






笔者最近在做物联网项目。需要使用 dataX 将数据从 Cassandra 迁移到阿里云 Lindorm 的时序数据库里。
一、脚本准备
Cassandra 的表结构如下:
CREATE KEYSPACE IF NOT EXISTS thingsboard
WITH replication = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
CREATE TABLE IF NOT EXISTS thingsboard.ts_kv_cf (
entity_type text, // (DEVICE, CUSTOMER, TENANT)
entity_id timeuuid,
key text,
partition bigint,
ts bigint,
bool_v boolean,
str_v text,
long_v bigint,
dbl_v double,
json_v text,
PRIMARY KEY (( entity_type, entity_id, key, partition ), ts)
);Lindorm 时序引擎的表结构如下:
CREATE TABLE ts_kv (entity_type VARCHAR TAG,entity_id VARCHAR TAG,key VARCHAR TAG,`partition` VARCHAR TAG,time BIGINT,bool_v BOOLEAN,dbl_v DOUBLE,json_v VARCHAR,long_v BIGINT,str_v VARCHAR,PRIMARY KEY(entity_type,entity_id,key,`partition`));dataX job 脚本如下:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "cassandrareader",
"parameter": {
"host": "localhost",
"port": 9042,
"username": "",
"password": "",
"useSSL": false,
"consistancyLevel": "LOCAL_ONE",
"timeout": 600000,
"fetchsize": 1,
"keyspace": "thingsboard",
"table": "ts_kv_cf",
"column": [
"entity_type",
"entity_id",
"key",
"partition",
"ts",
"bool_v",
"dbl_v",
"str_v",
"long_v",
"json_v"
],
"where": ""
}
},
"writer": {
"name": "tsdbwriter",
"parameter": {
"column": [
"entity_type",
"entity_id",
"key",
"partition",
"time",
"bool_v",
"dbl_v",
"str_v",
"long_v",
"json_v"
],
"columnType": [
"tag",
"tag",
"tag",
"tag",
"timestamp",
"field_boolean",
"field_double",
"field_string",
"field_long",
"field_string"
],
"sourceDbType": "RDB",
"endpoint": "http://xxxxxxxx:8242",
"table": "ts_kv",
"multiField": "true",
"username":"",
"password":"",
"ignoreWriteError":"false",
"database":"default"
}
}
}
]
}
} 二、field_long 类型
当我用 dataX 尝试第一次导入的时候,报了一个这个错:
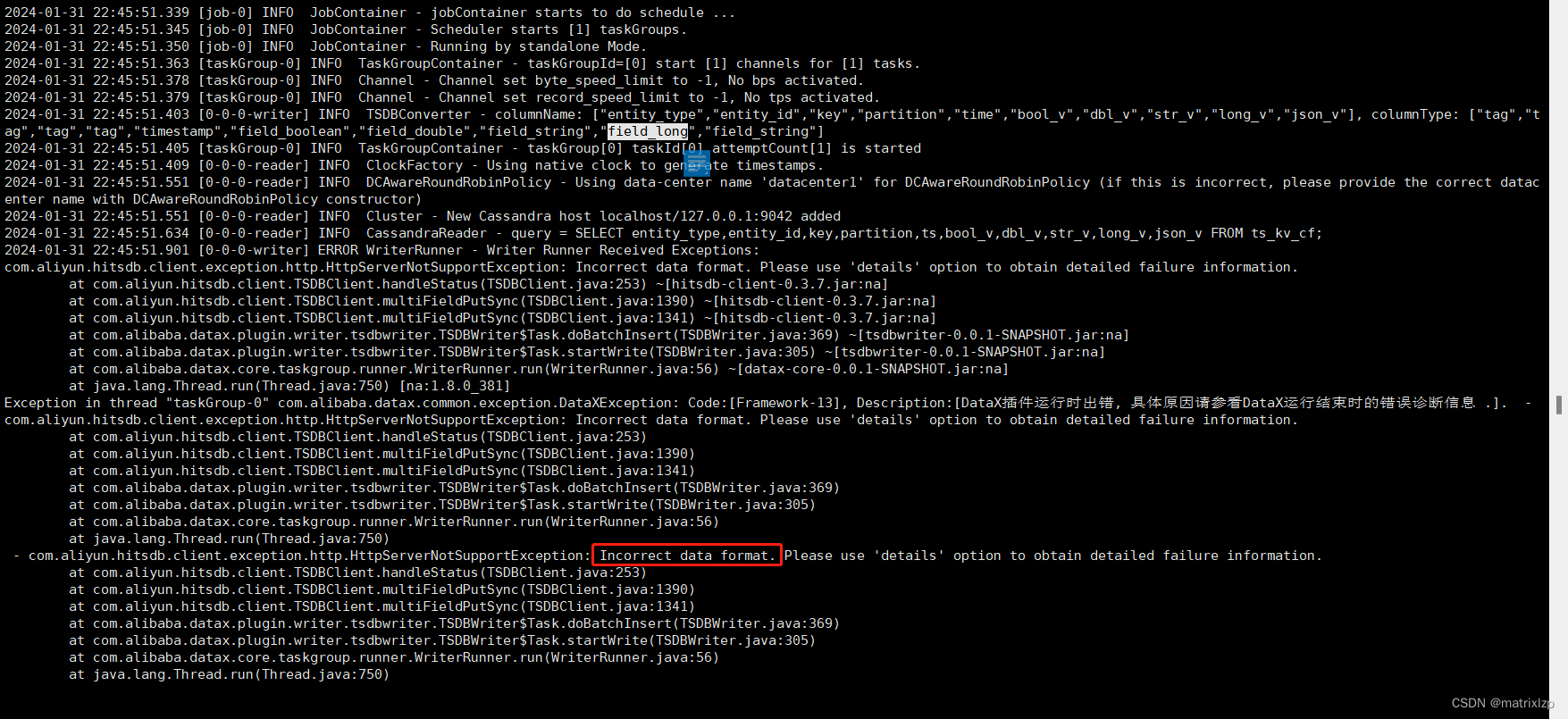
问题的原因,是 dataX 官网,现在还不支持 field_long 类型。
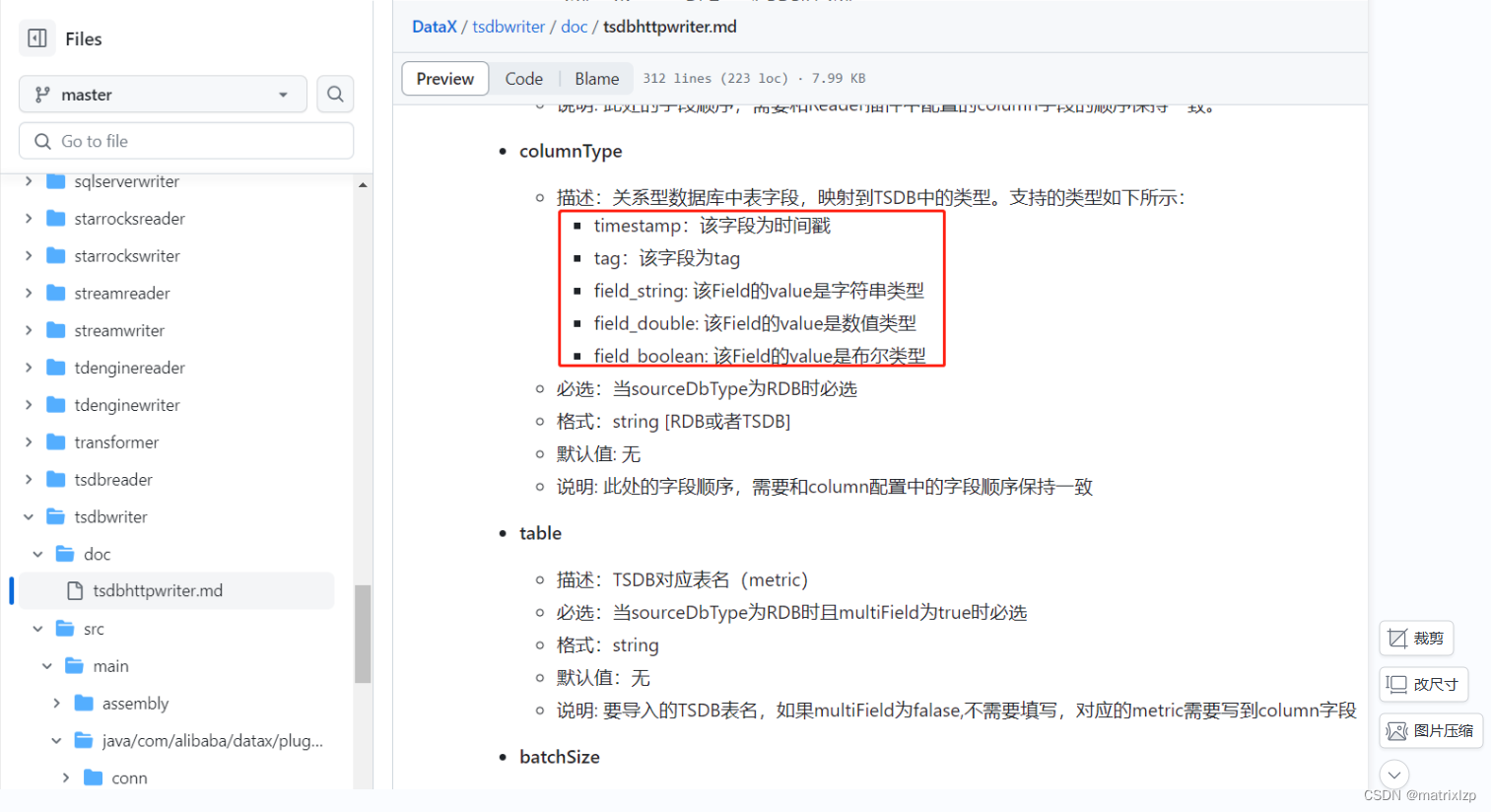
三、field_double 类型
但当我尝试把 dataX job 脚本中 long_v 的 columnType 改成 field_double 时,报了另外一个错:
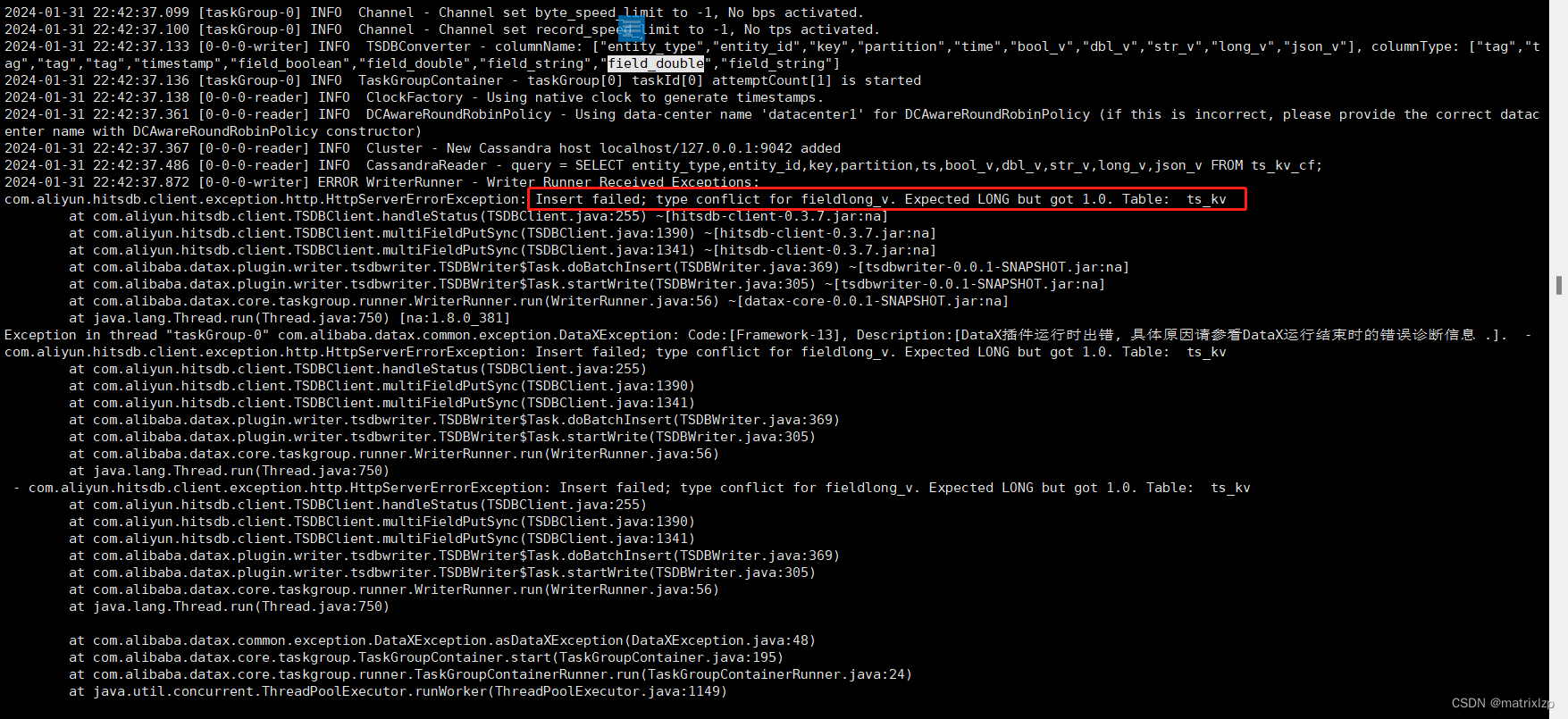
问题的原因,是我 Lindorm 的表结构里面,long_v 是 BIGINT。当 Cassandra 的 long_v 数据被查询出来,比如 1,在导入 Lindorm 之前,会由 columnType 配置的 field_double 决定转成 Double 类型,变成 1.0,然后导入 Lindorm,这个时候发现 Lindorm 的 long_v 是 BIGINT,插入失败。
怎么办?没办法,只好找阿里云 Lindorm 定制 tsdbwritter 插件,支持一下 field_long 类型。
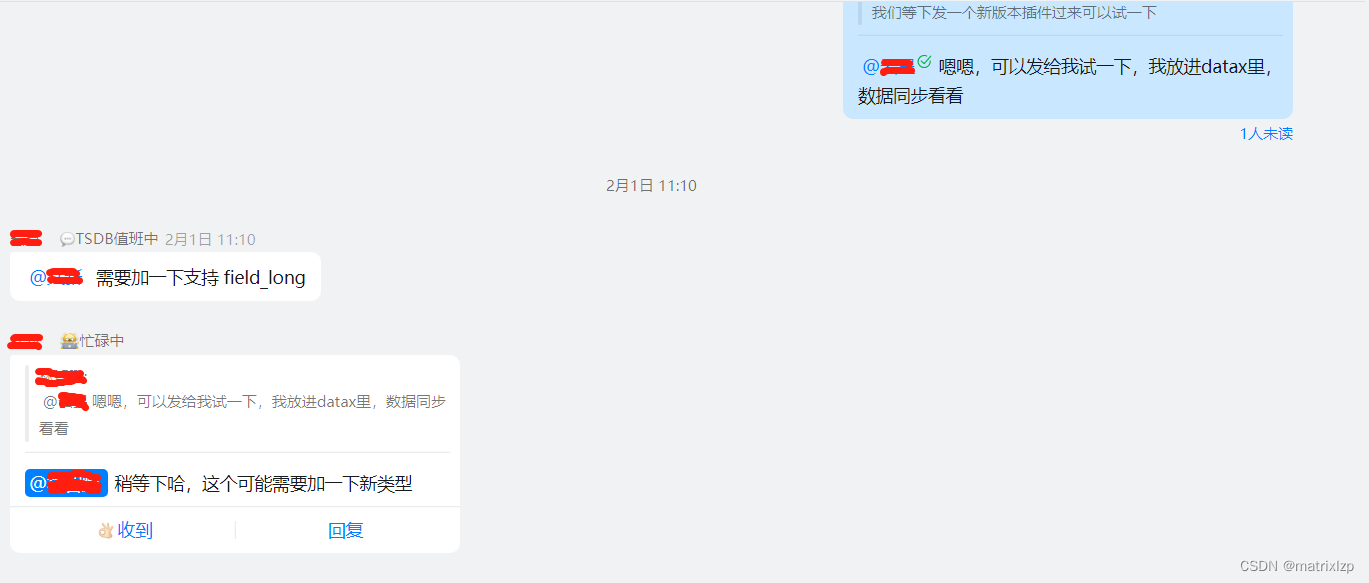
最后阿里云 Lindorm 团队发给我支持 field_long 类型的 dataX,我分享在下面:
https://download.csdn.net/download/matrixlzp/88804499
dataX 的脚本,还是文章开头的那个不变。
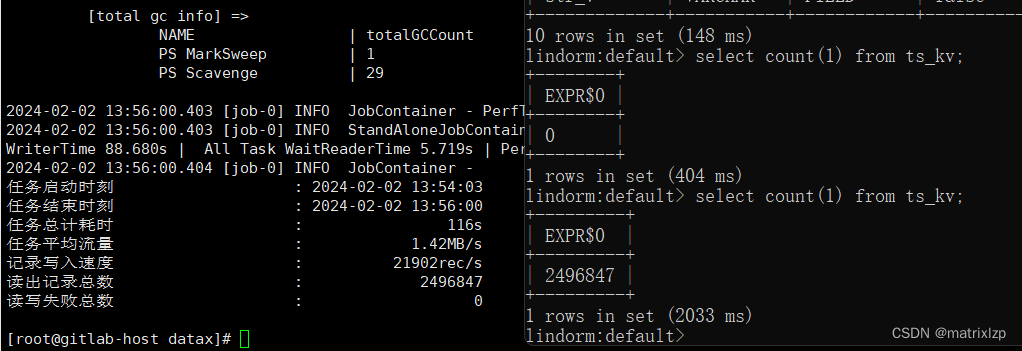
四、导入速率测试
250万 2分钟,速率还可以。















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









