







- 环境说明
- 系统:centos 6.5
- hadoop:2.7.1
- JDK:1.7
- 虚拟机3台(1台 namenode;2台 datanode)
- 环境准备(可选)
准备了3台虚拟机,1台 namenode,叫 master;2台 datanode,分别叫 slave1 和 slave2。
- 修改主机名称
命令:vi /etc/sysconfig/network,修改 HOSTNAME=master(其他两台机器请自行修改成 slave1 和 slave2)。 - IP 与主机名映射
命令:vi /etc/hosts,增加3行:
192.168.182.128 master
192.168.182.129 slave1
192.168.182.130 slave2
注:其中的 ip 为 主机名对应机器的ip(ip使用 ifconfig 命令查看)。
其他两台机器,做相同修改。 - 增加组、用户
– groupadd hadoopGrp #增加组
– useradd hadoop -g hadoopGrp #增加用户 hadoop,并将用户分配到组 hadoopGrp 中
– passwd hadoop #修改用户登录密码
其他两台机器,做相同修改。 - 创建文件夹 files,并将 hadoop 和 jdk 通过 ftp 上传到该目录下
## 请退出 root 用户,用 hadoop 用户登录
– mkdir files
– 请自行通过 ftp 工具,将文件上传到该目录下
其他两台机器,做相同修改(或使用 scp 命令直接传输文件)。 - 安装 JDK
– su - root ## 切换 root 用户
– [root@master ~]# rpm -ivh /home/hadoop/files/jdk-7u80-linux-x64.rpm ##安装 jdk
Preparing… ########################################### [100%]
1:jdk ########################################### [100%]
Unpacking JAR files…
rt.jar…
jsse.jar…
charsets.jar…
tools.jar…
localedata.jar…
jfxrt.jar…
– [root@master source]# rpm -ql jdk ## 查看 jdk 安装路径
…….
/usr/java/jdk1.7.0_80/src.zip - 配置环境变量
– [root@master ~]# vi /etc/profile ##在文件最后增加 2 行,jdk 的目录是上面你自己机器加粗的部分。
JAVA_HOME=/usr/java/jdk1.7.0_80
export JAVA_HOME
– [root@master ~]# source /etc/profile
– [root@master ~]# echo $JAVA_HOME
其他两台机器做相同修改。
- 修改主机名称
- hadoop 配置
- 免密码登录
## hadoop 用户
[hadoop@master ~] $ ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa
[hadoop@master ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~]$ chmod 0600 ~/.ssh/authorized_keys ## 这步特别重要,否则不能免密码登录 - 创建 .ssh 文件夹
## hadoop 用户,在 slave1 和 slave2 机器上创建
– [hadoop@slave1 ~]$ mkdir /home/hadoop/.ssh
– [hadoop@slave2 ~]$ mkdir /home/hadoop/.ssh - 复制 master 公开密码,到 slave1 和 slave2 机器上
–[hadoop@master .ssh]$ scp ./authorized_keys hadoop@slave1:~/.ssh/
hadoop@slave1’s password:
authorized_keys
–[hadoop@master .ssh]$ scp ./authorized_keys hadoop@slave2:~/.ssh/
hadoop@slave1’s password:
authorized_keys
- 免密码登录
- 解压 hadoop 文件
## hadoop 用户
– [hadoop@master ~]$ cd /home/hadoop/files/
– [hadoop@master source]$ tar -xvf hadoop-2.7.1.tar.gz
– [hadoop@master source]$ mv hadoop-2.7.1 hadoop
其他两台机器做相同操作。 - 配置 namenoe 地址
## hadoop 用户
– [hadoop@master hadoop]$ vi /home/hadoop/files/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>– [hadoop@master hadoop]$ scp /home/hadoop/files/hadoop/etc/hadoop/core-site.xml hadoop@slave1:/home/hadoop/files/hadoop/etc/hadoop/
– [hadoop@master hadoop]$ scp /home/hadoop/files/hadoop/etc/hadoop/core-site.xml hadoop@slave2:/home/hadoop/files/hadoop/etc/hadoop/
- 设置 namenode 和 datanode 目录
– [hadoop@master hadoop]$ vi /home/hadoop/files/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/files/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/files/hadoop/data/datanode</value>
</property>
</configuration>配置 slave 机器
– [hadoop@master hadoop]$ vi etc/hadoop/slaves #增加两行
slave1
slave2配置 JAVA_HOME
– [hadoop@master hadoop]$ vi etc/hadoop/hadoop-env.sh #修改成以下内容,大约在文件 25 行
export JAVA_HOME=/usr/java/jdk1.7.0_80 ## 配置成自己机器的 jdk 安装路径
其他两台机器做相同操作。格式化 namenode
– [hadoop@master hadoop]$ /home/hadoop/files/hadoop/bin/hdfs namenode -format
– 启动 namenode
– [hadoop@master hadoop]$ /home/hadoop/files/hadoop/sbin/start-dfs.sh- 查看 namenode
– 浏览器访问: http://192.168.182.128:50070/ #192.168.182.128 为 master 机器的 ip
上面的地址可能访问不了,因为 linux 的端口没有开放。此处为了方便,只能关闭了防火墙。
## root 用户
- [root@master ~]# /etc/init.d/iptables stop #上面的地址就可以了
## 可以看到 namenode 里有两个 datanode,分别叫 slave1 和 slave2
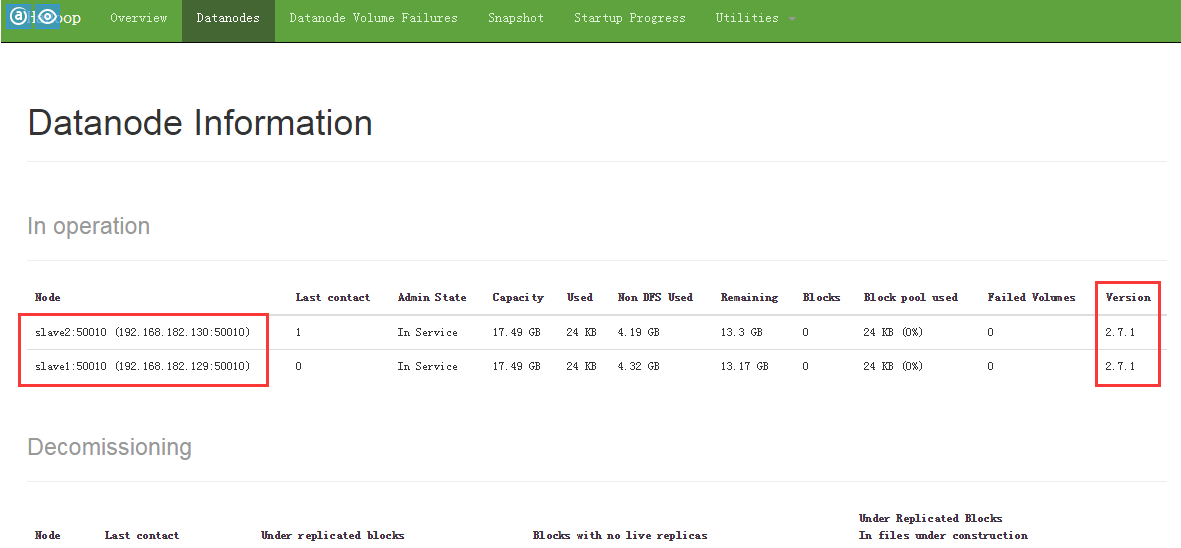
此时, hadoop 的环境就已经搭好了。
- 停止 namenode
– [hadoop@master hadoop]$ /home/hadoop/files/hadoop/sbin/stop-dfs.sh
因为怕读者不知道当前目录的位置,固采用绝对路径。如果读者清楚当前路径,采用相对路径即可。















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









