前向声明
(2)一般来说,一个类里是存另一个类的对象的指针,如果我们要在该类的方法里调用另一个类的方法,我们需要把这个调用函数定义到类外
/*
即使使用了向前定义依旧出错,问题原因:使用向前声明之后,在类定义之前,类是一个不完全类型(incompete type),即已知向前声明过的类是一个类型,但不知道包含哪些成员,所以在使用向前声明后,类定义前,只能定义指向该类型的指针及引用而不能使用该类成员。解决方法:让所有函数都用类外调用,并且放在类的后面即可。
*/
lst_timer.h
定时器类、定时器链表的定义:
#ifndef LST_TIMER
#define LST_TIMER
#include <stdio.h>
#include <time.h>
#include <arpa/inet.h>
#include "../http_conn.h"
#define BUFFER_SIZE 64
class http_conn; //前向声明
/*
即使使用了向前定义依旧出错,问题原因:使用向前声明之后,在类定义之前,
类是一个不完全类型(incompete type),即已知向前声明过的类是一个类型,
但不知道包含哪些成员,所以在使用向前声明后,类定义前,只能定义指向该
类型的指针及引用而不能使用该类成员。解决方法:让所有函数都用类外调用,
并且放在类的后面即可。
*/
// 定时器类
class util_timer {
public:
util_timer() : prev(NULL), next(NULL){}
public:
time_t expire; // 任务超时时间,这里使用绝对时间
//没用这个,直接使用了close_conn()
//void (*cb_func)(http_conn*); // 任务回调函数,回调函数处理的客户数据,由定时器的执行者传递给回调函数
http_conn* user_data;
util_timer* prev; // 指向前一个定时器
util_timer* next; // 指向后一个定时器
};
// 定时器链表,它是一个升序、双向链表,且带有头节点和尾节点。
class sort_timer_lst {
public:
sort_timer_lst() : head( NULL ), tail( NULL ) {}
// 链表被销毁时,删除其中所有的定时器
~sort_timer_lst() {
util_timer* tmp = head;
while( tmp ) {
head = tmp->next;
delete tmp;
tmp = head;
}
}
// 将目标定时器timer添加到链表中
void add_timer( util_timer* timer ) {
if( !timer ) {
return;
}
if( !head ) {
head = tail = timer;
return;
}
/* 如果目标定时器的超时时间小于当前链表中所有定时器的超时时间,则把该定时器插入链表头部,作为链表新的头节点,
否则就需要调用重载函数 add_timer(),把它插入链表中合适的位置,以保证链表的升序特性 */
if( timer->expire < head->expire ) {
timer->next = head;
head->prev = timer;
head = timer;
return;
}
add_timer(timer, head);
}
/* 当某个定时任务发生变化时,调整对应的定时器在链表中的位置。这个函数只考虑被调整的定时器的
超时时间延长的情况,即该定时器需要往链表的尾部移动。*/
void adjust_timer(util_timer* timer)
{
if( !timer ) {
return;
}
util_timer* tmp = timer->next;
// 如果被调整的目标定时器处在链表的尾部,或者该定时器新的超时时间值仍然小于其下一个定时器的超时时间则不用调整
if( !tmp || ( timer->expire < tmp->expire ) ) {
return;
}
// 如果目标定时器是链表的头节点,则将该定时器从链表中取出并重新插入链表
if( timer == head ) {
head = head->next;
head->prev = NULL;
timer->next = NULL;
add_timer( timer, head );
} else {
// 如果目标定时器不是链表的头节点,则将该定时器从链表中取出,然后插入其原来所在位置后的部分链表中
timer->prev->next = timer->next;
timer->next->prev = timer->prev;
add_timer( timer, timer->next );
}
}
// 将目标定时器 timer 从链表中删除
void del_timer( util_timer* timer )
{
if( !timer ) {
return;
}
// 下面这个条件成立表示链表中只有一个定时器,即目标定时器
if( ( timer == head ) && ( timer == tail ) ) {
delete timer;
head = NULL;
tail = NULL;
return;
}
/* 如果链表中至少有两个定时器,且目标定时器是链表的头节点,
则将链表的头节点重置为原头节点的下一个节点,然后删除目标定时器。 */
if( timer == head ) {
head = head->next;
head->prev = NULL;
delete timer;
return;
}
/* 如果链表中至少有两个定时器,且目标定时器是链表的尾节点,
则将链表的尾节点重置为原尾节点的前一个节点,然后删除目标定时器。*/
if( timer == tail ) {
tail = tail->prev;
tail->next = NULL;
delete timer;
return;
}
// 如果目标定时器位于链表的中间,则把它前后的定时器串联起来,然后删除目标定时器
timer->prev->next = timer->next;
timer->next->prev = timer->prev;
delete timer;
}
/* SIGALARM 信号每次被触发就在其信号处理函数中执行一次 tick() 函数,以处理链表上到期任务。*/
void tick();
private:
/* 一个重载的辅助函数,它被公有的 add_timer 函数和 adjust_timer 函数调用
该函数表示将目标定时器 timer 添加到节点 lst_head 之后的部分链表中 */
void add_timer(util_timer* timer, util_timer* lst_head) {
util_timer* prev = lst_head;
util_timer* tmp = prev->next;
/* 遍历 list_head 节点之后的部分链表,直到找到一个超时时间大于目标定时器的超时时间节点
并将目标定时器插入该节点之前 */
while(tmp) {
if( timer->expire < tmp->expire ) {
prev->next = timer;
timer->next = tmp;
tmp->prev = timer;
timer->prev = prev;
break;
}
prev = tmp;
tmp = tmp->next;
}
/* 如果遍历完 lst_head 节点之后的部分链表,仍未找到超时时间大于目标定时器的超时时间的节点,
则将目标定时器插入链表尾部,并把它设置为链表新的尾节点。*/
if( !tmp ) {
prev->next = timer;
timer->prev = prev;
timer->next = NULL;
tail = timer;
}
}
private:
util_timer* head; // 头结点
util_timer* tail; // 尾结点
};
#endif
http_conn.h(里面新增util_timer* timer)
#ifndef HTTPCONNECTION_H
#define HTTPCONNECTION_H
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include "locker.h"
#include <sys/uio.h>
#include "noactive/lst_timer.h"
class util_timer;
class http_conn
{
public:
static const int FILENAME_LEN = 200; // 文件名的最大长度
static const int READ_BUFFER_SIZE = 2048; // 读缓冲区的大小
static const int WRITE_BUFFER_SIZE = 1024; // 写缓冲区的大小
// HTTP请求方法,这里只支持GET
enum METHOD {GET = 0, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT};
/*
解析客户端请求时,主状态机的状态
CHECK_STATE_REQUESTLINE:当前正在分析请求行
CHECK_STATE_HEADER:当前正在分析头部字段
CHECK_STATE_CONTENT:当前正在解析请求体
*/
enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT };
/*
服务器处理HTTP请求的可能结果,报文解析的结果
NO_REQUEST : 请求不完整,需要继续读取客户数据
GET_REQUEST : 表示获得了一个完成的客户请求
BAD_REQUEST : 表示客户请求语法错误
NO_RESOURCE : 表示服务器没有资源
FORBIDDEN_REQUEST : 表示客户对资源没有足够的访问权限
FILE_REQUEST : 文件请求,获取文件成功
INTERNAL_ERROR : 表示服务器内部错误
CLOSED_CONNECTION : 表示客户端已经关闭连接了
*/
enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };
// 从状态机的三种可能状态,即行的读取状态,分别表示
// 1.读取到一个完整的行 2.行出错 3.行数据尚且不完整
enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };
public:
http_conn(){}
~http_conn(){}
public:
void init(int sockfd, const sockaddr_in& addr); // 初始化新接受的连接
void close_conn(); // 关闭连接
void process(); // 处理客户端请求
bool read();// 非阻塞读
bool write();// 非阻塞写
void printt(){
printf("nima\n");
}
private:
void init(); // 初始化连接
HTTP_CODE process_read(); // 解析HTTP请求
bool process_write( HTTP_CODE ret ); // 填充HTTP应答
// 下面这一组函数被process_read调用以分析HTTP请求
HTTP_CODE parse_request_line( char* text );
HTTP_CODE parse_headers( char* text );
HTTP_CODE parse_content( char* text );
HTTP_CODE do_request();
char* get_line() { return m_read_buf + m_start_line; }
LINE_STATUS parse_line();
// 这一组函数被process_write调用以填充HTTP应答。
void unmap();
bool add_response( const char* format, ... );
bool add_content( const char* content );
bool add_content_type();
bool add_status_line( int status, const char* title );
bool add_headers( int content_length );
bool add_content_length( int content_length );
bool add_linger();
bool add_blank_line();
void cb_func();
public:
static int m_epollfd; // 所有socket上的事件都被注册到同一个epoll内核事件中,所以设置成静态的
static int m_user_count; // 统计用户的数量
util_timer* timer; // 定时器
private:
int m_sockfd; // 该HTTP连接的socket和对方的socket地址
sockaddr_in m_address;
char m_read_buf[ READ_BUFFER_SIZE ]; // 读缓冲区
int m_read_idx; // 标识读缓冲区中已经读入的客户端数据的最后一个字节的下一个位置
int m_checked_idx; // 当前正在分析的字符在读缓冲区中的位置
int m_start_line; // 当前正在解析的行的起始位置
CHECK_STATE m_check_state; // 主状态机当前所处的状态
METHOD m_method; // 请求方法
char m_real_file[ FILENAME_LEN ]; // 客户请求的目标文件的完整路径,其内容等于 doc_root + m_url, doc_root是网站根目录
char* m_url; // 客户请求的目标文件的文件名
char* m_version; // HTTP协议版本号,我们仅支持HTTP1.1
char* m_host; // 主机名
int m_content_length; // HTTP请求的消息总长度
bool m_linger; // HTTP请求是否要求保持连接
char m_write_buf[ WRITE_BUFFER_SIZE ]; // 写缓冲区
int m_write_idx; // 写缓冲区中待发送的字节数
char* m_file_address; // 客户请求的目标文件被mmap到内存中的起始位置
struct stat m_file_stat; // 目标文件的状态。通过它我们可以判断文件是否存在、是否为目录、是否可读,并获取文件大小等信息
struct iovec m_iv[2]; // 我们将采用writev来执行写操作,所以定义下面两个成员,其中m_iv_count表示被写内存块的数量。
int m_iv_count;
int bytes_to_send; // 将要发送的数据的字节数
int bytes_have_send; // 已经发送的字节数
};
#endif
http_conn.cpp
#include "http_conn.h"
// 定义HTTP响应的一些状态信息
const char* ok_200_title = "OK";
const char* error_400_title = "Bad Request";
const char* error_400_form = "Your request has bad syntax or is inherently impossible to satisfy.\n";
const char* error_403_title = "Forbidden";
const char* error_403_form = "You do not have permission to get file from this server.\n";
const char* error_404_title = "Not Found";
const char* error_404_form = "The requested file was not found on this server.\n";
const char* error_500_title = "Internal Error";
const char* error_500_form = "There was an unusual problem serving the requested file.\n";
// 网站的根目录
const char* doc_root = "/root/gjcc/webserver/resources";
int setnonblocking( int fd ) {
int old_option = fcntl( fd, F_GETFL );
int new_option = old_option | O_NONBLOCK;
fcntl( fd, F_SETFL, new_option );
return old_option;
}
// 向epoll中添加需要监听的文件描述符
void addfd( int epollfd, int fd, bool one_shot ) {
epoll_event event;
event.data.fd = fd;
// event.events = EPOLLIN | EPOLLET;
//EPOLLRDHUP是对方连接断开,可以在底层去处理,不需要移交给上层 不用通过read/recv判断
//直接通过事件判断
// event.events = EPOLLIN | EPOLLRDHUP;
event.events = EPOLLIN | EPOLLRDHUP;
if(one_shot)
{
// 防止同一个通信被不同的线程处理
event.events |= EPOLLONESHOT;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
// 设置文件描述符非阻塞
setnonblocking(fd);
}
// 从epoll中移除监听的文件描述符
void removefd( int epollfd, int fd ) {
epoll_ctl( epollfd, EPOLL_CTL_DEL, fd, 0 );
close(fd);
}
// 定时器回调函数,它删除非活动连接socket上的注册事件,并关闭之。
void cb_func(http_conn* user_data)
{
user_data->close_conn();
}
// 修改文件描述符,重置socket上的EPOLLONESHOT事件,以确保下一次可读时,EPOLLIN事件能被触发
void modfd(int epollfd, int fd, int ev) {
epoll_event event;
event.data.fd = fd;
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
epoll_ctl( epollfd, EPOLL_CTL_MOD, fd, &event );
}
// 所有的客户数
int http_conn::m_user_count = 0;
// 所有socket上的事件都被注册到同一个epoll内核事件中,所以设置成静态的
int http_conn::m_epollfd = -1;
// 关闭连接
void http_conn::close_conn() {
if(m_sockfd != -1) {
printf("进来了\n");
removefd(m_epollfd, m_sockfd);
m_user_count--; // 关闭一个连接,将客户总数量-1
printf( "close fd %d\n", m_sockfd );
m_sockfd = -1;
}
}
// 初始化连接,外部调用初始化套接字地址
void http_conn::init(int sockfd, const sockaddr_in& addr){
m_sockfd = sockfd;
m_address = addr;
// 端口复用
int reuse = 1;
setsockopt( m_sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof( reuse ) );
addfd( m_epollfd, sockfd, true );
m_user_count++;
init();
}
void http_conn::init()
{
bytes_to_send = 0;
bytes_have_send = 0;
m_check_state = CHECK_STATE_REQUESTLINE; // 初始状态为检查请求行
m_linger = false; // 默认不保持链接 Connection : keep-alive保持连接
m_method = GET; // 默认请求方式为GET
m_url = 0;
m_version = 0;
m_content_length = 0;
m_host = 0;
m_start_line = 0;
m_checked_idx = 0;
m_read_idx = 0;
m_write_idx = 0;
bzero(m_read_buf, READ_BUFFER_SIZE);
bzero(m_write_buf, READ_BUFFER_SIZE);
bzero(m_real_file, FILENAME_LEN);
}
// 循环读取客户数据,直到无数据可读或者对方关闭连接
bool http_conn::read() {
if( m_read_idx >= READ_BUFFER_SIZE ) {
return false;
}
int bytes_read = 0;
while(true) {
// 从m_read_buf + m_read_idx索引出开始保存数据,大小是READ_BUFFER_SIZE - m_read_idx
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx,
READ_BUFFER_SIZE - m_read_idx, 0 );
if (bytes_read == -1) {
if( errno == EAGAIN || errno == EWOULDBLOCK ) {
// 没有数据
break;
}
return false;
} else if (bytes_read == 0) { // 对方关闭连接
return false;
}
m_read_idx += bytes_read;
}
return true;
}
// 解析一行,判断依据\r\n
http_conn::LINE_STATUS http_conn::parse_line() {
char temp;
for ( ; m_checked_idx < m_read_idx; ++m_checked_idx ) {
temp = m_read_buf[ m_checked_idx ];
if ( temp == '\r' ) {
if ( ( m_checked_idx + 1 ) == m_read_idx ) {
return LINE_OPEN;
} else if ( m_read_buf[ m_checked_idx + 1 ] == '\n' ) {
//把\r和\n都变成\0, 并且把index放到了下一行
m_read_buf[ m_checked_idx++ ] = '\0';
m_read_buf[ m_checked_idx++ ] = '\0';
return LINE_OK;
}
return LINE_BAD;
} else if( temp == '\n' ) {
//为什么要单独再判断一次'\n'?之前的不是应该已经处理了?
//如果上一次是读到'\r'就读完了,(m_checked_index + 1) == m_read_index
//它就没处理,那么下次从\n开始读,就要把之前的处理一下
if( ( m_checked_idx > 1) && ( m_read_buf[ m_checked_idx - 1 ] == '\r' ) ) {
m_read_buf[ m_checked_idx-1 ] = '\0';
m_read_buf[ m_checked_idx++ ] = '\0';
return LINE_OK;
}
return LINE_BAD;
}
}
return LINE_OPEN;
}
// 解析HTTP请求行,获得请求方法,目标URL,以及HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char* text) {
// GET /index.html HTTP/1.1
m_url = strpbrk(text, " \t"); // 判断第二个参数中的字符哪个在text中最先出现
if (! m_url) {
return BAD_REQUEST;
}
// GET\0/index.html HTTP/1.1
*m_url++ = '\0'; // 置位空字符,字符串结束符
char* method = text;
if ( strcasecmp(method, "GET") == 0 ) { // 忽略大小写比较
m_method = GET;
} else {
return BAD_REQUEST;
}
// /index.html HTTP/1.1
// 检索字符串 str1 中第一个不在字符串 str2 中出现的字符下标。
m_version = strpbrk( m_url, " \t" );
if (!m_version) {
return BAD_REQUEST;
}
*m_version++ = '\0';
if (strcasecmp( m_version, "HTTP/1.1") != 0 ) {
return BAD_REQUEST;
}
/**
* http://192.168.110.129:10000/index.html
*/
if (strncasecmp(m_url, "http://", 7) == 0 ) {
m_url += 7;
// 在参数 str 所指向的字符串中搜索第一次出现字符 c(一个无符号字符)的位置。
m_url = strchr( m_url, '/' );
}
if ( !m_url || m_url[0] != '/' ) {
return BAD_REQUEST;
}
m_check_state = CHECK_STATE_HEADER; // 检查状态变成检查头
return NO_REQUEST;
}
// 解析HTTP请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char* text) {
// 遇到空行,表示头部字段解析完毕
if( text[0] == '\0' ) {
// 如果HTTP请求有消息体,则还需要读取m_content_length字节的消息体,
// 状态机转移到CHECK_STATE_CONTENT状态
if ( m_content_length != 0 ) {
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
// 否则说明我们已经得到了一个完整的HTTP请求
return GET_REQUEST;
} else if ( strncasecmp( text, "Connection:", 11 ) == 0 ) {
// 处理Connection 头部字段 Connection: keep-alive
text += 11;
text += strspn( text, " \t" );
if ( strcasecmp( text, "keep-alive" ) == 0 ) {
m_linger = true;
}
} else if ( strncasecmp( text, "Content-Length:", 15 ) == 0 ) {
// 处理Content-Length头部字段
text += 15;
text += strspn( text, " \t" );
m_content_length = atol(text);
} else if ( strncasecmp( text, "Host:", 5 ) == 0 ) {
// 处理Host头部字段
text += 5;
text += strspn( text, " \t" );
m_host = text;
} else {
printf( "oop! unknow header %s\n", text );
}
return NO_REQUEST;
}
// 我们没有真正解析HTTP请求的消息体,只是判断它是否被完整的读入了
http_conn::HTTP_CODE http_conn::parse_content( char* text ) {
if ( m_read_idx >= ( m_content_length + m_checked_idx ) )
{
text[ m_content_length ] = '\0';
return GET_REQUEST;
}
return NO_REQUEST;
}
// 主状态机,解析请求
http_conn::HTTP_CODE http_conn::process_read() {
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char* text = 0;
//主状态机是解析请求体且当前从状态机一行的数据是OK的
//或者解析的一行数据是LINE_OK
while (((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK))
|| ((line_status = parse_line()) == LINE_OK)) {
// 获取一行数据
text = get_line();
// 更新start_line的状态
m_start_line = m_checked_idx;
printf( "got 1 http line: %s\n", text );
switch ( m_check_state ) {
case CHECK_STATE_REQUESTLINE: {
ret = parse_request_line( text );
if ( ret == BAD_REQUEST ) {
return BAD_REQUEST;
}
break;
}
case CHECK_STATE_HEADER: {
ret = parse_headers( text );
if ( ret == BAD_REQUEST ) {
return BAD_REQUEST;
} else if ( ret == GET_REQUEST ) {
//请求完了整个请求头,下面遇到换行了,就认为请求完了,不管下面还有没有请求体
return do_request();
}
break;
}
case CHECK_STATE_CONTENT: {
ret = parse_content( text );
if ( ret == GET_REQUEST ) {
return do_request();
}
//失败了
line_status = LINE_OPEN;//状态改编为尚不完整
break;
}
default: {
return INTERNAL_ERROR;
}
}
}
return NO_REQUEST;
}
// 两种do_request的调用方式, 请求头处理完发现没有请求体,直接调用
// 还有处理完请求体调用
// 当得到一个完整、正确的HTTP请求时,我们就分析目标文件的属性,
// 如果目标文件存在、对所有用户可读,且不是目录,则使用mmap将其
// 映射到内存地址m_file_address处,并告诉调用者获取文件成功
// 要把数据写给客户端(获取文件)
http_conn::HTTP_CODE http_conn::do_request()
{
// "/root/gjcc/Web_Server/resources"
// doc_root就是资源的路径,项目的根目录(例如网站项目,它根目录就是resource)
strcpy( m_real_file, doc_root );
int len = strlen( doc_root );
// 拼接后得到真实的文件:/root/gjcc/Web_Server/resources/index.html
strncpy( m_real_file + len, m_url, FILENAME_LEN - len - 1 );
// 获取m_real_file文件的相关的状态信息,-1失败,0成功
if ( stat( m_real_file, &m_file_stat ) < 0 ) {
return NO_RESOURCE;
}
// 判断访问权限
if ( ! ( m_file_stat.st_mode & S_IROTH ) ) {
return FORBIDDEN_REQUEST;
}
// 判断是否是目录
if ( S_ISDIR( m_file_stat.st_mode ) ) {
return BAD_REQUEST;
}
// 以只读方式打开文件
int fd = open( m_real_file, O_RDONLY );
// 创建内存映射
// 把文件映射到内存当中, 地址就是我们要发送的资源(网页数据)
// 将来写的时候,是要将这快内存的数据发送给客户端
m_file_address = ( char* )mmap( 0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0 );
close( fd );
//表示已经获取到了这个文件
return FILE_REQUEST;
}
// 对内存映射区执行munmap操作(使用完了内存映射后释放)
void http_conn::unmap() {
if( m_file_address )
{
munmap( m_file_address, m_file_stat.st_size );
m_file_address = 0;
}
}
// 写HTTP响应
bool http_conn::write()
{
int temp = 0;
if ( bytes_to_send == 0 ) {
// 将要发送的字节为0,这一次响应结束。
modfd( m_epollfd, m_sockfd, EPOLLIN );
init();
return true;
}
while(1) {
// 分散写
temp = writev(m_sockfd, m_iv, m_iv_count);
if ( temp <= -1 ) {
// 如果TCP写缓冲没有空间,则等待下一轮EPOLLOUT事件,虽然在此期间,
// 服务器无法立即接收到同一客户的下一个请求,但可以保证连接的完整性。
if( errno == EAGAIN ) {
modfd( m_epollfd, m_sockfd, EPOLLOUT );
return true;
}
unmap();
return false;
}
bytes_have_send += temp;
bytes_to_send -= temp;
if (bytes_have_send >= m_iv[0].iov_len)
{
m_iv[0].iov_len = 0;
m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx);
m_iv[1].iov_len = bytes_to_send;
}
else
{
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - temp;
}
if (bytes_to_send <= 0)
{
// 没有数据要发送了
unmap();
modfd(m_epollfd, m_sockfd, EPOLLIN);
if (m_linger)
{
init();
return true;
}
else
{
return false;
}
}
}
}
// 往写缓冲中写入待发送的数据
bool http_conn::add_response( const char* format, ... ) {
if( m_write_idx >= WRITE_BUFFER_SIZE ) {
return false;
}
va_list arg_list;
va_start( arg_list, format );
int len = vsnprintf( m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list );
if( len >= ( WRITE_BUFFER_SIZE - 1 - m_write_idx ) ) {
return false;
}
m_write_idx += len;
va_end( arg_list );
return true;
}
bool http_conn::add_status_line( int status, const char* title ) {
return add_response( "%s %d %s\r\n", "HTTP/1.1", status, title );
}
bool http_conn::add_headers(int content_len) {
add_content_length(content_len);
add_content_type();
add_linger();
add_blank_line();
}
bool http_conn::add_content_length(int content_len) {
return add_response( "Content-Length: %d\r\n", content_len );
}
bool http_conn::add_linger()
{
return add_response( "Connection: %s\r\n", ( m_linger == true ) ? "keep-alive" : "close" );
}
bool http_conn::add_blank_line()
{
return add_response( "%s", "\r\n" );
}
bool http_conn::add_content( const char* content )
{
return add_response( "%s", content );
}
bool http_conn::add_content_type() {
return add_response("Content-Type:%s\r\n", "text/html");
}
// 根据服务器处理HTTP请求的结果,决定返回给客户端的内容
bool http_conn::process_write(HTTP_CODE ret) {
switch (ret)
{
case INTERNAL_ERROR:
add_status_line( 500, error_500_title );
add_headers( strlen( error_500_form ) );
if ( ! add_content( error_500_form ) ) {
return false;
}
break;
case BAD_REQUEST:
add_status_line( 400, error_400_title );
add_headers( strlen( error_400_form ) );
if ( ! add_content( error_400_form ) ) {
return false;
}
break;
case NO_RESOURCE:
add_status_line( 404, error_404_title );
add_headers( strlen( error_404_form ) );
if ( ! add_content( error_404_form ) ) {
return false;
}
break;
case FORBIDDEN_REQUEST:
add_status_line( 403, error_403_title );
add_headers(strlen( error_403_form));
if ( ! add_content( error_403_form ) ) {
return false;
}
break;
case FILE_REQUEST:
add_status_line(200, ok_200_title );
add_headers(m_file_stat.st_size);
m_iv[ 0 ].iov_base = m_write_buf;
m_iv[ 0 ].iov_len = m_write_idx;
m_iv[ 1 ].iov_base = m_file_address;
m_iv[ 1 ].iov_len = m_file_stat.st_size;
m_iv_count = 2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
default:
return false;
}
m_iv[ 0 ].iov_base = m_write_buf;
m_iv[ 0 ].iov_len = m_write_idx;
m_iv_count = 1;
bytes_to_send = m_write_idx;
return true;
}
// 由线程池中的工作线程调用,这是处理HTTP请求的入口函数
// 已经读入了,在process里调用process_read
void http_conn::process() {
// 解析HTTP请求
HTTP_CODE read_ret = process_read();
if ( read_ret == NO_REQUEST ) {
//请求不完整,继续监听读事件
modfd( m_epollfd, m_sockfd, EPOLLIN );
return;
}
// 生成响应(要根据结果去响应)
bool write_ret = process_write( read_ret );
if ( !write_ret ) {
close_conn();
}
modfd( m_epollfd, m_sockfd, EPOLLOUT);
}
main.cpp
主要思想:设置SIGALRM信号处理函数, 设置一个定时器, 到期处理函数就往pipefd[1]里面写,epoll_wait就会由于pipefd[0]可以读而触发, 再设置timeout为true, 调用tick()函数删除非活跃连接, 然后再设置一个定时器. 以此重复.
tips:
//遍历信号:除了SIGALRM外还有SIGTERM信号
//因为可能会有别的信号,所以要遍历,并不是因为一个信号在里面很多个
//一个信号出现,只会调用回调函数往里面写一个
//等下次再调用信号,还是往里面再写一个
//产生一个ALRM信号,所有线程的时间检查一遍
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include "locker.h"
#include "threadpool.h"
#include "http_conn.h"
#include "noactive/lst_timer.h"
#define MAX_FD 65536 // 最大的文件描述符个数
#define MAX_EVENT_NUMBER 10000 // 监听的最大的事件数量
#define TIMESLOT 5 //每隔5秒检测一次
static int pipefd[2];
static sort_timer_lst timer_lst;
/*
设置SIGALRM信号处理函数, 设置一个定时器, 到期处理函数就往pipefd[1]里面写,
epoll_wait就会由于pipefd[0]可以读而触发, 再设置timeout为true, 调用tick()
函数删除非活跃连接, 然后再设置一个定时器. 以此重复.
*/
void sort_timer_lst::tick() {
if( !head ) {
return;
}
printf( "timer tick\n" );
time_t cur = time( NULL ); // 获取当前系统时间
util_timer* tmp = head;
// 从头节点开始依次处理每个定时器,直到遇到一个尚未到期的定时器
while( tmp ) {
/* 因为每个定时器都使用绝对时间作为超时值,所以可以把定时器的超时值和系统当前时间,
比较以判断定时器是否到期*/
// 这个节点都没超时,后面的更不会超时,直接break
// tmp->user_data->printt();
if( cur < tmp->expire ) {
break;
}
// 如果超时了
// 调用定时器的回调函数,以执行定时任务
// tmp->cb_func( tmp->user_data );
tmp->user_data->close_conn();
// 执行完定时器中的定时任务之后,就将它从链表中删除,并重置链表头节点
head = tmp->next;
if( head ) {
head->prev = NULL;
}
delete tmp;
tmp = head;
}
}
//发送信号到管道里面
//pipefd[1]是写、pipefd[0]是读
void sig_handler( int sig )
{
int save_errno = errno;
int msg = sig;
// printf("发送信号!!!!!!!\n\n");
send( pipefd[1], ( char* )&msg, 1, 0 );
errno = save_errno;
}
void addsig_time( int sig )
{
struct sigaction sa;
memset( &sa, '\0', sizeof( sa ) );
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset( &sa.sa_mask );
assert( sigaction( sig, &sa, NULL ) != -1 );
}
void timer_handler()
{
// 定时处理任务,实际上就是调用tick()函数
timer_lst.tick();
// 因为一次 alarm 调用只会引起一次SIGALARM 信号,所以我们要重新定时,以不断触发 SIGALARM信号。
// 再次alarm以达到循环的效果 循环5秒一次ALRM
alarm(TIMESLOT);
}
// 添加文件描述符
extern void addfd( int epollfd, int fd, bool one_shot );
extern void removefd( int epollfd, int fd );
extern int setnonblocking( int fd );
void addsig(int sig, void( handler )(int)){
struct sigaction sa;
memset( &sa, '\0', sizeof( sa ) );
sa.sa_handler = handler;
//信号集 sa_mask 是在执行信号处理程序时被阻塞的信号集。把阻塞信号集都置为了1
//只有通过sigprocmask才能改变内核当中的信号集
//临时阻塞信号集,在信号捕捉函数执行过程中,临时阻塞某些信号。执行完了就不阻塞了
sigfillset( &sa.sa_mask );
//sigaction 信号捕捉函数
assert( sigaction( sig, &sa, NULL ) != -1 );
}
int main( int argc, char* argv[] ) {
if( argc <= 1 ) {
printf( "usage: %s port_number\n", basename(argv[0]));
return 1;
}
int port = atoi( argv[1] );
//一端断开连接了,另一方还在写,会产生信号SIGPIPE
//对SIGPIPE进行处理
//遇到SIGPIPE忽略(默认是终止的)
addsig( SIGPIPE, SIG_IGN );
threadpool< http_conn >* pool = NULL;
try {
pool = new threadpool<http_conn>;
} catch( ... ) {
return 1;
}
http_conn* users = new http_conn[ MAX_FD ];
int listenfd = socket( PF_INET, SOCK_STREAM, 0 );
int ret = 0;
struct sockaddr_in address;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_family = AF_INET;
address.sin_port = htons( port );
// 端口复用
//在!!绑定前!!设置端口复用
//socket端口复用
//主要用于服务端绑定固定端口,防止端口被占用或者没有释放时绑定失败。
//端口仍被占用(因端口上有处于TIME_WAIT的连接)。
int reuse = 1;
setsockopt( listenfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof( reuse ) );
ret = bind( listenfd, ( struct sockaddr* )&address, sizeof( address ) );
ret = listen( listenfd, 5 );
// 创建epoll对象,和事件数组,添加
epoll_event events[ MAX_EVENT_NUMBER ];
int epollfd = epoll_create( 5 );
// 添加到epoll对象中
//listenfd不需要添加oneshot事件,因为它是监听的文件描述符
addfd( epollfd, listenfd, false );
http_conn::m_epollfd = epollfd;
// 创建管道
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert( ret != -1 );
setnonblocking( pipefd[1] );
//监听读的一端
addfd( epollfd, pipefd[0], false);
// 设置信号处理函数
addsig_time( SIGALRM );
addsig_time( SIGTERM );
bool timeout = false;
bool stop_server = false;
alarm(TIMESLOT);
while(!stop_server) {
int number = epoll_wait( epollfd, events, MAX_EVENT_NUMBER, -1 );
//为什么判断EINTR?产生信号以后它就中断,回来后不阻塞了,所以它返回的-1
//在这种情况下是没有错误的
if ( ( number < 0 ) && ( errno != EINTR ) ) {
printf( "epoll failure\n" );
break;
}
for ( int i = 0; i < number; i++ ) {
int sockfd = events[i].data.fd;
util_timer* timer = users[sockfd].timer;
if( sockfd == listenfd ) {
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof( client_address );
int connfd = accept( listenfd, ( struct sockaddr* )&client_address, &client_addrlength );
if ( connfd < 0 ) {
printf( "errno is: %d\n", errno );
continue;
}
if( http_conn::m_user_count >= MAX_FD ) {
//目前连接数满了, 回写数据给客户端(服务器内部正忙)
close(connfd);
continue;
}
users[connfd].init( connfd, client_address);
// 创建定时器,设置其回调函数与超时时间,然后绑定定时器与用户数据,最后将定时器添加到链表timer_lst中
util_timer* timer = new util_timer;
timer->user_data = &users[connfd];
time_t cur = time( NULL );
//超时时间:从当前时间开始,过15秒没有收发数据就会清除掉
timer->expire = cur + 3 * TIMESLOT;
users[connfd].timer = timer;
//把当前定时器放在链表里
timer_lst.add_timer( timer );
} else if( events[i].events & ( EPOLLRDHUP | EPOLLHUP | EPOLLERR ) ) {
//对方异常断开或者错误等事件发生
//关闭连接
printf("1\n");
users[sockfd].close_conn();
if(timer)
{
timer_lst.del_timer( timer );
}
} else if(events[i].events & EPOLLIN) {
if(users[sockfd].read()) {
if( timer ) {
time_t cur = time( NULL );
// 有数据到达了, 更新超时时间并改变位置
timer->expire = cur + 3 * TIMESLOT;
printf( "adjust timer once\n" );
timer_lst.adjust_timer( timer );
}
pool->append(users + sockfd);
} else {
//因为我们想让他15秒后自动关闭,而不是说只要没数据读进来就立即关闭,
//因此这里全注释掉
// printf("2\n");
// users[sockfd].close_conn();
// if(timer)
// {
// timer_lst.del_timer( timer );
// }
}
} else if( events[i].events & EPOLLOUT ) {
if( !users[sockfd].write() ) {
printf("3\n");
users[sockfd].close_conn();
if(timer)
{
timer_lst.del_timer( timer );
}
}
}
if( ( sockfd == pipefd[0] ) && ( events[i].events & EPOLLIN ) ) {
// 管道里有数据了
// 处理信号
int sig;
char signals[1024];
ret = recv( pipefd[0], signals, sizeof( signals ), 0 );
if( ret == -1 ) {
continue;
} else if( ret == 0 ) {
continue;
} else {
//遍历信号:除了SIGALRM外还有SIGTERM信号
//因为可能会有别的信号,所以要遍历,并不是因为一个信号在里面很多个
//一个信号出现,只会调用回调函数往里面写一个
//等下次再调用信号,还是往里面再写一个
//产生一个ALRM信号,所有线程的时间检查一遍
for( int i = 0; i < ret; ++i ) {
switch( signals[i] ) {
case SIGALRM: //每5秒钟检测一下哪些是超时的
{
// 用timeout变量标记有定时任务需要处理,但不立即处理定时任务
// 这是因为定时任务的优先级不是很高,我们优先处理其他更重要的任务。
// 不是立即处理定时任务,因为IO操作的优先级更高,先处理IO
timeout = true;
break;
}
case SIGTERM:
{
stop_server = true;
}
}
}
}
}
}
//最后处理定时事件,因为I/O事件有更高的优先级。当然,这样做将导致定时任务不能精准的按照预定的时间执行。
if( timeout ) {
timer_handler();
timeout = false;
}
}
close( epollfd );
close( listenfd );
delete [] users;
delete pool;
close( pipefd[1] );
close( pipefd[0] );
return 0;
}














 4083
4083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









