







先介绍下我们的druid集群配置
Overload 1台
Coordinator 1台
Middle manager 3台
Broker 3台
Historical一共12台,其中cold 6台,hot 6台
druid版本:0.10, 0.9之后即可支持Kafka indexing service
目前的druid主要用来做批量灌入,包括天级,小时级,五分钟级
由于这个五分钟是一个小时前的五分钟,实时性不能满足需求,无法指导广告主实时投放
需要引入分钟级的实时数据,即广告主在投放一分钟之后就能看到投放的展现点击等指标数据,从而指导广告主投放
业务维度字段主要有
uid campaign_id plan_id mid posid
指标字段主要有
impressions clicks installs revenue
由于transqulity有数据丢失风险,所以我们拟采用kafka indexing service
1.打开druid的extensions目录,这个插件已经自带
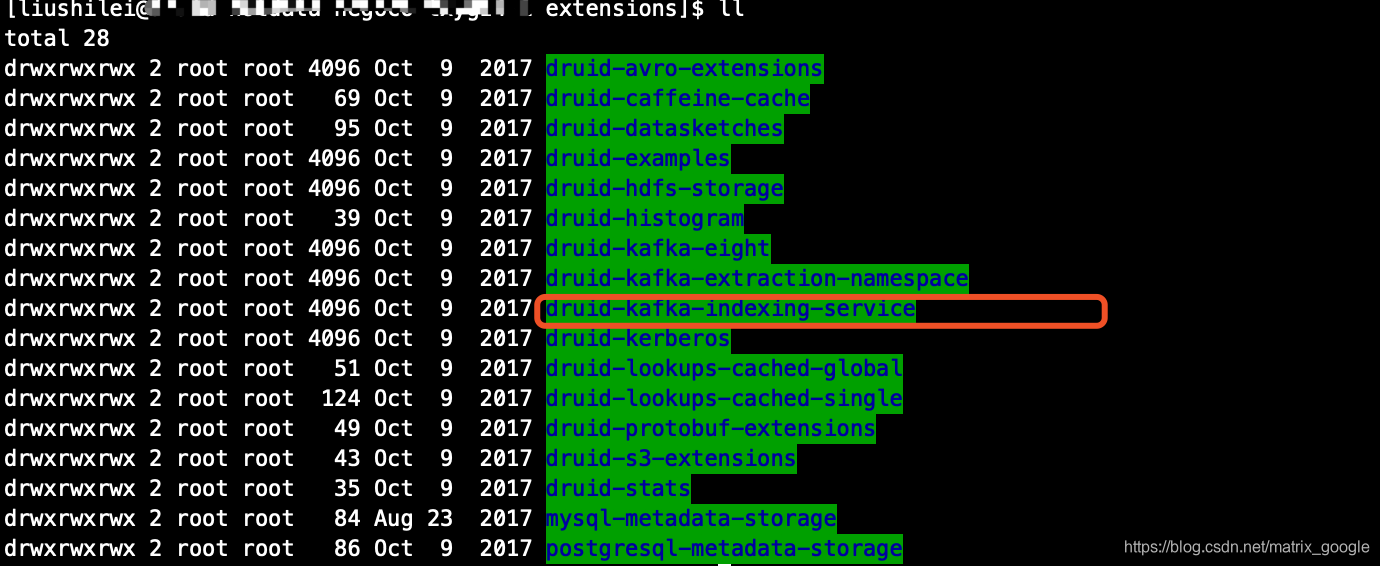
2.在overload和middleManager上配置loadList,注意overload节点和middleManager节点都要配置,其他节点不需要
名称千万不能写错 "druid-kafka-indexing-service"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









