







创建项目
scrapy startproject {name}


创建一个子目录scrapyname 并包含一些基本文件
- *item 定义爬取对象,字段
- middlewares 包含cookies 代理ip等的设置的中间件
- piplines 返回item类型对象后再piplines对item数据处理
- setting 日志级别,是否遵守robots协议等一些参数的设置
- spider目录 里面存放具体的爬虫请求内容 可以有多个*
创建spider请求
进入scrapy项目
scrapy genspider {name爬虫名称} {domain目标域名}

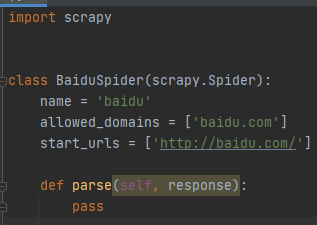
- name 即spider的名称 用于启动spider
- allowed_domains spider所有的请求都只能在这个域名范围内 与name一样都是创建spider的时候设置的
- start_urls 启动spider的时候 首先请求的url
- parse() spider在请求start_urls后会执行parse response参数即是响应内容 可用xpath text等提取响应内容
启动spider
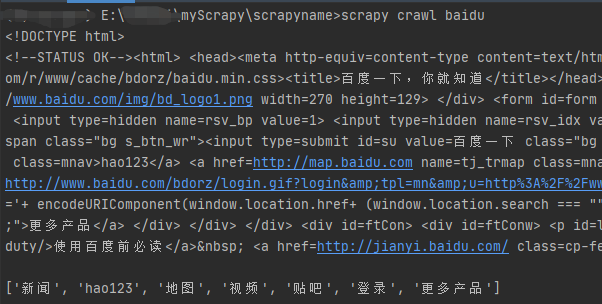
修改parse方法 打印响应html内容 并修改setting robots协议


启动

结果














 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









